

Depuis quelque temps, le terme « distillation » est de plus en plus utilisé. Dans le domaine de l'IA, il désigne généralement la compression de compétences complexes en structures plus compactes et réutilisables. Appliquée à la recherche de stratégies, cette même logique tient la route. Pour être plus direct, il s'agit de transformer des connaissances dispersées, floues et reposant sur l'expérience subjective en un système calculable, vérifiable et susceptible d'être amélioré.
Le projet crypto-kol-quant a récemment gagné en popularité. Ce qui est vraiment intéressant, ce n'est pas le nombre de KOL qu'il capture, ni son utilisation des LLM, mais le fait qu'il tente de faire quelque chose de peu courant dans la recherche quantitative : distiller l'expérience des traders en un ensemble de facteurs de capacité calculables, puis les agréger en un signal de consensus. Cette question mérite d'être prise au sérieux. Car si un groupe de traders actifs depuis longtemps et au style stable a effectivement développé ses propres cadres cognitifs sur le marché, ces cadres ne devraient pas exister uniquement dans des tweets, des graphiques et des bribes de discussion ; ils méritent d'être extraits, structurés et intégrés dans une chaîne de stratégie opérationnelle.
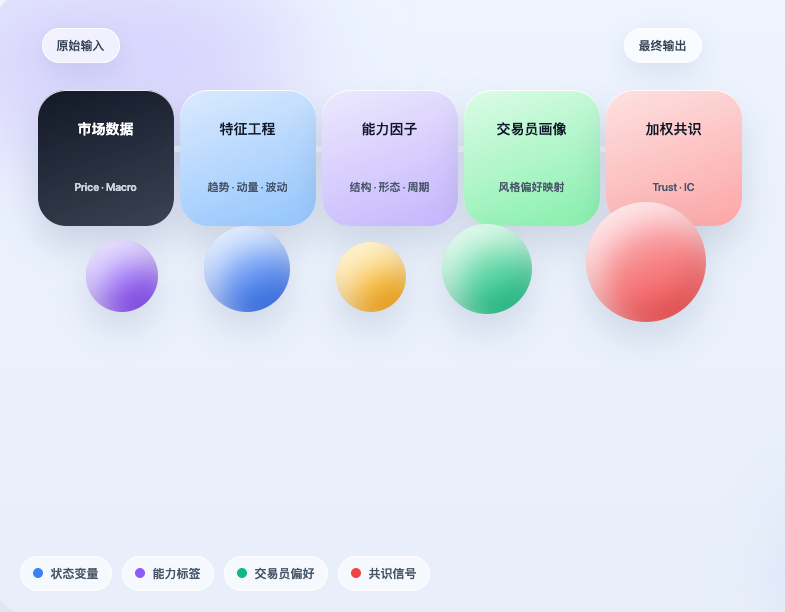
Sur la base de cette idée, nous avons réalisé une implémentation préliminaire dans l'environnement quantitatif Inventor. L'objectif n'était pas de simplement « copier » le projet, mais de relier véritablement sa logique centrale : d'abord acquérir les données de marché, puis traduire le marché en états structurés ; ensuite, selon ces états, déterminer quelles capacités de trading sont activées ; puis mapper ces capacités sur les profils des traders ; enfin, agréger les jugements individuels des différents traders en un signal de consensus pondéré. Ce n'est évidemment pas encore un système de trading mature, mais il accomplit au moins une chose importante : prouver que l'expérience des traders peut effectivement être compressée, structurée et intégrée dans un processus de décision stratégique.
L'objet de la distillation n'est pas l'opinion, mais la capacité de trading
Beaucoup de gens qui découvrent ce type de projet pour la première fois le prennent pour une « stratégie de sentiment des KOL ». Mais ce n'est pas tout à fait exact. Ce que fait vraiment le projet original, ce n'est pas simplement déterminer qui est le plus optimiste aujourd'hui, ni compter qui crie « long » ou « short », mais plutôt aller plus loin et se demander : comment ce trader comprend-il le marché ? Dans quelle structure penche-t-il vers le long ? Se concentre-t-il davantage sur la tendance, la position, la configuration, la volatilité ou l'environnement macro ? Ces approches peuvent-elles être organisées en un ensemble stable d'étiquettes de capacités ?
