고주파 거래 전략에 대한 생각 (3)
저자:리디아, 창작: 2023-08-08 10:05:19, 업데이트: 2023-09-12 15:50:55
고주파 거래 전략에 대한 생각 (3)
이전 기사에서는 누적 거래량을 모델링하는 방법을 소개하고 가격 영향 현상을 분석했습니다. 이 기사에서는 거래 주문 데이터를 계속 분석할 것입니다. YGG는 최근 바이낸스 U 기반 계약을 출시했으며 가격 변동이 상당히 컸으며 거래량은 한 시점에서 BTC를 초과했습니다. 오늘, 나는 그것을 분석 할 것입니다.
주문 시간 간격
일반적으로, 주문의 도착 시간은 포이슨 프로세스를 따르는 것으로 가정됩니다.포산 공정여기, 저는 경험적인 증거를 제공하겠습니다.
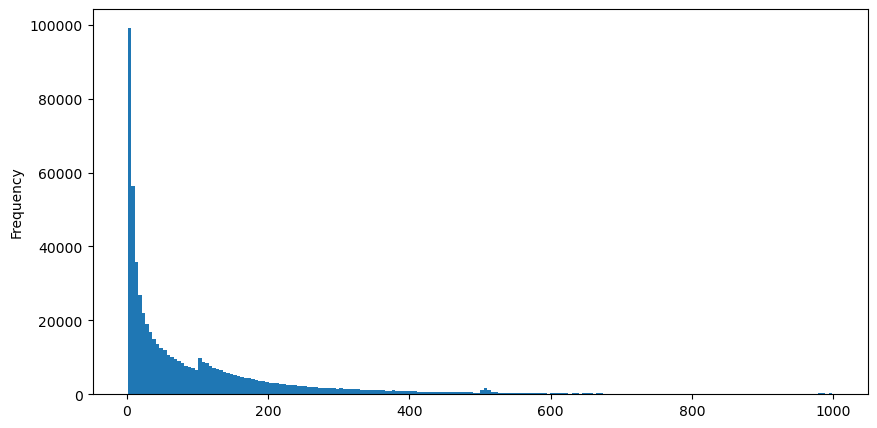
8월 5일 AggTrades 데이터를 다운로드했는데, 1,931,193개의 트레이드로 구성되어 있는데, 이는 상당히 중요합니다. 먼저, 구매 주문의 분포를 살펴보자. 우리는 100ms와 500ms 주위에서 매끄러운 지역 정점을 볼 수 있습니다. 이는 거래 봇에 의해 정기적으로 배치된 빙산 주문으로 인해 발생할 수 있습니다. 이것은 그 날의 특이한 시장 조건의 이유 중 하나일 수도 있습니다.
푸아슨 분포의 확률 질량 함수 (PMF) 는 다음과 같은 공식으로 주어집니다.
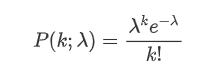
어디:
- κ는 우리가 관심있는 이벤트의 수입니다.
- λ는 시간 단위 (또는 공간 단위) 당 발생하는 사건의 평균 비율입니다.
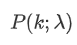 평균 속도 λ를 감안하면 정확히 κ 사건이 발생할 확률을 나타냅니다.
평균 속도 λ를 감안하면 정확히 κ 사건이 발생할 확률을 나타냅니다.
포이슨 과정에서는 사건들 사이의 시간 간격이 기하급수 분포를 따른다. 기하급수 분포의 확률 밀도 함수 (PDF) 는 다음과 같은 공식으로 주어진다.
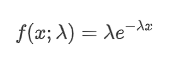
적절한 결과는 관찰된 데이터와 예상된 포이손 분포 사이에 상당한 차이가 있음을 보여줍니다. 포이손 과정은 긴 시간 간격의 빈도를 과소평가하고 짧은 시간 간격의 빈도를 과대평가합니다. (간격의 실제 분포는 수정된 파레토 분포에 더 가깝습니다.)
[1]에서:
from datetime import date,datetime
import time
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
[2]에서:
trades = pd.read_csv('YGGUSDT-aggTrades-2023-08-05.csv')
trades['date'] = pd.to_datetime(trades['transact_time'], unit='ms')
trades.index = trades['date']
buy_trades = trades[trades['is_buyer_maker']==False].copy()
buy_trades = buy_trades.groupby('transact_time').agg({
'agg_trade_id': 'last',
'price': 'last',
'quantity': 'sum',
'first_trade_id': 'first',
'last_trade_id': 'last',
'is_buyer_maker': 'last',
'date': 'last',
'transact_time':'last'
})
buy_trades['interval']=buy_trades['transact_time'] - buy_trades['transact_time'].shift()
buy_trades.index = buy_trades['date']
[10]에서:
buy_trades['interval'][buy_trades['interval']<1000].plot.hist(bins=200,figsize=(10, 5));
아웃[10]:
[20]에서:
Intervals = np.array(range(0, 1000, 5))
mean_intervals = buy_trades['interval'].mean()
buy_rates = 1000/mean_intervals
probabilities = np.array([np.mean(buy_trades['interval'] > interval) for interval in Intervals])
probabilities_s = np.array([np.e**(-buy_rates*interval/1000) for interval in Intervals])
plt.figure(figsize=(10, 5))
plt.plot(Intervals, probabilities)
plt.plot(Intervals, probabilities_s)
plt.xlabel('Intervals')
plt.ylabel('Probability')
plt.grid(True)
외출[20]:
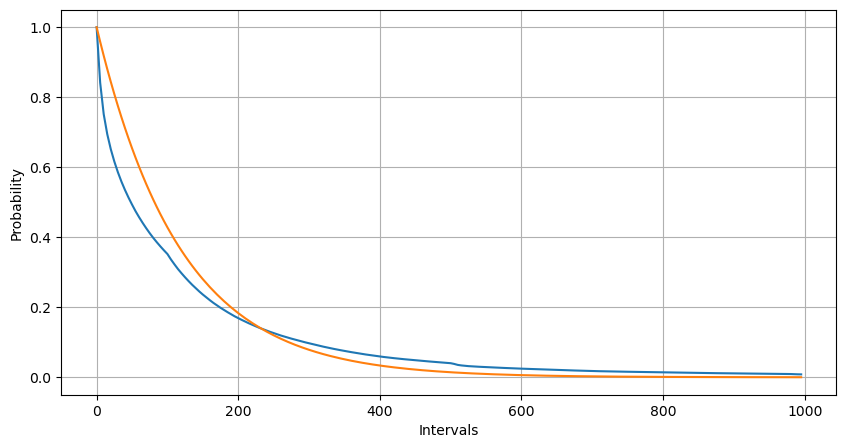
1초 이내에 순서 발생의 수 분포를 포아슨 분포와 비교할 때 차이도 크다. 포아슨 분포는 희귀 사건의 빈도를 크게 과소평가한다.
- 발생률이 일정하지 않은 경우: 포이손 과정은 주어진 시간 간격 내에서 발생하는 사건의 평균 비율이 일정하다고 가정합니다. 이 가정이 맞지 않으면 데이터의 분포가 포이손 분포에서 벗어나게됩니다.
- 프로세스 간의 상호작용: 포이손 프로세스의 또 다른 기본 가정은 사건이 서로 독립한다는 것입니다. 실제 세계의 사건이 서로 상호 작용하면 그 분포는 포이손 분포에서 벗어날 수 있습니다.
즉, 실제 환경에서는 주문 발생 빈도가 일정하지 않으며 실시간으로 업데이트되어야합니다. 고정된 시간 내에 더 많은 주문이 더 많은 주문을 자극하는 인센티브 효과도있을 수 있습니다. 이것은 전략이 단일 고정 매개 변수에 의존할 수 없게합니다.
