Pemikiran mengenai Strategi Dagangan Frekuensi Tinggi (2)
Penulis:Lydia, Dicipta: 2023-08-04 17:17:30, Dikemas kini: 2023-09-12 15:50:31
Pemikiran mengenai Strategi Dagangan Frekuensi Tinggi (2)
Model Jumlah Dagangan Berkumulatif
Dalam artikel sebelumnya, kita menyalurkan ungkapan untuk kebarangkalian jumlah perdagangan tunggal yang lebih besar daripada nilai tertentu.
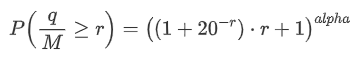
Kami juga berminat dengan pengedaran jumlah dagangan dalam tempoh masa, yang secara intuitif harus berkaitan dengan jumlah dagangan individu dan kekerapan pesanan.
Dalam [1]:
from datetime import date,datetime
import time
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
Dalam [2]:
trades = pd.read_csv('HOOKUSDT-aggTrades-2023-01-27.csv')
trades['date'] = pd.to_datetime(trades['transact_time'], unit='ms')
trades.index = trades['date']
buy_trades = trades[trades['is_buyer_maker']==False].copy()
buy_trades = buy_trades.groupby('transact_time').agg({
'agg_trade_id': 'last',
'price': 'last',
'quantity': 'sum',
'first_trade_id': 'first',
'last_trade_id': 'last',
'is_buyer_maker': 'last',
'date': 'last',
'transact_time':'last'
})
buy_trades['interval']=buy_trades['transact_time'] - buy_trades['transact_time'].shift()
buy_trades.index = buy_trades['date']
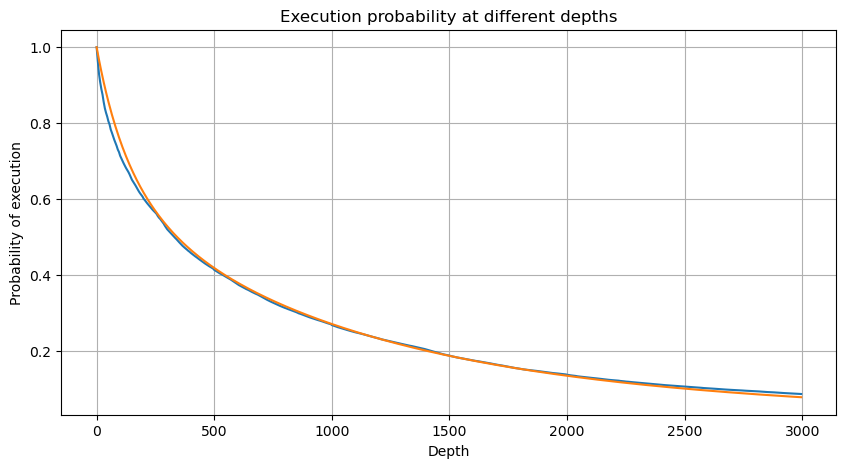
Kami menggabungkan jumlah dagangan individu pada selang 1 saat untuk mendapatkan jumlah dagangan agregat, tidak termasuk tempoh tanpa aktiviti dagangan. Kami kemudian menyesuaikan jumlah agregat ini menggunakan pengagihan yang berasal dari analisis jumlah dagangan tunggal yang disebutkan sebelumnya. Hasilnya menunjukkan kesesuaian yang baik apabila mempertimbangkan setiap dagangan dalam selang 1 saat sebagai satu dagangan, dengan berkesan menyelesaikan masalah. Walau bagaimanapun, apabila selang masa diperpanjang berbanding dengan kekerapan dagangan, kami melihat peningkatan kesilapan. Penyelidikan lanjut mendedahkan bahawa kesilapan ini disebabkan oleh istilah pembetulan yang diperkenalkan oleh pengagihan Pareto. Ini menunjukkan bahawa apabila tempoh masa memanjang dan merangkumi lebih banyak dagangan individu, pengumpulan pelbagai dagangan mendekati pengagihan Pareto lebih dekat, memerlukan penghapusan istilah pembetulan.