Une fois que la question est posée ainsi, le centre de gravité de la stratégie change. Le système ne s'intéresse plus à une phrase particulière, mais à la méthodologie derrière cette phrase. En d'autres termes, ce que cette stratégie distille vraiment, ce n'est pas du texte, mais la connaissance du trading elle-même. Elle tente de traduire l'expérience subjective qui dépendait auparavant de l'interprétation humaine en capacités régulées que le programme peut reconnaître et utiliser. C'est aussi la plus grande différence avec les modèles de sentiment courants : il ne s'agit pas de juger à quel point le sentiment du marché est « chaud », mais de reconstruire la façon dont différents cadres de trading réagissent dans le marché actuel.
Première étape : traduire d'abord le marché en variables d'état
Pour que la distillation devienne réellement opérationnelle, la première étape n'est certainement pas la prédiction, mais l'ingénierie des caractéristiques. La raison est simple : le langage des traders est conçu pour les humains, pas pour les programmes. Par exemple, la phrase « Le prix a rebondi sur la moyenne mobile clé, c'est un bon point de réentrée » est très claire pour un trader, mais pour un programme, elle doit d'abord être décomposée : quelle est la moyenne mobile clé ? Est-ce la 50 ou la 200 périodes ? Le prix actuel est-il proche de cette moyenne mobile ? La tendance a-t-elle été brisée ? Y a-t-il un signal de soutien ?
Ainsi, la première chose que le système doit faire n'est pas de donner une conclusion haussière ou baissière, mais de convertir les données de marché brutes en un ensemble d'états structurés. La couche la plus fondamentale consiste à utiliser les prix pour construire des caractéristiques de tendance et de momentum. Des variables comme les moyennes mobiles simples, exponentielles, RSI, MACD ne sont pas là pour empiler des indicateurs, mais pour répondre à une question simple : dans quel état général se trouve le marché actuellement ?

Le code clé est le suivant :
python
# Utiliser des moyennes mobiles de différentes périodes pour décrire la position du prix par rapport à la tendance
f['ma20'] = _sma(c,20)
f['ma50'] = _sma(c,50)
f['ma100'] = _sma(c,100)
f['ma200'] = _sma(c,200)
# Les moyennes mobiles exponentielles sont plus sensibles aux variations récentes des prix
f['ema20'] = _ema(c,20)
f['ema50'] = _ema(c,50)
# Le RSI permet de déterminer si le marché est en surachat ou survente, ou si le momentum s'estompe
f['rsi14'] = _rsi(c,14)
# Le MACD, sa ligne de signal et son histogramme, pour observer les changements de tendance et de momentum
ml, ms, mh = _macd(c)
f['macd'] = ml
f['macd_sig'] = ms
f['macd_hist'] = mh
Ce que fait ce code n'est pas très complexe. Les moyennes mobiles aident le système à déterminer la position du prix par rapport à la tendance à long terme, tandis que le RSI et le MACD décrivent si le momentum s'accélère ou s'atténue. On n'est pas encore dans le jugement de trading, mais simplement dans la construction d'une couche de « description de l'état du marché ».
Ensuite, le système doit également ajouter la volatilité et les relations de position, car de nombreuses décisions de trading ne reposent pas uniquement sur la tendance, mais aussi sur le fait de savoir si l'on est dans une « période de contraction de la volatilité » ou si le prix est proche des plus hauts/bas d'une fourchette.
