Pikiran tentang Strategi Perdagangan Frekuensi Tinggi (2)
Penulis:Lydia, Dibuat: 2023-08-04 17:17:30, Diperbarui: 2023-09-12 15:50:31
Pikiran tentang Strategi Perdagangan Frekuensi Tinggi (2)
Modeling Jumlah Perdagangan Terakumulasi
Dalam artikel sebelumnya, kami memperoleh ekspresi untuk probabilitas jumlah perdagangan tunggal yang lebih besar dari nilai tertentu.
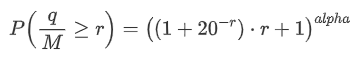
Kami juga tertarik pada distribusi jumlah perdagangan selama periode waktu, yang secara intuitif harus terkait dengan jumlah perdagangan individu dan frekuensi pesanan. di bawah ini, kami memproses data dalam interval tetap dan memetakan distribusi, mirip dengan apa yang dilakukan di bagian sebelumnya.
Dalam [1]:
from datetime import date,datetime
import time
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
Dalam [2]:
trades = pd.read_csv('HOOKUSDT-aggTrades-2023-01-27.csv')
trades['date'] = pd.to_datetime(trades['transact_time'], unit='ms')
trades.index = trades['date']
buy_trades = trades[trades['is_buyer_maker']==False].copy()
buy_trades = buy_trades.groupby('transact_time').agg({
'agg_trade_id': 'last',
'price': 'last',
'quantity': 'sum',
'first_trade_id': 'first',
'last_trade_id': 'last',
'is_buyer_maker': 'last',
'date': 'last',
'transact_time':'last'
})
buy_trades['interval']=buy_trades['transact_time'] - buy_trades['transact_time'].shift()
buy_trades.index = buy_trades['date']
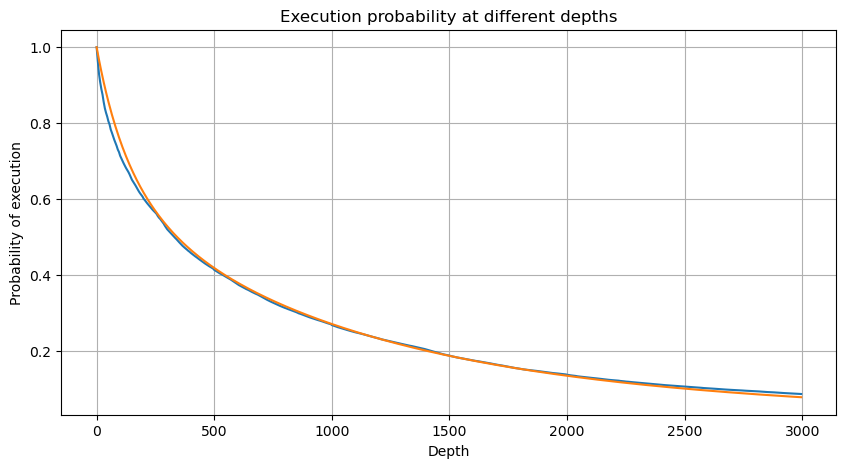
Kami menggabungkan jumlah perdagangan individu pada interval 1 detik untuk mendapatkan jumlah perdagangan agregat, tidak termasuk periode tanpa aktivitas perdagangan. Kami kemudian menyesuaikan jumlah agregat ini dengan menggunakan distribusi yang berasal dari analisis jumlah perdagangan tunggal yang disebutkan sebelumnya. Hasilnya menunjukkan kesesuaian yang baik ketika mempertimbangkan setiap perdagangan dalam interval 1 detik sebagai perdagangan tunggal, secara efektif memecahkan masalah. Namun, ketika interval waktu diperpanjang relatif terhadap frekuensi perdagangan, kami mengamati peningkatan kesalahan. Penelitian lebih lanjut mengungkapkan bahwa kesalahan ini disebabkan oleh istilah koreksi yang diperkenalkan oleh distribusi Pareto. Ini menunjukkan bahwa seiring waktu memperpanjang dan mencakup lebih banyak perdagangan individu, agregasi interval beberapa perdagangan mendekati distribusi Pareto lebih dekat, yang mengharuskan penghapusan istilah koreksi.