Dalam [3]:
df_resampled = buy_trades['quantity'].resample('1S').sum()
df_resampled = df_resampled.to_frame(name='quantity')
df_resampled = df_resampled[df_resampled['quantity']>0]
Dalam [4]:
# Cumulative distribution in 1s
depths = np.array(range(0, 3000, 5))
probabilities = np.array([np.mean(df_resampled['quantity'] > depth) for depth in depths])
mean = df_resampled['quantity'].mean()
alpha = np.log(np.mean(df_resampled['quantity'] > mean))/np.log(2.05)
probabilities_s = np.array([((1+20**(-depth/mean))*depth/mean+1)**(alpha) for depth in depths])
plt.figure(figsize=(10, 5))
plt.plot(depths, probabilities)
plt.plot(depths, probabilities_s)
plt.xlabel('Depth')
plt.ylabel('Probability of execution')
plt.title('Execution probability at different depths')
plt.grid(True)
Keluar[4]:
Dalam [5]:
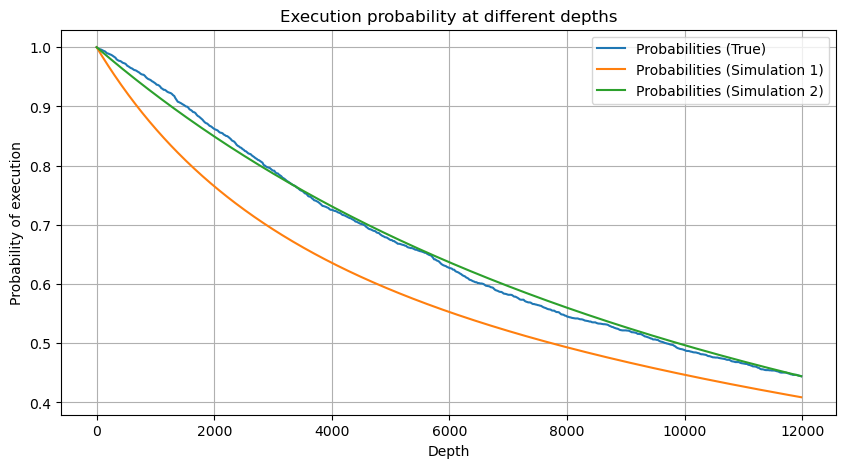
df_resampled = buy_trades['quantity'].resample('30S').sum()
df_resampled = df_resampled.to_frame(name='quantity')
df_resampled = df_resampled[df_resampled['quantity']>0]
depths = np.array(range(0, 12000, 20))
probabilities = np.array([np.mean(df_resampled['quantity'] > depth) for depth in depths])
mean = df_resampled['quantity'].mean()
alpha = np.log(np.mean(df_resampled['quantity'] > mean))/np.log(2.05)
probabilities_s = np.array([((1+20**(-depth/mean))*depth/mean+1)**(alpha) for depth in depths])
alpha = np.log(np.mean(df_resampled['quantity'] > mean))/np.log(2)
probabilities_s_2 = np.array([(depth/mean+1)**alpha for depth in depths]) # No amendment
plt.figure(figsize=(10, 5))
plt.plot(depths, probabilities,label='Probabilities (True)')
plt.plot(depths, probabilities_s, label='Probabilities (Simulation 1)')
plt.plot(depths, probabilities_s_2, label='Probabilities (Simulation 2)')
plt.xlabel('Depth')
plt.ylabel('Probability of execution')
plt.title('Execution probability at different depths')
plt.legend()
plt.grid(True)
Keluar[5]:
Sekarang meringkaskan formula umum untuk pengedaran jumlah dagangan terkumpul untuk tempoh masa yang berbeza, menggunakan pengedaran jumlah urus niaga tunggal untuk muat, bukannya mengira secara berasingan setiap kali.
