

最近、「蒸留」という言葉がますます頻繁に使われるようになっています。AI分野では、複雑な能力をよりコンパクトで再利用可能な構造に抽出することを意味することが多いですが、これを戦略研究に当てはめても同様の考え方が成り立ちます。もっと直接的には、散在していて曖昧で主観的な経験に依存していた知識を、計算可能で検証可能、さらに修正可能なシステムに整理するということです。
crypto-kol-quant というプロジェクトが最近注目されていますが、その真に興味深い点は、どれだけのKOLを取得したかや、LLMを使ったかではなく、定量研究ではあまり見られないことを試みている点です。すなわち、トレーダーの経験を一連の計算可能な能力因子に蒸留し、さらにそれを集約してコンセンサスシグナルにすることです。この問題自体、真剣に取り組む価値があります。なぜなら、長期間活発に活動し、スタイルが安定したトレーダーたちが、実際に市場でそれぞれの認知枠組みを形成しているなら、それらの枠組みは理論上、ツイートやチャート、断片的な言葉だけに存在すべきではなく、抽出され、整理され、実行可能な戦略のパイプラインに組み込まれる機会があるべきだからです。
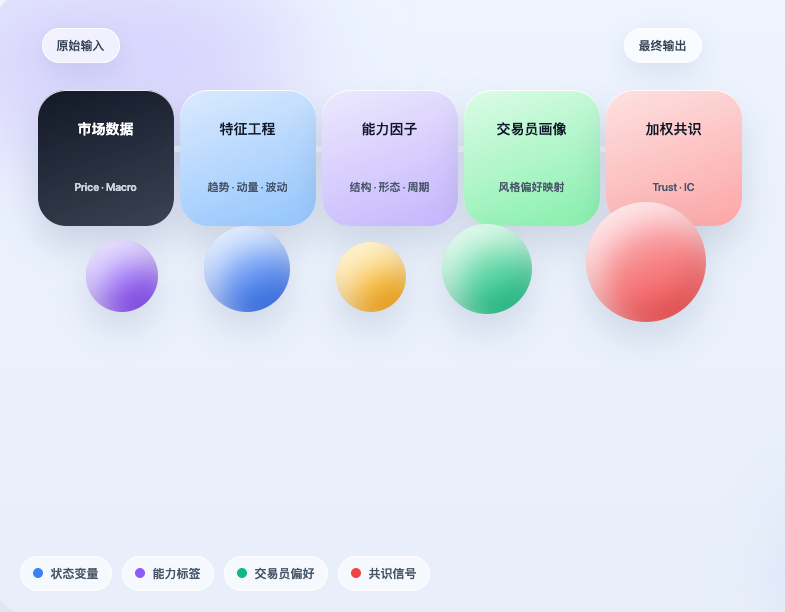
この考えに基づき、私たちは発明者量化環境で初期実装を行いました。重要なのは、プロジェクトを単に「移植する」ことではなく、その最も核となるロジックを実際に連携させることです。まず市場データを取得し、市場を構造化された状態に変換します。次に、その状態に基づいてどの取引能力がトリガーされているかを判断します。そして、その能力をトレーダーのプロファイルにマッピングし、最後に異なるトレーダーの個人的な判断を重み付きのコンセンサスシグナルに集約します。これは明らかにまだ成熟した取引システムではありませんが、少なくとも重要なことを達成しています。すなわち、トレーダーの経験が確かに圧縮可能で構造化可能であり、実際に戦略判断のプロセスに取り入れることができることを証明したのです。
蒸留の対象は、意見ではなく、取引能力
多くの人が初めてこの種のプロジェクトに触れたとき、「KOL感情戦略」と理解しがちです。しかし、これは実際には正確ではありません。元のプロジェクトが実際に行っているのは、単に誰が今日より楽観的かを判断したり、誰がロングを叫び、誰がショートを叫んだかを統計したりすることではなく、さらに一歩進んで、次のことを追求しています。すなわち、このトレーダーは市場をどのように理解しているのか? どのような構造下で強気になりやすいのか? トレンド、位置、形状、ボラティリティ、マクロ環境のどれをより重視しているのか? これらの判断方法は、安定した能力ラベルのセットに整理できるだろうか?