Le code correspondant est :
python
# Le rendement logarithmique est la base du calcul de la volatilité
logr = np.log(c / c.shift(1))
# Volatilité annualisée sur 30 jours, pour mesurer le niveau actuel de volatilité du marché
f['rv30'] = logr.rolling(30, min_periods=10).std() * np.sqrt(365)
# Plus hauts et plus bas sur 20 et 50 jours, pour déterminer la position du prix
f['high_20d'] = h.rolling(20, min_periods=1).max()
f['low_20d'] = l.rolling(20, min_periods=1).min()
f['high_50d'] = h.rolling(50, min_periods=1).max()
f['low_50d'] = l.rolling(50, min_periods=1).min()
Ici, rv30 représente le niveau de volatilité annualisée sur les 30 derniers jours, tandis que les plus hauts et bas de la fourchette aident le système à déterminer où se situe le prix actuel dans la structure de prix récente. En outre, le contexte macroéconomique est également intégré dans l'espace d'état. Car certains traders ne se contentent pas de regarder le prix de la crypto ; ils observent simultanément l'indice du dollar, l'appétit pour le risque des actions américaines et le contexte des taux d'intérêt. La manière de gérer cela dans le code consiste d'abord à aligner ces variables sur une base quotidienne, puis à les convertir en états lisibles :
python
# DXY comme variable de fond pour la force du dollar
if 'DXY' in macro:
dxy = _align(macro['DXY'])
f['dxy_ret_20d'] = dxy.pct_change(20)
f['dxy_trend_down'] = (dxy.pct_change(20) < -0.01).astype(int)
# SPX comme variable de fond pour l'appétit pour le risque
if 'SPX' in macro:
spx = _align(macro['SPX'])
f['spx_ret_20d'] = spx.pct_change(20)
f['spx_trend_up'] = (spx.pct_change(20) > 0).astype(int)
Le sens de cette étape peut se résumer en une phrase : d'abord traduire « comment est le marché maintenant ? » en un état structuré et lisible en continu par la machine. Sans cette couche, la distillation ultérieure serait impossible.
Deuxième étape : écrire l'expérience subjective sous forme de facteurs de capacité
Les caractéristiques seules ne suffisent pas, car elles ne font que décrire le marché sans exprimer directement ce que cet état signifie. L'étape suivante consiste à écrire l'expérience des traders sous forme de règles, c'est-à-dire, en fonction de ces variables d'état actuelles, déterminer quelles capacités de trading sont activées.
C'est l'étape la plus marquée par la distillation dans l'ensemble de la stratégie. Car il ne s'agit plus de dire abstraitement qu'« un certain cadre est important », mais de l'écrire vraiment sous forme de conditions de programme. Les facteurs de capacité inclus dans l'implémentation actuelle couvrent plusieurs niveaux : patterns morphologiques, structurels, indicateurs, cycles et macroéconomie. Par exemple, certaines capacités proviennent de la reconnaissance de patterns (drapeau haussier, drapeau baissier, double sommet/creux, tête-épaules, triangle) ; d'autres de l'analyse structurelle (Wyckoff, SMC, ICT, etc.) ; d'autres encore des indicateurs eux-mêmes (divergence RSI, croisement de moyennes mobiles, sortie des bandes de Bollinger) ; et enfin certaines proviennent du cycle et de l'environnement macro (cycle de halving, transition entre marché de tendance et marché de range, baisse du DXY, regain d'appétit pour le risque).
Un exemple typique est la « continuation après un pullback sur tendance ». De nombreux traders ont l'expérience suivante : si la tendance générale est toujours haussière, le prix effectue un pullback sur la moyenne mobile clé, et la bougie actuelle montre un soutien, cela signifie souvent une continuation de la tendance. Le programme l'exprime très directement :
python
# Vérifier si le prix actuel est proche de la moyenne mobile à 50 jours
near_ma50 = abs(close - ma50_v) / close < 0.02 if close > 0 else False
# Si la moyenne mobile à 50 jours est toujours au-dessus de celle à 200 jours, et qu'un pullback sur cette moyenne est suivi d'une bougie haussière
# alors on enregistre un signal de capacité de continuation de tendance
s['cap_014_trend_pullback_continuation'] = 0.6 if (ma50_gt and near_ma50 and is_green) else 0.0
Il n'y a rien de mystérieux ici : il s'agit simplement de décomposer une phrase humaine en conditions que la machine peut évaluer une par une. Un autre exemple est la « sortie des bandes de Bollinger en compression ». Pour de nombreux traders, lorsque la volatilité se contracte longtemps puis se dilate soudainement à la hausse ou à la baisse, cela indique généralement un nouveau choix de direction. La règle correspondante s'écrit :
python
# Si la largeur des bandes de Bollinger de la bougie précédente est inférieure au seuil de compression, on considère qu'il y a contraction
squeezed = bb_w_p1 < bb_w20_p1 if bb_w20_p1 > 0 else False
# Après contraction, sortie au-dessus de la bande supérieure → signal positif ; cassure en dessous de la bande inférieure → signal négatif
s['cap_021_bollinger_squeeze_breakout'] = (
0.6 if (squeezed and close > bb_u) else
-0.6 if (squeezed and close < bb_l) else 0.0
)
Le traitement des facteurs macro est identique. Pour une catégorie de traders plus macro, le BTC n'est pas une série de prix totalement isolée ; il est influencé par le dollar, les marchés actions et les taux d'intérêt. Ces compréhensions sont donc également écrites sous forme de jugements de capacité.
