高周波取引戦略について考える (3)
作者: リン・ハーンリディア, 作成日:2023-08-08 10:05:19, 更新日:2023-09-12 15:50:55
高周波取引戦略について考える (3)
前回の記事では,累積的な取引量をモデル化する方法と価格の影響現象を分析しました. この記事では,取引注文データを分析し続けます. YGGは最近,Binance Uベースの契約を開始し,価格変動が顕著で,取引量は一度 BTC を上回っています. 今日,それを分析します.
注文時間間隔
一般的に,注文の到着時間はプーソンプロセスに従っていると仮定されます.魚類加工実験的な証拠を 提供します
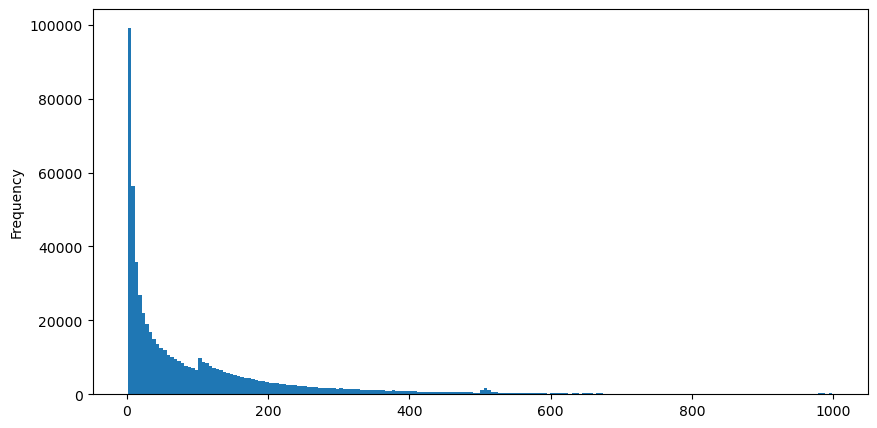
8月5日のaggTradesデータをダウンロードしました. 1,931,193の取引で構成されています. これはかなり重要なことです. まず,買い注文の分布を見てみましょう. 100msと500msの周りにスムーズでないローカルピークが見られます. これは,定期的に取引ボットによって配られた氷山の注文によって引き起こされる可能性があります. これは,その日の異常な市場状況の理由の一つです.
ポイスン分布の確率量関数 (PMF) は,次の式で与えられる.
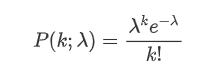
どこに:
- 興味のあるイベントの数です.
- λは,単位時間 (または単位空間) 単位で発生するイベントの平均率です.
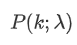 平均速度 λ を考えると,正確に κ 事件が起こる確率を表します.
平均速度 λ を考えると,正確に κ 事件が起こる確率を表します.
ポイソンプロセスでは,イベント間の時間間隔は指数分布に従います.指数分布の確率密度関数 (PDF) は次の式で与えられる:
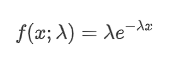
Fitting の結果は,観測データと予想される Poisson 分布の間に有意な差があることを示しています. Poisson プロセスは,長い時間間隔の頻度を過小評価し,短い時間間隔の頻度を過大評価します. (間隔の実際の分布は修正された Pareto 分布に近い)
[1] において
from datetime import date,datetime
import time
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
[2] において
trades = pd.read_csv('YGGUSDT-aggTrades-2023-08-05.csv')
trades['date'] = pd.to_datetime(trades['transact_time'], unit='ms')
trades.index = trades['date']
buy_trades = trades[trades['is_buyer_maker']==False].copy()
buy_trades = buy_trades.groupby('transact_time').agg({
'agg_trade_id': 'last',
'price': 'last',
'quantity': 'sum',
'first_trade_id': 'first',
'last_trade_id': 'last',