問題がこのように提起されると、戦略の重心は変わります。システムはもはや特定の一文に関心があるのではなく、その一文の背後にある方法論に関心を持ちます。言い換えれば、この戦略が真に蒸留する対象はテキストではなく、取引知識そのものです。それは、本来は人の理解に依存していた主観的な経験を、プログラムが認識して呼び出せるルール化された能力に翻訳しようと試みます。これこそが、一般的な感情モデルとの最大の違いです。市場の感情がどれほど熱いかを判断するのではなく、異なる取引フレームワークが現在の市場でどのように反応するかを再構築するのです。
第一歩:まず市場を状態変数に翻訳する
蒸留を実際に機能させるためには、最初のステップは予測ではなく、特徴量エンジニアリングです。理由は簡単で、トレーダーの言語は人が見るためのものであり、プログラムが見るためのものではないからです。例えば、「価格が重要な移動平均線に押し戻され、これは良い2回目のエントリーポイントだ」という文は、トレーダーにはよく理解できますが、プログラムにとっては、まず分解されなければなりません。重要な移動平均線とは何か、50日か200日か、現在の価格はその線に近いか、トレンドは壊れていないか、買い支えのシグナルが出ているか。
したがって、システムが最初に行うべきことは、多かれ少なかれの結論を出すことではなく、生の相場を一連の構造化された状態に変換することです。ここで最も基本的な層は、価格を使用してトレンドとモメンタムの特徴を構築することです。移動平均線、指数移動平均線、RSI、MACDなどの変数は、指標を積み上げるためのものではなく、単純な質問に答えるためのものです。すなわち、市場は今おおよそどのような状態にあるのか?

重要なコードは以下の通りです。
python
# 用不同周期的均线描述价格所处的趋势位置
f['ma20'] = _sma(c,20)
f['ma50'] = _sma(c,50)
f['ma100'] = _sma(c,100)
f['ma200'] = _sma(c,200)
# 指数均线对近期价格变化更敏感
f['ema20'] = _ema(c,20)
f['ema50'] = _ema(c,50)
# RSI 用来描述市场是否进入超买超卖,或者动量是否衰减
f['rsi14'] = _rsi(c,14)
# MACD 及其信号线、柱体,用来观察趋势和动量变化
ml, ms, mh = _macd(c)
f['macd'] = ml
f['macd_sig'] = ms
f['macd_hist'] = mh
このコードが行っていることはそれほど複雑ではありません。移動平均線は、システムが現在の価格が長期的なトレンドに対してどの位置にあるかを判断するのに役立ち、RSIやMACDはモメンタムが強化されているのか減衰しているのかを記述するために使用されます。まだ取引判断には入っておらず、単に「市場状態の記述」の層を構築しているだけです。
次に、システムはボラティリティと位置関係も補完する必要があります。なぜなら、多くの取引判断はトレンドだけでなく、「今はボラティリティ収縮期か」「価格がレンジの高値または安値に近いか」にも依存するからです。
対応するコードは以下の通りです。
python
# 对数收益率是计算波动率的基础
logr = np.log(c / c.shift(1))
# 近 30 天年化波动率,用来衡量当前市场波动水平
f['rv30'] = logr.rolling(30, min_periods=10).std() * np.sqrt(365)
# 最近 20 天和 50 天的高低点,用来判断价格所处位置
f['high_20d'] = h.rolling(20, min_periods=1).max()
f['low_20d'] = l.rolling(20, min_periods=1).min()
f['high_50d'] = h.rolling(50, min_periods=1).max()
f['low_50d'] = l.rolling(50, min_periods=1).min()
ここでの rv30 は直近30日間の年率換算ボラティリティレベルを示し、レンジの高値安値は、現在の価格が最近の価格構造の中でどの位置にあるかをシステムが判断するのに役立ちます。これに加えて、マクロの背景も状態空間に組み込まれます。なぜなら、あるタイプのトレーダーは仮想通貨の価格だけを見るのではなく、ドル指数、米国株式のリスク選好、金利環境も同時に観察するからです。コード内での対応する処理方法は、まずこれらの変数を日次でアラインし、次に読み取り可能な状態に変換することです。
python
# DXY 作为美元强弱的背景变量
if 'DXY' in macro:
dxy = _align(macro['DXY'])
f['dxy_ret_20d'] = dxy.pct_change(20)
f['dxy_trend_down'] = (dxy.pct_change(20) < -0.01).astype(int)
# SPX 作为风险偏好背景变量
if 'SPX' in macro:
spx = _align(macro['SPX'])
f['spx_ret_20d'] = spx.pct_change(20)
f['spx_trend_up'] = (spx.pct_change(20) > 0).astype(int)
このステップの意味は一言でまとめられます。まず「市場は今どうなっているか」を、機械が継続的に読み取れる構造化された状態に翻訳することです。この層がなければ、その後の蒸留は成り立ちません。
第二歩:主観的な経験を能力因子として記述する
特徴量だけでは不十分です。なぜなら、特徴量は市場を記述しているに過ぎず、「この状態が何を意味するのか」を直接表現しているわけではないからです。次のステップでは、トレーダーの経験をルールとして記述し、すなわち、現在のこれらの状態変数に基づいて、どの取引能力がトリガーされているかを判断しなければなりません。
このステップは、一連の戦略の中で最も蒸留らしさが強い部分です。なぜなら、ここでは抽象的に「何らかのフレームワークが重要だ」と言うのではなく、実際にプログラム条件として記述するからです。現在の実装に含まれる能力因子は、形状、構造、指標、周期、マクロの複数のレベルをカバーしています。例えば、一部の能力は形状認識(ブルフラッグ、ベアフラッグ、ダブルトップ・ダブルボトム、ヘッドアンドショルダー、トライアングル)に由来し、一部は構造分析(Wyckoff、SMC、ICTなどのフレームワーク)、一部は指標自体(RSIダイバージェンス、移動平均線ゴールデンクロス・デッドクロス、ボリンジャーバンドスクイーズブレイクアウト)、さらに一部は周期やマクロ環境(半減期サイクル、トレンド相場とレンジ相場の切り替え、DXY下落、リスク選好の回復など)に由来します。
非常に典型的な例は、「トレンド押し戻し継続」です。多くのトレーダーは似たような経験を持っています。大きなトレンドがまだ上向きで、価格が重要な移動平均線に押し戻され、現在のローソク足に買い支えのシグナルが出ている場合、それはしばしばトレンドの継続を意味します。プログラムでの表現は非常に直接的です。
python
# 判断当前价格是否接近 50 日均线
near_ma50 = abs(close - ma50_v) / close < 0.02 if close > 0 else False
# 如果 50 日均线仍在 200 日均线上方,且回踩均线后出现阳线承接
# 则记为一个趋势延续能力信号
s['cap_014_trend_pullback_continuation'] = 0.6 if (ma50_gt and near_ma50 and is_green) else 0.0