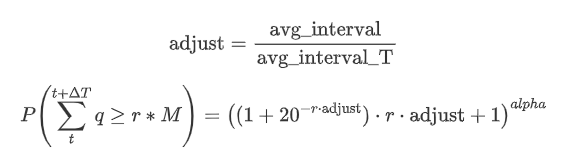
Di sini, avg_interval mewakili selang purata transaksi tunggal, dan avg_interval_T mewakili selang purata selang yang perlu dianggarkan. Ia mungkin terdengar agak mengelirukan. Jika kita ingin menganggarkan jumlah dagangan untuk 1 saat, kita perlu mengira selang purata antara peristiwa yang mengandungi transaksi dalam masa 1 saat. Jika kebarangkalian ketibaan pesanan mengikuti pengedaran Poisson, ia harus langsung boleh dianggarkan. Walau bagaimanapun, pada hakikatnya, terdapat penyimpangan yang ketara, tetapi saya tidak akan membincangkannya di sini.
Perhatikan bahawa kebarangkalian jumlah dagangan melebihi nilai tertentu dalam selang masa tertentu dan kebarangkalian sebenar perdagangan di kedudukan itu dalam kedalaman harus sangat berbeza. Apabila masa menunggu meningkat, kemungkinan perubahan dalam buku pesanan meningkat, dan perdagangan juga membawa kepada perubahan kedalaman. Oleh itu, kebarangkalian perdagangan di kedudukan kedalaman yang sama berubah dalam masa nyata sebagai kemas kini data.
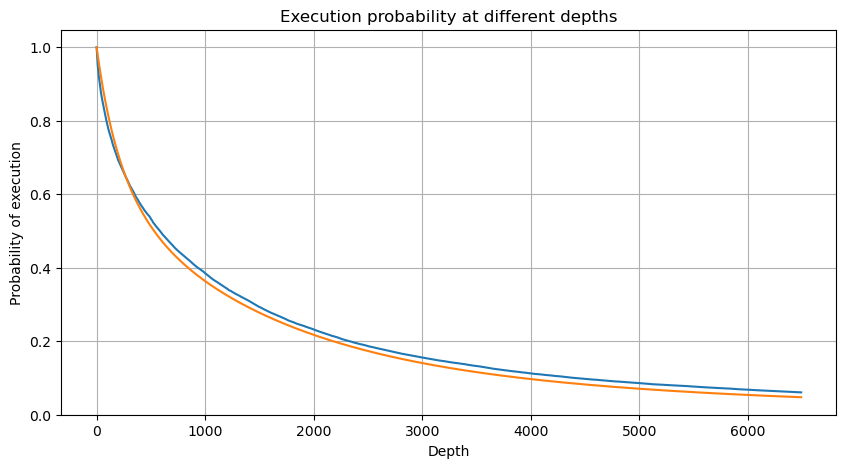
Dalam [6]:
df_resampled = buy_trades['quantity'].resample('2S').sum()
df_resampled = df_resampled.to_frame(name='quantity')
df_resampled = df_resampled[df_resampled['quantity']>0]
depths = np.array(range(0, 6500, 10))
probabilities = np.array([np.mean(df_resampled['quantity'] > depth) for depth in depths])
mean = buy_trades['quantity'].mean()
adjust = buy_trades['interval'].mean() / 2620
alpha = np.log(np.mean(buy_trades['quantity'] > mean))/0.7178397931503168
probabilities_s = np.array([((1+20**(-depth*adjust/mean))*depth*adjust/mean+1)**(alpha) for depth in depths])
plt.figure(figsize=(10, 5))
plt.plot(depths, probabilities)
plt.plot(depths, probabilities_s)
plt.xlabel('Depth')
plt.ylabel('Probability of execution')
plt.title('Execution probability at different depths')
plt.grid(True)
Keluar[6]:
Kesan Harga Perdagangan Tunggal
Data perdagangan adalah berharga, dan masih ada banyak data yang boleh digali. Kita harus memberi perhatian kepada kesan pesanan pada harga, kerana ini mempengaruhi kedudukan strategi. Begitu juga, mengumpul data berdasarkan masa transaksi, kita mengira perbezaan antara harga terakhir dan harga pertama. Jika hanya ada satu pesanan, perbezaan harga adalah 0. Menariknya, terdapat beberapa hasil data yang negatif, yang mungkin disebabkan oleh susunan data, tetapi kita tidak akan menggali di sini.