Dalam [3]:
df_resampled = buy_trades['quantity'].resample('1S').sum()
df_resampled = df_resampled.to_frame(name='quantity')
df_resampled = df_resampled[df_resampled['quantity']>0]
Dalam [4]:
# Cumulative distribution in 1s
depths = np.array(range(0, 3000, 5))
probabilities = np.array([np.mean(df_resampled['quantity'] > depth) for depth in depths])
mean = df_resampled['quantity'].mean()
alpha = np.log(np.mean(df_resampled['quantity'] > mean))/np.log(2.05)
probabilities_s = np.array([((1+20**(-depth/mean))*depth/mean+1)**(alpha) for depth in depths])
plt.figure(figsize=(10, 5))
plt.plot(depths, probabilities)
plt.plot(depths, probabilities_s)
plt.xlabel('Depth')
plt.ylabel('Probability of execution')
plt.title('Execution probability at different depths')
plt.grid(True)
Keluar[4]:
Dalam [5]:
df_resampled = buy_trades['quantity'].resample('30S').sum()
df_resampled = df_resampled.to_frame(name='quantity')
df_resampled = df_resampled[df_resampled['quantity']>0]
depths = np.array(range(0, 12000, 20))
probabilities = np.array([np.mean(df_resampled['quantity'] > depth) for depth in depths])
mean = df_resampled['quantity'].mean()
alpha = np.log(np.mean(df_resampled['quantity'] > mean))/np.log(2.05)
probabilities_s = np.array([((1+20**(-depth/mean))*depth/mean+1)**(alpha) for depth in depths])
alpha = np.log(np.mean(df_resampled['quantity'] > mean))/np.log(2)
probabilities_s_2 = np.array([(depth/mean+1)**alpha for depth in depths]) # No amendment
plt.figure(figsize=(10, 5))
plt.plot(depths, probabilities,label='Probabilities (True)')
plt.plot(depths, probabilities_s, label='Probabilities (Simulation 1)')
plt.plot(depths, probabilities_s_2, label='Probabilities (Simulation 2)')
plt.xlabel('Depth')
plt.ylabel('Probability of execution')
plt.title('Execution probability at different depths')
plt.legend()
plt.grid(True)
Keluar[5]:
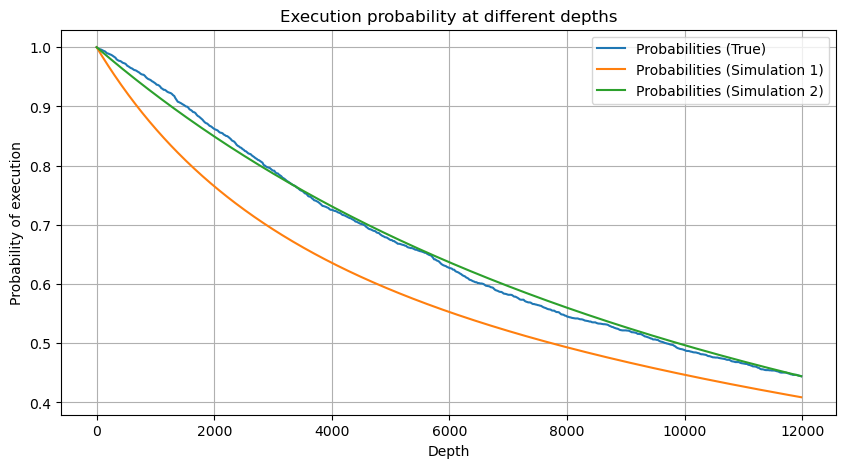
Sekarang rangkum rumus umum untuk distribusi jumlah perdagangan terakumulasi untuk periode waktu yang berbeda, menggunakan distribusi jumlah transaksi tunggal untuk menyesuaikan, daripada secara terpisah menghitung setiap kali.
