高周波取引戦略について考える (2)
作者: リン・ハーンリディア, 作成日:2023-08-04 17:17:30, 更新日:2023-09-12 15:50:31
高周波取引戦略について考える (2)
累積取引額モデル化
取引額が一定値よりも大きい確率を表す式を導き出しました
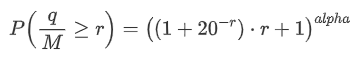
取引額の時間間の分布についても興味があります.これは,直感的に個々の取引額と注文頻度に関連しているはずです.下記では,一定の間隔でデータを処理し,前のセクションでやったものと類似してその分布をグラフ化します.
[1] において
from datetime import date,datetime
import time
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
[2] において
trades = pd.read_csv('HOOKUSDT-aggTrades-2023-01-27.csv')
trades['date'] = pd.to_datetime(trades['transact_time'], unit='ms')
trades.index = trades['date']
buy_trades = trades[trades['is_buyer_maker']==False].copy()
buy_trades = buy_trades.groupby('transact_time').agg({
'agg_trade_id': 'last',
'price': 'last',
'quantity': 'sum',
'first_trade_id': 'first',
'last_trade_id': 'last',
'is_buyer_maker': 'last',
'date': 'last',
'transact_time':'last'
})
buy_trades['interval']=buy_trades['transact_time'] - buy_trades['transact_time'].shift()
buy_trades.index = buy_trades['date']
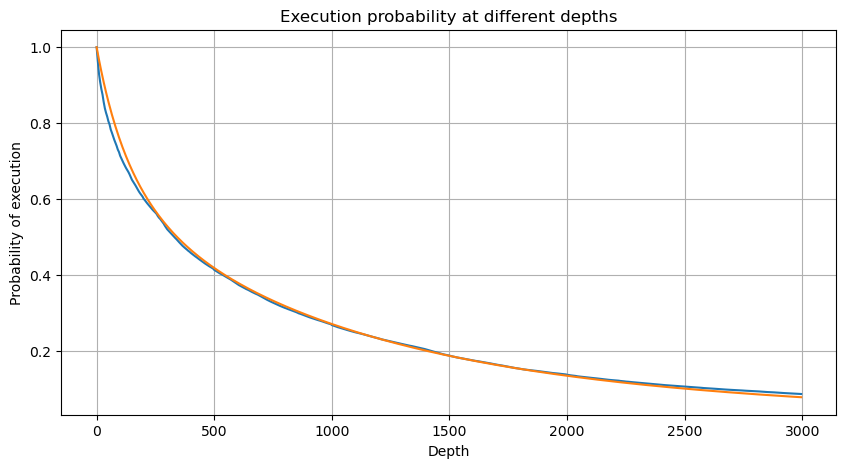
1秒間の間隔で個々の取引額を組み合わせ,取引活動のない期間を除いて,総取引額を得ます.次に,前述の単一の取引額分析から導いた分布を使用して,この総取引額にフィットします.結果は,1秒間の間隔内の各取引を単一の取引として検討するときに良いフィットを示し,効果的に問題を解決します.しかし,取引頻度との関係で時間間隔が延長されると,誤差の増加を観察します.さらなる研究は,この誤差がパレト分布によって導入された訂正期間によって引き起こされていることを明らかにします.これは,時間が長くなり,より多くの個別の取引が含まれると,複数の取引の間隔の総集がパレト分布に近づくことを示唆し,訂正期間を取り除く必要があります.
