एक बिटकॉइन ट्रेडिंग रोबोट बनाएं जो पैसा नहीं खोएगा
लेखक:लिडिया, बनाया गयाः 2023-02-01 11:52:21, अद्यतन किया गयाः 2023-09-18 19:40:25
एक बिटकॉइन ट्रेडिंग रोबोट बनाएं जो पैसा नहीं खोएगा
आइए एक डिजिटल मुद्रा व्यापार रोबोट बनाने के लिए एआई में सुदृढीकरण सीखने का उपयोग करें।
इस लेख में, हम एक बिटकॉइन ट्रेडिंग रोबोट बनाने के तरीके सीखने के लिए एक उन्नत सीखने के फ्रेम नंबर बनाएंगे और लागू करेंगे। इस ट्यूटोरियल में, हम ओपनएआई के जिम और स्टैबल-बेसलाइन लाइब्रेरी से पीपीओ रोबोट का उपयोग करेंगे, जो ओपनएआई बेसलाइन लाइब्रेरी की एक शाखा है।
पिछले कुछ वर्षों में डीप लर्निंग के शोधकर्ताओं के लिए ओपनएआई और डीपमाइंड द्वारा प्रदान किए गए ओपन सोर्स सॉफ्टवेयर के लिए बहुत बहुत धन्यवाद। यदि आपने अल्फागो, ओपनएआई फाइव, अल्फास्टार और अन्य प्रौद्योगिकियों के साथ उनकी अद्भुत उपलब्धियों को नहीं देखा है, तो आप पिछले साल अलगाव में रह सकते हैं, लेकिन आपको उन्हें देखना चाहिए।
अल्फास्टार प्रशिक्षण:https://deepmind.com/blog/alphastar-mastering-real-time-strategy-game-starcraft-ii/
हालांकि हम कुछ भी प्रभावशाली नहीं बनाएंगे, लेकिन दैनिक लेनदेन में बिटकॉइन रोबोट का व्यापार करना अभी भी आसान नहीं है।
किसी भी चीज़ में कोई मूल्य नहीं है जो बहुत सरल है।
इसलिए, हमें न केवल खुद को व्यापार करना सीखना चाहिए, बल्कि रोबोटों को भी हमारे लिए व्यापार करने देना चाहिए।
योजना

-
मशीन सीखने के लिए हमारे रोबोट के लिए एक जिम वातावरण बनाएँ
-
एक सरल और सुरुचिपूर्ण दृश्य वातावरण बनाना
-
लाभदायक व्यापारिक रणनीति सीखने के लिए हमारे रोबोट को प्रशिक्षित करें
यदि आप स्क्रैच से जिम वातावरण बनाने के तरीके से परिचित नहीं हैं, या इन वातावरणों के विज़ुअलाइज़ेशन को कैसे प्रस्तुत करें। जारी रखने से पहले, कृपया इस तरह के एक लेख को गूगल करने के लिए स्वतंत्र महसूस करें। ये दो क्रियाएं सबसे नौसिखिया प्रोग्रामर के लिए भी मुश्किल नहीं होंगी।
शुरू करना
इस ट्यूटोरियल में, हम Zielak द्वारा उत्पन्न Kaggle डेटासेट का उपयोग करेंगे. यदि आप स्रोत कोड डाउनलोड करना चाहते हैं, तो यह.csv डेटा फ़ाइल के साथ मेरे Github रिपॉजिटरी में प्रदान किया जाएगा. ठीक है, चलो शुरू करते हैं.
सबसे पहले, सभी आवश्यक पुस्तकालयों का आयात करते हैं. आप लापता हैं किसी भी पुस्तकालयों को स्थापित करने के लिए पाइप का उपयोग करना सुनिश्चित करें.