python
# DXY en baisse est généralement considéré comme un contexte favorable pour BTC
s['cap_027_dxy_inverse_btc'] = 0.4 if (not _nm(dxy_r20) and dxy_r20 < -0.01) else 0.0
# La hausse du S&P est considérée comme une amélioration de l'appétit pour le risque
s['cap_028_spx_risk_on_off'] = 0.4 if (not _nm(spx_r20) and spx_r20 > 0.02) else 0.0
# La baisse des taux courts est considérée comme une amélioration marginale de la liquidité
s['cap_029_yields_liquidity'] = 0.4 if (not _nm(y_r20) and y_r20 < -0.02) else 0.0
Ce qui compte vraiment à ce niveau, ce n’est pas le nombre de règles écrites, mais le fait d’avoir accompli l’étape la plus cruciale de la distillation : transformer des jugements qui ne pouvaient auparavant être saisis que subjectivement en conditions calculables. Il convient de noter au passage que la plupart des facteurs de capacité dans la version actuelle sont encore de type conditionnel plutôt que de notation continue. Cela signifie que le système fonctionne davantage comme un détecteur de structure que comme un réévaluateur permanent de chaque fluctuation infime. Cela le rend également plus adapté pour l’instant à des décisions daily ou basse fréquence, plutôt qu’au trading haute fréquence.
Troisième étape : les facteurs ne sont pas additionnés directement, mais d’abord mappés sur le profil du trader
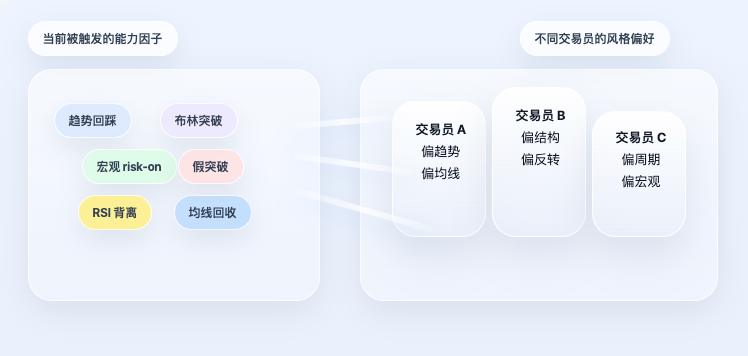
Si une stratégie s’arrêtait au niveau des facteurs, elle ne serait encore qu’un système de règles ordinaire. Ce qui rend le projet original particulier, c’est qu’il ne s’arrête pas là, mais franchit une étape supplémentaire : les facteurs ne déterminent pas directement la direction, ils sont d’abord mappés sur le profil du trader.
Ce point est crucial. Car dans la réalité, un trader n’utilise pas « toutes ses capacités de manière égale ». Certains sont plutôt trend, d’autres structure, d’autres cycles, d’autres macro. Même face au même état de marché, l’attention de chacun porte sur des éléments complètement différents. Ainsi, le système ne se contente pas de faire la moyenne de tous les facteurs. Il commence par lire les préférences de capacités de chaque trader, puis calcule son signal personnel en fonction de l’état actuel des facteurs.
La logique de lecture du profil correspondante est la suivante :
python
# Lecture des facteurs de capacité et de leurs poids utilisés par chaque trader dans son profil
caps = {c['id']: float(c.get('weight', 0.5))
for c in p.get('capabilities_used', [])}
profiles.append({
'handle': p.get('handle', item['name'][:-5]),
'caps': caps
})
Chaque profil répond essentiellement à une question : de quels facteurs de capacité ce trader dépend-il le plus, et quel poids ces capacités ont-elles dans son cadre d’analyse. Une fois ces profils en main, le système calcule le « signal personnel » de chaque trader dans le marché actuel :
python
for p in profiles:
sig = 0.0
wt = 0.0
# Parcours de tous les facteurs de capacité suivis par ce trader
for cap_id, w in p['caps'].items():
score = factor_scores.get(cap_id, 0.0)
# Score du facteur multiplié par le poids de préférence du trader pour ce facteur
sig += w * score
wt += abs(w)
# Normalisation pour obtenir le signal personnel de ce trader dans le marché actuel
trader_raw = sig / wt if wt > 0 else 0.0
À ce stade, on voit bien que le système a une saveur très différente. Il ne se contente plus de regarder « quels facteurs sont activés », mais reconstruit approximativement une chose : si l’on confiait le marché d’aujourd’hui à ces 99 traders, comment chacun jugerait-il la situation.
