Le collecteur de cotations de marché est à nouveau mis à niveau.
Auteur:La bonté, Créé: 2020-05-26 14:25:15, Mis à jour: 2023-11-02 19:53:34
Prise en charge de l'importation de fichiers au format CSV pour fournir une source de données personnalisée
Récemment, un commerçant a besoin d'utiliser son propre fichier au format CSV comme source de données pour le système de backtest de la plateforme FMZ. notre système de backtest de la plateforme a de nombreuses fonctions et est simple et efficace à utiliser, de sorte que tant que les utilisateurs ont leurs propres données, ils peuvent effectuer des backtesting en fonction de ces données, ce qui n'est plus limité aux échanges et variétés pris en charge par notre centre de données de plateforme.
Idées de conception
L'idée de conception est en fait très simple. nous avons seulement besoin de le modifier légèrement basé sur le collecteur de marché précédent. nous ajoutons un paramètreisOnlySupportCSVLe paramètre de l'indicateur d'impact est le paramètre de l'indicateur d'impact de l'indicateur d'impact de l'indicateur d'impact de l'indicateur d'impact de l'indicateur d'impact de l'indicateur d'impact de l'indicateur d'impact de l'indicateur d'impact.filePathForCSVIl est utilisé pour définir le chemin du fichier de données CSV placé sur le serveur où le robot collecteur de marché s'exécute.isOnlySupportCSVparamètre est réglé surTruePour décider de la source de données à utiliser (collectée par vous-même ou les données du fichier CSV), cette modification se fait principalement dans ledo_GETLe rôle de laProvider class.
C'est quoi un fichier CSV?
Les valeurs séparées par des virgules, également connues sous le nom de CSV, sont parfois appelées valeurs séparées par des caractères, car le caractère séparateur ne peut pas non plus être une virgule. Son fichier stocke les données de la table (numéros et texte) en texte brut. Le texte brut signifie que le fichier est une séquence de caractères et ne contient pas de données qui doivent être interprétées comme un nombre binaire. Le fichier CSV se compose d'un nombre quelconque d'enregistrements, séparés par un caractère de nouvelle ligne; chaque enregistrement est composé de champs, et les séparateurs entre les champs sont d'autres caractères ou chaînes, et les plus courants sont des virgules ou des onglets.WORDPADouExcelPour ouvrir.
La norme générale du format de fichier CSV n'existe pas, mais il existe certaines règles, généralement un enregistrement par ligne, et la première ligne est l'en-tête.
Par exemple, le fichier CSV que nous avons utilisé pour le test est ouvert avec le Bloc-notes comme ceci:
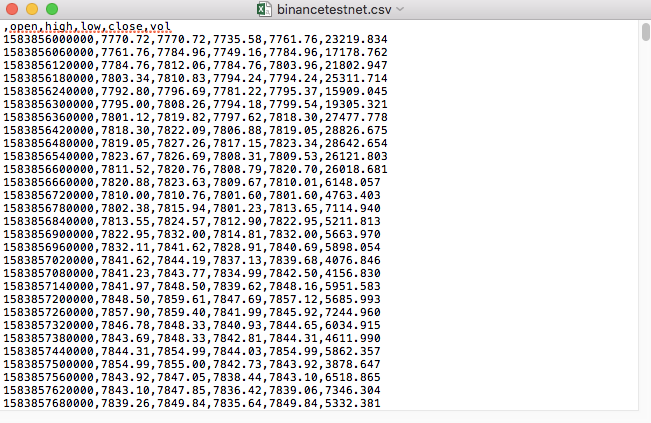
On constate que la première ligne du fichier CSV est l'en-tête de la table.
,open,high,low,close,vol
Nous avons juste besoin d'analyser et de trier ces données, puis de les construire dans le format requis par la source de données personnalisée du système de backtest.