[3] において
df_resampled = buy_trades['quantity'].resample('1S').sum()
df_resampled = df_resampled.to_frame(name='quantity')
df_resampled = df_resampled[df_resampled['quantity']>0]
[4] において
# Cumulative distribution in 1s
depths = np.array(range(0, 3000, 5))
probabilities = np.array([np.mean(df_resampled['quantity'] > depth) for depth in depths])
mean = df_resampled['quantity'].mean()
alpha = np.log(np.mean(df_resampled['quantity'] > mean))/np.log(2.05)
probabilities_s = np.array([((1+20**(-depth/mean))*depth/mean+1)**(alpha) for depth in depths])
plt.figure(figsize=(10, 5))
plt.plot(depths, probabilities)
plt.plot(depths, probabilities_s)
plt.xlabel('Depth')
plt.ylabel('Probability of execution')
plt.title('Execution probability at different depths')
plt.grid(True)
アウト[4]:
[5] において
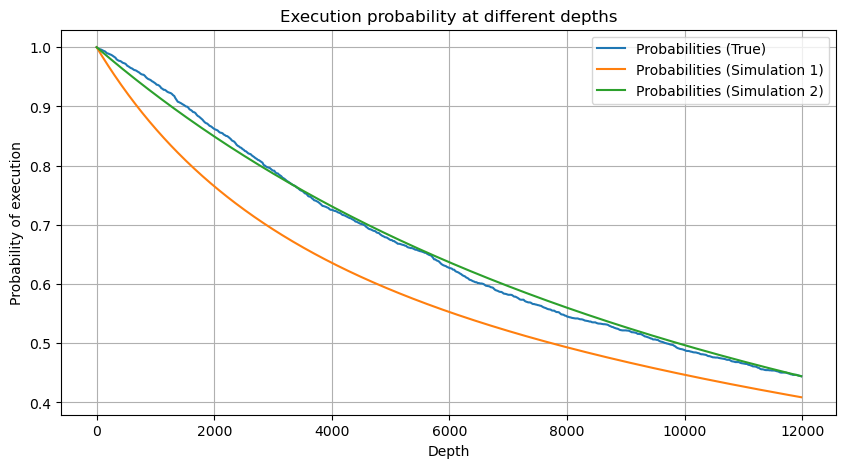
df_resampled = buy_trades['quantity'].resample('30S').sum()
df_resampled = df_resampled.to_frame(name='quantity')
df_resampled = df_resampled[df_resampled['quantity']>0]
depths = np.array(range(0, 12000, 20))
probabilities = np.array([np.mean(df_resampled['quantity'] > depth) for depth in depths])
mean = df_resampled['quantity'].mean()
alpha = np.log(np.mean(df_resampled['quantity'] > mean))/np.log(2.05)
probabilities_s = np.array([((1+20**(-depth/mean))*depth/mean+1)**(alpha) for depth in depths])
alpha = np.log(np.mean(df_resampled['quantity'] > mean))/np.log(2)
probabilities_s_2 = np.array([(depth/mean+1)**alpha for depth in depths]) # No amendment
plt.figure(figsize=(10, 5))
plt.plot(depths, probabilities,label='Probabilities (True)')
plt.plot(depths, probabilities_s, label='Probabilities (Simulation 1)')
plt.plot(depths, probabilities_s_2, label='Probabilities (Simulation 2)')
plt.xlabel('Depth')
plt.ylabel('Probability of execution')
plt.title('Execution probability at different depths')
plt.legend()
plt.grid(True)
アウト[5]:
各回別々に計算するのではなく,単一の取引金額の配分を使用して,異なる時間帯に累積された取引金額の分布のための一般的な式を要約します.
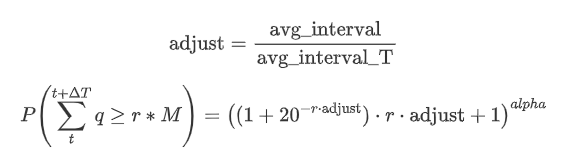
ここで, avg_interval は単一の取引の平均間隔を表し, avg_interval_T は推定する必要がある間隔の平均間隔を表します.少し混乱するかもしれません. 1秒間の取引額を推定したい場合は, 1秒以内に取引を含むイベント間の平均間隔を計算する必要があります. 注文の到着確率がポイスンの分布に従う場合,それは直接推定可能であるべきです. しかし,実際には,重大な偏差がありますが,ここで詳しく説明しません.