Quatrième étape : du signal personnel au consensus pondéré
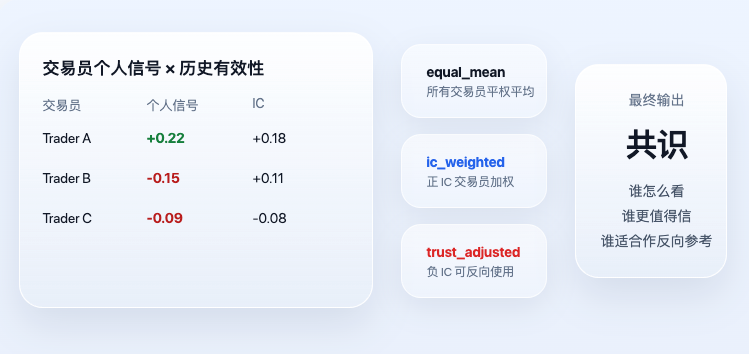
Une fois le signal personnel de chaque trader calculé, le système entre dans la véritable couche de consensus. Ce « consensus » n’est pas un simple vote, encore moins une affaire de qui parle le plus fort, mais prend en compte l’efficacité historique.
Les deux résultats les plus importants dans le code actuel sont ic_weighted et trust_adjusted. La logique centrale correspondante est :
python
# D’abord, pondération positive des traders ayant un IC positif pour obtenir ic_weighted
pos_w = sum(max(t['ic'], 0) for t in trader_signals)
ic_wt = (
sum(t['signal'] * max(t['ic'], 0) for t in trader_signals) / pos_w
if pos_w > 0 else 0.0
)
# trust_adjusted va plus loin :
# IC positif utilisé dans le même sens, IC négatif utilisé en sens inverse, pondéré par la valeur absolue de l'IC
abs_w = sum(abs(t['ic']) for t in trader_signals)
trust = (
sum((t['signal'] if t['ic'] >= 0 else -t['signal']) * abs(t['ic'])
for t in trader_signals) / abs_w
if abs_w > 0 else 0.0
)
Ce code exprime deux principes très simples mais essentiels. Premièrement, les traders historiquement plus efficaces ont aujourd’hui un poids plus important. Deuxièmement, les traders dont l’IC historique est négatif ne sont pas écartés, mais peuvent être utilisés comme indicateurs inverses. Ainsi, le trust_adjusted final n’est pas un simple « qu’en pense la majorité », mais plutôt « qui pense quoi, et qui est le plus digne de confiance ».
C’est aussi pourquoi ce système diffère des modèles de sentiment ordinaires. Il ne comptabilise pas le nombre d’opinions, mais effectue une agrégation cognitive validée historiquement. Si l’on résume l’ensemble en une phrase : il s’agit d’abord de transformer le marché en variables d’état, puis de mapper ces variables d’état en facteurs de capacité, puis de mapper ces facteurs de capacité en signaux personnels de traders, et enfin d’agréger ces signaux personnels en un jugement consensuel pondéré par l’efficacité historique.