Code modifié
import _thread
import pymongo
import json
import math
import csv
from http.server import HTTPServer, BaseHTTPRequestHandler
from urllib.parse import parse_qs, urlparse
def url2Dict(url):
query = urlparse(url).query
params = parse_qs(query)
result = {key: params[key][0] for key in params}
return result
class Provider(BaseHTTPRequestHandler):
def do_GET(self):
global isOnlySupportCSV, filePathForCSV
try:
self.send_response(200)
self.send_header("Content-type", "application/json")
self.end_headers()
dictParam = url2Dict(self.path)
Log("The custom data source service receives the request,self.path:", self.path, "query parameter:", dictParam)
# At present, the backtest system can only select the exchange name from the list. When adding a custom data source, set it to Binance, that is: Binance
exName = exchange.GetName()
# Note that period is the bottom K-line period
tabName = "%s_%s" % ("records", int(int(dictParam["period"]) / 1000))
priceRatio = math.pow(10, int(dictParam["round"]))
amountRatio = math.pow(10, int(dictParam["vround"]))
fromTS = int(dictParam["from"]) * int(1000)
toTS = int(dictParam["to"]) * int(1000)
# Request data
data = {
"schema" : ["time", "open", "high", "low", "close", "vol"],
"data" : []
}
if isOnlySupportCSV:
# Handle CSV reading, filePathForCSV path
listDataSequence = []
with open(filePathForCSV, "r") as f:
reader = csv.reader(f)
# Get table header
header = next(reader)
headerIsNoneCount = 0
if len(header) != len(data["schema"]):
Log("The CSV file format is wrong, the number of columns is different, please check!", "#FF0000")
return
for ele in header:
for i in range(len(data["schema"])):
if data["schema"][i] == ele or ele == "":
if ele == "":
headerIsNoneCount += 1
if headerIsNoneCount > 1:
Log("The CSV file format is incorrect, please check!", "#FF0000")
return
listDataSequence.append(i)
break
# Read content
while True:
record = next(reader, -1)
if record == -1:
break
index = 0
arr = [0, 0, 0, 0, 0, 0]
for ele in record:
arr[listDataSequence[index]] = int(ele) if listDataSequence[index] == 0 else (int(float(ele) * amountRatio) if listDataSequence[index] == 5 else int(float(ele) * priceRatio))
index += 1
data["data"].append(arr)
Log("data: ", data, "Respond to backtest system requests.")
self.wfile.write(json.dumps(data).encode())
return
# Connect to the database
Log("Connect to the database service to obtain data, the database: ", exName, "table: ", tabName)
myDBClient = pymongo.MongoClient("mongodb://localhost:27017")
ex_DB = myDBClient[exName]
exRecords = ex_DB[tabName]
# Construct query conditions: greater than a certain value {'age': {'$ gt': 20}} less than a certain value {'age': {'$lt': 20}}
dbQuery = {"$and":[{'Time': {'$gt': fromTS}}, {'Time': {'$lt': toTS}}]}
Log("Query conditions: ", dbQuery, "Number of inquiries: ", exRecords.find(dbQuery).count(), "Total number of databases: ", exRecords.find().count())
for x in exRecords.find(dbQuery).sort("Time"):
# Need to process data accuracy according to request parameters round and vround
bar = [x["Time"], int(x["Open"] * priceRatio), int(x["High"] * priceRatio), int(x["Low"] * priceRatio), int(x["Close"] * priceRatio), int(x["Volume"] * amountRatio)]
data["data"].append(bar)
Log("data: ", data, "Respond to backtest system requests.")
# Write data response
self.wfile.write(json.dumps(data).encode())
except BaseException as e:
Log("Provider do_GET error, e:", e)
def createServer(host):
try:
server = HTTPServer(host, Provider)
Log("Starting server, listen at: %s:%s" % host)
server.serve_forever()
except BaseException as e:
Log("createServer error, e:", e)
raise Exception("stop")
def main():
LogReset(1)
if (isOnlySupportCSV):
try:
# _thread.start_new_thread(createServer, (("localhost", 9090), )) # local test
_thread.start_new_thread(createServer, (("0.0.0.0", 9090), )) # Test on VPS server
Log("Start the custom data source service thread, and the data is provided by the CSV file. ", "#FF0000")
except BaseException as e:
Log("Failed to start the custom data source service!")
Log("Error message: ", e)
raise Exception("stop")
while True:
LogStatus(_D(), "Only start the custom data source service, do not collect data!")
Sleep(2000)
exName = exchange.GetName()
period = exchange.GetPeriod()
Log("collect", exName, "Exchange K-line data,", "K line cycle:", period, "Second")
# Connect to the database service, service address mongodb: //127.0.0.1: 27017 See the settings of mongodb installed on the server
Log("Connect to the mongodb service of the hosting device, mongodb://localhost:27017")
myDBClient = pymongo.MongoClient("mongodb://localhost:27017")
# Create a database
ex_DB = myDBClient[exName]
# Print the current database table
collist = ex_DB.list_collection_names()
Log("mongodb", exName, "collist:", collist)
# Check if the table is deleted
arrDropNames = json.loads(dropNames)
if isinstance(arrDropNames, list):
for i in range(len(arrDropNames)):
dropName = arrDropNames[i]
if isinstance(dropName, str):
if not dropName in collist:
continue
tab = ex_DB[dropName]
Log("dropName:", dropName, "delete:", dropName)
ret = tab.drop()
collist = ex_DB.list_collection_names()
if dropName in collist:
Log(dropName, "failed to delete")
else :
Log(dropName, "successfully deleted")
# Start a thread to provide a custom data source service
try:
# _thread.start_new_thread(createServer, (("localhost", 9090), )) # local test
_thread.start_new_thread(createServer, (("0.0.0.0", 9090), )) # Test on VPS server
Log("Open the custom data source service thread", "#FF0000")
except BaseException as e:
Log("Failed to start the custom data source service!")