Hasilnya menunjukkan bahawa peratusan dagangan yang tidak menyebabkan sebarang kesan adalah setinggi 77%, sementara peratusan dagangan yang menyebabkan pergerakan harga 1 tik adalah 16.5%, 2 tik adalah 3.7%, 3 tik adalah 1.2%, dan lebih daripada 4 tik adalah kurang dari 1%.
Jumlah perdagangan yang menyebabkan perbezaan harga yang sepadan juga dianalisis, tidak termasuk gangguan yang disebabkan oleh kesan yang berlebihan. Ia menunjukkan hubungan linear, dengan kira-kira 1 tanda turun naik harga yang disebabkan oleh setiap 1000 unit jumlah. Ini juga boleh difahami sebagai purata sekitar 1000 unit pesanan yang diletakkan berhampiran setiap tahap harga dalam buku pesanan.
Dalam [7]:
diff_df = trades[trades['is_buyer_maker']==False].groupby('transact_time')['price'].agg(lambda x: abs(round(x.iloc[-1] - x.iloc[0],3)) if len(x) > 1 else 0)
buy_trades['diff'] = buy_trades['transact_time'].map(diff_df)
Dalam [8]:
diff_counts = buy_trades['diff'].value_counts()
diff_counts[diff_counts>10]/diff_counts.sum()
Keluar[8]:
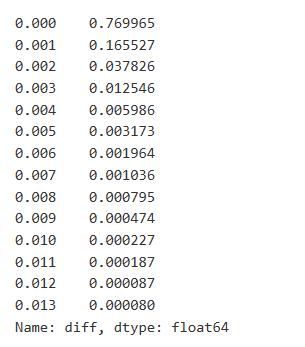
Dalam [9]:
diff_group = buy_trades.groupby('diff').agg({
'quantity': 'mean',
'diff': 'last',
})
Dalam [10]:
diff_group['quantity'][diff_group['diff']>0][diff_group['diff']<0.01].plot(figsize=(10,5),grid=True);
Keluar[10]:
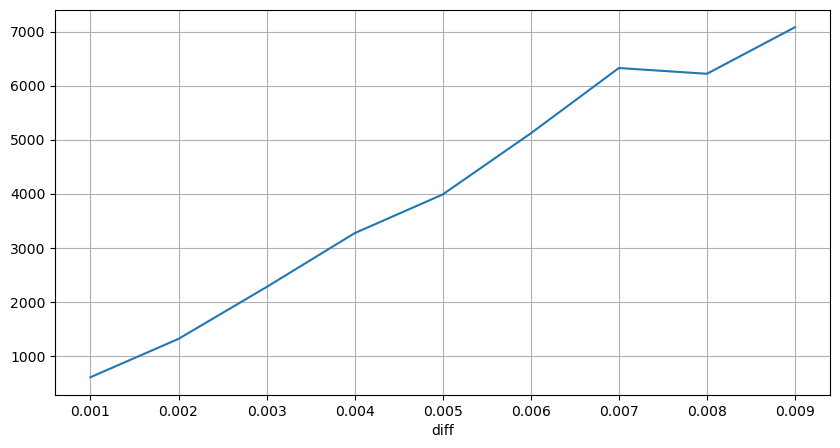
Kesan Harga Interval Tetap
Mari kita menganalisis kesan harga dalam selang 2 saat. Perbezaannya di sini adalah bahawa mungkin terdapat nilai negatif. Walau bagaimanapun, kerana kita hanya mempertimbangkan pesanan beli, kesan pada kedudukan simetri akan menjadi satu tik lebih tinggi. Terus memerhatikan hubungan antara jumlah perdagangan dan kesan, kita hanya menganggap hasil lebih besar daripada 0. Kesimpulan ini serupa dengan pesanan tunggal, menunjukkan hubungan linear kira-kira, dengan kira-kira 2000 unit jumlah yang diperlukan untuk setiap tik.