'is_buyer_maker': 'last',
'date': 'last',
'transact_time':'last'
})
buy_trades['interval']=buy_trades['transact_time'] - buy_trades['transact_time'].shift()
buy_trades.index = buy_trades['date']
[10] で:
buy_trades['interval'][buy_trades['interval']<1000].plot.hist(bins=200,figsize=(10, 5));
アウト[10]:
[20]:
Intervals = np.array(range(0, 1000, 5))
mean_intervals = buy_trades['interval'].mean()
buy_rates = 1000/mean_intervals
probabilities = np.array([np.mean(buy_trades['interval'] > interval) for interval in Intervals])
probabilities_s = np.array([np.e**(-buy_rates*interval/1000) for interval in Intervals])
plt.figure(figsize=(10, 5))
plt.plot(Intervals, probabilities)
plt.plot(Intervals, probabilities_s)
plt.xlabel('Intervals')
plt.ylabel('Probability')
plt.grid(True)
アウト[20]:
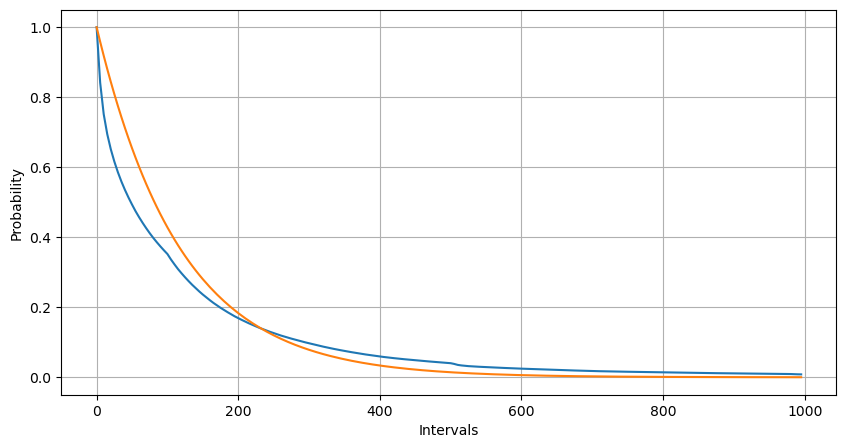
1秒間の順序発生数の分布とポイスン分布を比較すると,差異も顕著である.ポイスン分布は希少な出来事の頻度を著しく過小評価する.この可能性の理由は以下の通りである.
- 不一定発生率:ポイソンプロセスは,特定の時間間隔内で発生するイベントの平均発生率が一定であると仮定する.この仮定が成立しない場合,データの分布はポイソン分布から逸脱する.
- プロセス間の相互作用: ポイソンプロセスのもう一つの基本的な仮定は,イベントが互いに独立していることです.現実世界のイベントが相互に相互作用した場合,それらの分布はポイソン分布から逸脱する可能性があります.
つまり,実世界の環境では,オーダー発生頻度は不定であり,リアルタイムで更新する必要がある.また,一定の時間内により多くのオーダーがより多くのオーダーを刺激するインセンティブ効果がある可能性があります.これは,戦略が単一の固定パラメータに依存できないようにします.
[190年]:
result_df = buy_trades.resample('1S').agg({
'price': 'count',
'quantity': 'sum'
}).rename(columns={'price': 'order_count', 'quantity': 'quantity_sum'})
[219]:
count_df = result_df['order_count'].value_counts().sort_index()[result_df['order_count'].value_counts()>20]