import gym
import pandas as pd
import numpy as np
from gym import spaces
from sklearn import preprocessing
इसके बाद, चलो पर्यावरण के लिए हमारी कक्षा बनाते हैं। हमें एक पांडा डेटा फ्रेम नंबर और एक वैकल्पिक initial_balance और एक lookback_window_size पास करने की आवश्यकता है, जो प्रत्येक चरण में रोबोट द्वारा देखे गए पिछले समय चरणों की संख्या को इंगित करेगा। हम प्रत्येक लेनदेन के कमीशन को 0.075% तक डिफ़ॉल्ट करते हैं, अर्थात, बिटकॉइन की वर्तमान विनिमय दर, और डिफ़ॉल्ट रूप से सीरियल पैरामीटर को गलत करते हैं, जिसका अर्थ है कि हमारे डेटा फ्रेम नंबर को डिफ़ॉल्ट रूप से यादृच्छिक टुकड़ों द्वारा पार किया जाएगा।
हम डेटा पर dropna() और reset_index() को भी कॉल करते हैं, पहले NaN मान के साथ पंक्ति हटा दें, और फिर फ्रेम संख्या के सूचकांक को रीसेट करें, क्योंकि हमने डेटा हटा दिया है।
class BitcoinTradingEnv(gym.Env):
"""A Bitcoin trading environment for OpenAI gym"""
metadata = {'render.modes': ['live', 'file', 'none']}
scaler = preprocessing.MinMaxScaler()
viewer = None
def __init__(self, df, lookback_window_size=50,
commission=0.00075,
initial_balance=10000
serial=False):
super(BitcoinTradingEnv, self).__init__()
self.df = df.dropna().reset_index()
self.lookback_window_size = lookback_window_size
self.initial_balance = initial_balance
self.commission = commission
self.serial = serial
# Actions of the format Buy 1/10, Sell 3/10, Hold, etc.
self.action_space = spaces.MultiDiscrete([3, 10])
# Observes the OHCLV values, net worth, and trade history
self.observation_space = spaces.Box(low=0, high=1, shape=(10, lookback_window_size + 1), dtype=np.float16)
हमारी action_space को 3 विकल्पों (खरीद, बेच या पकड़) के समूह के रूप में दर्शाया गया है और 10 राशि (1/10, 2/10, 3/10 आदि) का एक और समूह। जब हम खरीदना चुनते हैं, तो हम BTC की राशि * self.balance word खरीदेंगे। बेचने के लिए, हम BTC की राशि * self.btc_held value बेचेंगे। बेशक, होल्डिंग राशि को अनदेखा करेगी और कुछ नहीं करेगी।
हमारे observation_space को 0 और 1 के बीच सेट एक निरंतर फ्लोटिंग पॉइंट के रूप में परिभाषित किया गया है, और इसका आकार है (10, lookback_window_size+1) । + 1 का उपयोग वर्तमान समय चरण की गणना करने के लिए किया जाता है। विंडो में प्रत्येक समय चरण के लिए, हम OHCLV मान का अवलोकन करेंगे। हमारी शुद्ध संपत्ति हमारे द्वारा खरीदे या बेचे जाने वाले BTC की संख्या और इन BTC पर खर्च या प्राप्त होने वाले डॉलर की कुल राशि के बराबर है।
इसके बाद, हम पर्यावरण को आरंभ करने के लिए रीसेट विधि लिखने की जरूरत है.
def reset(self):
self.balance = self.initial_balance
self.net_worth = self.initial_balance
self.btc_held = 0
self._reset_session()
self.account_history = np.repeat([
[self.net_worth],
[0],
[0],
[0],
[0]
], self.lookback_window_size + 1, axis=1)
self.trades = []
return self._next_observation()
यहाँ हम self._reset_session और self._next_observation का उपयोग करते हैं, जिन्हें हमने अभी तक परिभाषित नहीं किया है। आइए उन्हें पहले परिभाषित करें।
व्यापार सत्र
हमारे वातावरण का एक महत्वपूर्ण हिस्सा ट्रेडिंग सत्रों की अवधारणा है। यदि हम इस रोबोट को बाजार के बाहर तैनात करते हैं, तो हम इसे एक समय में कुछ महीनों से अधिक नहीं चला सकते हैं। इस कारण से, हम self.df में लगातार फ्रेम की संख्या को सीमित करेंगे, जो कि हमारे रोबोट द्वारा एक समय में देखे जाने वाले फ्रेम की संख्या है।
हमारे _reset_session विधि में, हम पहले current_step को 0 पर रीसेट करते हैं. अगला, हम 1 से MAX_TRADING_SESSIONS के बीच एक यादृच्छिक संख्या पर steps_left सेट करेंगे, जिसे हम कार्यक्रम के शीर्ष पर परिभाषित करेंगे.