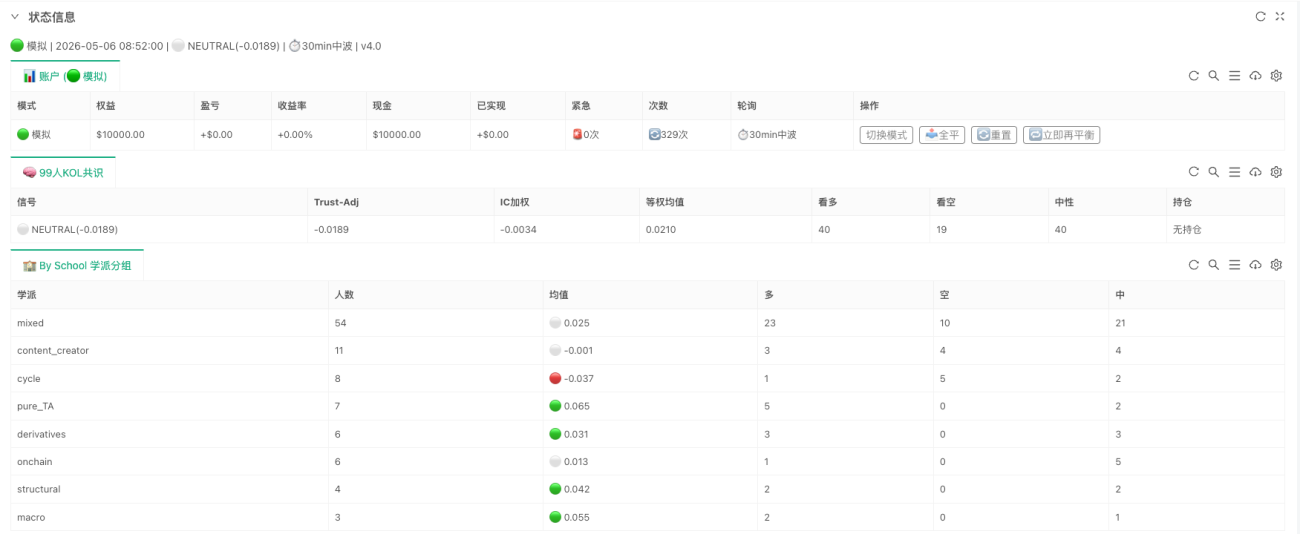
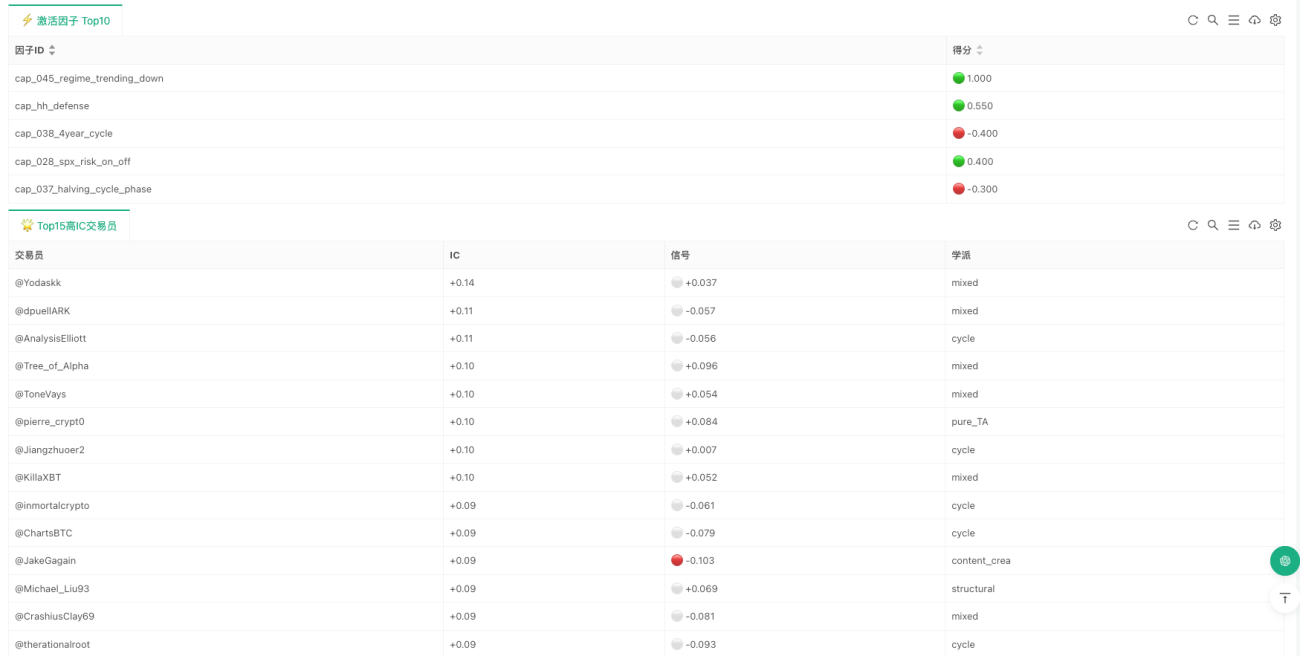
Ce qui a réellement été mis en œuvre sur Inventor
Si ce système n’était resté qu’un projet de recherche, il ressemblerait surtout à un « analyseur de consensus ». L’implémentation sur Inventor, elle, a pour objectif de boucler toute la chaîne pour qu’elle puisse tourner en continu. Le code le plus central se résume à trois lignes :
python
# Première étape : convertir les données brutes de marché et les variables macro en état structuré
feat_df = build_features(records, macro if macro else None)
# Deuxième étape : évaluer quels facteurs de capacité sont activés par l’état actuel
factor_scores = evaluate_factors(feat_df)
# Troisième étape : mapper les facteurs de capacité sur les profils de traders et agréger en consensus
consensus = compute_consensus(factor_scores)
Ces trois lignes constituent les trois couches d’abstraction les plus importantes de la stratégie. La première couche gère l’état du marché, la seconde le jugement de capacité, la troisième le consensus des traders. Bien sûr, viennent ensuite la couche d’exécution, la gestion des risques et l’affichage d’état, mais du point de vue de la logique de recherche, la partie la plus critique est déjà complète et valide. Autrement dit, l’importance principale de cette implémentation n’est pas d’ajouter des détails d’exécution, mais de faire en sorte que, dans le projet original, le profil de capacité ne soit plus seulement un fichier statique, les facteurs ne soient plus seulement des sorties de recherche, et le consensus ne soit plus seulement un chiffre dans un rapport : ils sont désormais intégrés dans un processus de jugement continu.
Pourquoi ce n’est encore qu’un prototype
Bien sûr, cette implémentation n’est pas une version finale. Le code actuel utilise un cadre daily pour BTC, il est donc mieux adapté à des jugements de consensus basse fréquence qu’à un système de trading haute fréquence. Son cœur reste centré sur les structures daily, les positions cycliques, le contexte macro et les préférences de capacités des traders. De plus, les profils de traders et les IC sont toujours des entrées statiques, sans phase d’évolution en ligne. Autrement dit, le système a bien réalisé la première étape de « distillation des connaissances », mais il n’est pas encore parvenu à une « auto-correction des connaissances distillées ».
