

1. संक्षिप्त परिचय
हाल के वर्षों में डीप न्यूरल नेटवर्क तेजी से लोकप्रिय हो गए हैं, जो कई क्षेत्रों में पहले से न सुलझने वाली समस्याओं को हल कर रहे हैं और अपनी शक्तिशाली क्षमताओं का प्रदर्शन कर रहे हैं। समय श्रृंखला की भविष्यवाणी में, आमतौर पर इस्तेमाल किया जाने वाला तंत्रिका नेटवर्क मूल्य RNN है, क्योंकि RNN में न केवल वर्तमान डेटा इनपुट होता है, बल्कि ऐतिहासिक डेटा इनपुट भी होता है। बेशक, जब हम RNN द्वारा कीमतों की भविष्यवाणी करने की बात करते हैं, तो हम अक्सर RNN के एक प्रकार के बारे में बात करते हैं : एलएसटीएम . यह आलेख पाइटॉर्च के आधार पर बिटकॉइन की कीमतों की भविष्यवाणी करने के लिए एक मॉडल का निर्माण करेगा। हालाँकि इंटरनेट पर बहुत सारी प्रासंगिक जानकारी है, फिर भी यह पूरी तरह से पर्याप्त नहीं है, और अपेक्षाकृत कम लोग पाइटोरच का उपयोग कर रहे हैं। एक लेख लिखना अभी भी आवश्यक है। अंतिम परिणाम उद्घाटन मूल्य, समापन मूल्य का उपयोग करना है, बिटकॉइन बाजार की उच्चतम कीमत, निम्नतम कीमत और लेनदेन की मात्रा। अगले समापन मूल्य की भविष्यवाणी करने के लिए। तंत्रिका नेटवर्क के बारे में मेरा व्यक्तिगत ज्ञान औसत है, और मैं आपकी आलोचना और सुधार का स्वागत करता हूँ।
यह ट्यूटोरियल FMZ द्वारा निर्मित है, जो डिजिटल मुद्रा मात्रात्मक ट्रेडिंग प्लेटफ़ॉर्म (www.fmz.com) का आविष्कारक है। QQ समूह में शामिल होने के लिए आपका स्वागत है: संचार के लिए 863946592।
2. डेटा और संदर्भ
संबंधित मूल्य पूर्वानुमान उदाहरण: https://yq.aliyun.com/articles/538484
RNN मॉडल का विस्तृत परिचय: https://zhuanlan.zhihu.com/p/27485750
RNN के इनपुट और आउटपुट को समझना: https://www.zhihu.com/question/41949741/answer/318771336
pytorch के बारे में: आधिकारिक दस्तावेज https://pytorch.org/docs अन्य जानकारी के लिए स्वयं खोजें।
इसके अलावा, इस लेख को समझने के लिए कुछ पूर्वापेक्षित ज्ञान की आवश्यकता है, जैसे कि पांडा / क्रॉलर / डेटा प्रोसेसिंग, आदि, लेकिन अगर आप इसे नहीं जानते हैं तो कोई बात नहीं।
3. पाइटॉर्च एलएसटीएम मॉडल के पैरामीटर