特定の時間間隔内で特定の値を上回る取引金額の確率と,その位置での深さの取引の実際の確率がかなり異なるべきであることに注意してください.待機時間が増加するにつれて,オーダーブックの変化の可能性が増加し,取引も深さの変化につながります.したがって,同じ深さの位置での取引の確率は,データ更新とともにリアルタイムで変化します.
[6] において
df_resampled = buy_trades['quantity'].resample('2S').sum()
df_resampled = df_resampled.to_frame(name='quantity')
df_resampled = df_resampled[df_resampled['quantity']>0]
depths = np.array(range(0, 6500, 10))
probabilities = np.array([np.mean(df_resampled['quantity'] > depth) for depth in depths])
mean = buy_trades['quantity'].mean()
adjust = buy_trades['interval'].mean() / 2620
alpha = np.log(np.mean(buy_trades['quantity'] > mean))/0.7178397931503168
probabilities_s = np.array([((1+20**(-depth*adjust/mean))*depth*adjust/mean+1)**(alpha) for depth in depths])
plt.figure(figsize=(10, 5))
plt.plot(depths, probabilities)
plt.plot(depths, probabilities_s)
plt.xlabel('Depth')
plt.ylabel('Probability of execution')
plt.title('Execution probability at different depths')
plt.grid(True)
アウト[6]:
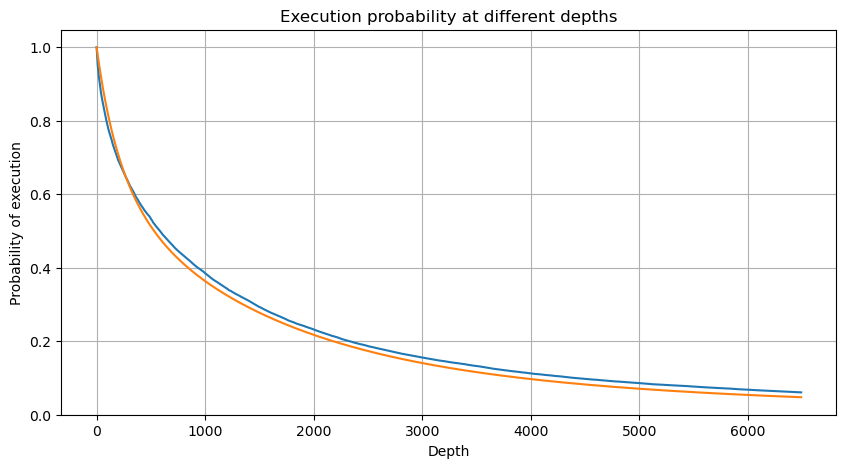
単一貿易価格の影響
取引データは価値があり,まだ多くのデータが採掘できる.これは戦略のポジショニングに影響するので,価格に対するオーダーの影響に注意を払うべきです.同様に,トランザクション_タイムに基づいてデータをアグリゲートすることで,最後の価格と最初の価格の違いを計算します.ただ1つのオーダーがある場合,価格の差は0です.興味深いことに,データの順序によるかもしれないマイナスデータ結果がいくつかあります.しかし,ここでは深く掘り下げません.
結果は,影響を与えない取引の割合は77%に達し,1つのティックの価格変動を引き起こす取引の割合は16.5%,2つのティックの価格は3.7%,3つのティックの価格は1.2%であり,4つ以上のティックの価格は1%未満であることを示しています.これは基本的に指数関数の特徴に従いますが,フィッティングは正確ではありません.
対応する価格差を引き起こす取引額も分析され,過剰な影響による歪みを除外した.これは線形的な関係を示し,金額の1000ユニットごとに約1つの価格変動が起こります.これはまた,注文簿内の各価格レベルに近い約1000ユニットの注文の平均として理解することができます.