Log("Error message:", e)
raise Exception("stop")
# Create the records table
ex_DB_Records = ex_DB["%s_%d" % ("records", period)]
Log("Start collecting", exName, "K-line data", "cycle:", period, "Open (create) the database table:", "%s_%d" % ("records", period), "#FF0000")
preBarTime = 0
index = 1
while True:
r = _C(exchange.GetRecords)
if len(r) < 2:
Sleep(1000)
continue
if preBarTime == 0:
# Write all BAR data for the first time
for i in range(len(r) - 1):
bar = r[i]
# Write root by root, you need to determine whether the data already exists in the current database table, based on timestamp detection, if there is the data, then skip, if not write
retQuery = ex_DB_Records.find({"Time": bar["Time"]})
if retQuery.count() > 0:
continue
# Write bar to the database table
ex_DB_Records.insert_one({"High": bar["High"], "Low": bar["Low"], "Open": bar["Open"], "Close": bar["Close"], "Time": bar["Time"], "Volume": bar["Volume"]})
index += 1
preBarTime = r[-1]["Time"]
elif preBarTime != r[-1]["Time"]:
bar = r[-2]
# Check before writing data, whether the data already exists, based on time stamp detection
retQuery = ex_DB_Records.find({"Time": bar["Time"]})
if retQuery.count() > 0:
continue
ex_DB_Records.insert_one({"High": bar["High"], "Low": bar["Low"], "Open": bar["Open"], "Close": bar["Close"], "Time": bar["Time"], "Volume": bar["Volume"]})
index += 1
preBarTime = r[-1]["Time"]
LogStatus(_D(), "preBarTime:", preBarTime, "_D(preBarTime):", _D(preBarTime/1000), "index:", index)
# Increase drawing display
ext.PlotRecords(r, "%s_%d" % ("records", period))
Sleep(10000)
Exécution de l'essai
D'abord, on démarre le robot collecteur, on ajoute un échange au robot et on le laisse fonctionner.
Configuration des paramètres:

Puis nous créons une stratégie de test:
function main() {
Log(exchange.GetRecords())
Log(exchange.GetRecords())
Log(exchange.GetRecords())
}
La stratégie est très simple, il suffit d'obtenir et d'imprimer des données de ligne K trois fois.
Sur la page de backtest, définissez la source de données du système de backtest comme une source de données personnalisée, et remplissez l'adresse du serveur où le robot collecteur de marché fonctionne.
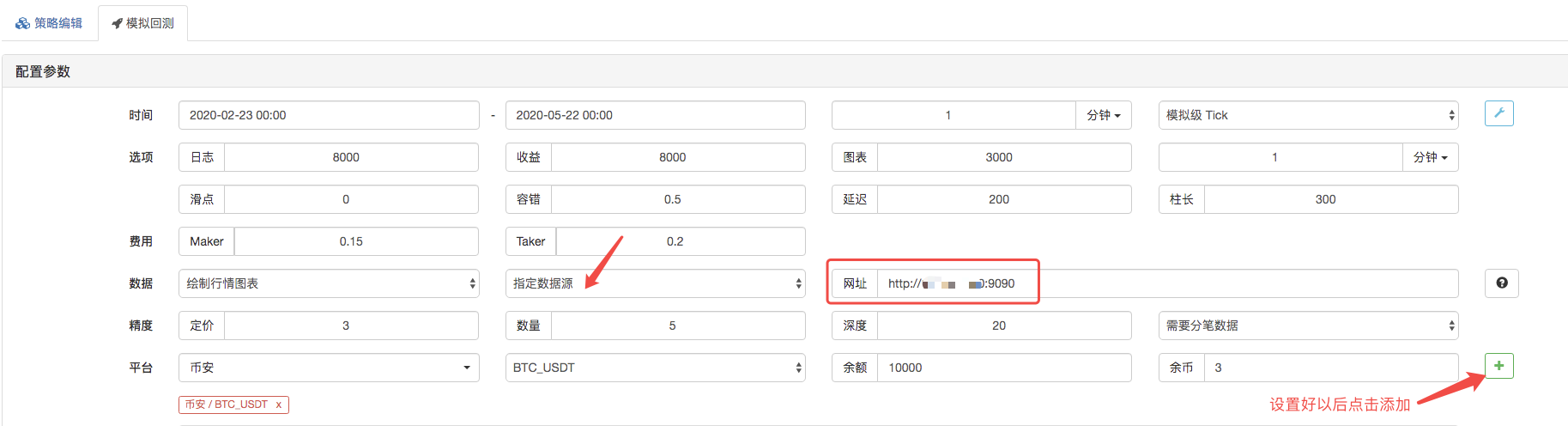
Cliquez pour démarrer le backtest, et le robot collecteur de marché reçoit la demande de données:

Une fois que la stratégie d'exécution du système de backtest est terminée, un graphique de ligne K est généré sur la base des données de ligne K de la source de données.