Dalam [11]:
df_resampled = buy_trades.resample('2S').agg({
'price': ['first', 'last', 'count'],
'quantity': 'sum'
})
df_resampled['price_diff'] = round(df_resampled[('price', 'last')] - df_resampled[('price', 'first')],3)
df_resampled['price_diff'] = df_resampled['price_diff'].fillna(0)
result_df_raw = pd.DataFrame({
'price_diff': df_resampled['price_diff'],
'quantity_sum': df_resampled[('quantity', 'sum')],
'data_count': df_resampled[('price', 'count')]
})
result_df = result_df_raw[result_df_raw['price_diff'] != 0]
Dalam [12]:
result_df['price_diff'][abs(result_df['price_diff'])<0.016].value_counts().sort_index().plot.bar(figsize=(10,5));
Keluar[12]:
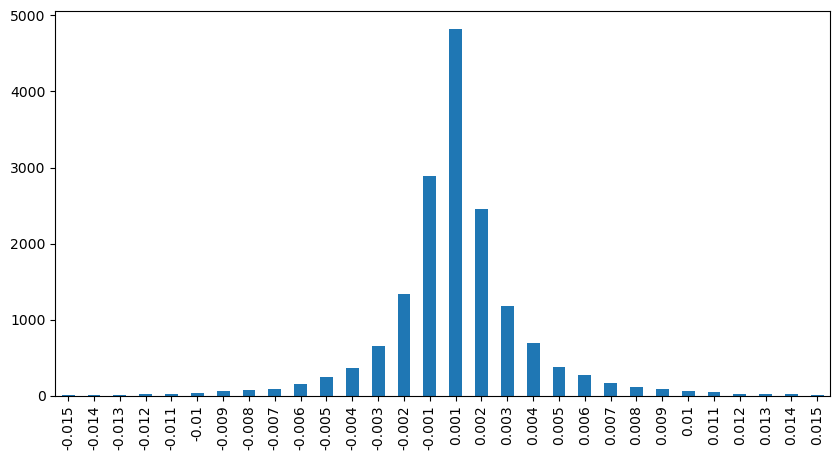
Dalam [23]:
result_df['price_diff'].value_counts()[result_df['price_diff'].value_counts()>30]
Keluar[23]:
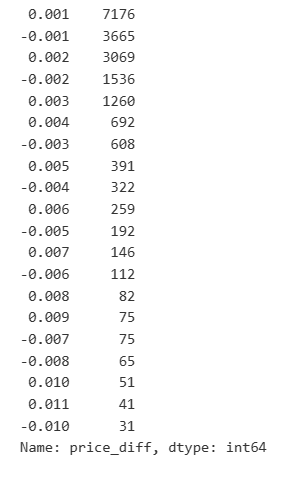
Dalam [14]:
diff_group = result_df.groupby('price_diff').agg({ 'quantity_sum': 'mean'})
Dalam [15]:
diff_group[(diff_group.index>0) & (diff_group.index<0.015)].plot(figsize=(10,5),grid=True);
Keluar[15]:
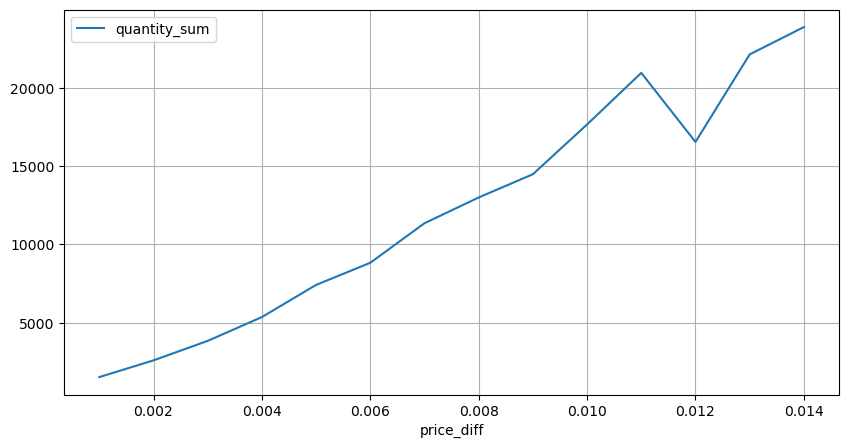
Kesan Harga Jumlah Perdagangan
Sebelum ini, kita menentukan jumlah perdagangan yang diperlukan untuk perubahan tanda, tetapi ia tidak tepat kerana ia berdasarkan andaian bahawa kesan telah berlaku.