[7]:
diff_df = trades[trades['is_buyer_maker']==False].groupby('transact_time')['price'].agg(lambda x: abs(round(x.iloc[-1] - x.iloc[0],3)) if len(x) > 1 else 0)
buy_trades['diff'] = buy_trades['transact_time'].map(diff_df)
[8] で:
diff_counts = buy_trades['diff'].value_counts()
diff_counts[diff_counts>10]/diff_counts.sum()
アウト[8]:
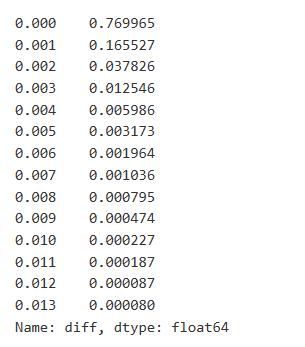
[9]:
diff_group = buy_trades.groupby('diff').agg({
'quantity': 'mean',
'diff': 'last',
})
[10] で:
diff_group['quantity'][diff_group['diff']>0][diff_group['diff']<0.01].plot(figsize=(10,5),grid=True);
アウト[10]:
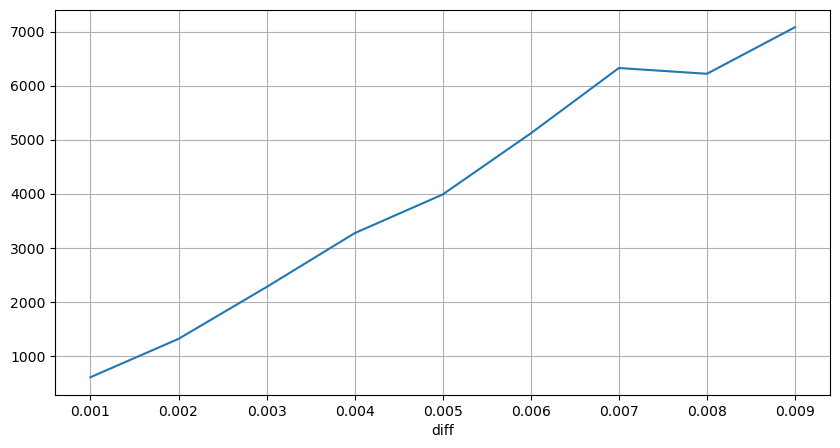
固定期間の価格への影響
2秒間の間隔で価格の影響を分析してみよう.ここで違いは負値がある可能性があることです.しかし,購入オーダーのみを検討しているため,対称ポジションへの影響は1ティック高いでしょう.取引量とインパクトの関係を観察し続けると,0以上の結果のみを考慮します.結論は,1つのオーダーと類似しており,各ティックに約2000ユニットの金額が必要で,ほぼ線形的な関係を示しています.
[11] で:
df_resampled = buy_trades.resample('2S').agg({
'price': ['first', 'last', 'count'],
'quantity': 'sum'
})
df_resampled['price_diff'] = round(df_resampled[('price', 'last')] - df_resampled[('price', 'first')],3)
df_resampled['price_diff'] = df_resampled['price_diff'].fillna(0)
result_df_raw = pd.DataFrame({
'price_diff': df_resampled['price_diff'],