[190년]
result_df = buy_trades.resample('1S').agg({
'price': 'count',
'quantity': 'sum'
}).rename(columns={'price': 'order_count', 'quantity': 'quantity_sum'})
[219]에서:
count_df = result_df['order_count'].value_counts().sort_index()[result_df['order_count'].value_counts()>20]
(count_df/count_df.sum()).plot(figsize=(10,5),grid=True,label='sample pmf');
from scipy.stats import poisson
prob_values = poisson.pmf(count_df.index, 1000/mean_intervals)
plt.plot(count_df.index, prob_values,label='poisson pmf');
plt.legend() ;
아웃[219]:
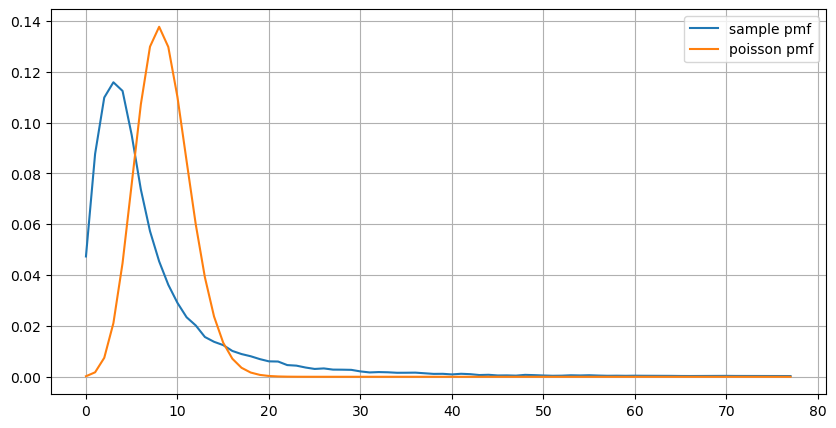
실시간 매개 변수 업데이트
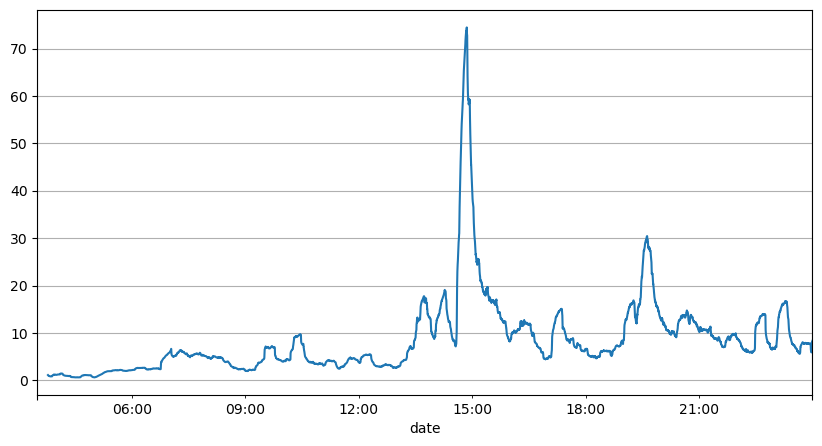
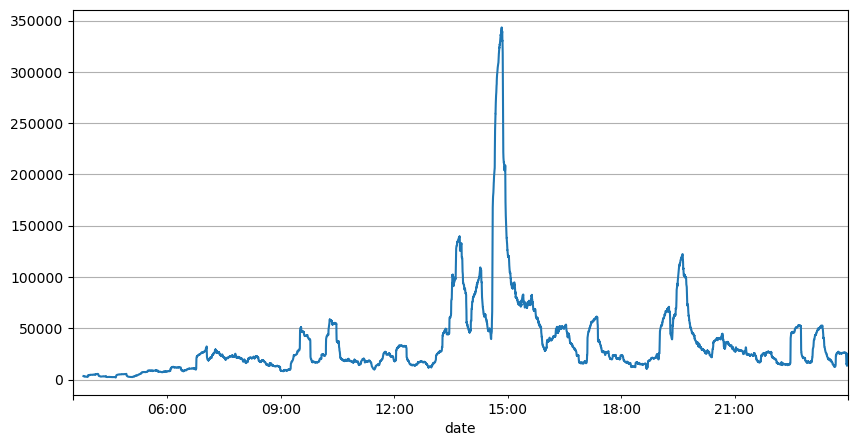
이전 주문 간격 분석을 통해 고정 매개 변수가 실제 시장 조건에 적합하지 않으며 전략에서 시장을 설명하는 주요 매개 변수가 실시간으로 업데이트되어야한다는 결론을 내릴 수 있습니다. 가장 간단한 해결책은 슬라이딩 윈도우 이동 평균을 사용하는 것입니다. 아래의 두 그래프는 1 초 이내에 구매 주문의 빈도와 1000 창 크기의 평균 거래 부피를 보여줍니다. 거래에서 클러스터링 현상이 있음을 관찰 할 수 있습니다. 주문의 빈도가 일정 기간 동안 평소보다 현저히 높고 부피도 동기적으로 증가합니다. 여기서 이전 값의 평균은 최신 값을 예측하는 데 사용되며 잔류값의 평균 오류는 예측의 품질을 측정하는 데 사용됩니다.
그래프에서, 우리는 또한 왜 순위 빈도가 포이슨 분포에서 너무 많이 벗어나는지 이해할 수 있습니다. 초당 평균 순위 수가 8.5에 불과하지만, 극단적인 경우이 값에서 크게 벗어납니다.
예측하기 위해 전 2초의 평균을 사용하는 것이 가장 작은 잔류 오류를 발생시키는 것으로 밝혀졌으며 예측 결과를 위해 평균을 사용하는 것보다 훨씬 낫습니다.
[221]에서:
result_df['order_count'].rolling(1000).mean().plot(figsize=(10,5),grid=True);
외출 [1]:
[193]:
result_df['quantity_sum'].rolling(1000).mean().plot(figsize=(10,5),grid=True);
아웃[193]:
[195]:
(result_df['order_count'] - result_df['mean_count'].mean()).abs().mean()
외출[195]:
6.985628185332997
[205]에서:
result_df['mean_count'] = result_df['order_count'].rolling(2).mean()
(result_df['order_count'] - result_df['mean_count'].shift()).abs().mean()
외출 [1]:
3.091737586730269
요약
이 문서에서는 포이슨 과정에서 주문 시간 간격의 오차의 이유를 간략하게 설명하고 있으며, 이는 주로 시간이 지남에 따라 매개 변수의 변화로 인해 발생합니다. 정확한 시장을 예측하기 위해서는 전략이 시장의 기본 매개 변수에 대한 실시간 예측을 수행해야합니다. 잔류는 예측의 품질을 측정하는 데 사용할 수 있습니다. 위의 예는 간단한 시범이며 특정 시간 계열 분석, 변동성 클러스터링 및 기타 관련 주제에 대한 광범위한 연구가 있으며 위의 시범은 더 향상 될 수 있습니다.
- 웃는 곡선으로 비트코인 옵션에 대한 델타 헤지킹
- 고주파 거래 전략에 대한 생각 (5)
- 고주파 거래 전략에 대한 생각 (4)
- 고주파 거래 전략에 대한 생각 (5)
- 고주파 거래 전략에 대한 생각 (4)
- 높은 주파수 거래 전략에 대한 생각 (3)
- 고주파 거래 전략에 대한 생각 (2)
- 고주파 거래 전략에 대한 생각 (2)
- 고주파 거래 전략에 대한 생각 (1)
- 높은 주파수 거래 전략에 대한 생각 (1)
- 퓨투 증권 구성 설명 문서
- FMZ Quant Uniswap V3 거래소 풀 유동성 관련 거래 안내 (1부)
- FMZ 양적Uniswap V3 교환 풀 유동성 관련 운영 지침서 (1)