Dalam analisis ini, data diambil sampel setiap 1 saat, dengan setiap langkah mewakili 100 unit jumlah.
- Apabila jumlah pesanan beli adalah di bawah 500, perubahan harga yang dijangkakan adalah penurunan, yang seperti yang dijangkakan kerana terdapat juga pesanan jual yang mempengaruhi harga.
- Pada jumlah perdagangan yang lebih rendah, terdapat hubungan linear, yang bermaksud bahawa semakin besar jumlah perdagangan, semakin besar kenaikan harga.
- Apabila jumlah pesanan beli meningkat, perubahan harga menjadi lebih ketara. Ini sering menunjukkan kejayaan harga, yang kemudiannya boleh merosot. Di samping itu, pengambilan sampel selang tetap menambah ketidakstabilan data.
- Adalah penting untuk memberi perhatian kepada bahagian atas grafik penyebaran, yang sepadan dengan peningkatan harga dengan jumlah perdagangan.
- Untuk pasangan dagangan tertentu ini, kami memberikan versi kasar hubungan antara jumlah dagangan dan perubahan harga.
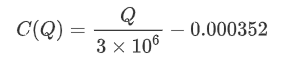
Di mana
Dalam [16]:
df_resampled = buy_trades.resample('1S').agg({
'price': ['first', 'last', 'count'],
'quantity': 'sum'
})
df_resampled['price_diff'] = round(df_resampled[('price', 'last')] - df_resampled[('price', 'first')],3)
df_resampled['price_diff'] = df_resampled['price_diff'].fillna(0)
result_df_raw = pd.DataFrame({
'price_diff': df_resampled['price_diff'],
'quantity_sum': df_resampled[('quantity', 'sum')],
'data_count': df_resampled[('price', 'count')]
})
result_df = result_df_raw[result_df_raw['price_diff'] != 0]
Dalam [24]:
df = result_df.copy()
bins = np.arange(0, 30000, 100) #
labels = [f'{i}-{i+100-1}' for i in bins[:-1]]
df.loc[:, 'quantity_group'] = pd.cut(df['quantity_sum'], bins=bins, labels=labels)
grouped = df.groupby('quantity_group')['price_diff'].mean()
Dalam [25]:
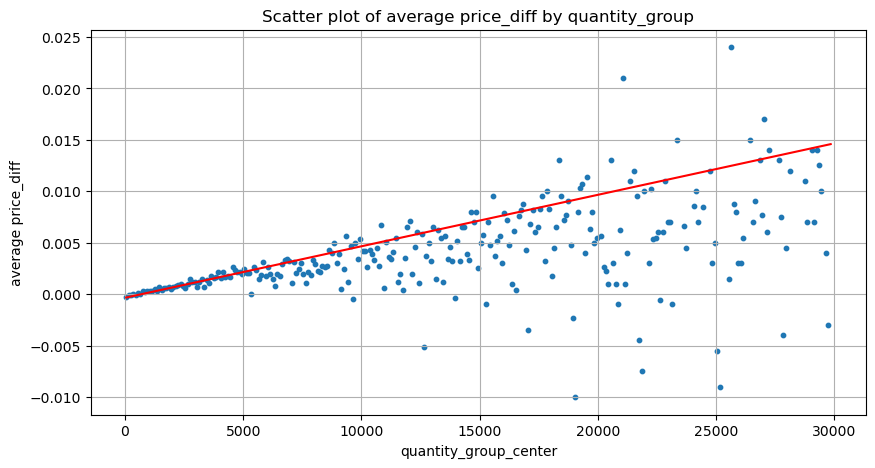
grouped_df = pd.DataFrame(grouped).reset_index()