MAX_TRADING_SESSION = 100000 # ~2 months
अगला, अगर हम लगातार फ्रेम की संख्या को पार करना चाहते हैं, तो हमें इसे फ्रेम की पूरी संख्या को पार करने के लिए सेट करना होगा, अन्यथा हम frame_start को self.df में एक यादृच्छिक बिंदु पर सेट करते हैं और active_df नाम का एक नया डेटा फ्रेम बनाते हैं, जो कि self.df का सिर्फ एक टुकड़ा है और यह frame_start से frame_start + steps_left तक जा रहा है।
def _reset_session(self):
self.current_step = 0
if self.serial:
self.steps_left = len(self.df) - self.lookback_window_size - 1
self.frame_start = self.lookback_window_size
else:
self.steps_left = np.random.randint(1, MAX_TRADING_SESSION)
self.frame_start = np.random.randint(self.lookback_window_size, len(self.df) - self.steps_left)
self.active_df = self.df[self.frame_start - self.lookback_window_size:self.frame_start + self.steps_left]
यादृच्छिक स्लाइस में डेटा फ्रेम की संख्या को पार करने का एक महत्वपूर्ण दुष्प्रभाव यह है कि हमारे रोबोट के पास दीर्घकालिक प्रशिक्षण में उपयोग के लिए अधिक अद्वितीय डेटा होगा। उदाहरण के लिए, यदि हम केवल डेटा फ्रेम की संख्या को सीरियल तरीके से पार करते हैं (यानी, 0 से लेन ((df))), तो हमारे पास केवल डेटा फ्रेम की संख्या के रूप में कई अद्वितीय डेटा बिंदु होंगे। हमारा अवलोकन स्थान केवल प्रत्येक समय चरण में असतत संख्या में राज्यों का उपयोग कर सकता है।
हालांकि, डेटा सेट के स्लाइस को यादृच्छिक रूप से पार करके, हम प्रारंभिक डेटा सेट में प्रत्येक समय चरण के लिए अधिक सार्थक व्यापार परिणामों का एक सेट बना सकते हैं, अर्थात, अधिक अद्वितीय डेटा सेट बनाने के लिए पहले देखे गए व्यापार व्यवहार और मूल्य व्यवहार का संयोजन। मुझे एक उदाहरण देने दें।
जब सीरियल वातावरण को रीसेट करने के बाद समय चरण 10 है, तो हमारा रोबोट हमेशा एक ही समय में डेटा सेट में चलेगा, और प्रत्येक समय चरण के बाद तीन विकल्प हैंः खरीदें, बेचें या रखें। तीन विकल्पों में से प्रत्येक के लिए, आपको एक और विकल्प की आवश्यकता हैः 10%, 20%,... या विशिष्ट कार्यान्वयन राशि का 100%। इसका मतलब है कि हमारा रोबोट किसी भी 103, कुल 1030 मामलों में से 10 राज्यों में से एक का सामना कर सकता है।
अब हमारे यादृच्छिक स्लाइसिंग वातावरण में वापस। जब समय चरण 10 है, तो हमारा रोबोट डेटा फ्रेम की संख्या के भीतर किसी भी len(df) समय चरण में हो सकता है। यह मानते हुए कि प्रत्येक समय चरण के बाद एक ही विकल्प बनाया जाता है, इसका मतलब है कि रोबोट एक ही 10 समय चरणों में किसी भी len(df) की 30 वीं शक्ति की अनूठी स्थिति का अनुभव कर सकता है।
यद्यपि यह बड़े डेटा सेटों के लिए काफी शोर ला सकता है, मेरा मानना है कि रोबोटों को हमारे सीमित डेटा से अधिक सीखने की अनुमति दी जानी चाहिए। हम अभी भी अपने परीक्षण डेटा को एक सीरियल तरीके से ताजा और प्रतीत होता है
एक रोबोट की आंखों से देखा गया
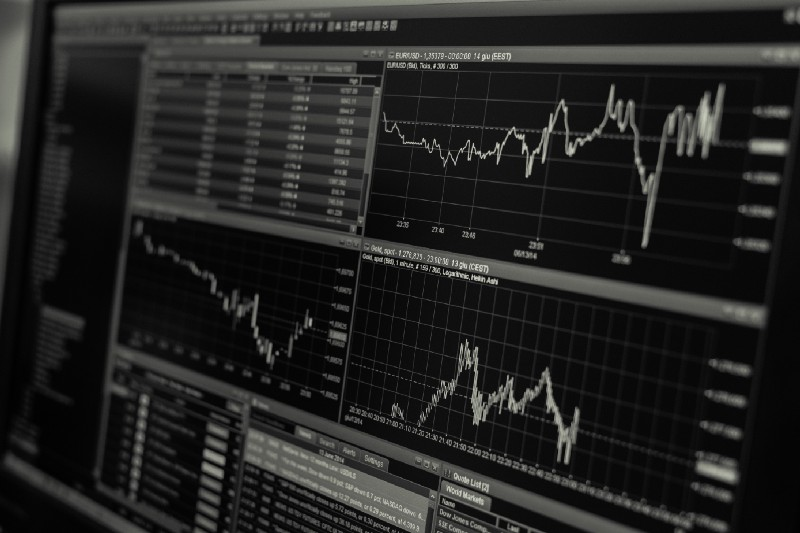
प्रभावी दृश्य पर्यावरण अवलोकन के माध्यम से, यह अक्सर हमारे रोबोट का उपयोग करेगा कि कार्यों के प्रकार को समझने के लिए उपयोगी है। उदाहरण के लिए, यहाँ OpenCV का उपयोग करके प्रस्तुत अवलोकन योग्य अंतरिक्ष की दृश्यता है।
