시장 코트 수집가 다시 업그레이드
저자:선함, 2020-05-26 14:25:15, 업데이트: 2023-11-02 19:53:34
사용자 지정 데이터 소스를 제공하기 위해 CSV 형식 파일 수입을 지원
최근, 거래자는 자신의 CSV 형식 파일을 FMZ 플랫폼 백테스트 시스템 데이터 소스로 사용해야 합니다. 우리의 플랫폼의 백테스트 시스템은 많은 기능을 가지고 있으며 간단하고 효율적으로 사용할 수 있습니다. 따라서 사용자가 자신의 데이터를 가지고있는 한, 그들은이 데이터에 따라 백테스트를 수행 할 수 있습니다.
디자인 아이디어
디자인 아이디어는 실제로 매우 간단합니다. 우리는 단지 이전 시장 수집자에 기초하여 약간 변경해야합니다. 우리는 매개 변수를 추가isOnlySupportCSV시장 수집자에게 CSV 파일만 백테스트 시스템의 데이터 소스로 사용하는지 확인합니다.filePathForCSV마켓 컬렉터 로봇이 실행되는 서버에 배치된 CSV 데이터 파일의 경로를 설정하는 데 사용됩니다.isOnlySupportCSV매개 변수가True어떤 데이터 소스를 사용할지 결정하기 위해 (자신 또는 CSV 파일의 데이터를 수집),이 변화는 주로do_GET의 역할Provider class.
CSV 파일이란 무엇인가요?
코마로 분리 된 값, CSV로도 알려져 있으며, 때로는 캐릭터로 분리 된 값으로 불리기도 합니다. 왜냐하면 분리 문자 또한 코마가 될 수 없기 때문입니다. 파일은 테이블 데이터 (수와 텍스트) 를 일반 텍스트로 저장합니다. 일반 텍스트는 파일이 문자 순서이며 바이너리 숫자처럼 해석해야 할 데이터가 포함되어 있지 않다는 것을 의미합니다. CSV 파일은 어떤 뉴라인 문자로 분리 된 임의 수의 기록으로 구성됩니다. 각 기록은 필드로 구성되며 필드 사이의 분리자는 다른 문자 또는 문자열이며 가장 일반적인 것은 코마 또는 탭입니다. 일반적으로 모든 기록은 동일한 필드 순서를 가지고 있습니다. 일반적으로 일반 텍스트 파일입니다. 사용하는 것이 좋습니다.WORDPAD또는Excel열기 위해.
CSV 파일 형식의 일반적인 표준은 존재하지 않지만 특정 규칙이 있습니다. 일반적으로 한 줄당 한 레코드, 첫 줄은 헤더입니다. 각 줄의 데이터는 koma로 분리됩니다.
예를 들어, 테스트를 위해 사용한 CSV 파일은 이렇게 메모장으로 열립니다.
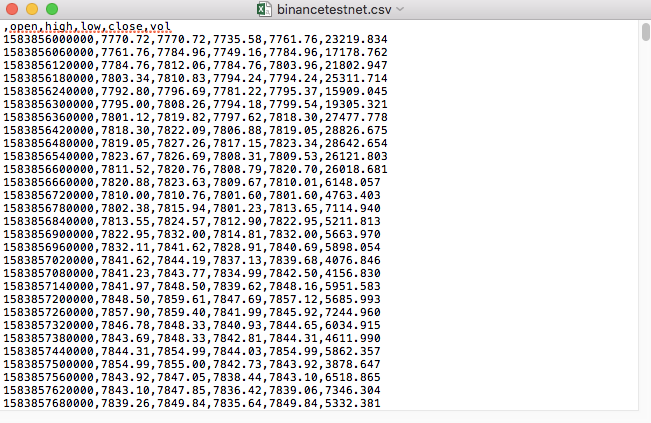
CSV 파일의 첫 번째 줄은 테이블 헤더라는 것을 관찰했습니다.