grouped_df['quantity_group_center'] = grouped_df['quantity_group'].apply(lambda x: (float(x.split('-')[0]) + float(x.split('-')[1])) / 2)
plt.figure(figsize=(10,5))
plt.scatter(grouped_df['quantity_group_center'], grouped_df['price_diff'],s=10)
plt.plot(grouped_df['quantity_group_center'], np.array(grouped_df['quantity_group_center'].values)/2e6-0.000352,color='red')
plt.xlabel('quantity_group_center')
plt.ylabel('average price_diff')
plt.title('Scatter plot of average price_diff by quantity_group')
plt.grid(True)
Keluar[25]:
Dalam [19]:
grouped_df.head(10)
Keluar[19]: ,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,
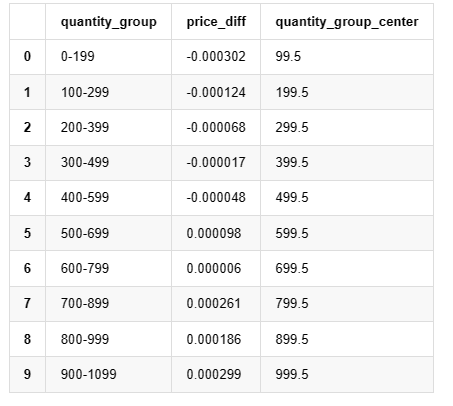
Penempatan pesanan optimum awal
Dengan pemodelan jumlah dagangan dan model kasar kesan harga yang sepadan dengan jumlah dagangan, nampaknya mungkin untuk mengira penempatan pesanan yang optimum.
- Mengandaikan bahawa harga kembali ke nilai asalnya selepas kesan (yang sangat tidak mungkin dan memerlukan analisis lanjut mengenai perubahan harga selepas kesan).
- Anggaplah bahawa pengedaran jumlah dagangan dan kekerapan pesanan dalam tempoh ini mengikuti corak yang telah ditetapkan (yang juga tidak tepat, kerana kami menganggarkan berdasarkan data satu hari dan perdagangan menunjukkan fenomena pengelompokan yang jelas).
- Anggap bahawa hanya satu pesanan jual berlaku semasa masa yang disimulasikan dan kemudian ditutup.
- Misalkan selepas pesanan dilaksanakan, terdapat pesanan beli lain yang terus mendorong harga naik, terutamanya apabila jumlahnya sangat rendah. kesan ini diabaikan di sini, dan hanya diasumsikan bahawa harga akan merosot.
Mari kita mulakan dengan menulis pulangan yang dijangkakan yang mudah, yang merupakan kebarangkalian pesanan pembelian kumulatif melebihi Q dalam masa 1 saat, didarabkan dengan kadar pulangan yang dijangkakan (iaitu, kesan harga).