ここには神秘的なものは何もなく、単に人間の言語を、機械が一つ一つ判断できる条件に分解しただけです。もう一つの例は「ボリンジャーバンドスクイーズブレイクアウト」です。多くのトレーダーにとって、ボラティリティが長期間収縮した後に突然上または下に拡大することは、しばしば新たな方向性の選択を意味します。対応するルールの書き方は以下の通りです。
python
# 如果前一根 K 线布林带宽度低于压缩阈值,则视为波动收缩
squeezed = bb_w_p1 < bb_w20_p1 if bb_w20_p1 > 0 else False
# 收缩之后向上突破上轨,给正向信号;向下跌破下轨,给负向信号
s['cap_021_bollinger_squeeze_breakout'] = (
0.6 if (squeezed and close > bb_u) else
-0.6 if (squeezed and close < bb_l) else 0.0
)
マクロ因子の処理も同様です。よりマクロ志向のトレーダーにとって、BTCは完全に孤立した価格系列ではなく、ドル、株式市場、金利環境の影響を受けるため、これらの理解も能力判断として記述されます。
python
# DXYの下落は通常、BTCにとってややポジティブな環境とみなされる
s['cap_027_dxy_inverse_btc'] = 0.4 if (not _nm(dxy_r20) and dxy_r20 < -0.01) else 0.0
# S&Pの上昇はリスク選好の改善と見なせる
s['cap_028_spx_risk_on_off'] = 0.4 if (not _nm(spx_r20) and spx_r20 > 0.02) else 0.0
# 短期金利の低下は流動性の限界的改善と見なせる
s['cap_029_yields_liquidity'] = 0.4 if (not _nm(y_r20) and y_r20 < -0.02) else 0.0
この層で本当に重要なのは、いくつのルールが書かれているかではなく、「蒸留」の最も重要な一歩を完了したことにある。すなわち、本来は主観的な理解だけに頼る判断を、計算可能な条件に圧縮したのである。ついでに指摘しておくと、現行バージョンのほとんどの能力因子は、連続的なスコアリング型ではなく、条件トリガー型である。つまり、システムは細かな変動ごとに継続的に再価格付けを行うのではなく、ある種の構造が成立しているかどうかを判断しているようなものだ。このことから、現在のところ日足または中低頻度の判断に適しており、高頻度取引には向いていない。
第3ステップ:因子はそのまま合計せず、まずトレーダープロファイルにマッピングする
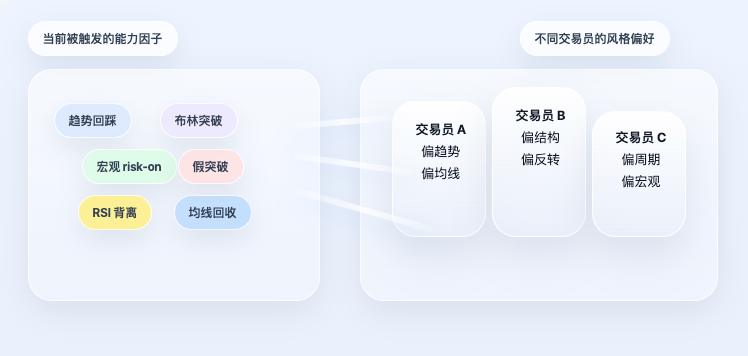
戦略が因子層で止まってしまうなら、それは依然として単なるルールシステムにすぎない。このプロジェクトのさらに特別な点は、ここで立ち止まらず、さらに一歩先に進んだことにある。すなわち、因子は直接方向を決めるのではなく、まずトレーダープロファイルにマッピングされる。
この点は非常に重要である。現実のトレーダーは「すべての能力を平均的に使う」わけではないからだ。トレンド派もいれば、構造派、サイクル派、マクロ派もいる。同じ市場状態に直面しても、各人が注目するポイントはまったく異なる。したがってシステムは、すべての因子を単純に平均するのではなく、まず各トレーダーの能力選好を読み取り、現在の因子状態に基づいて個人シグナルを計算する。
対応するプロファイル読み取りロジックは以下の通り。
python
# 各トレーダーがプロファイルで使用する能力因子とその重みを読み取る
caps = {c['id']: float(c.get('weight', 0.5))
for c in p.get('capabilities_used', [])}
profiles.append({
'handle': p.get('handle', item['name'][:-5]),
'caps': caps
})
各プロファイルは本質的に一つの問いに答えている。すなわち、このトレーダーはどの能力因子に依存し、それらの能力は自身のフレームワークの中でどの程度の重みを持つか、である。このプロファイルができて初めて、システムは現在の市場における各トレーダーの「個人シグナル」を計算する。
python
for p in profiles:
sig = 0.0
wt = 0.0
# そのトレーダーが注目するすべての能力因子を走査
for cap_id, w in p['caps'].items():
score = factor_scores.get(cap_id, 0.0)
# 現在の因子スコアにトレーダーのその因子に対する選好重みを乗算
sig += w * score
wt += abs(w)
# 正規化して、現在の市場におけるそのトレーダーの個人シグナルを得る
trader_raw = sig / wt if wt > 0 else 0.0
ここまで見てくると、このシステムの味わいはすでにかなり異なることがわかる。もはや「どの因子が光っているか」を見るだけではなく、次のようなことを近似的に再構築している。すなわち、今日の市場をこれら99人のトレーダーに委ねたら、それぞれがどのように判断するかを、である。
第4ステップ:個人シグナルから加重コンセンサスへ
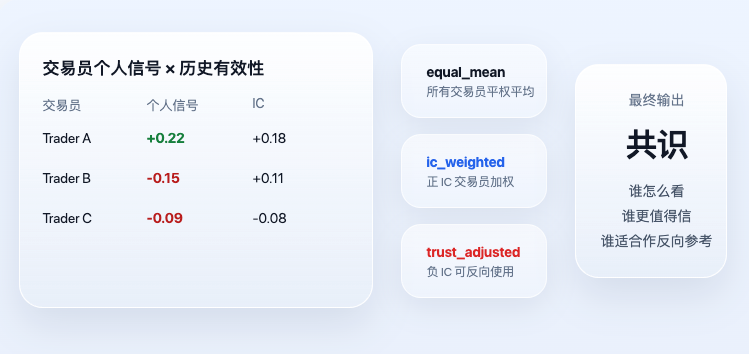
各トレーダーの個人シグナルが計算された後、システムはようやく真のコンセンサス層に入る。ここでの「コンセンサス」は単純な投票ではなく、ましてや声の大きい者が決めるものでもなく、さらに過去の有効性を考慮する。
現在のコードで最も重要な2つの結果は ic_weighted と trust_adjusted である。対応する中核ロジックは以下の通り。
python
# まず正のICを持つトレーダーに正の重み付けを行い、ic_weightedを得る
pos_w = sum(max(t['ic'], 0) for t in trader_signals)
ic_wt = (
sum(t['signal'] * max(t['ic'], 0) for t in trader_signals) / pos_w
if pos_w > 0 else 0.0
)
# trust_adjusted はさらに一歩進む:
# 正のICはそのまま使用、負のICは反転使用し、絶対ICの大きさで加重する
abs_w = sum(abs(t['ic']) for t in trader_signals)
trust = (
sum((t['signal'] if t['ic'] >= 0 else -t['signal']) * abs(t['ic'])
for t in trader_signals) / abs_w
if abs_w > 0 else 0.0
)
このコードは、非常にシンプルだが重要な2つの原則を表現している。第一に、過去に有効だったトレーダーほど、今日において大きな重みを持つ。第二に、過去のパフォーマンスが負のICだったトレーダーも、排除されるのではなく、逆張り指標として使用される可能性がある。したがって、最終的に出力される trust_adjusted は単純な「みんなの見方」ではなく、「誰がどう見ているか、そして誰がより信頼に値するか」を表している。
これこそが、このシステムが通常の感情モデルと異なる理由である。単に声の数を集計するのではなく、過去の検証を伴う認知の集約を行っているのだ。この一連の方法を一言に圧縮するなら、次のようになる。まず市場を状態変数に変換し、状態変数を能力因子にマッピングし、能力因子をトレーダーの個人シグナルにマッピングし、最後にそれらの個人シグナルを過去の有効性に基づいてコンセンサス判断に集約する。
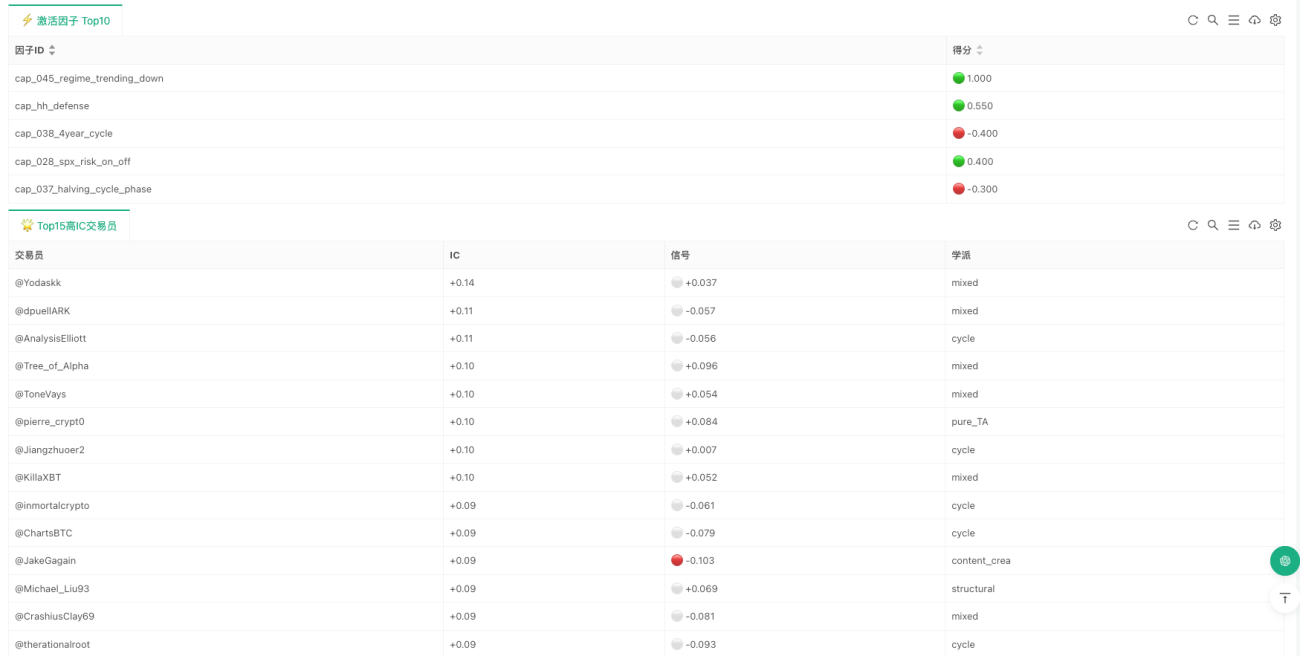
Inventor上での実装:実際に何が動いたか