एलएसटीएम के पैरामीटर:
जब मैंने पहली बार दस्तावेज़ पर इन सघन मापदंडों को देखा, तो मेरी प्रतिक्रिया थी:

धीरे-धीरे पढ़ते हुए अंततः मुझे यह बात समझ में आ गयी।

input_size: इनपुट वेक्टर x का फ़ीचर आकार। यदि समापन मूल्य का पूर्वानुमान लगाने के लिए समापन मूल्य का उपयोग किया जाता है, तो input_size=1; यदि समापन मूल्य का पूर्वानुमान उच्च खुलने और निम्न समापन द्वारा लगाया जाता है, तो input_size=4
hidden_size: छिपी परत का आकार
num_layers: RNN की परतों की संख्या
batch_first: यदि सत्य है, तो पहला इनपुट आयाम बैच_साइज़ है। यह पैरामीटर भी बहुत भ्रामक है और इसे नीचे विस्तार से वर्णित किया जाएगा।
इनपुट डेटा पैरामीटर:
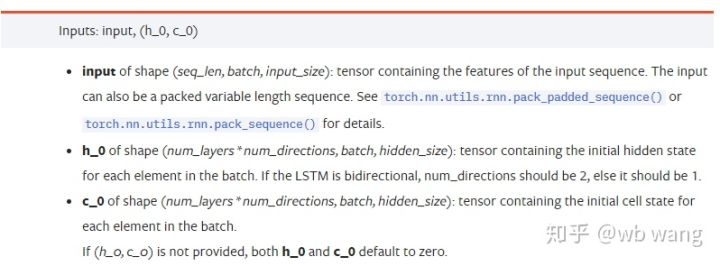
inputविशिष्ट इनपुट डेटा एक त्रि-आयामी टेंसर है जिसका विशिष्ट आकार (seq_len, batch, input_size) है। उनमें से, seq_len अनुक्रम की लंबाई को संदर्भित करता है, अर्थात, LSTM को कितने समय तक ऐतिहासिक डेटा पर विचार करने की आवश्यकता है। ध्यान दें कि यह केवल डेटा के प्रारूप को संदर्भित करता है, LSTM की आंतरिक संरचना को नहीं। वही LSTM मॉडल अलग-अलग seq_len के साथ इनपुट डेटा और पूर्वानुमान दे सकते हैं। परिणाम; बैच बैच आकार को संदर्भित करता है, जो दर्शाता है कि डेटा के कितने अलग-अलग समूह हैं; input_size पिछले input_size है।
h_0: प्रारंभिक छिपी हुई स्थिति, आकार (num_layers * num_directions, बैच, hidden_size) है, यदि यह एक द्विदिश नेटवर्क है num_directions=2
c_0: प्रारंभिक सेल स्थिति, आकार ऊपर के समान है, अनिर्दिष्ट छोड़ा जा सकता है।
आउटपुट पैरामीटर:
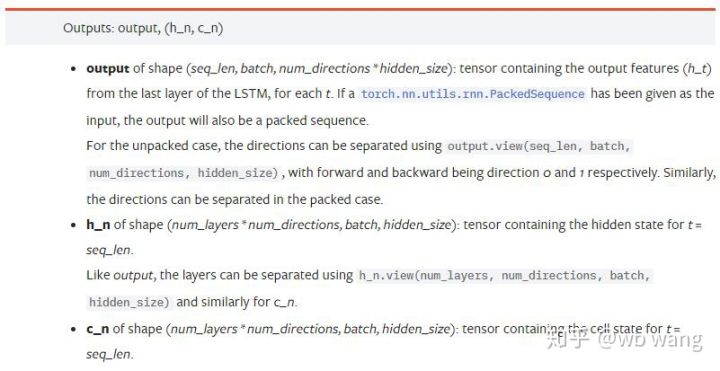
output: आउटपुट आकार (seq_len, बैच, num_directions * hidden_size), ध्यान दें कि यह मॉडल पैरामीटर batch_first से संबंधित है
h_n: समय t पर h स्थिति = seq_len, h_0 के समान आकार
c_n: समय t पर c अवस्था = seq_len, c_0 के समान आकार
4. एलएसटीएम इनपुट और आउटपुट का सरल उदाहरण
सबसे पहले आवश्यक पैकेज आयात करें
python
import pandas as pd
import numpy as np