'quantity_sum': df_resampled[('quantity', 'sum')],
'data_count': df_resampled[('price', 'count')]
})
result_df = result_df_raw[result_df_raw['price_diff'] != 0]
[12] で:
result_df['price_diff'][abs(result_df['price_diff'])<0.016].value_counts().sort_index().plot.bar(figsize=(10,5));
アウト[12]:
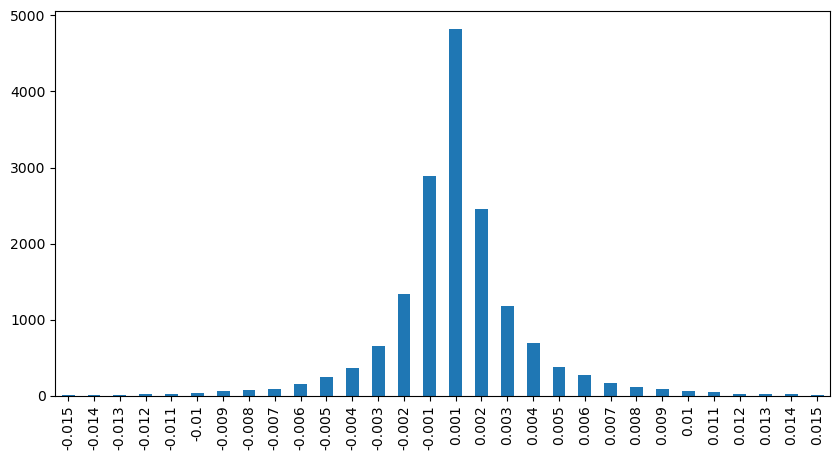
[23]:
result_df['price_diff'].value_counts()[result_df['price_diff'].value_counts()>30]
アウト[23]:
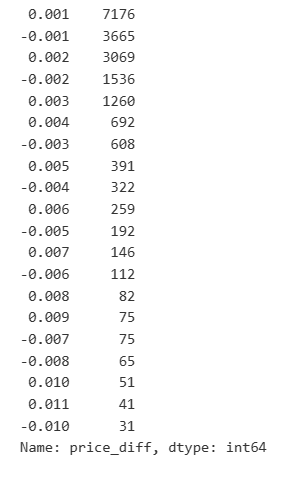
[14] では:
diff_group = result_df.groupby('price_diff').agg({ 'quantity_sum': 'mean'})
[15] について
diff_group[(diff_group.index>0) & (diff_group.index<0.015)].plot(figsize=(10,5),grid=True);
アウト[15]:
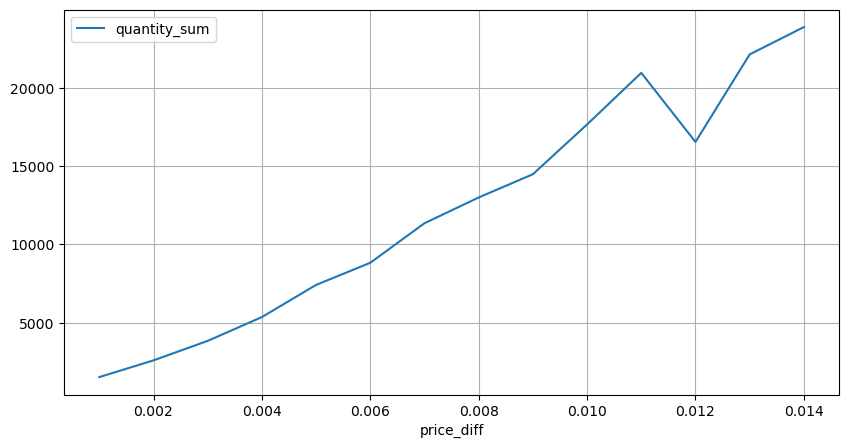
貿易量による価格影響
以前は,ティックの変更に必要な取引額を決定しましたが,その影響が既に発生したと仮定したため,正確ではありませんでした.今,見方を変えて,取引額による価格影響を調べましょう.
この分析では,データは1秒ごとにサンプリングされ,各ステップは100ユニットの量を表します.その後,この量範囲内の価格変化を計算しました. 以下にはいくつかの貴重な結論があります:
- 購入注文額が500未満である場合,予想される価格変動は下がり,価格に影響を与える販売注文も存在しているため,予想通りです.
- 取引額が低い場合,線形関係があり,取引額が大きいほど価格上昇が大きいことを意味します.
- 購入注文額が増加するにつれて,価格の変化はより顕著になる.これはしばしば価格の突破を示し,後に後退する可能性があります.さらに,固定間隔のサンプリングはデータ不安定性を増加させます.
- 分散グラフの上部に注意を払うことが重要です.これは取引量との価格増加に対応します.