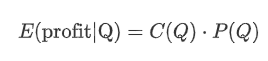
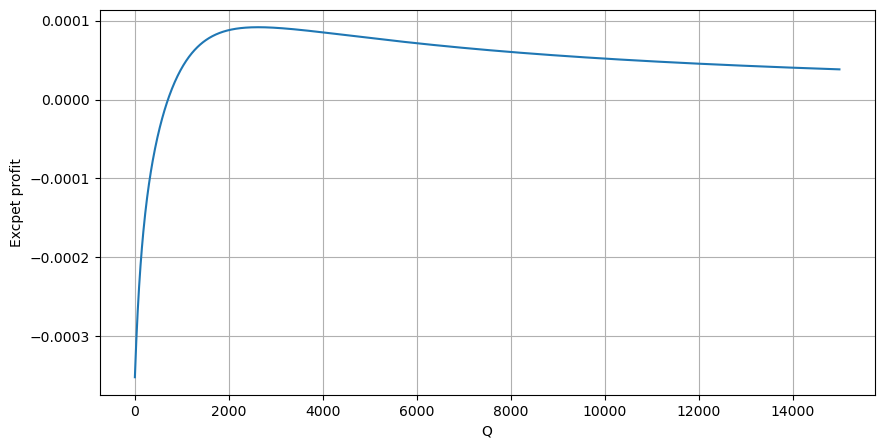
Berdasarkan grafik, pulangan maksimum yang dijangkakan adalah kira-kira 2500, iaitu kira-kira 2.5 kali jumlah dagangan purata. Ini menunjukkan bahawa pesanan jual harus diletakkan pada kedudukan harga 2500. Penting untuk menekankan bahawa paksi mendatar mewakili jumlah dagangan dalam masa 1 saat dan tidak boleh disamakan dengan kedudukan kedalaman. Di samping itu, analisis ini berdasarkan data dagangan dan tidak mempunyai data kedalaman yang penting.
Ringkasan
Kami telah menemui bahawa pengedaran jumlah dagangan pada selang masa yang berbeza adalah skala sederhana pengedaran jumlah dagangan individu. Kami juga telah membangunkan model pulangan yang dijangka yang mudah berdasarkan kesan harga dan kebarangkalian perdagangan. Hasil model ini sejajar dengan jangkaan kami, menunjukkan bahawa jika jumlah pesanan jual rendah, ia menunjukkan penurunan harga, dan sejumlah tertentu diperlukan untuk potensi keuntungan. Kebarangkalian berkurangan apabila jumlah perdagangan meningkat, dengan saiz optimum di antara, yang mewakili strategi penempatan pesanan yang optimum. Walau bagaimanapun, model ini masih terlalu sederhana. Dalam artikel seterusnya, saya akan menggali lebih dalam topik ini.
Dalam [20]:
# Cumulative distribution in 1s
df_resampled = buy_trades['quantity'].resample('1S').sum()
df_resampled = df_resampled.to_frame(name='quantity')
df_resampled = df_resampled[df_resampled['quantity']>0]
depths = np.array(range(0, 15000, 10))
mean = df_resampled['quantity'].mean()
alpha = np.log(np.mean(df_resampled['quantity'] > mean))/np.log(2.05)
probabilities_s = np.array([((1+20**(-depth/mean))*depth/mean+1)**(alpha) for depth in depths])
profit_s = np.array([depth/2e6-0.000352 for depth in depths])
plt.figure(figsize=(10, 5))
plt.plot(depths, probabilities_s*profit_s)
plt.xlabel('Q')
plt.ylabel('Excpet profit')
plt.grid(True)
Keluar[20]:
- Delta Hedge Bitcoin Options dengan Gelak Curve
- Pemikiran mengenai Strategi Dagangan Frekuensi Tinggi (5)
- Pemikiran mengenai Strategi Perdagangan Frekuensi Tinggi (4)
- Berfikir tentang strategi perdagangan frekuensi tinggi (5)
- Memikirkan strategi perdagangan frekuensi tinggi (4)
- Pemikiran mengenai Strategi Dagangan Frekuensi Tinggi (3)
- Pemikiran mengenai strategi perdagangan frekuensi tinggi (3)
- Berfikir tentang strategi perdagangan frekuensi tinggi ((2)
- Pemikiran mengenai Strategi Dagangan Frekuensi Tinggi (1)
- Memikirkan strategi perdagangan frekuensi tinggi (1)
- Dokumen Penerangan Konfigurasi Sekuriti Futu
- FMZ Quant Uniswap V3 Exchange Pool Liquidity Related Operations Guide (Bahagian 1)
- FMZ Kuantitatif Uniswap V3 Panduan Operasi yang berkaitan dengan Likuiditi Kolam Pertukaran (1)