Pikiran tentang Strategi Perdagangan Frekuensi Tinggi (3)
Penulis:Lydia, Dibuat: 2023-08-08 10:05:19, Diperbarui: 2023-09-12 15:50:55
Pikiran tentang Strategi Perdagangan Frekuensi Tinggi (3)
Dalam artikel sebelumnya, saya memperkenalkan cara memodelkan volume perdagangan kumulatif dan menganalisis fenomena dampak harga. Dalam artikel ini, saya akan terus menganalisis data pesanan perdagangan. YGG baru-baru ini meluncurkan kontrak berbasis Binance U, dan fluktuasi harga telah signifikan, dengan volume perdagangan bahkan melampaui BTC pada satu titik. Hari ini, saya akan menganalisisnya.
Interval Waktu Pemesanan
Secara umum, diasumsikan bahwa waktu kedatangan pesanan mengikuti proses Poisson.Proses PoissonDi sini, aku akan memberikan bukti empiris.
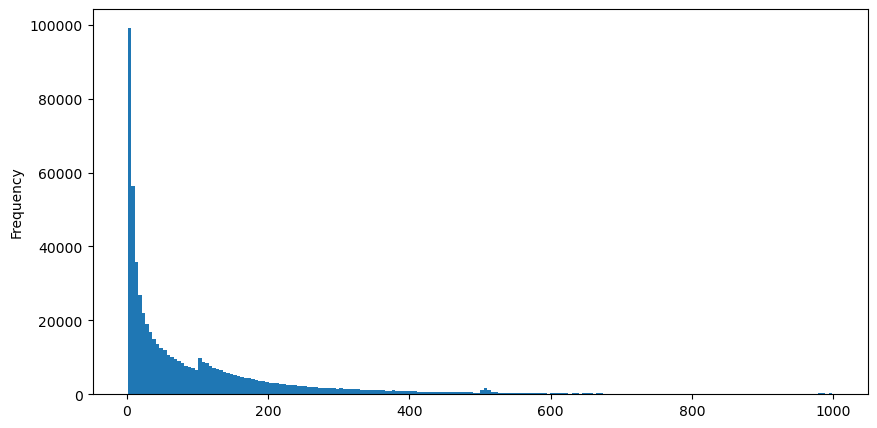
Saya mengunduh data aggTrades untuk 5 Agustus, yang terdiri dari 1.931.193 perdagangan, yang cukup signifikan. Pertama, mari kita lihat distribusi pesanan beli. Kita dapat melihat puncak lokal yang tidak mulus sekitar 100ms dan 500ms, yang kemungkinan disebabkan oleh pesanan gunung es yang ditempatkan oleh bot perdagangan pada interval reguler. Ini juga mungkin salah satu alasan untuk kondisi pasar yang tidak biasa pada hari itu.
Fungsi massa probabilitas (PMF) dari distribusi Poisson diberikan dengan rumus berikut:
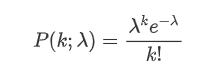
Di mana:
- κ adalah jumlah acara yang kami minati.
- λ adalah rata-rata tingkat kejadian yang terjadi per satuan waktu (atau ruang satuan).
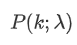 mewakili probabilitas kejadian tepat κ terjadi, mengingat laju rata-rata λ.
mewakili probabilitas kejadian tepat κ terjadi, mengingat laju rata-rata λ.