- 取引額と価格変動の関係について 粗略なバージョンを提示します
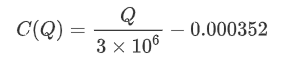
[16]:
df_resampled = buy_trades.resample('1S').agg({
'price': ['first', 'last', 'count'],
'quantity': 'sum'
})
df_resampled['price_diff'] = round(df_resampled[('price', 'last')] - df_resampled[('price', 'first')],3)
df_resampled['price_diff'] = df_resampled['price_diff'].fillna(0)
result_df_raw = pd.DataFrame({
'price_diff': df_resampled['price_diff'],
'quantity_sum': df_resampled[('quantity', 'sum')],
'data_count': df_resampled[('price', 'count')]
})
result_df = result_df_raw[result_df_raw['price_diff'] != 0]
[24]:
df = result_df.copy()
bins = np.arange(0, 30000, 100) #
labels = [f'{i}-{i+100-1}' for i in bins[:-1]]
df.loc[:, 'quantity_group'] = pd.cut(df['quantity_sum'], bins=bins, labels=labels)
grouped = df.groupby('quantity_group')['price_diff'].mean()
[25]では:
grouped_df = pd.DataFrame(grouped).reset_index()
grouped_df['quantity_group_center'] = grouped_df['quantity_group'].apply(lambda x: (float(x.split('-')[0]) + float(x.split('-')[1])) / 2)
plt.figure(figsize=(10,5))
plt.scatter(grouped_df['quantity_group_center'], grouped_df['price_diff'],s=10)
plt.plot(grouped_df['quantity_group_center'], np.array(grouped_df['quantity_group_center'].values)/2e6-0.000352,color='red')
plt.xlabel('quantity_group_center')
plt.ylabel('average price_diff')
plt.title('Scatter plot of average price_diff by quantity_group')
plt.grid(True)
出場[25]:
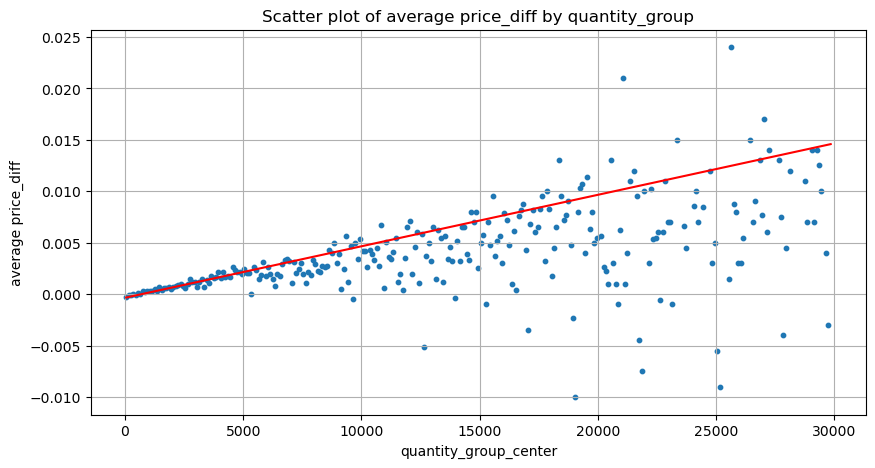
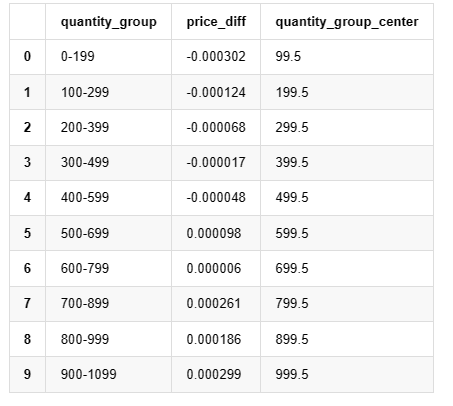
[19]:
grouped_df.head(10)
アウト[19]: ほら ほら ほら ほら ほら
初期最適注文の配置
取引額のモデル化と取引額に対応する価格影響の粗略モデルにより,最適なオーダー配置を計算することは可能と思われる.いくつかの仮定を行い,無責任な最適な価格位置を提供しましょう.