ओपनसीवी विज़ुअलाइज़ेशन वातावरण का अवलोकन
छवि में प्रत्येक पंक्ति हमारे अवलोकन_स्पेस में एक पंक्ति का प्रतिनिधित्व करती है। समान आवृत्तियों वाली लाल रेखाओं की पहली चार पंक्तियां OHCL डेटा का प्रतिनिधित्व करती हैं, और सीधे नीचे नारंगी और पीले डॉट्स ट्रेडिंग वॉल्यूम का प्रतिनिधित्व करते हैं। नीचे उतार-चढ़ाव वाली नीली पट्टी रोबोट के शुद्ध मूल्य का प्रतिनिधित्व करती है, जबकि नीचे हल्का पट्टी रोबोट के लेनदेन का प्रतिनिधित्व करती है।
यदि आप ध्यान से अवलोकन करते हैं, तो आप स्वयं भी एक मोमबत्ती मानचित्र बना सकते हैं। ट्रेडिंग वॉल्यूम बार के नीचे एक मोर्स कोड इंटरफ़ेस है, जो ट्रेडिंग इतिहास प्रदर्शित करता है। ऐसा लगता है कि हमारे रोबोट को हमारे अवलोकन_स्पेस में डेटा से पर्याप्त रूप से सीखने में सक्षम होना चाहिए, इसलिए चलो जारी रखें। यहां हम _next_observation विधि को परिभाषित करेंगे, हम 0 से 1 तक अवलोकन किए गए डेटा को स्केल करते हैं।
- अग्रणी विचलन को रोकने के लिए केवल रोबोट द्वारा अब तक देखे गए आंकड़ों का विस्तार करना महत्वपूर्ण है।
def _next_observation(self):
end = self.current_step + self.lookback_window_size + 1
obs = np.array([
self.active_df['Open'].values[self.current_step:end],
self.active_df['High'].values[self.current_step:end],
self.active_df['Low'].values[self.current_step:end],
self.active_df['Close'].values[self.current_step:end],
self.active_df['Volume_(BTC)'].values[self.current_step:end],])
scaled_history = self.scaler.fit_transform(self.account_history)
obs = np.append(obs, scaled_history[:, -(self.lookback_window_size + 1):], axis=0)
return obs
कार्यवाही करें
हमने अपना अवलोकन स्थान स्थापित कर लिया है, और अब समय आ गया है कि हम अपनी सीढ़ी फ़ंक्शन लिखें, और फिर रोबोट की अनुसूचित कार्रवाई करें। जब भी self.steps_left == 0 हमारे वर्तमान ट्रेडिंग सत्र के लिए, हम अपना BTC बेचेंगे और _reset_session को कॉल करेंगे। अन्यथा, हम वर्तमान शुद्ध मूल्य पर इनाम सेट करेंगे। यदि हम धन से बाहर निकलते हैं, तो हम सही पर सेट करेंगे।
def step(self, action):
current_price = self._get_current_price() + 0.01
self._take_action(action, current_price)
self.steps_left -= 1
self.current_step += 1
if self.steps_left == 0:
self.balance += self.btc_held * current_price
self.btc_held = 0
self._reset_session()
obs = self._next_observation()
reward = self.net_worth
done = self.net_worth <= 0
return obs, reward, done, {}
ट्रेडिंग क्रिया लेना उतना ही सरल है जितना कि वर्तमान_मूल्य प्राप्त करना, निष्पादित करने के लिए क्रियाओं को निर्धारित करना और खरीदने या बेचने के लिए मात्रा। चलो जल्दी से लिखें _take_action ताकि हम अपने वातावरण का परीक्षण कर सकें।
def _take_action(self, action, current_price):
action_type = action[0]
amount = action[1] / 10
btc_bought = 0
btc_sold = 0
cost = 0
sales = 0
if action_type < 1:
btc_bought = self.balance / current_price * amount