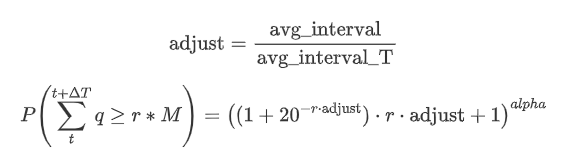
Di sini, avg_interval mewakili interval rata-rata transaksi tunggal, dan avg_interval_T mewakili interval rata-rata interval yang perlu diperkirakan. Mungkin terdengar agak membingungkan. Jika kita ingin memperkirakan jumlah perdagangan selama 1 detik, kita perlu menghitung interval rata-rata antara peristiwa yang berisi transaksi dalam waktu 1 detik. Jika probabilitas kedatangan pesanan mengikuti distribusi Poisson, itu harus dapat diestimasi secara langsung. Namun, pada kenyataannya, ada penyimpangan yang signifikan, tetapi saya tidak akan memperjelasnya di sini.
Perhatikan bahwa probabilitas jumlah perdagangan melebihi nilai tertentu dalam interval waktu tertentu dan probabilitas aktual perdagangan di posisi itu dalam kedalaman harus sangat berbeda. Seiring waktu tunggu meningkat, kemungkinan perubahan dalam buku pesanan meningkat, dan perdagangan juga mengarah pada perubahan kedalaman. Oleh karena itu, probabilitas perdagangan di posisi kedalaman yang sama berubah secara real-time saat pembaruan data.
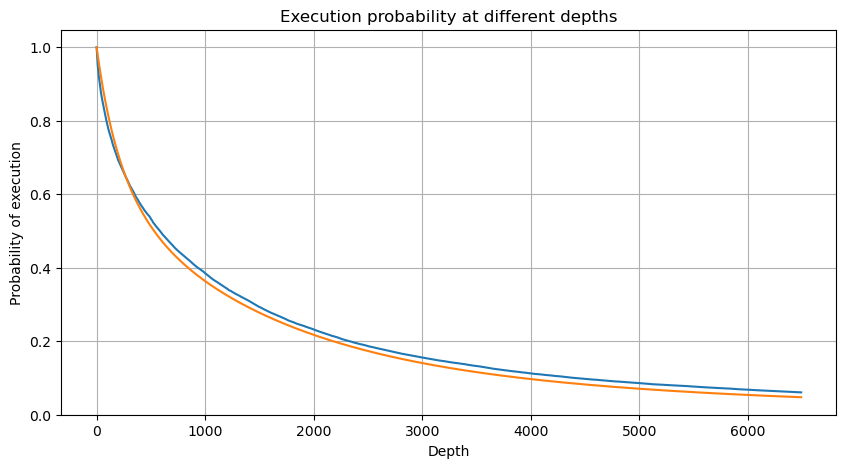
Dalam [6]:
df_resampled = buy_trades['quantity'].resample('2S').sum()
df_resampled = df_resampled.to_frame(name='quantity')
df_resampled = df_resampled[df_resampled['quantity']>0]
depths = np.array(range(0, 6500, 10))
probabilities = np.array([np.mean(df_resampled['quantity'] > depth) for depth in depths])
mean = buy_trades['quantity'].mean()
adjust = buy_trades['interval'].mean() / 2620
alpha = np.log(np.mean(buy_trades['quantity'] > mean))/0.7178397931503168
probabilities_s = np.array([((1+20**(-depth*adjust/mean))*depth*adjust/mean+1)**(alpha) for depth in depths])
plt.figure(figsize=(10, 5))
plt.plot(depths, probabilities)
plt.plot(depths, probabilities_s)
plt.xlabel('Depth')
plt.ylabel('Probability of execution')
plt.title('Execution probability at different depths')
plt.grid(True)
Keluar[6]:
Dampak Harga Perdagangan Tunggal
Data perdagangan sangat berharga, dan masih banyak data yang dapat digali. Kita harus memperhatikan dampak pesanan pada harga, karena ini mempengaruhi posisi strategi. Demikian pula, mengumpulkan data berdasarkan waktu transaksi, kita menghitung perbedaan antara harga terakhir dan harga pertama. Jika hanya ada satu pesanan, perbedaan harga adalah 0.
Hasilnya menunjukkan bahwa proporsi perdagangan yang tidak menyebabkan dampak adalah setinggi 77%, sementara proporsi perdagangan yang menyebabkan pergerakan harga 1 tik adalah 16,5%, 2 tik adalah 3,7%, 3 tik adalah 1,2%, dan lebih dari 4 tik kurang dari 1%.
Jumlah perdagangan yang menyebabkan perbedaan harga yang sesuai juga dianalisis, tidak termasuk distorsi yang disebabkan oleh dampak yang berlebihan. Ini menunjukkan hubungan linier, dengan sekitar 1 tanda fluktuasi harga yang disebabkan oleh setiap 1000 unit jumlah. Ini juga dapat dipahami sebagai rata-rata sekitar 1000 unit pesanan yang ditempatkan di dekat setiap tingkat harga dalam buku pesanan.
Dalam [7]:
diff_df = trades[trades['is_buyer_maker']==False].groupby('transact_time')['price'].agg(lambda x: abs(round(x.iloc[-1] - x.iloc[0],3)) if len(x) > 1 else 0)
buy_trades['diff'] = buy_trades['transact_time'].map(diff_df)
Dalam [8]:
diff_counts = buy_trades['diff'].value_counts()
diff_counts[diff_counts>10]/diff_counts.sum()
Keluar[8]:
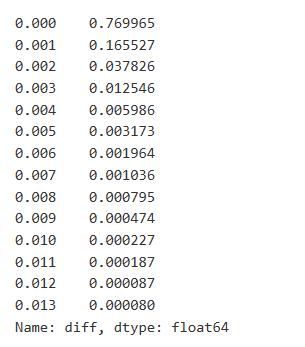
Dalam [9]:
diff_group = buy_trades.groupby('diff').agg({
'quantity': 'mean',
'diff': 'last',
})
Dalam [10]:
diff_group['quantity'][diff_group['diff']>0][diff_group['diff']<0.01].plot(figsize=(10,5),grid=True);
Keluar[10]:
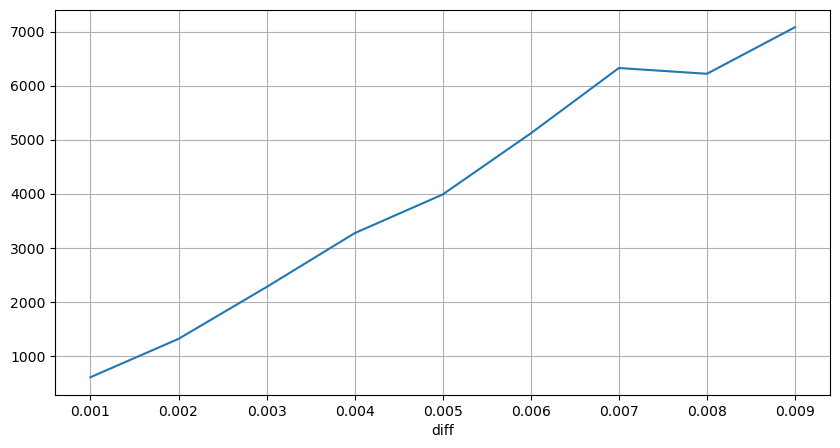
Dampak Harga Interval Tetap
Mari kita menganalisis dampak harga dalam interval 2 detik. Perbedaannya di sini adalah bahwa mungkin ada nilai negatif. Namun, karena kita hanya mempertimbangkan pesanan beli, dampak pada posisi simetris akan lebih tinggi satu tik. Terus mengamati hubungan antara jumlah perdagangan dan dampak, kita hanya menganggap hasil yang lebih besar dari 0.
Dalam [11]:
df_resampled = buy_trades.resample('2S').agg({
'price': ['first', 'last', 'count'],
'quantity': 'sum'
})
df_resampled['price_diff'] = round(df_resampled[('price', 'last')] - df_resampled[('price', 'first')],3)
df_resampled['price_diff'] = df_resampled['price_diff'].fillna(0)
result_df_raw = pd.DataFrame({
'price_diff': df_resampled['price_diff'],
'quantity_sum': df_resampled[('quantity', 'sum')],
'data_count': df_resampled[('price', 'count')]
})
result_df = result_df_raw[result_df_raw['price_diff'] != 0]
Dalam [12]:
result_df['price_diff'][abs(result_df['price_diff'])<0.016].value_counts().sort_index().plot.bar(figsize=(10,5));
Keluar[12]:
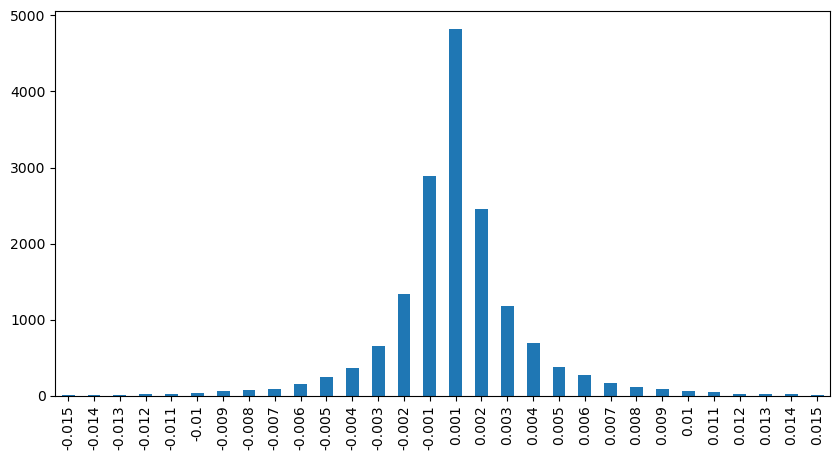
Dalam [23]:
result_df['price_diff'].value_counts()[result_df['price_diff'].value_counts()>30]
Keluar[23]:
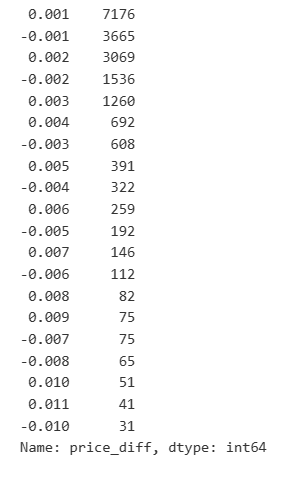
Dalam [14]:
diff_group = result_df.groupby('price_diff').agg({ 'quantity_sum': 'mean'})
Di [15]:
diff_group[(diff_group.index>0) & (diff_group.index<0.015)].plot(figsize=(10,5),grid=True);
Keluar[15]:
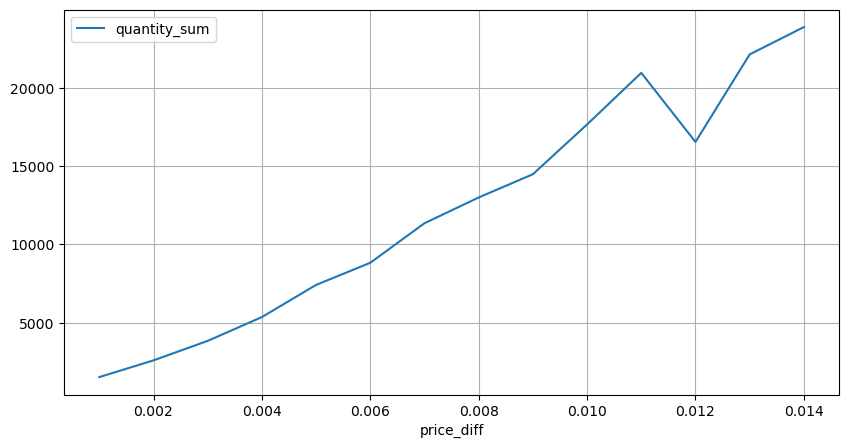
Dampak Harga dari Jumlah Perdagangan
Sebelumnya, kami menentukan jumlah perdagangan yang diperlukan untuk perubahan tik, tetapi itu tidak tepat karena didasarkan pada asumsi bahwa dampak telah terjadi.
Dalam analisis ini, data disampel setiap 1 detik, dengan setiap langkah mewakili 100 unit jumlah.
- Ketika jumlah pesanan beli di bawah 500, perubahan harga yang diharapkan adalah penurunan, yang diharapkan karena ada juga pesanan jual yang mempengaruhi harga.
- Pada jumlah perdagangan yang lebih rendah, ada hubungan linier, yang berarti bahwa semakin besar jumlah perdagangan, semakin besar kenaikan harga.
- Dengan meningkatnya jumlah pesanan beli, perubahan harga menjadi lebih signifikan. Hal ini sering menunjukkan terobosan harga, yang kemudian dapat mundur. Selain itu, pengambilan sampel interval tetap menambah ketidakstabilan data.
- Penting untuk memperhatikan bagian atas grafik penyebaran, yang sesuai dengan peningkatan harga dengan jumlah perdagangan.
- Untuk pasangan perdagangan tertentu ini, kami memberikan versi kasar dari hubungan antara jumlah perdagangan dan perubahan harga.
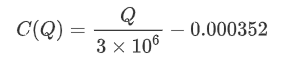
Di mana
Di [16]:
df_resampled = buy_trades.resample('1S').agg({
'price': ['first', 'last', 'count'],
'quantity': 'sum'
})
df_resampled['price_diff'] = round(df_resampled[('price', 'last')] - df_resampled[('price', 'first')],3)
df_resampled['price_diff'] = df_resampled['price_diff'].fillna(0)
result_df_raw = pd.DataFrame({
'price_diff': df_resampled['price_diff'],
'quantity_sum': df_resampled[('quantity', 'sum')],
'data_count': df_resampled[('price', 'count')]
})
result_df = result_df_raw[result_df_raw['price_diff'] != 0]
Dalam [24]:
df = result_df.copy()
bins = np.arange(0, 30000, 100) #
labels = [f'{i}-{i+100-1}' for i in bins[:-1]]
df.loc[:, 'quantity_group'] = pd.cut(df['quantity_sum'], bins=bins, labels=labels)
grouped = df.groupby('quantity_group')['price_diff'].mean()
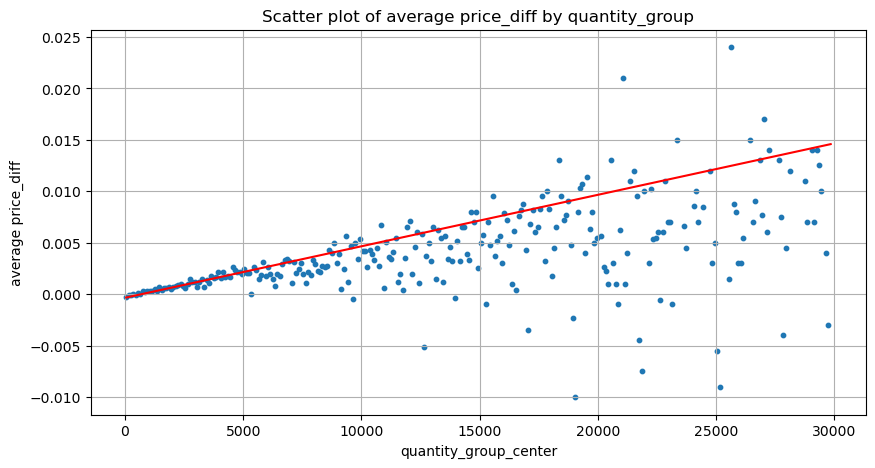
Di [25]:
grouped_df = pd.DataFrame(grouped).reset_index()
grouped_df['quantity_group_center'] = grouped_df['quantity_group'].apply(lambda x: (float(x.split('-')[0]) + float(x.split('-')[1])) / 2)
plt.figure(figsize=(10,5))
plt.scatter(grouped_df['quantity_group_center'], grouped_df['price_diff'],s=10)
plt.plot(grouped_df['quantity_group_center'], np.array(grouped_df['quantity_group_center'].values)/2e6-0.000352,color='red')
plt.xlabel('quantity_group_center')
plt.ylabel('average price_diff')
plt.title('Scatter plot of average price_diff by quantity_group')
plt.grid(True)
Keluar[25]:
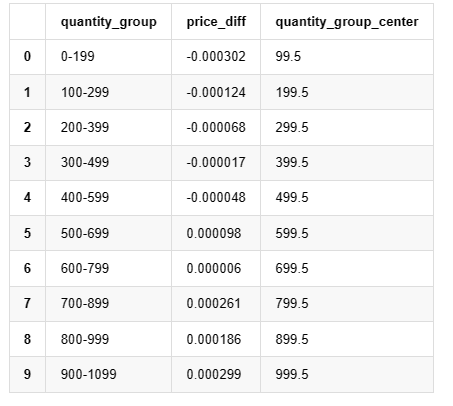
Dalam [19]:
grouped_df.head(10)
Keluar[19]: ,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,
Penempatan Pesenan Optimal Awal
Dengan pemodelan jumlah perdagangan dan model kasar dampak harga yang sesuai dengan jumlah perdagangan, tampaknya mungkin untuk menghitung penempatan pesanan optimal.
- Asumsikan bahwa harga kembali ke nilai aslinya setelah dampak (yang sangat tidak mungkin dan akan memerlukan analisis lebih lanjut tentang perubahan harga setelah dampak).
- Asumsikan bahwa distribusi volume perdagangan dan frekuensi pesanan selama periode ini mengikuti pola yang telah ditetapkan sebelumnya (yang juga tidak akurat, karena kami memperkirakan berdasarkan data satu hari dan perdagangan menunjukkan fenomena pengelompokan yang jelas).
- Asumsikan bahwa hanya satu pesanan jual terjadi selama waktu simulasi dan kemudian ditutup.
- Asumsikan bahwa setelah order dieksekusi, ada order beli lain yang terus mendorong harga naik, terutama ketika jumlahnya sangat rendah.
Mari kita mulai dengan menulis pengembalian yang diharapkan sederhana, yang merupakan probabilitas pesanan pembelian kumulatif melebihi Q dalam waktu 1 detik, dikalikan dengan tingkat pengembalian yang diharapkan (yaitu, dampak harga).
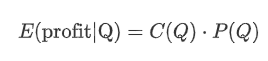
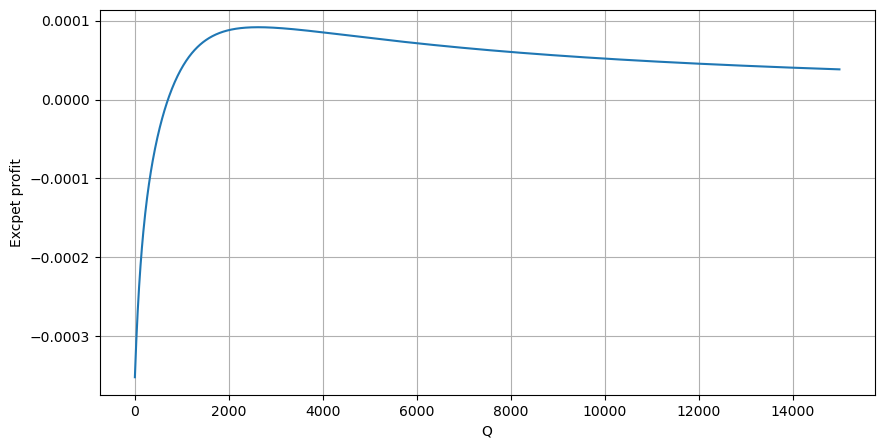
Berdasarkan grafik, pengembalian maksimum yang diharapkan adalah sekitar 2500, yang sekitar 2,5 kali jumlah perdagangan rata-rata. Ini menunjukkan bahwa pesanan jual harus ditempatkan pada posisi harga 2500. Penting untuk menekankan bahwa sumbu horizontal mewakili jumlah perdagangan dalam waktu 1 detik dan tidak boleh disamakan dengan posisi kedalaman. Selain itu, analisis ini didasarkan pada data perdagangan dan tidak memiliki data kedalaman yang penting.
Ringkasan
Kami telah menemukan bahwa distribusi jumlah perdagangan pada interval waktu yang berbeda adalah skala sederhana dari distribusi jumlah perdagangan individu. Kami juga telah mengembangkan model pengembalian yang diharapkan yang sederhana berdasarkan dampak harga dan probabilitas perdagangan. Hasil dari model ini selaras dengan harapan kami, menunjukkan bahwa jika jumlah pesanan jual rendah, itu menunjukkan penurunan harga, dan jumlah tertentu diperlukan untuk potensi keuntungan. Probabilitas berkurang seiring dengan peningkatan jumlah perdagangan, dengan ukuran optimal di antara, yang mewakili strategi penempatan pesanan yang optimal. Namun, model ini masih terlalu sederhana. Dalam artikel berikutnya, saya akan menyelidiki topik ini lebih mendalam.
Dalam [20]:
# Cumulative distribution in 1s
df_resampled = buy_trades['quantity'].resample('1S').sum()
df_resampled = df_resampled.to_frame(name='quantity')
df_resampled = df_resampled[df_resampled['quantity']>0]
depths = np.array(range(0, 15000, 10))
mean = df_resampled['quantity'].mean()
alpha = np.log(np.mean(df_resampled['quantity'] > mean))/np.log(2.05)
probabilities_s = np.array([((1+20**(-depth/mean))*depth/mean+1)**(alpha) for depth in depths])
profit_s = np.array([depth/2e6-0.000352 for depth in depths])
plt.figure(figsize=(10, 5))
plt.plot(depths, probabilities_s*profit_s)
plt.xlabel('Q')
plt.ylabel('Excpet profit')
plt.grid(True)
Keluar[20]:
- Hemat Opsi Delta untuk Bitcoin dengan Curve Senyum
- Pikiran tentang Strategi Perdagangan Frekuensi Tinggi (5)
- Pikiran tentang Strategi Perdagangan Frekuensi Tinggi (4)
- Berpikir tentang strategi perdagangan frekuensi tinggi (5)
- Berpikir tentang strategi perdagangan frekuensi tinggi (4)
- Pikiran tentang Strategi Perdagangan Frekuensi Tinggi (3)
- Berpikir tentang strategi perdagangan frekuensi tinggi (3)
- Berpikir tentang strategi perdagangan frekuensi tinggi (2)
- Pikiran tentang Strategi Perdagangan Frekuensi Tinggi (1)
- Berpikir tentang strategi perdagangan frekuensi tinggi (1)
- Dokumen Deskripsi Konfigurasi Futu Securities
- FMZ Quant Uniswap V3 Exchange Pool Liquidity Related Operations Guide (Bagian 1)
- FMZ Kuantitatif Uniswap V3 Panduan Operasi yang berkaitan dengan Likuiditas Kolam Pertukaran (1)