研究プロジェクトのままでは、このシステムは単なる「コンセンサス分析器」に過ぎない。Inventor上での実装の重点は、チェーン全体を実際に繋ぎ、継続的に動作可能にしたことにある。最も中核的なコードは実質的に次の3行だけである。
python
# 第1ステップ:生の相場データとマクロ変数を構造化された状態に変換
feat_df = build_features(records, macro if macro else None)
# 第2ステップ:状態変数に基づいて現在どの能力因子がトリガーされているかを評価
factor_scores = evaluate_factors(feat_df)
# 第3ステップ:能力因子をトレーダープロファイルにマッピングし、コンセンサス結果に集約
consensus = compute_consensus(factor_scores)
この3行が、戦略全体で最も重要な3つの抽象層である。第1層は市場状態、第2層は能力判断、第3層はトレーダーコンセンサスを担当する。もちろんその後には実行層、リスク管理層、状態表示が続くが、研究ロジックの観点から言えば、最も重要な部分はすでに完全に成立している。つまり、この実装の最も重要な意義は、どれだけ多くの運用細部が追加されたかではなく、元のプロジェクトにおける能力プロファイルがもはや静的なファイルではなくなり、因子が単なる研究出力ではなくなり、コンセンサスがレポート内の数字ではなくなり、それらがすべて継続的に動作する判断フローに組み込まれたことにある。
なぜまだプロトタイプに過ぎないのか
もちろん、この実装は最終形ではない。現在のコードはBTC日足フレームワークを使用しているため、中低頻度のコンセンサス判断には適しているが、高頻度取引システムには向いていない。その中核は依然として日足の構造、サイクル位置、マクロ的背景、トレーダーの能力選好を中心に展開している。さらに、トレーダープロファイルとICは現在も静的な入力であり、まだオンライン進化段階には入っていない。つまり、システムは「知識の蒸留」の第一歩を完了したものの、「蒸留後の知識が自己修正を続ける」ところまでは完全には至っていない。
しかし、これは非常に重要なことを示している点で妨げにならない。すなわち、トレーダーの経験は層ごとに圧縮・構造化され、実際に戦略チェーンに組み込むことができるということである。その価値は、すでに安定した収益を生み出していることではなく、もともと概念レベルにとどまっていた研究経路を、実行可能な段階に押し上げたことにある。これらの能力因子がどのように進化すべきか、トレーダーの重みをどのように更新するか、コンセンサスを実際の市場でどのように継続的に補正するかは、さらなる運用データで答えを出す必要がある。
結び
crypto-kol-quant が真に示唆に富む点は、どれだけ多くの流行概念を使ったかではなく、システム化が難しいことを一歩前に進めたことにある。すなわち、トレーダーの経験を「表現」から「能力」へ、「能力」から「因子」へ、「因子」から「コンセンサス」へと変換したのである。そしてInventor上のこの実装は、まさにこの蒸留チェーンを実際に動かすことを達成した。それは自分がすでに最終形であると誇張せず、依然として初期プロトタイプに過ぎない事実を隠そうともしない。しかし少なくとも、取引経験はチャートや言葉の中に留まる必要はなく、蒸留・構造化・実行可能であり、さらには市場を継続的に判断するシステムに組み込めることを証明した。
伝統的な定量分析が価格系列からパターンを見つけることを得意とするなら、この種の戦略が本当に推進する価値がある方向性は、おそらく次のようなものである。人間の認知からパターンを抽出し、そのパターンを市場にフィードバックさせること。そしてこれこそが、戦略研究において「蒸留」が最も注目されるべき点かもしれない。
オリジナルプロジェクト: 鎖妖塔 Skill — 煉化99個加密交易員
特にユーザー「GiantBin」に、そのアイデアと着想を提供していただいたことに感謝します。良いアイデアや考えがあれば、ぜひ共有・交流してください。
- 1