import torch
import torch.nn as nn
import matplotlib.pyplot as plt
एलएसटीएम मॉडल को परिभाषित करना
python
LSTM = nn.LSTM(input_size=5, hidden_size=10, num_layers=2, batch_first=True)
इनपुट डेटा तैयार करना
python
x = torch.randn(3,4,5)
# x的值为:
tensor([[[ 0.4657, 1.4398, -0.3479, 0.2685, 1.6903],
[ 1.0738, 0.6283, -1.3682, -0.1002, -1.7200],
[ 0.2836, 0.3013, -0.3373, -0.3271, 0.0375],
[-0.8852, 1.8098, -1.7099, -0.5992, -0.1143]],
[[ 0.6970, 0.6124, -0.1679, 0.8537, -0.1116],
[ 0.1997, -0.1041, -0.4871, 0.8724, 1.2750],
[ 1.9647, -0.3489, 0.7340, 1.3713, 0.3762],
[ 0.4603, -1.6203, -0.6294, -0.1459, -0.0317]],
[[-0.5309, 0.1540, -0.4613, -0.6425, -0.1957],
[-1.9796, -0.1186, -0.2930, -0.2619, -0.4039],
[-0.4453, 0.1987, -1.0775, 1.3212, 1.3577],
[-0.5488, 0.6669, -0.2151, 0.9337, -1.1805]]])
x का आकार (3,4,5) है, क्योंकि हमने परिभाषित किया हैbatch_first=Trueइस समय, बैच_साइज़ 3 है, sqe_len 4 है, और इनपुट_साइज़ 5 है। एक्स[0] प्रथम बैच को दर्शाता है।
यदि batch_first परिभाषित नहीं है, तो यह डिफ़ॉल्ट रूप से False होता है, और डेटा को पूरी तरह से अलग तरीके से दर्शाया जाता है, जिसमें बैच आकार 4, sqe_len 3, और input_size 5 होता है। इस समय x[0] t=0 पर सभी बैचों के डेटा को दर्शाता है, इत्यादि। मुझे व्यक्तिगत रूप से लगता है कि यह सेटिंग सहज नहीं है, इसलिए मैंने पैरामीटर जोड़ाbatch_first=True.
दोनों के बीच डेटा का रूपांतरण भी बहुत सुविधाजनक है:x.permute(1,0,2)
इनपुट और आउटपुट
एलएसटीएम इनपुट और आउटपुट के आकार को लेकर भ्रमित होना आसान है, इसे समझने के लिए निम्नलिखित चित्र की सहायता ली जा सकती है:
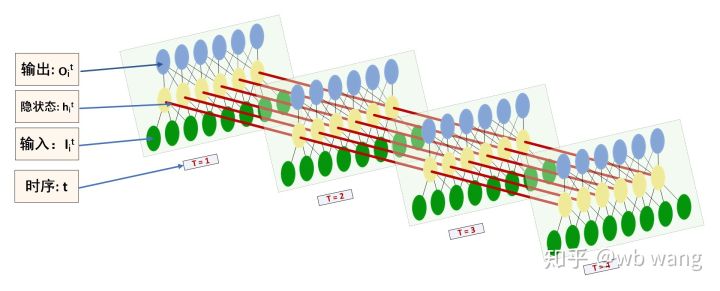
स्रोत: https://www.zhihu.com/question/41949741/answer/318771336
python
x = torch.randn(3,4,5)
h0 = torch.randn(2, 3, 10)
c0 = torch.randn(2, 3, 10)
output, (hn, cn) = LSTM(x, (h0, c0))
print(output.size()) #在这里思考一下,如果batch_first=False输出的大小会是多少?