- 影響後,価格が元の値に戻ると仮定する (これは非常に不可能で,影響後の価格変化のさらなる分析が必要である).
- この期間の取引量と注文頻度の分布が事前に設定されたパターンに従うと仮定します (これは1日間のデータに基づいて推定され,取引は明確なクラスタリング現象を示しているため,これもまた不正確です).
- シミュレーション期間中に1つのセールオーダーのみが発生し,その後閉じると仮定します.
- 注文が実行された後,価格が非常に低い場合,特に価格を押し上げ続ける他の購入注文があると仮定します.この効果はここで無視され,価格が後退すると仮定します.
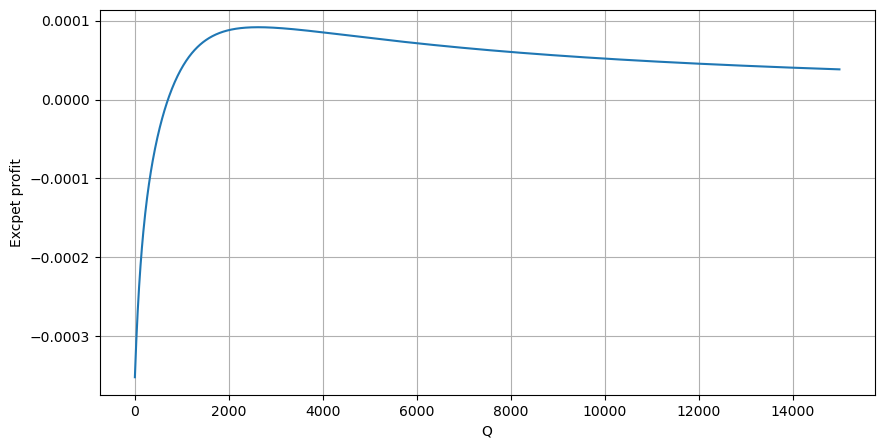
1秒以内にQを超えた累積買い注文の確率を, 予想回帰率 (つまり価格影響) に掛ける.
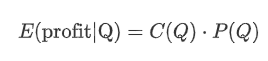
グラフに基づいて,最大期待回報は約2500であり,これは平均取引額の約2.5倍である.これは,セールオーダーが2500の価格ポジションに置かれるべきであることを示唆している.水平軸が1秒以内に取引額を表し,深度ポジションと同等化されるべきではないことを強調することが重要です.さらに,この分析は取引データに基づいているため,重要な深度データがない.
概要
異なる時間間隔で取引金額の分布は,個々の取引金額の分布の単純なスケーリングであることを発見しました.また,価格の影響と取引確率に基づいた単純な期待回帰モデルを開発しました.このモデルの結果は,販売注文金額が低い場合,価格減少を示し,利益の可能性のために一定の金額が必要であることを示す私たちの期待に準拠しています.取引額が増加するにつれて確率が減少し,中間で最適なサイズで,最適な注文配送戦略を表しています.しかし,このモデルは依然として単純すぎます.次の記事では,このトピックを深く探します.
[20]:
# Cumulative distribution in 1s
df_resampled = buy_trades['quantity'].resample('1S').sum()
df_resampled = df_resampled.to_frame(name='quantity')
df_resampled = df_resampled[df_resampled['quantity']>0]
depths = np.array(range(0, 15000, 10))
mean = df_resampled['quantity'].mean()
alpha = np.log(np.mean(df_resampled['quantity'] > mean))/np.log(2.05)
probabilities_s = np.array([((1+20**(-depth/mean))*depth/mean+1)**(alpha) for depth in depths])
profit_s = np.array([depth/2e6-0.000352 for depth in depths])
plt.figure(figsize=(10, 5))
plt.plot(depths, probabilities_s*profit_s)
plt.xlabel('Q')
plt.ylabel('Excpet profit')
plt.grid(True)
アウト[20]: