

हाल ही में, 'डिस्टिलेशन' शब्द का उपयोग तेजी से बढ़ा है। AI के क्षेत्र में, इसका आम तौर पर अर्थ होता है जटिल क्षमताओं को अधिक कॉम्पैक्ट, पुन: उपयोग करने योग्य संरचनाओं में संघनित करना; और जब रणनीति अनुसंधान की बात आती है, तो यही दृष्टिकोण लागू होता है। अधिक सीधे शब्दों में कहें तो, यह बिखरे हुए, अस्पष्ट, व्यक्तिपरक अनुभव पर निर्भर ज्ञान को एक ऐसी प्रणाली में व्यवस्थित करना है जिसकी गणना की जा सके, सत्यापित किया जा सके, और आगे संशोधित किया जा सके।
crypto-kol-quant प्रोजेक्ट हाल ही में काफी लोकप्रिय हुआ है, और इसमें वास्तव में दिलचस्प बात यह नहीं है कि इसने कितने KOL को पकड़ा, न ही इसमें LLM का उपयोग किया गया, बल्कि यह है कि यह कुछ ऐसा करने का प्रयास करता है जो मात्रात्मक अनुसंधान में आम नहीं है: ट्रेडर्स के अनुभव को गणना योग्य क्षमता कारकों के एक सेट में डिस्टिल करना, और फिर उन्हें एक सर्वसम्मति संकेत में एकत्रित करना। यह समस्या स्वयं गंभीरता से लेने योग्य है। क्योंकि यदि ट्रेडर्स का एक समूह, जो लंबे समय से सक्रिय हैं और जिनकी शैली स्थिर है, ने बाजार में अपने स्वयं के संज्ञानात्मक ढांचे बनाए हैं, तो सिद्धांत रूप में ये ढांचे केवल ट्वीट्स, चार्ट और टुकड़ों में ही मौजूद नहीं रहने चाहिए; उन्हें निकालने, व्यवस्थित करने और एक चलाने योग्य रणनीति पाइपलाइन में प्रवेश करने का भी अवसर मिलना चाहिए।
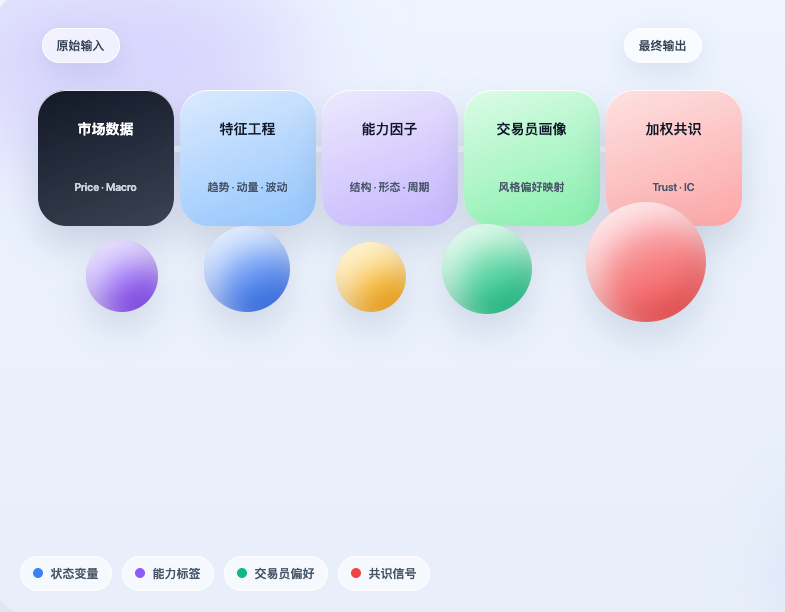
इस विचार के आधार पर, हमने FMZ Quantitative Environment में एक प्रारंभिक कार्यान्वयन किया। मुख्य बात केवल प्रोजेक्ट को 'कॉपी' करना नहीं है, बल्कि इसके मुख्य तर्क को वास्तव में एक साथ जोड़ना है: पहले बाजार डेटा प्राप्त करें, फिर बाजार को संरचित अवस्था में अनुवादित करें; फिर इन अवस्थाओं के आधार पर निर्धारित करें कि कौन सी ट्रेडिंग क्षमताएं ट्रिगर हो रही हैं; फिर इन क्षमताओं को ट्रेडर प्रोफाइल पर मैप करें, और अंत में विभिन्न ट्रेडर्स के व्यक्तिगत निर्णयों को एक भारित सर्वसम्मति संकेत में एकत्रित करें। यह स्पष्ट रूप से अभी तक एक परिपक्व ट्रेडिंग सिस्टम नहीं है, लेकिन इसने कम से कम एक महत्वपूर्ण काम पूरा किया है: यह साबित करना कि ट्रेडर के अनुभव को वास्तव में संपीड़ित, संरचित और वास्तविक रणनीति निर्णय प्रक्रिया में शामिल किया जा सकता है।
डिस्टिलेशन का उद्देश्य विचार नहीं, बल्कि ट्रेडिंग क्षमता है
कई लोग जब पहली बार इस प्रकार के प्रोजेक्ट से संपर्क करते हैं, तो वे इसे 'KOL भावना रणनीति' के रूप में समझने लगते हैं। लेकिन यह वास्तव में सटीक नहीं है। मूल प्रोजेक्ट वास्तव में यह नहीं करता कि आज कौन अधिक आशावादी है, या किसने बुलिश या बियरिश कहा, इसका सरल निर्धारण करे; बल्कि यह आगे जाकर पूछता है: यह ट्रेडर वास्तव में बाजार को कैसे समझता है? वह किस संरचना में बुलिश होता है? वह ट्रेंड, पोजीशन, पैटर्न, वोलैटिलिटी या मैक्रो एनवायरनमेंट पर अधिक ध्यान देता है? क्या इन निर्णय विधियों को स्थिर क्षमता टैग के एक सेट में व्यवस्थित किया जा सकता है?
जब समस्या इस प्रकार प्रस्तुत की जाती है, तो रणनीति का फोकस बदल जाता है। सिस्टम अब किसी एक वाक्य की परवाह नहीं करता, बल्कि उस वाक्य के पीछे की कार्यप्रणाली की परवाह करता है। दूसरे शब्दों में, इस रणनीति का वास्तविक डिस्टिलेशन लक्ष्य पाठ नहीं, बल्कि स्वयं ट्रेडिंग ज्ञान है। यह उस व्यक्तिपरक अनुभव को, जो पहले मनुष्यों पर निर्भर था, प्रोग्राम द्वारा पहचाने और कॉल किए जा सकने वाले नियम-आधारित क्षमताओं में अनुवादित करने का प्रयास करता है। यह सामान्य भावना मॉडल से इसका सबसे बड़ा अंतर है: यह यह निर्धारित नहीं करता कि बाजार की भावना कितनी गर्म है, बल्कि यह वर्तमान बाजार में विभिन्न ट्रेडिंग फ्रेमवर्क की प्रतिक्रिया के तरीकों का पुनर्निर्माण करता है।
चरण 1: पहले बाजार को राज्य चर में अनुवादित करें
डिस्टिलेशन को वास्तव में लागू करने के लिए, पहला कदम निश्चित रूप से भविष्यवाणी नहीं है, बल्कि फीचर इंजीनियरिंग है। इसका कारण सरल है: ट्रेडर्स की भाषा मनुष्यों को पढ़ने के लिए होती है, प्रोग्राम के लिए नहीं। उदाहरण के लिए, 'कीमत एक महत्वपूर्ण मूविंग एवरेज पर वापस आती है, यह एक अच्छा दूसरा प्रवेश बिंदु है' - यह वाक्य एक ट्रेडर के लिए समझना आसान है, लेकिन प्रोग्राम के लिए, इसे पहले तोड़ना होगा: महत्वपूर्ण मूविंग एवरेज क्या है, 50-दिवसीय या 200-दिवसीय? क्या वर्तमान मूल्य इस मूविंग एवरेज के करीब है? क्या ट्रेंड टूट गया है? क्या कोई समर्थन संकेत है?
इसलिए सिस्टम को पहले क्या करना चाहिए, यह बुलिश या बियरिश निष्कर्ष देना नहीं है, बल्कि कच्चे बाजार डेटा को संरचित राज्यों के एक सेट में परिवर्तित करना है। यहाँ सबसे बुनियादी परत कीमतों का उपयोग करके ट्रेंड और मोमेंटम विशेषताओं का निर्माण करना है। मूविंग एवरेज, एक्सपोनेंशियल मूविंग एवरेज, RSI, MACD जैसे चर संकेतकों को ढेर करने के लिए नहीं हैं, बल्कि एक सरल प्रश्न का उत्तर देने के लिए हैं: बाजार वर्तमान में मोटे तौर पर किस अवस्था में है?