print(hn.size())
print(cn.size())
#结果
torch.Size([3, 4, 10])
torch.Size([2, 3, 10])
torch.Size([2, 3, 10])
आउटपुट परिणामों का अवलोकन करें, जो पिछले पैरामीटर स्पष्टीकरण के अनुरूप हैं। ध्यान दें कि hn.size() का दूसरा मान 3 है, जो batch_size के आकार के अनुरूप है, जो यह दर्शाता है कि hn में कोई मध्यवर्ती स्थिति सहेजी नहीं गई है, केवल अंतिम चरण सहेजा गया है।
चूँकि हमारे LSTM नेटवर्क में दो परतें हैं, hn की अंतिम परत का आउटपुट वास्तव में आउटपुट का मान है, और आउटपुट का आकार है[3, 4, 10], सभी क्षणों t=0,1,2,3 के परिणामों को सहेजता है, इसलिए:
python
hn[-1][0] == output[0][-1] #第一个batch在hn最后一层的输出等于第一个batch在t=3时output的结果
hn[-1][1] == output[1][-1]
hn[-1][2] == output[2][-1]
5. बिटकॉइन बाज़ार डेटा तैयार करें
मैंने पहले जो कुछ भी कहा है, वह सिर्फ़ एक प्रस्तावना है। LSTM के इनपुट और आउटपुट को समझना बहुत ज़रूरी है। अन्यथा, अगर आप इंटरनेट से कुछ कोड बेतरतीब ढंग से कॉपी करते हैं, तो गलतियाँ करना आसान है। की शक्तिशाली क्षमता के कारण समय श्रृंखला में LSTM, भले ही मॉडल गलत हो, आप अंत में इसे प्राप्त कर सकते हैं। अच्छे परिणाम।
आंकड़ा अधिग्रहण
उपयोग किया गया डेटा बिटफिनेक्स एक्सचेंज के BTC_USD ट्रेडिंग जोड़े का बाजार डेटा है।
python
import requests
import json
resp = requests.get('https://q.fmz.com/chart/history?symbol=bitfinex.btc_usd&resolution=15&from=0&to=0&from=1525622626&to=1562658565')
data = resp.json()
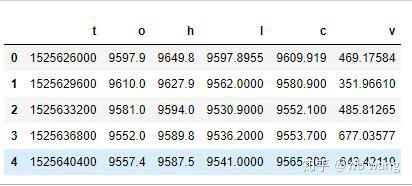
df = pd.DataFrame(data,columns = ['t','o','h','l','c','v'])
print(df.head(5))
डेटा का प्रारूप इस प्रकार है:
डेटा प्रीप्रोसेसिंग
python
df.index = df['t'] # index设为时间戳
df = (df-df.mean())/df.std() # 数据的标准化,否则模型的Loss会非常大,不利于收敛
df['n'] = df['c'].shift(-1) # n为下一个周期的收盘价,是我们预测的目标
df = df.dropna()
df = df.astype(np.float32) # 改变下数据格式适应pytorch
डेटा मानकीकरण की विधि बहुत कठिन है और इसमें कुछ समस्याएं होंगी। यह सिर्फ प्रदर्शन के लिए है। आप उपज जैसे डेटा मानकीकरण का उपयोग कर सकते हैं।
प्रशिक्षण डेटा तैयार करना
python
seq_len = 10 # 输入10个周期的数据
train_size = 800 # 训练集batch_size
def create_dataset(data, seq_len):
dataX, dataY=[], []
for i in range(0,len(data)-seq_len, seq_len):
dataX.append(data[['o','h','l','c','v']][i:i+seq_len].values)
dataY.append(data['n'][i:i+seq_len].values)
return np.array(dataX), np.array(dataY)
data_X, data_Y = create_dataset(df, seq_len)
train_x = torch.from_numpy(data_X[:train_size].reshape(-1,seq_len,5)) #变化形状,-1代表的值会自动计算
train_y = torch.from_numpy(data_Y[:train_size].reshape(-1,seq_len,1))
train_x और train_y के अंतिम आकार हैं: torch.Size([800, 10, 5]), torch.Size([800, 10, 1]). चूंकि हमारा मॉडल 10 अवधियों के डेटा के आधार पर अगली अवधि के समापन मूल्य की भविष्यवाणी करता है, इसलिए सैद्धांतिक रूप से, 800 बैचों के लिए केवल 800 पूर्वानुमानित समापन मूल्यों की आवश्यकता होती है। लेकिन train_y में प्रत्येक बैच में 10 डेटा होते हैं। वास्तव में, प्रत्येक बैच भविष्यवाणी के मध्यवर्ती परिणाम बनाए रखे जाते हैं, न कि केवल अंतिम परिणाम। अंतिम हानि की गणना करते समय, सभी 10 पूर्वानुमान परिणामों को ध्यान में रखा जा सकता है और train_y में वास्तविक मूल्यों के साथ तुलना की जा सकती है। सैद्धांतिक रूप से, केवल अंतिम पूर्वानुमान परिणाम की हानि की गणना करना भी संभव है। मैंने इस समस्या को स्पष्ट करने के लिए एक मोटा चित्र बनाया। चूंकि LSTM मॉडल में वास्तव में seq_len पैरामीटर शामिल नहीं है, इसलिए मॉडल को विभिन्न लंबाइयों पर लागू किया जा सकता है, और मध्यवर्ती भविष्यवाणी परिणाम भी सार्थक हैं, इसलिए मैं हानि की गणना को मर्ज कर देता हूं।
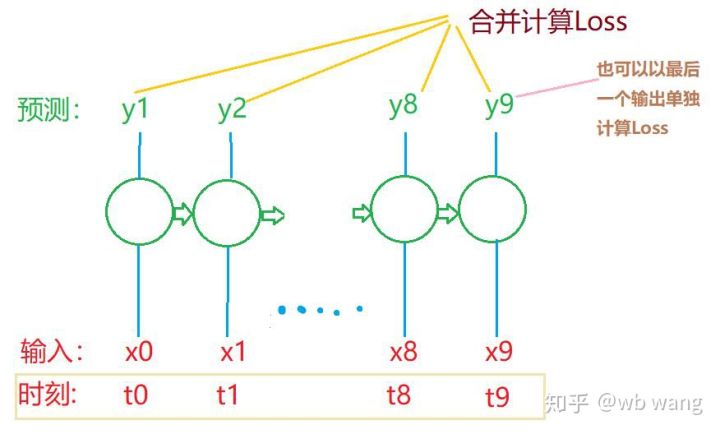
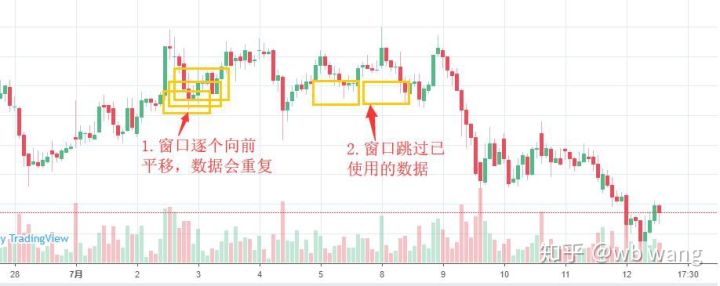
ध्यान दें कि प्रशिक्षण डेटा तैयार करते समय, विंडो की गति उछलती है, और उपयोग किया गया डेटा अब उपयोग नहीं किया जाता है। बेशक, विंडो को एक-एक करके भी स्थानांतरित किया जा सकता है, ताकि प्राप्त प्रशिक्षण सेट बहुत बड़ा हो . लेकिन मुझे लगा कि आसन्न बैच डेटा बहुत दोहराव वाला था, इसलिए मैंने वर्तमान पद्धति को अपनाया।
6. एलएसटीएम मॉडल का निर्माण
अंतिम मॉडल इस प्रकार है, जिसमें दो-परत LSTM और एक रैखिक परत शामिल है।
python
class LSTM(nn.Module):
def __init__(self, input_size, hidden_size, output_size=1, num_layers=2):
super(LSTM, self).__init__()
self.rnn = nn.LSTM(input_size,hidden_size,num_layers,batch_first=True)
self.reg = nn.Linear(hidden_size,output_size) # 线性层,把LSTM的结果输出成一个值
def forward(self, x):
x, _ = self.rnn(x) # 如果不理解前向传播中数据维度的变化,可单独调试
x = self.reg(x)
return x
net = LSTM(5, 10) # input_size为5,代表了高开低收和交易量. 隐含层为10.
7. मॉडल का प्रशिक्षण शुरू करें
अंततः प्रशिक्षण शुरू हुआ, कोड इस प्रकार है:
python
criterion = nn.MSELoss() # 使用了简单的均方差损失函数
optimizer = torch.optim.Adam(net.parameters(),lr=0.01) # 优化函数,lr可调
for epoch in range(600): # 由于速度很快,这里的epoch多一些
out = net(train_x) # 由于数据量很小, 直接拿全量数据计算
loss = criterion(out, train_y)
optimizer.zero_grad()
loss.backward() # 反向传播损失
optimizer.step() # 更新参数
print('Epoch: {:<3}, Loss:{:.6f}'.format(epoch+1, loss.item()))
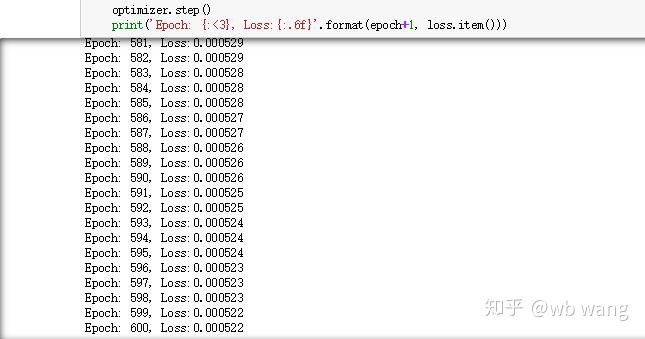
प्रशिक्षण के परिणाम इस प्रकार हैं:
8. मॉडल मूल्यांकन
मॉडल के अनुमानित मान हैं:
python
p = net(torch.from_numpy(data_X))[:,-1,0] # 这里只取最后一个预测值作为比较
plt.figure(figsize=(12,8))
plt.plot(p.data.numpy(), label= 'predict')
plt.plot(data_Y[:,-1], label = 'real')
plt.legend()
plt.show()
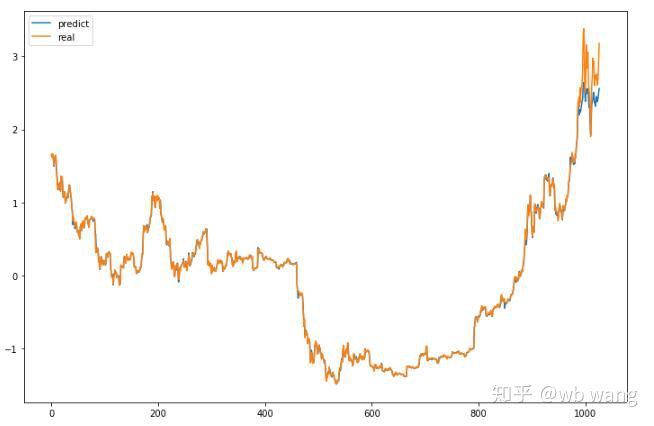
जैसा कि आंकड़े से देखा जा सकता है, प्रशिक्षण डेटा (800 से पहले) की फिट की डिग्री बहुत अधिक है, लेकिन बिटकॉइन की कीमत बाद में एक नए उच्च स्तर पर पहुंच गई है, और मॉडल ने इन आंकड़ों को नहीं देखा है, इसलिए भविष्यवाणी है अच्छा प्रदर्शन करने में असमर्थ. इससे यह भी पता चलता है कि पिछले डेटा मानकीकरण में भी समस्या थी।
हालाँकि अनुमानित कीमत सटीक नहीं हो सकती है, लेकिन वृद्धि और गिरावट की भविष्यवाणी कितनी सटीक है? पूर्वानुमान डेटा के एक भाग पर नज़र डालें:
python
r = data_Y[:,-1][800:1000]
y = p.data.numpy()[800:1000]
r_change = np.array([1 if i > 0 else 0 for i in r[1:200] - r[:199]])
y_change = np.array([1 if i > 0 else 0 for i in y[1:200] - r[:199]])
print((r_change == y_change).sum()/float(len(r_change)))
वृद्धि और गिरावट की भविष्यवाणी की सटीकता 81.4% तक पहुंच गई, जो मेरी उम्मीदों से अधिक थी। मुझे नहीं मालूम कि मैंने कहीं कोई गलती की है या नहीं।
बेशक, इस मॉडल का कोई वास्तविक मूल्य नहीं है, लेकिन यह सरल और समझने में आसान है। बस इसे शुरुआती बिंदु के रूप में उपयोग करें। डिजिटल मुद्रा परिमाणीकरण में तंत्रिका नेटवर्क के अनुप्रयोग पर अधिक परिचयात्मक पाठ्यक्रम होंगे।