Dalam proses Poisson, interval waktu antara peristiwa mengikuti distribusi eksponensial. Fungsi kepadatan probabilitas (PDF) dari distribusi eksponensial diberikan oleh rumus berikut:
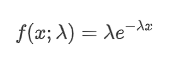
Hasil yang cocok menunjukkan bahwa ada perbedaan yang signifikan antara data yang diamati dan distribusi Poisson yang diharapkan. Proses Poisson meremehkan frekuensi interval waktu yang panjang dan meremehkan frekuensi interval waktu yang pendek. (Pembagian interval yang sebenarnya lebih dekat dengan distribusi Pareto yang dimodifikasi)
Dalam [1]:
from datetime import date,datetime
import time
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
Dalam [2]:
trades = pd.read_csv('YGGUSDT-aggTrades-2023-08-05.csv')
trades['date'] = pd.to_datetime(trades['transact_time'], unit='ms')
trades.index = trades['date']
buy_trades = trades[trades['is_buyer_maker']==False].copy()
buy_trades = buy_trades.groupby('transact_time').agg({
'agg_trade_id': 'last',
'price': 'last',
'quantity': 'sum',
'first_trade_id': 'first',
'last_trade_id': 'last',
'is_buyer_maker': 'last',
'date': 'last',
'transact_time':'last'
})
buy_trades['interval']=buy_trades['transact_time'] - buy_trades['transact_time'].shift()
buy_trades.index = buy_trades['date']
Dalam [10]:
buy_trades['interval'][buy_trades['interval']<1000].plot.hist(bins=200,figsize=(10, 5));
Keluar[10]:
Dalam [20]:
Intervals = np.array(range(0, 1000, 5))
mean_intervals = buy_trades['interval'].mean()
buy_rates = 1000/mean_intervals
probabilities = np.array([np.mean(buy_trades['interval'] > interval) for interval in Intervals])
probabilities_s = np.array([np.e**(-buy_rates*interval/1000) for interval in Intervals])
plt.figure(figsize=(10, 5))
plt.plot(Intervals, probabilities)
plt.plot(Intervals, probabilities_s)
plt.xlabel('Intervals')
plt.ylabel('Probability')
plt.grid(True)
Keluar[20]:
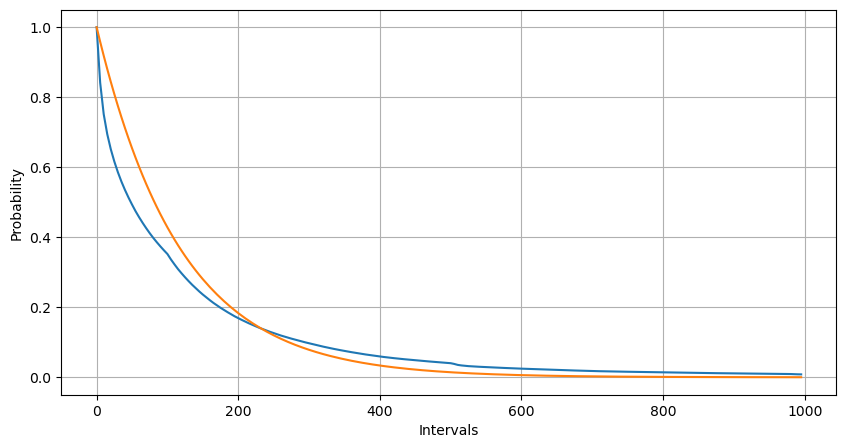
Ketika membandingkan distribusi jumlah kejadian urutan dalam 1 detik dengan distribusi Poisson, perbedaannya juga signifikan.
- Tingkat kejadian yang tidak konstan: Proses Poisson mengasumsikan bahwa rata-rata tingkat kejadian yang terjadi dalam interval waktu tertentu adalah konstan. Jika asumsi ini tidak berlaku, maka distribusi data akan menyimpang dari distribusi Poisson.
- Interaksi antara proses: Asumsi mendasar lain dari proses Poisson adalah bahwa peristiwa independen satu sama lain.
Dengan kata lain, dalam lingkungan dunia nyata, frekuensi kejadian order tidak konstan, dan perlu diperbarui secara real-time.
Pada tahun [190]:
result_df = buy_trades.resample('1S').agg({
'price': 'count',
'quantity': 'sum'
}).rename(columns={'price': 'order_count', 'quantity': 'quantity_sum'})
Di [219]:
count_df = result_df['order_count'].value_counts().sort_index()[result_df['order_count'].value_counts()>20]
(count_df/count_df.sum()).plot(figsize=(10,5),grid=True,label='sample pmf');
from scipy.stats import poisson
prob_values = poisson.pmf(count_df.index, 1000/mean_intervals)
plt.plot(count_df.index, prob_values,label='poisson pmf');
plt.legend() ;
Keluar[219]:
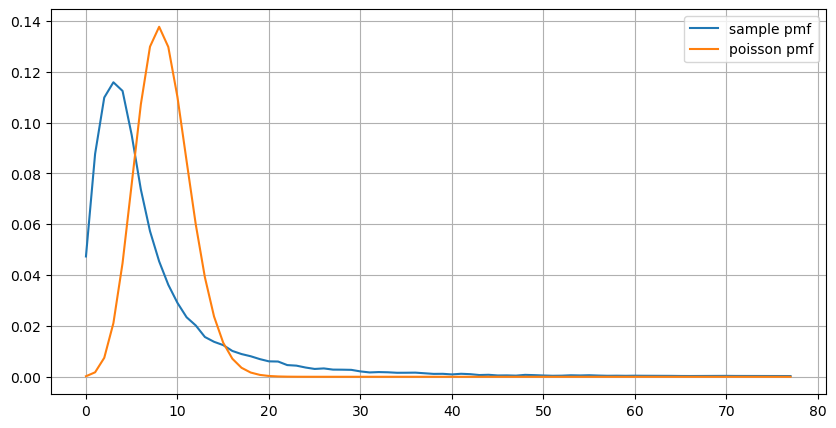
Pembaruan Parameter Waktu Nyata
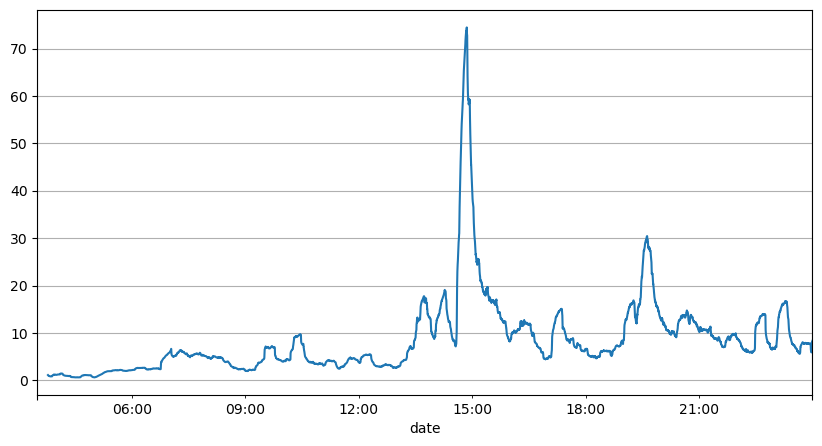
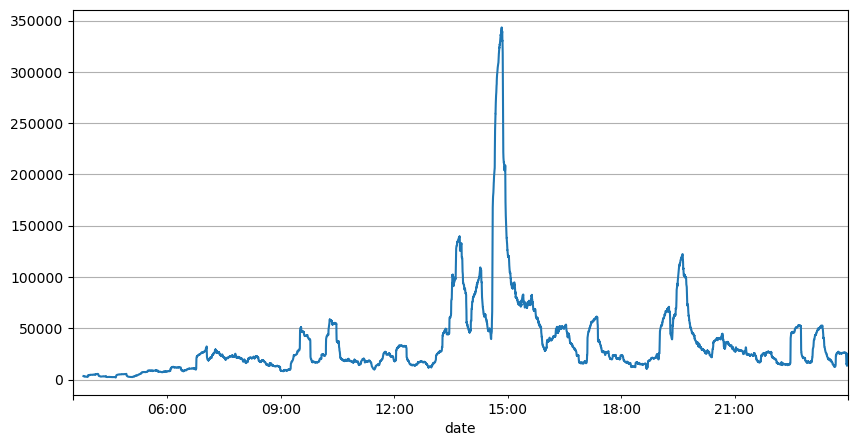
Dari analisis interval order sebelumnya, dapat disimpulkan bahwa parameter tetap tidak cocok untuk kondisi pasar nyata, dan parameter kunci yang menggambarkan pasar dalam strategi perlu diperbarui secara real-time. Solusi yang paling mudah adalah menggunakan rata-rata bergerak jendela geser. Dua grafik di bawah ini menunjukkan frekuensi pesanan beli dalam 1 detik dan rata-rata volume perdagangan dengan ukuran jendela 1000. Dapat diamati bahwa ada fenomena kluster dalam perdagangan, di mana frekuensi pesanan jauh lebih tinggi dari biasanya untuk jangka waktu tertentu, dan volume juga meningkat secara sinkron. Di sini, rata-rata nilai sebelumnya digunakan untuk memprediksi nilai absolut terbaru, dan rata-rata kesalahan residu digunakan untuk mengukur kualitas prediksi.
Dari grafik, kita juga dapat memahami mengapa frekuensi urutan menyimpang begitu banyak dari distribusi Poisson. Meskipun jumlah rata-rata perintah per detik hanya 8,5, kasus ekstrem menyimpang secara signifikan dari nilai ini.
Telah ditemukan bahwa menggunakan rata-rata dua detik sebelumnya untuk memprediksi menghasilkan kesalahan residual terkecil, dan jauh lebih baik daripada hanya menggunakan rata-rata untuk hasil prediksi.
Di [221]:
result_df['order_count'].rolling(1000).mean().plot(figsize=(10,5),grid=True);
Keluar[221]:
Pada tahun [193]:
result_df['quantity_sum'].rolling(1000).mean().plot(figsize=(10,5),grid=True);
Keluar[193]:
Pada tahun [195]:
(result_df['order_count'] - result_df['mean_count'].mean()).abs().mean()
Keluar[195]:
6.985628185332997
Di [205]:
result_df['mean_count'] = result_df['order_count'].rolling(2).mean()
(result_df['order_count'] - result_df['mean_count'].shift()).abs().mean()
Keluar[205]:
3.091737586730269
Ringkasan
Artikel ini secara singkat menjelaskan alasan penyimpangan interval waktu order dari proses Poisson, terutama karena variasi parameter dari waktu ke waktu. Untuk memprediksi pasar dengan akurat, strategi perlu membuat prediksi real-time dari parameter fundamental pasar. Sisa dapat digunakan untuk mengukur kualitas prediksi. Contoh yang diberikan di atas adalah demonstrasi sederhana, dan ada penelitian ekstensif tentang analisis deret waktu tertentu, pengelompokan volatilitas, dan topik terkait lainnya, demonstrasi di atas dapat ditingkatkan lebih lanjut.
- Hemat Opsi Delta untuk Bitcoin dengan Curve Senyum
- Pikiran tentang Strategi Perdagangan Frekuensi Tinggi (5)
- Pikiran tentang Strategi Perdagangan Frekuensi Tinggi (4)
- Berpikir tentang strategi perdagangan frekuensi tinggi (5)
- Berpikir tentang strategi perdagangan frekuensi tinggi (4)
- Berpikir tentang strategi perdagangan frekuensi tinggi (3)
- Pikiran tentang Strategi Perdagangan Frekuensi Tinggi (2)
- Berpikir tentang strategi perdagangan frekuensi tinggi (2)
- Pikiran tentang Strategi Perdagangan Frekuensi Tinggi (1)
- Berpikir tentang strategi perdagangan frekuensi tinggi (1)
- Dokumen Deskripsi Konfigurasi Futu Securities
- FMZ Quant Uniswap V3 Exchange Pool Liquidity Related Operations Guide (Bagian 1)
- FMZ Kuantitatif Uniswap V3 Panduan Operasi yang berkaitan dengan Likuiditas Kolam Pertukaran (1)