मुख्य कोड इस प्रकार है:
python
# 用不同周期的均线描述价格所处的趋势位置
f['ma20'] = _sma(c,20)
f['ma50'] = _sma(c,50)
f['ma100'] = _sma(c,100)
f['ma200'] = _sma(c,200)
# 指数均线对近期价格变化更敏感
f['ema20'] = _ema(c,20)
f['ema50'] = _ema(c,50)
# RSI 用来描述市场是否进入超买超卖,或者动量是否衰减
f['rsi14'] = _rsi(c,14)
# MACD 及其信号线、柱体,用来观察趋势和动量变化
ml, ms, mh = _macd(c)
f['macd'] = ml
f['macd_sig'] = ms
f['macd_hist'] = mh
यह कोड कुछ जटिल नहीं करता। मूविंग एवरेज सिस्टम को दीर्घकालिक ट्रेंड के सापेक्ष वर्तमान मूल्य की स्थिति निर्धारित करने में मदद करते हैं, जबकि RSI और MACD यह वर्णन करने के लिए उपयोग किए जाते हैं कि मोमेंटम बढ़ रहा है या घट रहा है। यह अभी तक ट्रेडिंग निर्णय में नहीं जाता, बस 'बाजार की स्थिति विवरण' की एक परत स्थापित कर रहा है।
इसके बाद, सिस्टम को वोलैटिलिटी और पोजीशन रिलेशनशिप भी जोड़नी होगी, क्योंकि कई ट्रेडिंग निर्णय केवल ट्रेंड पर निर्भर नहीं करते, बल्कि इस पर भी निर्भर करते हैं कि 'क्या अब वोलैटिलिटी संकुचन अवधि है' और 'क्या कीमत रेंज के उच्च या निम्न के करीब है'।
संबंधित कोड है:
python
# 对数收益率是计算波动率的基础
logr = np.log(c / c.shift(1))
# 近 30 天年化波动率,用来衡量当前市场波动水平
f['rv30'] = logr.rolling(30, min_periods=10).std() * np.sqrt(365)
# 最近 20 天和 50 天的高低点,用来判断价格所处位置
f['high_20d'] = h.rolling(20, min_periods=1).max()
f['low_20d'] = l.rolling(20, min_periods=1).min()
f['high_50d'] = h.rolling(50, min_periods=1).max()
f['low_50d'] = l.rolling(50, min_periods=1).min()
यहाँ rv30 पिछले 30 दिनों की वार्षिक वोलैटिलिटी स्तर को दर्शाता है, जबकि रेंज के उच्च और निम्न बिंदु सिस्टम को यह निर्धारित करने में मदद करते हैं कि वर्तमान मूल्य हाल की मूल्य संरचना में वास्तव में कहाँ स्थित है। इसके अलावा, मैक्रो पृष्ठभूमि को भी राज्य स्थान में शामिल किया गया है। क्योंकि एक प्रकार के ट्रेडर हैं जो केवल क्रिप्टो की कीमत नहीं देखते; वे एक साथ DXY, US इक्विटी रिस्क एपेटाइट और ब्याज दर पर्यावरण का भी निरीक्षण करते हैं। कोड में संबंधित प्रसंस्करण विधि पहले इन चरों को दैनिक आधार पर संरेखित करना है, फिर उन्हें पढ़ने योग्य स्थितियों में बदलना है:
python
# DXY 作为美元强弱的背景变量
if 'DXY' in macro:
dxy = _align(macro['DXY'])
f['dxy_ret_20d'] = dxy.pct_change(20)
f['dxy_trend_down'] = (dxy.pct_change(20) < -0.01).astype(int)
# SPX 作为风险偏好背景变量
if 'SPX' in macro:
spx = _align(macro['SPX'])
f['spx_ret_20d'] = spx.pct_change(20)
f['spx_trend_up'] = (spx.pct_change(20) > 0).astype(int)
इस कदम का महत्व एक वाक्य में संक्षेपित किया जा सकता है: पहले 'बाजार अब कैसा है' को मशीन द्वारा लगातार पढ़ी जा सकने वाली संरचित अवस्थाओं में अनुवादित करें। इस परत के बिना, आगे का डिस्टिलेशन असंभव है।
चरण 2: व्यक्तिपरक अनुभव को क्षमता कारकों में लिखें
केवल विशेषताएँ पर्याप्त नहीं हैं, क्योंकि विशेषताएँ केवल बाजार का वर्णन कर रही हैं, वे सीधे यह व्यक्त नहीं करतीं कि 'इस अवस्था का क्या अर्थ है'। अगले चरण में ट्रेडर्स के अनुभव को नियमों में लिखना होगा, अर्थात वर्तमान राज्य चरों के आधार पर यह निर्धारित करना कि कौन सी ट्रेडिंग क्षमताएँ ट्रिगर हो रही हैं।
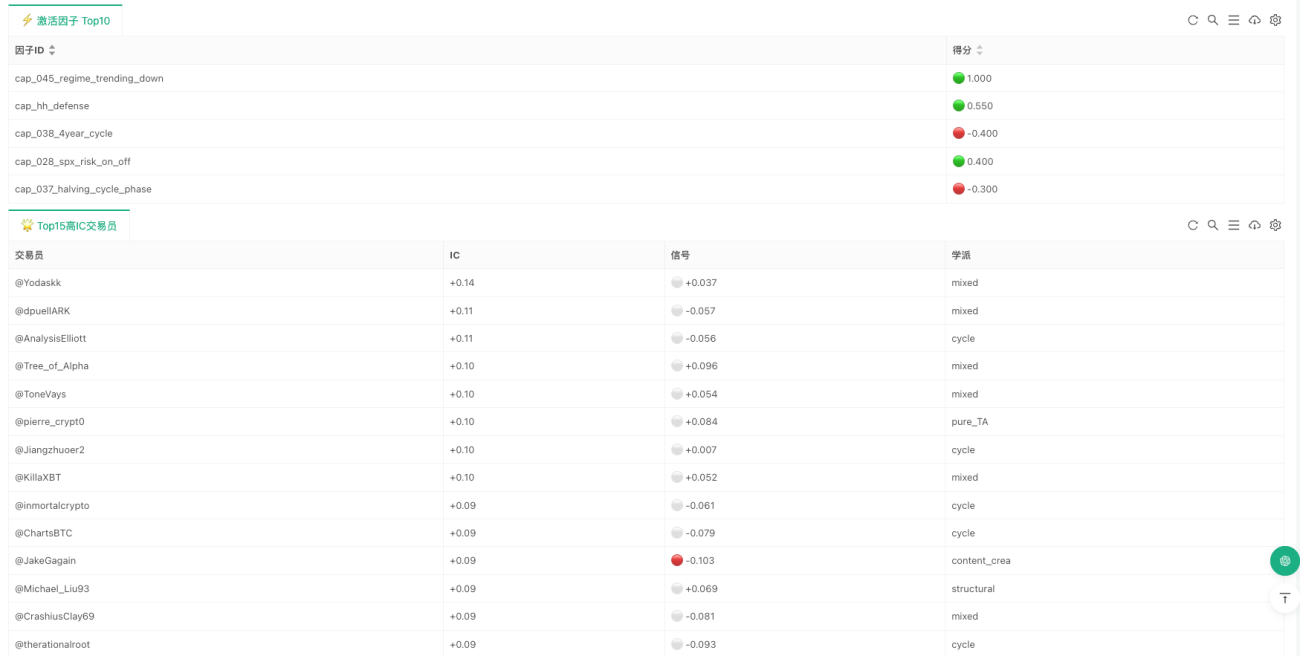
यह कदम पूरी रणनीति में डिस्टिलेशन का सबसे मजबूत हिस्सा है। क्योंकि यहाँ अब दूर से यह नहीं कहा जाता कि 'एक निश्चित ढांचा महत्वपूर्ण है', बल्कि इसे वास्तव में प्रोग्राम शर्तों में लिखा जाता है। वर्तमान कार्यान्वयन में शामिल क्षमता कारक पैटर्न, संरचना, संकेतक, चक्र और मैक्रो स्तरों को कवर करते हैं। उदाहरण के लिए, कुछ क्षमताएँ पैटर्न पहचान से आती हैं, जैसे बुल फ्लैग, बियर फ्लैग, डबल टॉप/बॉटम, हेड एंड शोल्डर्स, त्रिकोण; कुछ संरचनात्मक विश्लेषण से आती हैं, जैसे विकॉफ, SMC, ICT फ्रेमवर्क; कुछ स्वयं संकेतकों से आती हैं, जैसे RSI डाइवर्जेंस, मूविंग एवरेज गोल्डन/डेथ क्रॉस, बोलिंजर स्क्वीज़ ब्रेकआउट; और कुछ चक्र और मैक्रो पर्यावरण से आती हैं, जैसे हॉल्विंग चक्र, ट्रेंडिंग और रेंजिंग बाजारों के बीच स्विच, DXY में गिरावट, रिस्क एपेटाइट में वृद्धि आदि।
एक बहुत ही विशिष्ट उदाहरण है 'ट्रेंड पुलबैक कंटिन्यूएशन'। कई ट्रेडर्स का समान अनुभव होता है: यदि बड़ा ट्रेंड अभी भी ऊपर की ओर है, कीमत एक महत्वपूर्ण मूविंग एवरेज पर वापस आती है, और वर्तमान कैंडल में समर्थन दिखता है, तो इसका अक्सर अर्थ होता है कि ट्रेंड जारी रहेगा। प्रोग्राम इसे बहुत सीधे व्यक्त करता है:
python
# 判断当前价格是否接近 50 日均线
near_ma50 = abs(close - ma50_v) / close < 0.02 if close > 0 else False
# 如果 50 日均线仍在 200 日均线上方,且回踩均线后出现阳线承接
# 则记为一个趋势延续能力信号
s['cap_014_trend_pullback_continuation'] = 0.6 if (ma50_gt and near_ma50 and is_green) else 0.0
यहाँ कोई रहस्यमय बात नहीं है; यह केवल एक मानवीय भाषा को कई ऐसी शर्तों में विभाजित करता है जिन्हें मशीन एक-एक करके जाँच सकती है। एक और उदाहरण है 'बोलिंजर स्क्वीज़ ब्रेकआउट'। कई ट्रेडर्स के लिए, लंबे समय तक वोलैटिलिटी संकुचन के बाद अचानक ऊपर या नीचे की ओर विस्तार का अक्सर अर्थ होता है एक नई दिशा का चुनाव। संबंधित नियम लेखन इस प्रकार है:
python
# 如果前一根 K 线布林带宽度低于压缩阈值,则视为波动收缩
squeezed = bb_w_p1 < bb_w20_p1 if bb_w20_p1 > 0 else False
# 收缩之后向上突破上轨,给正向信号;向下跌破下轨,给负向信号
s['cap_021_bollinger_squeeze_breakout'] = (
0.6 if (squeezed and close > bb_u) else
-0.6 if (squeezed and close < bb_l) else 0.0
)
मैक्रो कारकों का प्रसंस्करण भी ऐसा ही है। एक प्रकार के ट्रेडर जो अधिक मैक्रो-उन्मुख हैं, उनके लिए BTC पूरी तरह से पृथक मूल्य श्रृंखला नहीं है; यह डॉलर, इक्विटी बाजार और ब्याज दर पर्यावरण से प्रभावित होता है, इसलिए इन समझों को भी क्षमता निर्णयों के रूप में लिखा गया है:
python
# DXY में गिरावट को आमतौर पर BTC के लिए सकारात्मक पृष्ठभूमि माना जाता है
s['cap_027_dxy_inverse_btc'] = 0.4 if (not _nm(dxy_r20) and dxy_r20 < -0.01) else 0.0
# S&P में वृद्धि को जोखिम भूख में सुधार के रूप में देखा जा सकता है
s['cap_028_spx_risk_on_off'] = 0.4 if (not _nm(spx_r20) and spx_r20 > 0.02) else 0.0
# अल्पकालिक ब्याज दरों में गिरावट को तरलता में सीमांत सुधार के रूप में देखा जा सकता है
s['cap_029_yields_liquidity'] = 0.4 if (not _nm(y_r20) and y_r20 < -0.02) else 0.0
इस परत में वास्तव में महत्वपूर्ण यह नहीं है कि इसमें कितने नियम लिखे हैं, बल्कि यह है कि इसने आसवन (distillation) का सबसे महत्वपूर्ण कदम पूरा कर लिया है: जो पहले केवल व्यक्तिपरक समझ पर निर्भर था, उसे गणना योग्य शर्तों में संपीड़ित कर दिया गया है। यह भी बताना आवश्यक है कि वर्तमान संस्करण के अधिकांश क्षमता कारक (capability factors) अभी भी शर्त-आधारित ट्रिगर हैं, न कि सतत स्कोरिंग प्रकार। इसका मतलब है कि सिस्टम यह निर्णय करने के लिए अधिक उपयुक्त है कि कोई संरचना मौजूद है या नहीं, बजाय हर छोटे उतार-चढ़ाव पर लगातार पुनर्मूल्यांकन करने के। यही कारण है कि यह वर्तमान में दैनिक या मध्यम-निम्न आवृत्ति के निर्णयों के लिए अधिक उपयुक्त है, न कि उच्च-आवृत्ति ट्रेडिंग के लिए।
तीसरा चरण: कारकों को सीधे जोड़ने के बजाय, पहले उन्हें ट्रेडर्स प्रोफाइल में मैप करें
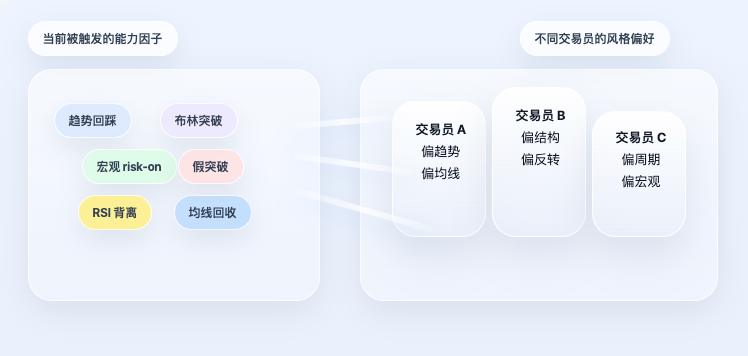
यदि रणनीति केवल कारक स्तर पर रुक जाती है, तो यह अभी भी एक सामान्य नियम-आधारित सिस्टम है। मूल प्रोजेक्ट की विशेष बात यह है कि यह यहाँ नहीं रुका, बल्कि एक कदम और आगे बढ़ गया: कारक सीधे दिशा तय नहीं करते, बल्कि पहले ट्रेडर्स प्रोफाइल में मैप किए जाते हैं।
यह बिंदु अत्यंत महत्वपूर्ण है। क्योंकि वास्तविक दुनिया में ट्रेडर "सभी क्षमताओं का औसत उपयोग" नहीं करते। कुछ ट्रेंड पर ध्यान केंद्रित करते हैं, कुछ संरचना पर, कुछ चक्र पर, कुछ मैक्रो पर। समान बाजार स्थितियों का सामना करने पर भी, अलग-अलग लोगों का ध्यान पूरी तरह से अलग होता है। इसलिए सिस्टम सभी कारकों को आसानी से औसत नहीं करेगा, बल्कि पहले प्रत्येक ट्रेडर की क्षमता वरीयता को पढ़ेगा, और फिर वर्तमान कारक स्थिति के आधार पर उसके लिए व्यक्तिगत सिग्नल की गणना करेगा।
संबंधित प्रोफाइल रीडिंग लॉजिक इस प्रकार है:
python
# प्रत्येक ट्रेडर द्वारा अपने प्रोफाइल में उपयोग किए जाने वाले क्षमता कारकों और उनके भार को पढ़ें
caps = {c['id']: float(c.get('weight', 0.5))
for c in p.get('capabilities_used', [])}
profiles.append({
'handle': p.get('handle', item['name'][:-5]),
'caps': caps
})
प्रत्येक प्रोफाइल मूल रूप से एक प्रश्न का उत्तर देती है: यह ट्रेडर किन क्षमता कारकों पर अधिक निर्भर करता है, और उन क्षमताओं का उनके फ्रेमवर्क में कितना भार है। इस प्रोफाइल के बाद ही सिस्टम वर्तमान बाजार में प्रत्येक ट्रेडर के "व्यक्तिगत सिग्नल" की गणना करता है:
python
for p in profiles:
sig = 0.0
wt = 0.0
# उस ट्रेडर द्वारा देखे जाने वाले सभी क्षमता कारकों पर लूप करें
for cap_id, w in p['caps'].items():
score = factor_scores.get(cap_id, 0.0)
# वर्तमान कारक स्कोर को ट्रेडर के उस कारक के लिए पसंदीदा भार से गुणा करें
sig += w * score
wt += abs(w)
# सामान्यीकरण के बाद वर्तमान बाजार में उस ट्रेडर का व्यक्तिगत सिग्नल प्राप्त करें
trader_raw = sig / wt if wt > 0 else 0.0
यहाँ देखने पर, इस सिस्टम की प्रकृति पहले से काफी अलग लगती है। यह अब केवल यह नहीं देखता कि "कौन से कारक चमक रहे हैं", बल्कि यह एक चीज़ का अनुमान लगा रहा है: यदि आज का बाजार इन 99 ट्रेडरों को सौंप दिया जाए, तो वे प्रत्येक कैसे निर्णय लेंगे।
चौथा चरण: व्यक्तिगत सिग्नल से भारित सहमति तक
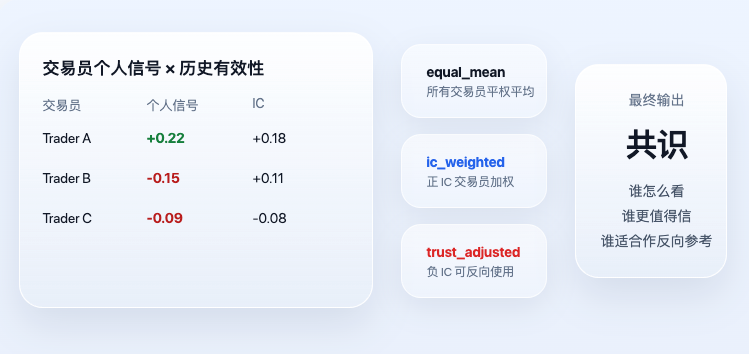
जब प्रत्येक ट्रेडर के व्यक्तिगत सिग्नल की गणना हो जाती है, तब सिस्टम वास्तविक सहमति स्तर में प्रवेश करता है। यहाँ "सहमति" साधारण मतदान नहीं है, न ही यह है कि जिसकी आवाज़ बुलंद हो वही फैसला करे, बल्कि इसमें ऐतिहासिक प्रभावशीलता पर और विचार किया जाता है।
वर्तमान कोड में दो सबसे महत्वपूर्ण परिणाम हैं ic_weighted और trust_adjusted। संबंधित मुख्य लॉजिक है:
python
# पहले सकारात्मक IC वाले ट्रेडरों को सकारात्मक भार देकर ic_weighted प्राप्त करें
pos_w = sum(max(t['ic'], 0) for t in trader_signals)
ic_wt = (
sum(t['signal'] * max(t['ic'], 0) for t in trader_signals) / pos_w
if pos_w > 0 else 0.0
)
# trust_adjusted एक कदम आगे जाता है:
# सकारात्मक IC का उपयोग सीधे किया जाता है, नकारात्मक IC का उल्टा उपयोग किया जाता है, और फिर पूर्ण IC परिमाण के अनुसार भार दिया जाता है
abs_w = sum(abs(t['ic']) for t in trader_signals)
trust = (
sum((t['signal'] if t['ic'] >= 0 else -t['signal']) * abs(t['ic'])
for t in trader_signals) / abs_w
if abs_w > 0 else 0.0
)
यह कोड दो बहुत ही सरल लेकिन महत्वपूर्ण सिद्धांतों को व्यक्त करता है। पहला, जो ट्रेडर ऐतिहासिक रूप से अधिक प्रभावी रहे हैं, उनका आज अधिक भार है। दूसरा, नकारात्मक IC वाले ट्रेडरों को त्यागा नहीं जाता, बल्कि उन्हें एक विपरीत संकेतक के रूप में उपयोग किया जा सकता है। इसलिए, अंतिम आउटपुट trust_adjusted सिर्फ "सब क्या सोचते हैं" नहीं है, बल्कि "कौन क्या सोचता है, और कौन अधिक विश्वसनीय है" है।
यही कारण है कि यह सिस्टम सामान्य भावना मॉडल से अलग है। यह रायों की संख्या नहीं गिन रहा, बल्कि ऐतिहासिक परीक्षण के साथ संज्ञानात्मक एकत्रीकरण कर रहा है। यदि पूरी विधि को एक वाक्य में संक्षेपित किया जाए, तो यह है: पहले बाजार को स्थिति चर में बदलें, फिर स्थिति चर को क्षमता कारकों में मैप करें, फिर क्षमता कारकों को ट्रेडर के व्यक्तिगत सिग्नल में मैप करें, और अंत में इन व्यक्तिगत सिग्नलों को ऐतिहासिक प्रभावशीलता के अनुसार एक सहमति निर्णय में एकत्रित करें।
FMZ (发明者) पर कार्यान्वयन: वास्तव में क्या काम कर गया
यदि यह केवल एक शोध परियोजना में रहता, तो यह सिस्टम एक "सहमति विश्लेषक" जैसा अधिक होता। FMZ पर कार्यान्वयन का मुख्य फोकस पूरी श्रृंखला को वास्तव में जोड़ना है, ताकि यह निरंतर चल सके। सबसे मुख्य कोड वास्तव में केवल तीन पंक्तियाँ हैं:
python
# पहला कदम: कच्चे बाजार डेटा और मैक्रो वेरिएबल को संरचित स्थिति में बदलें
feat_df = build_features(records, macro if macro else None)
# दूसरा कदम: स्थिति चर के आधार पर मूल्यांकन करें कि वर्तमान में कौन से क्षमता कारक सक्रिय हुए हैं
factor_scores = evaluate_factors(feat_df)
# तीसरा कदम: क्षमता कारकों को ट्रेडर्स प्रोफाइल में मैप करें और उन्हें एक सहमति परिणाम में एकत्रित करें
consensus = compute_consensus(factor_scores)
ये तीन पंक्तियाँ लगभग पूरी रणनीति की तीन सबसे महत्वपूर्ण अमूर्तन परतें हैं। पहली परत बाजार की स्थिति के लिए, दूसरी परत क्षमता निर्णय के लिए, और तीसरी परत ट्रेडर सहमति के लिए है। इनके पीछे निश्चित रूप से निष्पादन परत, जोखिम नियंत्रण परत और स्थिति प्रदर्शन भी हैं, लेकिन शोध तर्क के नजरिए से, सबसे महत्वपूर्ण हिस्सा पूरी तरह से स्थापित हो चुका है। दूसरे शब्दों में, इस कार्यान्वयन का सबसे महत्वपूर्ण महत्व यह नहीं है कि इसमें कितने अधिक चलाने का विवरण है, बल्कि यह है कि मूल प्रोजेक्ट में क्षमता प्रोफाइल अब केवल स्थैतिक फाइलें नहीं हैं, कारक अब केवल शोध आउटपुट नहीं हैं, और सहमति अब केवल रिपोर्ट में एक संख्या नहीं है; वे सभी एक निरंतर चलने वाली निर्णय प्रक्रिया में जुड़ गए हैं।
यह अभी भी एक प्रोटोटाइप क्यों है
बेशक, यह कार्यान्वयन अंतिम नहीं है। वर्तमान कोड BTC दैनिक फ्रेम का उपयोग करता है, इसलिए यह उच्च-आवृत्ति ट्रेडिंग सिस्टम के बजाय मध्यम-निम्न आवृत्ति सहमति निर्णयों के लिए अधिक उपयुक्त है। इसका मूल अभी भी दैनिक संरचना, चक्र स्थिति, मैक्रो पृष्ठभूमि और ट्रेडर की क्षमता वरीयता के आसपास घूमता है। इसके अलावा, ट्रेडर प्रोफाइल और IC अभी भी स्थैतिक इनपुट हैं और अभी तक ऑनलाइन विकास चरण में प्रवेश नहीं किया है। दूसरे शब्दों में, सिस्टम ने "ज्ञान आसवन" का पहला कदम पूरा कर लिया है, लेकिन अभी तक "आसवित ज्ञान का स्व-सुधार" पूरी तरह से नहीं किया है।
लेकिन यह इस तथ्य को प्रभावित नहीं करता है कि इसने पहले ही एक बहुत ही महत्वपूर्ण बात साबित कर दी है: ट्रेडर अनुभव को परत दर परत संपीड़ित, संरचित और वास्तव में रणनीति श्रृंखला में प्रवेश कराया जा सकता है। इसका मूल्य यह नहीं है कि इसने पहले से ही स्थिर लाभ उत्पन्न किया है, बल्कि यह है कि इसने एक शोध पथ को, जो मूल रूप से केवल अवधारणात्मक स्तर पर था, एक चलने योग्य चरण में आगे बढ़ाया है। जहाँ तक इस बात का सवाल है कि ये क्षमता कारक कैसे विकसित होंगे, ट्रेडर भार कैसे अपडेट होंगे, और वास्तविक बाजार में सहमति को कैसे लगातार ठीक किया जाएगा, इन सवालों के जवाब देने के लिए अभी भी अधिक चलाने के डेटा की आवश्यकता है।
निष्कर्ष
crypto-kol-quant की वास्तविक प्रेरणा इस बात में नहीं है कि इसने कितनी लोकप्रिय अवधारणाओं का उपयोग किया है, बल्कि इस बात में है कि इसने एक ऐसी चीज़ को, जिसे व्यवस्थित करना बहुत कठिन है, वास्तव में एक कदम आगे बढ़ाया है: ट्रेडर के अनुभव को, अभिव्यक्ति से क्षमता में, क्षमता से कारक में, और कारक से सहमति में बदल दिया। और FMZ पर यह कार्यान्वयन, वही कर रहा है जो इस आसवन श्रृंखला को वास्तव में चलाने योग्य बनाता है। यह अतिशयोक्ति नहीं करता कि यह पहले से ही अंतिम है, न ही यह इस तथ्य को छिपाने की कोशिश करता है कि यह अभी भी एक प्रारंभिक प्रोटोटाइप है। लेकिन इसने कम से कम यह साबित कर दिया है कि ट्रेडिंग अनुभव केवल चार्ट और भाषा तक सीमित नहीं रहना चाहिए; इसे आसवित, संरचित, चलाया जा सकता है, और यहां तक कि एक ऐसी प्रणाली में रखा जा सकता है जो लगातार बाजार का न्याय करती है।
यदि पारंपरिक मात्रात्मक विश्लेषण मूल्य श्रृंखलाओं से पैटर्न निकालने में माहिर है, तो इस प्रकार की रणनीति का वास्तव में आगे बढ़ने लायक दिशा शायद यह हो सकती है: मानव संज्ञान से पैटर्न निकालना, और फिर उन पैटर्न को बाजार में भाग लेने देना। और यही वह चीज़ हो सकती है जो रणनीति अनुसंधान में "आसवन" के बारे में सबसे उल्लेखनीय है।
मूल प्रोजेक्ट: 锁妖塔 Skill — 炼化99个加密交易员
विशेष रूप से उपयोगकर्ता "GiantBin" को उनके विचारों और सुझावों के लिए धन्यवाद। यदि किसी के पास अच्छे विचार और सुझाव हैं, तो कृपया साझा करें और चर्चा करें।
- 1