,open,high,low,close,vol
이 데이터를 분석하고 정렬한 다음 백테스트 시스템의 사용자 지정 데이터 소스가 요구하는 형식으로 구성해야 합니다.
변경된 코드
import _thread
import pymongo
import json
import math
import csv
from http.server import HTTPServer, BaseHTTPRequestHandler
from urllib.parse import parse_qs, urlparse
def url2Dict(url):
query = urlparse(url).query
params = parse_qs(query)
result = {key: params[key][0] for key in params}
return result
class Provider(BaseHTTPRequestHandler):
def do_GET(self):
global isOnlySupportCSV, filePathForCSV
try:
self.send_response(200)
self.send_header("Content-type", "application/json")
self.end_headers()
dictParam = url2Dict(self.path)
Log("The custom data source service receives the request,self.path:", self.path, "query parameter:", dictParam)
# At present, the backtest system can only select the exchange name from the list. When adding a custom data source, set it to Binance, that is: Binance
exName = exchange.GetName()
# Note that period is the bottom K-line period
tabName = "%s_%s" % ("records", int(int(dictParam["period"]) / 1000))
priceRatio = math.pow(10, int(dictParam["round"]))
amountRatio = math.pow(10, int(dictParam["vround"]))
fromTS = int(dictParam["from"]) * int(1000)
toTS = int(dictParam["to"]) * int(1000)
# Request data
data = {
"schema" : ["time", "open", "high", "low", "close", "vol"],
"data" : []
}
if isOnlySupportCSV:
# Handle CSV reading, filePathForCSV path
listDataSequence = []
with open(filePathForCSV, "r") as f:
reader = csv.reader(f)
# Get table header
header = next(reader)
headerIsNoneCount = 0
if len(header) != len(data["schema"]):
Log("The CSV file format is wrong, the number of columns is different, please check!", "#FF0000")
return
for ele in header:
for i in range(len(data["schema"])):
if data["schema"][i] == ele or ele == "":
if ele == "":
headerIsNoneCount += 1
if headerIsNoneCount > 1:
Log("The CSV file format is incorrect, please check!", "#FF0000")
return
listDataSequence.append(i)
break
# Read content
while True:
record = next(reader, -1)
if record == -1:
break
index = 0
arr = [0, 0, 0, 0, 0, 0]
for ele in record:
arr[listDataSequence[index]] = int(ele) if listDataSequence[index] == 0 else (int(float(ele) * amountRatio) if listDataSequence[index] == 5 else int(float(ele) * priceRatio))
index += 1
data["data"].append(arr)
Log("data: ", data, "Respond to backtest system requests.")
self.wfile.write(json.dumps(data).encode())
return
# Connect to the database
Log("Connect to the database service to obtain data, the database: ", exName, "table: ", tabName)
myDBClient = pymongo.MongoClient("mongodb://localhost:27017")
ex_DB = myDBClient[exName]
exRecords = ex_DB[tabName]
# Construct query conditions: greater than a certain value {'age': {'$ gt': 20}} less than a certain value {'age': {'$lt': 20}}
dbQuery = {"$and":[{'Time': {'$gt': fromTS}}, {'Time': {'$lt': toTS}}]}
Log("Query conditions: ", dbQuery, "Number of inquiries: ", exRecords.find(dbQuery).count(), "Total number of databases: ", exRecords.find().count())
for x in exRecords.find(dbQuery).sort("Time"):
# Need to process data accuracy according to request parameters round and vround
bar = [x["Time"], int(x["Open"] * priceRatio), int(x["High"] * priceRatio), int(x["Low"] * priceRatio), int(x["Close"] * priceRatio), int(x["Volume"] * amountRatio)]
data["data"].append(bar)
Log("data: ", data, "Respond to backtest system requests.")
# Write data response
self.wfile.write(json.dumps(data).encode())
except BaseException as e:
Log("Provider do_GET error, e:", e)
def createServer(host):
try:
server = HTTPServer(host, Provider)
Log("Starting server, listen at: %s:%s" % host)
server.serve_forever()
except BaseException as e:
Log("createServer error, e:", e)
raise Exception("stop")
def main():
LogReset(1)
if (isOnlySupportCSV):
try:
# _thread.start_new_thread(createServer, (("localhost", 9090), )) # local test
_thread.start_new_thread(createServer, (("0.0.0.0", 9090), )) # Test on VPS server
Log("Start the custom data source service thread, and the data is provided by the CSV file. ", "#FF0000")
except BaseException as e:
Log("Failed to start the custom data source service!")
Log("Error message: ", e)
raise Exception("stop")
while True:
LogStatus(_D(), "Only start the custom data source service, do not collect data!")
Sleep(2000)
exName = exchange.GetName()
period = exchange.GetPeriod()
Log("collect", exName, "Exchange K-line data,", "K line cycle:", period, "Second")
# Connect to the database service, service address mongodb: //127.0.0.1: 27017 See the settings of mongodb installed on the server
Log("Connect to the mongodb service of the hosting device, mongodb://localhost:27017")
myDBClient = pymongo.MongoClient("mongodb://localhost:27017")
# Create a database
ex_DB = myDBClient[exName]
# Print the current database table
collist = ex_DB.list_collection_names()
Log("mongodb", exName, "collist:", collist)
# Check if the table is deleted
arrDropNames = json.loads(dropNames)
if isinstance(arrDropNames, list):
for i in range(len(arrDropNames)):
dropName = arrDropNames[i]
if isinstance(dropName, str):
if not dropName in collist:
continue
tab = ex_DB[dropName]
Log("dropName:", dropName, "delete:", dropName)
ret = tab.drop()
collist = ex_DB.list_collection_names()
if dropName in collist:
Log(dropName, "failed to delete")
else :
Log(dropName, "successfully deleted")
# Start a thread to provide a custom data source service
try:
# _thread.start_new_thread(createServer, (("localhost", 9090), )) # local test
_thread.start_new_thread(createServer, (("0.0.0.0", 9090), )) # Test on VPS server
Log("Open the custom data source service thread", "#FF0000")
except BaseException as e:
Log("Failed to start the custom data source service!")
Log("Error message:", e)
raise Exception("stop")
# Create the records table
ex_DB_Records = ex_DB["%s_%d" % ("records", period)]
Log("Start collecting", exName, "K-line data", "cycle:", period, "Open (create) the database table:", "%s_%d" % ("records", period), "#FF0000")
preBarTime = 0
index = 1
while True:
r = _C(exchange.GetRecords)
if len(r) < 2:
Sleep(1000)
continue
if preBarTime == 0:
# Write all BAR data for the first time
for i in range(len(r) - 1):
bar = r[i]
# Write root by root, you need to determine whether the data already exists in the current database table, based on timestamp detection, if there is the data, then skip, if not write
retQuery = ex_DB_Records.find({"Time": bar["Time"]})
if retQuery.count() > 0:
continue
# Write bar to the database table
ex_DB_Records.insert_one({"High": bar["High"], "Low": bar["Low"], "Open": bar["Open"], "Close": bar["Close"], "Time": bar["Time"], "Volume": bar["Volume"]})
index += 1
preBarTime = r[-1]["Time"]
elif preBarTime != r[-1]["Time"]:
bar = r[-2]
# Check before writing data, whether the data already exists, based on time stamp detection
retQuery = ex_DB_Records.find({"Time": bar["Time"]})
if retQuery.count() > 0:
continue
ex_DB_Records.insert_one({"High": bar["High"], "Low": bar["Low"], "Open": bar["Open"], "Close": bar["Close"], "Time": bar["Time"], "Volume": bar["Volume"]})
index += 1
preBarTime = r[-1]["Time"]
LogStatus(_D(), "preBarTime:", preBarTime, "_D(preBarTime):", _D(preBarTime/1000), "index:", index)
# Increase drawing display
ext.PlotRecords(r, "%s_%d" % ("records", period))
Sleep(10000)
실행 테스트
먼저 시장 수집 로봇을 작동시키고 로봇에 교환을 추가하고 로봇을 실행하도록 합니다.
매개 변수 구성:

그 다음 테스트 전략을 만들죠.
function main() {
Log(exchange.GetRecords())
Log(exchange.GetRecords())
Log(exchange.GetRecords())
}
전략은 매우 간단합니다. K-라인 데이터를 3번만 받아서 인쇄합니다.
백테스트 페이지에서 백테스트 시스템의 데이터 소스를 사용자 정의 데이터 소스로 설정하고 시장 수집 로봇이 실행되는 서버 주소를 입력합니다. CSV 파일의 데이터는 1 분 K 라인입니다. 그래서 백테스트 할 때 K 라인 기간을 1 분으로 설정합니다.
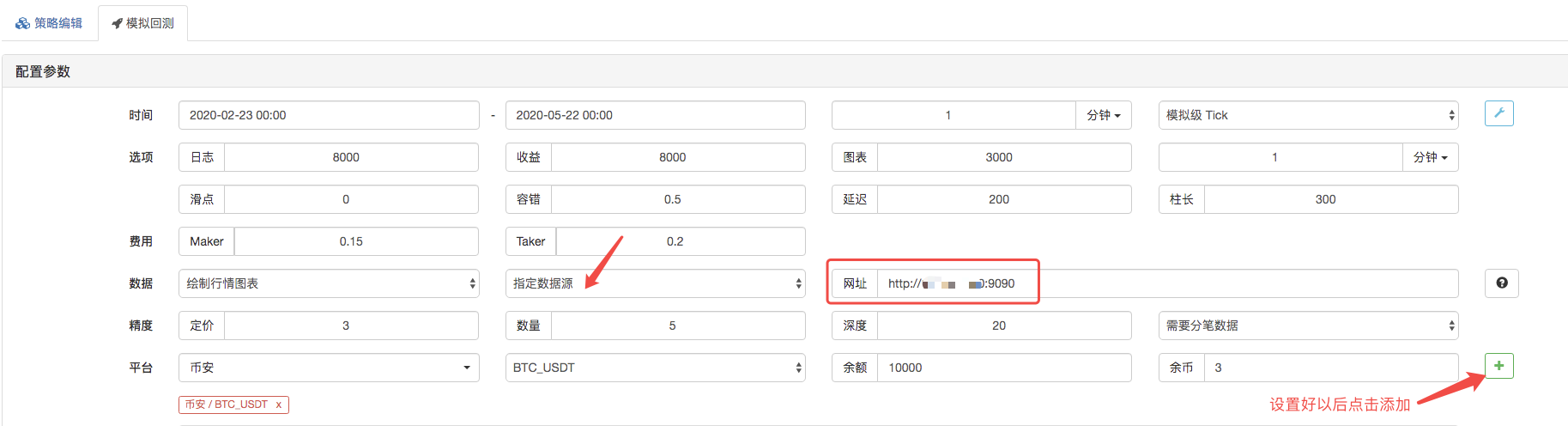
백테스트를 시작하기 위해 클릭하면 시장 수집 로봇이 데이터 요청을 수신합니다.

백테스트 시스템의 실행 전략이 완료되면 데이터 소스의 K-라인 데이터를 기반으로 K-라인 차트가 생성됩니다.
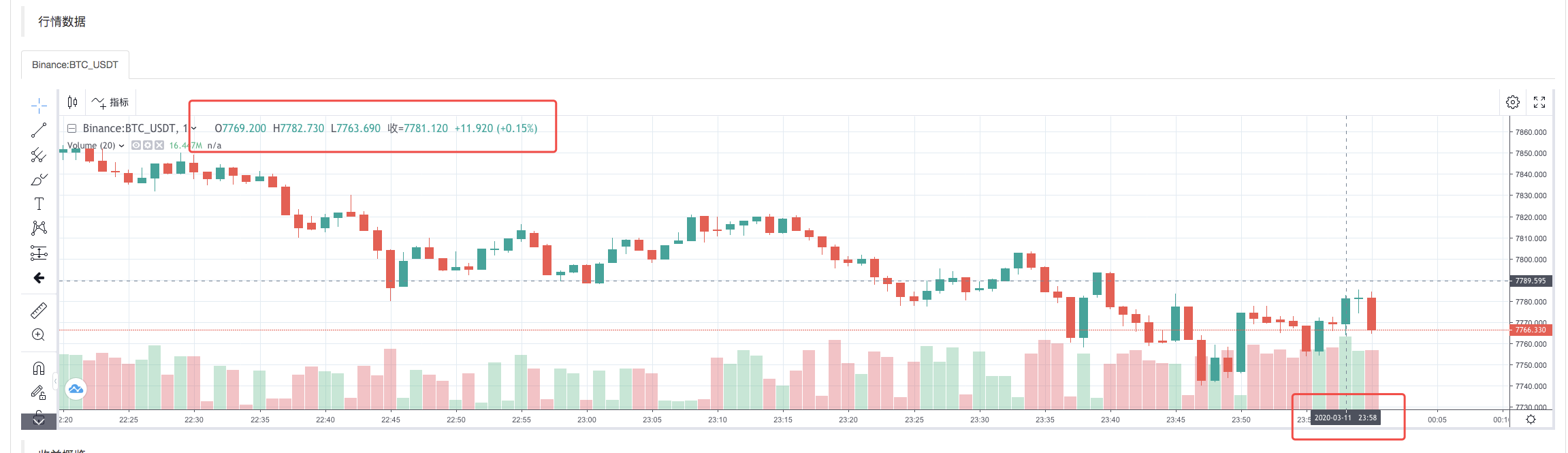
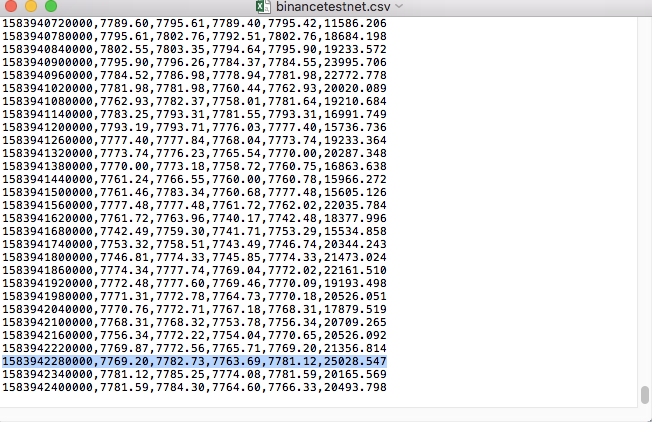
파일의 데이터를 비교하세요:

- 암호화폐 시장의 근본 분석을 정량화: 데이터를 스스로 이야기하도록!
- 동전圈의 기초적인 양적 연구 - 더 이상 모든
선생님들을 믿지 말고, 데이터를 객관적으로 이야기하십시오! - 양적 거래의 필수 도구 - 발명자 양적 데이터 탐색 모듈
- 모든 것을 마스터 - FMZ에 대한 소개 트레이딩 터미널의 새로운 버전 (TRB 중재 소스 코드)
- FMZ의 새로운 거래 단말기 소개 (TRB 리비트 소스 추가)
- FMZ 퀀트: 암호화폐 시장에서 공통 요구 사항 설계 예제 분석 (II)
- 80 줄의 코드에서 고주파 전략으로 뇌 없는 판매봇을 이용하는 방법
- FMZ 정량화: 암호화폐 시장의 일반적인 요구 디자인 사례 분석 (II)
- 80줄의 코드의 고주파 전략으로 뇌 없는 로봇을 파는 방법
- FMZ Quant: 암호화폐 시장에서 공통 요구 사항 디자인 예의 분석 (I)
- FMZ 정량화: 암호화폐 시장의 일반적인 요구 디자인 사례 분석 (1)