(count_df/count_df.sum()).plot(figsize=(10,5),grid=True,label='sample pmf');
from scipy.stats import poisson
prob_values = poisson.pmf(count_df.index, 1000/mean_intervals)
plt.plot(count_df.index, prob_values,label='poisson pmf');
plt.legend() ;
アウト[219]:
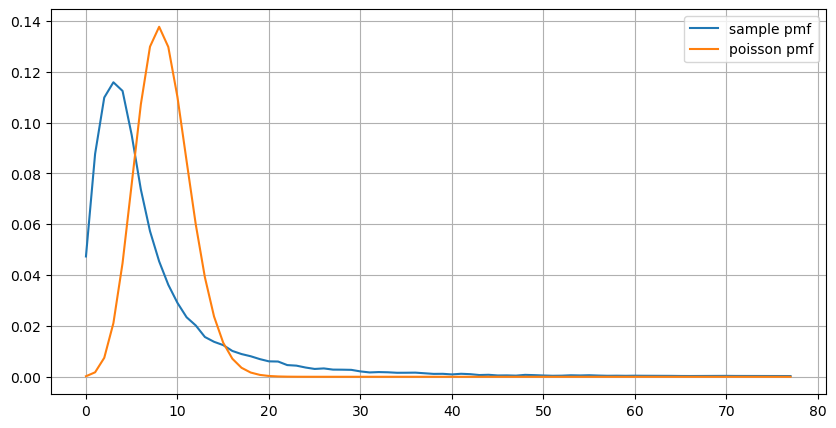
リアルタイムパラメータ更新
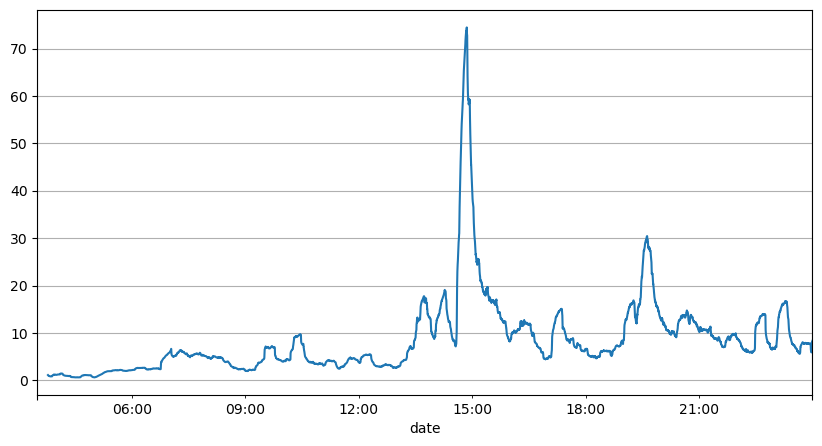
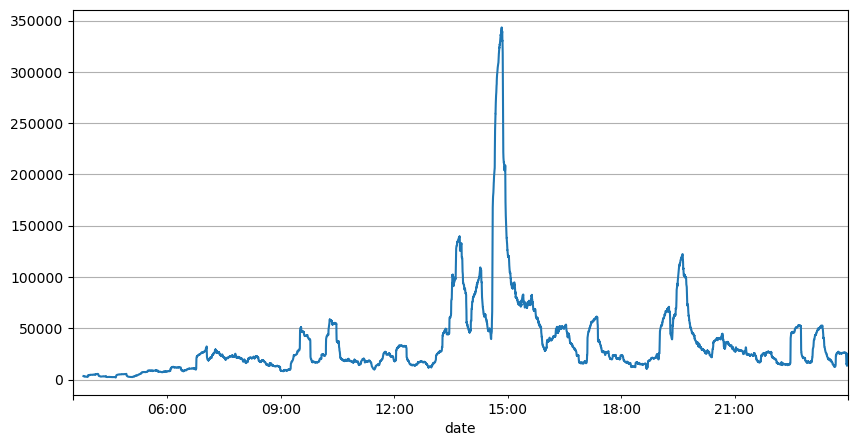
先ほどの注文間隔の分析から,固定パラメータは実際の市場状況に適していないと結論付けることができ,戦略における市場を記述する主要なパラメータはリアルタイムで更新する必要があります.最も簡単な解決策は,スライディングウィンドウ移動平均を使用することです.下記の2つのグラフは,1秒以内に購入注文の頻度と,1000のウィンドウサイズで取引量の平均を示しています.取引にはクラスタリング現象があり,注文の頻度が一定の期間通常よりも大幅に高くなり,ボリュームも同期的に増加します.ここで,以前の値の平均値は最新の値を予測するために使用され,残りの絶対値の平均誤差は予測の品質を測定するために使用されます.
グラフから,オーダー周波数がポイソン分布からそれほど偏っている理由も理解できます. 平均秒あたりオーダーの数は8.5しかありませんが,極端なケースはこの値から大幅に偏っています.
前2秒間の平均値を予測するのに使うと 最小の残留エラーが得られ 予測結果に平均値を使うよりも ずっと良いことがわかりました
[221]:
result_df['order_count'].rolling(1000).mean().plot(figsize=(10,5),grid=True);
出場[221]:
[193]:
result_df['quantity_sum'].rolling(1000).mean().plot(figsize=(10,5),grid=True);
アウト[1]:
[195] 年:
(result_df['order_count'] - result_df['mean_count'].mean()).abs().mean()
出場[195]:
6.985628185332997
[205]:
result_df['mean_count'] = result_df['order_count'].rolling(2).mean()
(result_df['order_count'] - result_df['mean_count'].shift()).abs().mean()
出場[205]:
3.091737586730269
概要
この記事では,主にパラメータの変化により,ポイソンプロセスからオーダータイムインターバルが逸脱する理由を簡潔に説明します.市場を正確に予測するために,戦略は市場の基本パラメータのリアルタイム予測を行う必要があります.残留値は予測の品質を測定するために使用できます.上記の例は簡単な実証であり,特定の時間系列分析,変動クラスタリング,およびその他の関連トピックに関する広範な研究があります.上記の実証はさらに改善することができます.