cost = btc_bought * current_price * (1 + self.commission)
self.btc_held += btc_bought
self.balance -= cost
elif action_type < 2:
btc_sold = self.btc_held * amount
sales = btc_sold * current_price * (1 - self.commission)
self.btc_held -= btc_sold
self.balance += sales
अंत में, उसी पद्धति से, हम लेनदेन को स्वयं व्यापार से जोड़ेंगे और अपने शुद्ध मूल्य और खाता इतिहास को अपडेट करेंगे।
if btc_sold > 0 or btc_bought > 0:
self.trades.append({
'step': self.frame_start+self.current_step,
'amount': btc_sold if btc_sold > 0 else btc_bought,
'total': sales if btc_sold > 0 else cost,
'type': "sell" if btc_sold > 0 else "buy"
})
self.net_worth = self.balance + self.btc_held * current_price
self.account_history = np.append(self.account_history, [
[self.net_worth],
[btc_bought],
[cost],
[btc_sold],
[sales]
], axis=1)
हमारा रोबोट अब एक नया वातावरण शुरू कर सकता है, धीरे-धीरे पर्यावरण को पूरा कर सकता है, और पर्यावरण को प्रभावित करने वाले कार्य कर सकता है।
हमारे रोबोट व्यापार देखो
हमारी प्रतिपादन विधि प्रिंट (self.net_word) को कॉल करने के रूप में सरल हो सकती है, लेकिन यह पर्याप्त दिलचस्प नहीं है। इसके बजाय, हम एक सरल मोमबत्ती चार्ट तैयार करेंगे, जिसमें ट्रेडिंग वॉल्यूम कॉलम और हमारी शुद्ध संपत्ति का एक अलग चार्ट होता है।
हम कोड में मिल जाएगाStockTrackingGraph.pyआप मेरे Github से कोड प्राप्त कर सकते हैं.
पहला बदलाव हमें self.df ['Date '] को self.df [
from datetime import datetime
सबसे पहले, datetime लाइब्रेरी आयात करें, और फिर हम प्रत्येक टाइमस्टैम्प और strftime से UTC स्ट्रिंग प्राप्त करने के लिए utcfromtimestampmethod का उपयोग करेंगे ताकि इसे स्ट्रिंग के रूप में स्वरूपित किया जा सकेः Y-m-d H:M प्रारूप.
date_labels = np.array([datetime.utcfromtimestamp(x).strftime('%Y-%m-%d %H:%M') for x in self.df['Timestamp'].values[step_range]])
अंत में, हम अपने डेटासेट से मेल खाने के लिए self. df['Volume '] को self. df[
def render(self, mode='human', **kwargs):
if mode == 'human':
if self.viewer == None:
self.viewer = BitcoinTradingGraph(self.df,
kwargs.get('title', None))
self.viewer.render(self.frame_start + self.current_step,
self.net_worth,
self.trades,
window_size=self.lookback_window_size)
अब हम अपने रोबोट को बिटकॉइन का व्यापार करते देख सकते हैं।
Matplotlib के साथ हमारे रोबोट ट्रेडिंग कल्पना करें
हरा फैंटम लेबल बीटीसी की खरीद का प्रतिनिधित्व करता है, और लाल फैंटम लेबल बिक्री का प्रतिनिधित्व करता है। ऊपरी दाएं कोने में सफेद लेबल रोबोट का वर्तमान शुद्ध मूल्य है, और निचले दाएं कोने में लेबल बिटकॉइन की वर्तमान कीमत है। यह सरल और सुरुचिपूर्ण है। अब, यह हमारे रोबोट को प्रशिक्षित करने का समय है और देखें कि हम कितना पैसा कमा सकते हैं!
प्रशिक्षण का समय
पिछले लेख में मुझे मिली आलोचनाओं में से एक क्रॉस-वैलिडेशन की कमी और डेटा को प्रशिक्षण सेट और परीक्षण सेट में विभाजित करने में विफलता थी। इसका उद्देश्य नए डेटा पर अंतिम मॉडल की सटीकता का परीक्षण करना है जो पहले कभी नहीं देखा गया है। हालांकि यह उस लेख का ध्यान केंद्रित नहीं है, यह वास्तव में बहुत महत्वपूर्ण है। क्योंकि हम समय श्रृंखला डेटा का उपयोग करते हैं, हमारे पास क्रॉस वैलिडेशन में बहुत सारे विकल्प नहीं हैं।
उदाहरण के लिए, क्रॉस-वैलिडेशन का एक सामान्य रूप k-fold वैलिडेशन कहा जाता है। इस वैलिडेशन में, आप डेटा को k बराबर समूहों में विभाजित करते हैं, एक-एक करके, व्यक्तिगत रूप से, परीक्षण समूह के रूप में और शेष डेटा का उपयोग प्रशिक्षण समूह के रूप में करते हैं। हालांकि, समय श्रृंखला डेटा समय पर अत्यधिक निर्भर हैं, जिसका अर्थ है कि बाद के डेटा पिछले डेटा पर अत्यधिक निर्भर हैं। इसलिए k-fold काम नहीं करेगा, क्योंकि हमारा रोबोट व्यापार से पहले भविष्य के डेटा से सीखता है, जो एक अनुचित लाभ है।
जब समय श्रृंखला डेटा पर लागू किया जाता है, तो वही दोष अधिकांश अन्य क्रॉस-वैधता रणनीतियों पर लागू होता है। इसलिए, हमें केवल पूर्ण डेटा फ्रेम नंबर के एक हिस्से का उपयोग फ्रेम नंबर से कुछ मनमाने सूचकांक तक प्रशिक्षण सेट के रूप में करने की आवश्यकता है, और शेष डेटा का उपयोग परीक्षण सेट के रूप में करें।
slice_point = int(len(df) - 100000)
train_df = df[:slice_point]
test_df = df[slice_point:]
इसके बाद, चूंकि हमारा वातावरण केवल एक ही संख्या में डेटा फ्रेम को संभालने के लिए सेट किया गया है, हम दो वातावरण बनाएंगे, एक प्रशिक्षण डेटा के लिए और एक परीक्षण डेटा के लिए।
train_env = DummyVecEnv([lambda: BitcoinTradingEnv(train_df, commission=0, serial=False)])
test_env = DummyVecEnv([lambda: BitcoinTradingEnv(test_df, commission=0, serial=True)])
अब, हमारे मॉडल को प्रशिक्षित करना हमारे वातावरण का उपयोग करके एक रोबोट बनाने और model.learn को कॉल करने जितना सरल है।
model = PPO2(MlpPolicy,
train_env,
verbose=1,
tensorboard_log="./tensorboard/")
model.learn(total_timesteps=50000)
यहाँ, हम टेन्सर प्लेटों का उपयोग करते हैं, इसलिए हम अपने टेन्सर प्रवाह चार्ट को आसानी से देख सकते हैं और हमारे रोबोट के बारे में कुछ मात्रात्मक संकेतक देख सकते हैं। उदाहरण के लिए, निम्नलिखित 200,000 से अधिक समय चरणों वाले कई रोबोटों के छूट वाले पुरस्कार चार्ट हैंः
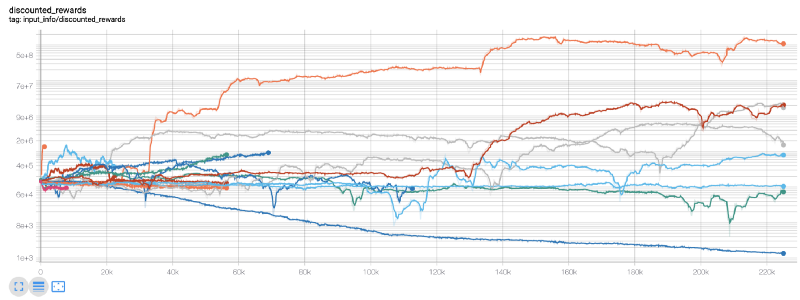
वाह, ऐसा लगता है कि हमारा रोबोट बहुत लाभदायक है! हमारा सबसे अच्छा रोबोट 200,000 चरणों में 1000 गुना संतुलन भी प्राप्त कर सकता है, और बाकी औसतन कम से कम 30 गुना बढ़ जाएगा!
इस समय, मुझे एहसास हुआ कि पर्यावरण में एक गलती थी... बग को ठीक करने के बाद, यह नया इनाम चार्ट हैः
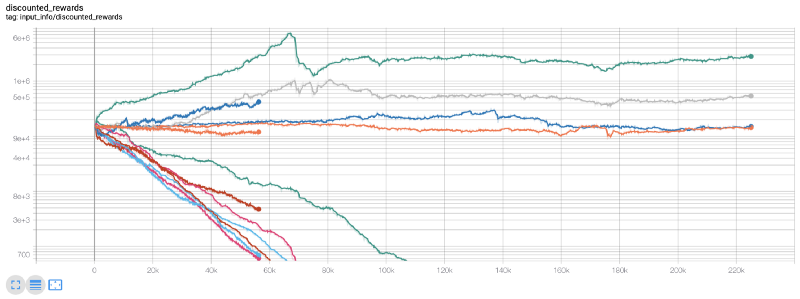
जैसा कि आप देख सकते हैं, हमारे कुछ रोबोट अच्छा कर रहे हैं, जबकि अन्य दिवालिया हो रहे हैं। हालांकि, अच्छे प्रदर्शन वाले रोबोट अधिकतम 10 गुना या 60 गुना प्रारंभिक संतुलन तक पहुंच सकते हैं। मुझे यह स्वीकार करना होगा कि सभी लाभदायक मशीनों को कमीशन के बिना प्रशिक्षित और परीक्षण किया जाता है, इसलिए हमारे रोबोटों के लिए कोई वास्तविक पैसा कमाना अवास्तविक है। लेकिन कम से कम हमने रास्ता ढूंढ लिया है!
आइए हम अपने रोबोटों को परीक्षण वातावरण में परीक्षण करें (नए डेटा का उपयोग करके जिन्हें उन्होंने पहले कभी नहीं देखा है) यह देखने के लिए कि वे कैसे व्यवहार करेंगे।
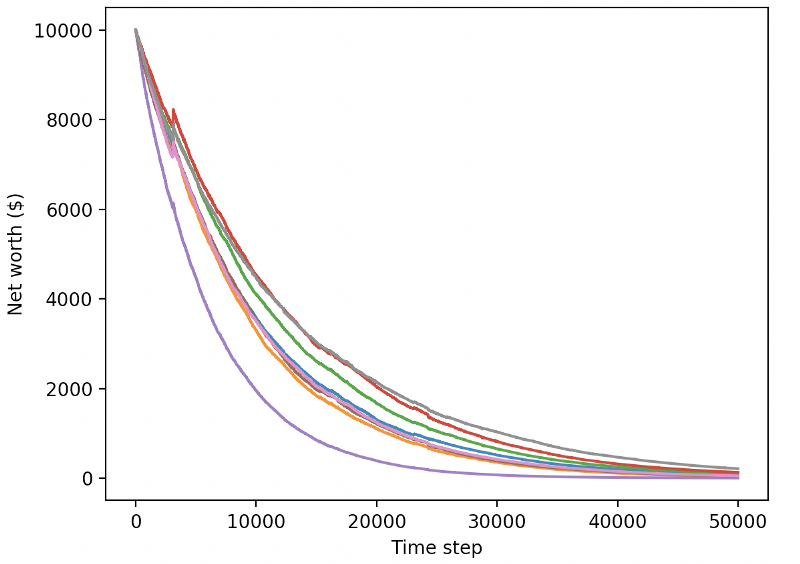
हमारे अच्छी तरह से प्रशिक्षित रोबोट नए परीक्षण डेटा का व्यापार करते समय दिवालिया हो जाएंगे
स्पष्ट रूप से, हमारे पास अभी भी बहुत काम करना है। वर्तमान पीपीओ 2 रोबोट के बजाय स्थिर बेसलाइन के साथ ए 2 सी का उपयोग करने के लिए मॉडल को स्विच करके, हम इस डेटा सेट पर अपने प्रदर्शन में काफी सुधार कर सकते हैं। अंत में, शॉन ओगोरमैन के सुझाव के अनुसार, हम अपने इनाम फ़ंक्शन को थोड़ा अपडेट कर सकते हैं, ताकि हम शुद्ध संपत्ति में इनाम जोड़ सकें, न कि केवल उच्च शुद्ध संपत्ति का एहसास करें और वहां रहें।
reward = self.net_worth - prev_net_worth
ये दो परिवर्तन अकेले परीक्षण डेटासेट के प्रदर्शन में काफी सुधार कर सकते हैं, और जैसा कि आप नीचे देख सकते हैं, हम अंत में नए डेटा पर लाभ उठाने में सक्षम थे जो प्रशिक्षण सेट में उपलब्ध नहीं थे।
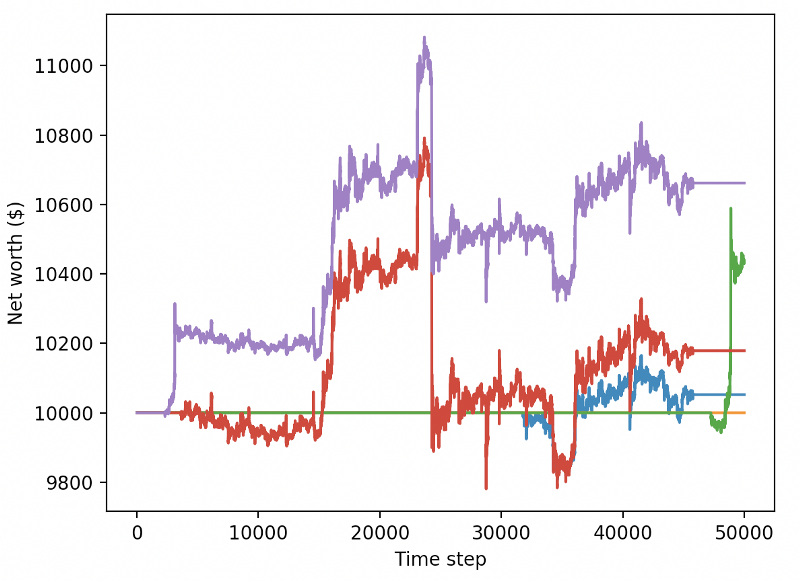
लेकिन हम बेहतर कर सकते हैं। इन परिणामों में सुधार के लिए, हमें अपने सुपर मापदंडों को अनुकूलित करने और अपने रोबोटों को अधिक समय के लिए प्रशिक्षित करने की आवश्यकता है। यह GPU के लिए काम करना शुरू करने और सभी सिलेंडरों पर फायरिंग करने का समय है!
अब तक, यह लेख थोड़ा लंबा हो गया है, और हमारे पास अभी भी विचार करने के लिए बहुत सारे विवरण हैं, इसलिए हम यहां आराम करने की योजना बना रहे हैं। अगले लेख में, हम अपने समस्या स्थान के लिए सर्वोत्तम हाइपरपैरामीटर को विभाजित करने और CUDA का उपयोग करके GPU पर प्रशिक्षण / परीक्षण के लिए तैयार करने के लिए बेजियन अनुकूलन का उपयोग करेंगे।
निष्कर्ष
इस लेख में, हम शून्य से एक लाभदायक बिटकॉइन ट्रेडिंग रोबोट बनाने के लिए सुदृढीकरण सीखने का उपयोग करना शुरू करते हैं। हम निम्नलिखित कार्यों को पूरा कर सकते हैंः
-
ओपनएआई के जिम का उपयोग करके खरोंच से बिटकॉइन ट्रेडिंग वातावरण बनाएं।
-
पर्यावरण के विज़ुअलाइज़ेशन का निर्माण करने के लिए Matplotlib का उपयोग करें.
-
हमारे रोबोट को प्रशिक्षित करने और परीक्षण करने के लिए सरल क्रॉस-प्रमाणन का उपयोग करें।
-
लाभ प्राप्त करने के लिए हमारे रोबोट को थोड़ा समायोजित करें।
यद्यपि हमारा ट्रेडिंग रोबोट उतना लाभदायक नहीं था जितना हमने उम्मीद की थी, लेकिन हम पहले से ही सही दिशा में आगे बढ़ रहे हैं। अगली बार, हम यह सुनिश्चित करेंगे कि हमारे रोबोट लगातार बाजार को हरा सकें। हम देखेंगे कि हमारे ट्रेडिंग रोबोट वास्तविक समय के डेटा को कैसे संसाधित करते हैं। कृपया मेरे अगले लेख और विवा बिटकॉइन का पालन जारी रखें!
- क्रिप्टोक्यूरेंसी बाजार में मौलिक विश्लेषण की मात्राः डेटा को खुद के लिए बोलने दें!
- मौद्रिक सर्कल के मूलभूत मात्रात्मक अनुसंधान - अब हर तरह के जादूगरों पर भरोसा न करें, डेटा निष्पक्ष रूप से बोलते हैं!
- क्वांटिफाइड ट्रेडिंग के लिए आवश्यक उपकरण - आविष्कारक क्वांटिफाइड डेटा एक्सप्लोरर मॉड्यूल
- सब कुछ में महारत हासिल करना - एफएमजेड ट्रेडिंग टर्मिनल का नया संस्करण (टीआरबी आर्बिट्रेज स्रोत कोड के साथ)
- सब कुछ जानने के लिए FMZ के नए संस्करण के लिए ट्रेडिंग टर्मिनल का परिचय (अनुदानित TRB सूट स्रोत कोड)
- एफएमजेड क्वांटः क्रिप्टोकरेंसी बाजार में सामान्य आवश्यकताओं के डिजाइन उदाहरणों का विश्लेषण (II)
- 80 पंक्तियों के कोड में उच्च आवृत्ति रणनीति के साथ मस्तिष्क रहित बिक्री बॉट्स का शोषण कैसे करें
- एफएमजेड क्वांटिकेशनः क्रिप्टोक्यूरेंसी बाजार में आम जरूरतों के डिजाइन उदाहरण का विश्लेषण
- 80 लाइनों के कोड के साथ उच्च आवृत्ति रणनीतियों का उपयोग करके बेचने के लिए मस्तिष्क रहित रोबोट का शोषण कैसे करें
- एफएमजेड क्वांटः क्रिप्टोकरेंसी बाजार में सामान्य आवश्यकताओं के डिजाइन उदाहरणों का विश्लेषण (I)
- एफएमजेड क्वांटिकेशनः क्रिप्टोक्यूरेंसी बाजार में आम जरूरतों के डिजाइन उदाहरण का विश्लेषण (1)