Cela n’empêche pas qu’il ait déjà démontré une chose très importante : l’expérience des traders peut être compressée, structurée par couches, et réellement intégrée dans une chaîne stratégique. Sa valeur ne réside pas dans le fait d’avoir déjà généré des rendements stables, mais dans le fait d’avoir fait passer un chemin de recherche qui restait au niveau conceptuel à un stade exécutable. Quant à savoir comment ces facteurs de capacité doivent évoluer, comment les poids des traders doivent être mis à jour, comment le consensus doit être continuellement recalibré dans un marché réel, cela nécessitera encore plus de données de fonctionnement pour y répondre.
Conclusion
Ce qui est vraiment inspirant dans crypto-kol-quant, ce n’est pas le nombre de concepts à la mode qu’il utilise, mais le fait qu’il a réellement fait avancer une chose difficile à systématiser : transformer l’expérience des traders, de l’expression en capacité, de la capacité en facteur, et du facteur en consensus. Et l’implémentation sur Inventor fait précisément fonctionner cette chaîne de distillation. Elle ne prétend pas être une version finale, et ne cherche pas à dissimuler qu’elle n’est encore qu’un prototype précoce. Mais elle prouve au moins que l’expérience de trading ne doit pas nécessairement rester confinée aux graphiques et aux mots : elle peut être distillée, structurée, exécutée, et même intégrée dans un système qui juge en continu le marché.
Si la quantification traditionnelle excelle à trouver des motifs dans les séries de prix, la direction qui vaut vraiment la peine d’être poursuivie pour ce type de stratégie est peut-être : extraire des motifs à partir de la cognition humaine, puis laisser ces motifs participer à leur tour au marché. Et c’est là que réside peut-être l’intérêt le plus grand de la « distillation » dans la recherche stratégique.
Projet original : 锁妖塔 Skill — 炼化99个加密交易员
Remerciements particuliers à l’utilisateur « GiantBin » pour ses idées et suggestions. Si vous avez de bonnes idées ou réflexions, n’hésitez pas à les partager.
- 1