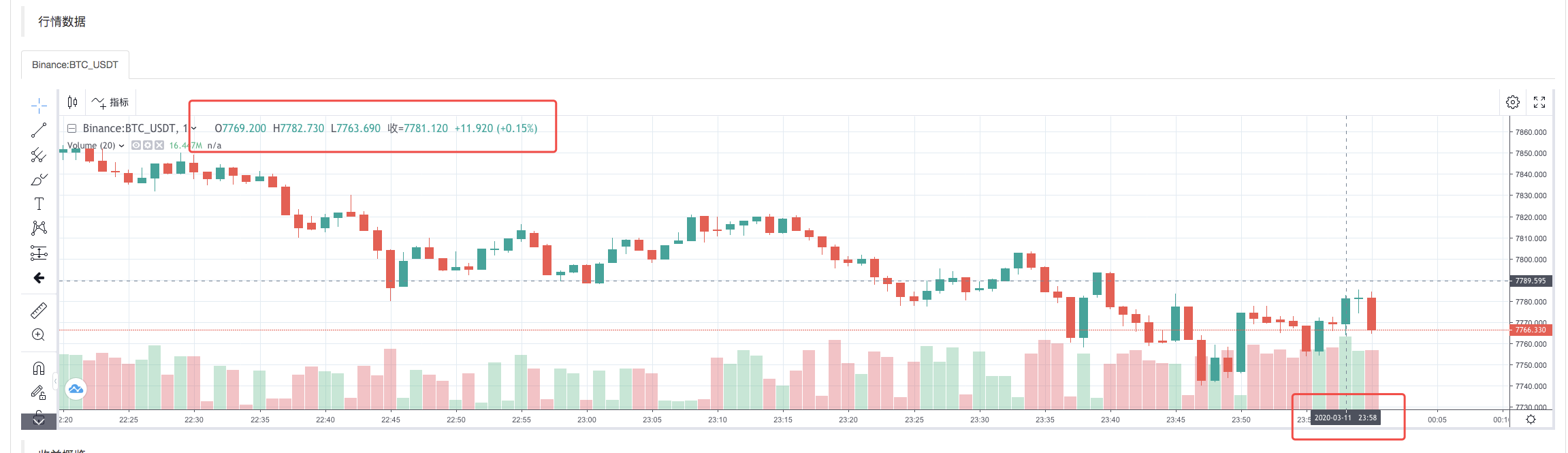
Comparez les données du fichier:

Le collecteur de cotations de marché est à nouveau mis à niveau.
- Quantifier l'analyse fondamentale sur le marché des crypto-monnaies: laissez les données parler d'elles-mêmes!
- Les fondements de la recherche quantifiée dans le cercle monétaire - ne croyez plus à tous les professeurs de mathématiques, les données sont objectives!
- Un outil indispensable dans le domaine de la quantification des transactions - l'inventeur du module de recherche de données quantifiées
- Maîtriser tout - Introduction à FMZ Nouvelle version du terminal de négociation (avec le code source TRB Arbitrage)
- Tout savoir sur la nouvelle version du terminal de trading FMZ (source code TRB)
- FMZ Quant: Une analyse des exemples de conception des exigences communes sur le marché des crypto-monnaies (II)
- Comment exploiter les robots de vente sans cerveau avec une stratégie de haute fréquence en 80 lignes de code
- Quantification FMZ: analyse de l'exemple de conception des besoins courants sur le marché des crypto-monnaies (II)
- Comment exploiter les robots sans cerveau pour les vendre avec une stratégie de haute fréquence de 80 lignes de code
- FMZ Quant: Une analyse des exemples de conception des exigences communes sur le marché des crypto-monnaies (I)
- Quantification FMZ: analyse de l'exemple de conception des besoins courants sur le marché des crypto-monnaies (1)