Reflexões sobre estratégias de negociação de alta frequência (2)
Autora:Lydia., Criado: 2023-08-04 17:17:30, Atualizado: 2023-09-12 15:50:31
Reflexões sobre estratégias de negociação de alta frequência (2)
Modelagem do montante de negociação acumulado
No artigo anterior, nós derivamos uma expressão para a probabilidade de um único valor de comércio ser maior do que um certo valor.
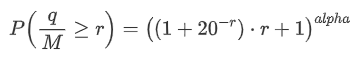
Também estamos interessados na distribuição do valor da negociação ao longo de um período de tempo, que intuitivamente deve estar relacionado com o valor da negociação individual e a frequência da ordem.
Em [1]:
from datetime import date,datetime
import time
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
Em [2]:
trades = pd.read_csv('HOOKUSDT-aggTrades-2023-01-27.csv')
trades['date'] = pd.to_datetime(trades['transact_time'], unit='ms')
trades.index = trades['date']
buy_trades = trades[trades['is_buyer_maker']==False].copy()
buy_trades = buy_trades.groupby('transact_time').agg({
'agg_trade_id': 'last',
'price': 'last',
'quantity': 'sum',
'first_trade_id': 'first',
'last_trade_id': 'last',
'is_buyer_maker': 'last',
'date': 'last',
'transact_time':'last'
})
buy_trades['interval']=buy_trades['transact_time'] - buy_trades['transact_time'].shift()
buy_trades.index = buy_trades['date']
Combinamos os valores individuais de negociação em intervalos de 1 segundo para obter o valor agregado de negociação, excluindo períodos sem atividade comercial. Em seguida, ajustamos esse valor agregado usando a distribuição derivada da análise do valor único de negociação mencionada anteriormente. Os resultados mostram um bom ajuste ao considerar cada negociação dentro do intervalo de 1 segundo como uma única negociação, resolvendo efetivamente o problema. No entanto, quando o intervalo de tempo é estendido em relação à frequência de negociação, observamos um aumento nos erros. Pesquisas posteriores revelam que esse erro é causado pelo prazo de correção introduzido pela distribuição de Pareto. Isso sugere que, à medida que o tempo se prolonga e inclui mais negociações individuais, a agregação de múltiplos negócios se aproxima da distribuição de Pareto mais de perto, necessitando a remoção do prazo de correção.
Em [3]:
df_resampled = buy_trades['quantity'].resample('1S').sum()
df_resampled = df_resampled.to_frame(name='quantity')
df_resampled = df_resampled[df_resampled['quantity']>0]
Em [4]:
# Cumulative distribution in 1s
depths = np.array(range(0, 3000, 5))
probabilities = np.array([np.mean(df_resampled['quantity'] > depth) for depth in depths])
mean = df_resampled['quantity'].mean()
alpha = np.log(np.mean(df_resampled['quantity'] > mean))/np.log(2.05)
probabilities_s = np.array([((1+20**(-depth/mean))*depth/mean+1)**(alpha) for depth in depths])
plt.figure(figsize=(10, 5))
plt.plot(depths, probabilities)
plt.plot(depths, probabilities_s)
plt.xlabel('Depth')
plt.ylabel('Probability of execution')
plt.title('Execution probability at different depths')
plt.grid(True)
Fora[4]:
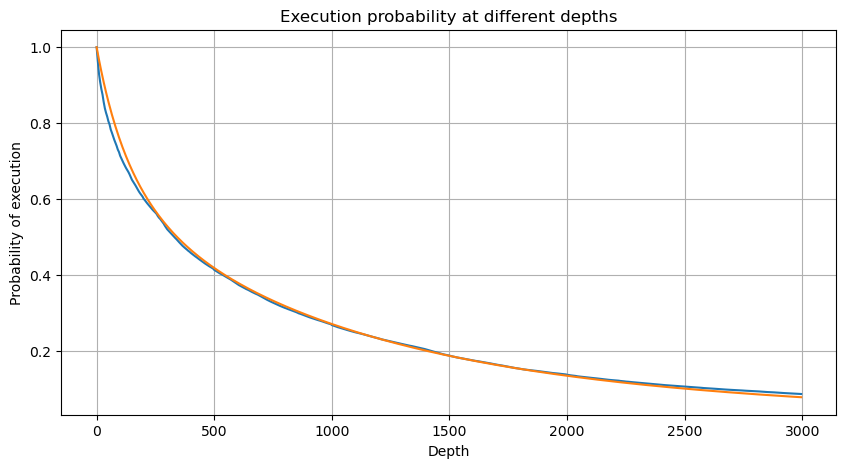
Em [5]:
df_resampled = buy_trades['quantity'].resample('30S').sum()
df_resampled = df_resampled.to_frame(name='quantity')
df_resampled = df_resampled[df_resampled['quantity']>0]
depths = np.array(range(0, 12000, 20))
probabilities = np.array([np.mean(df_resampled['quantity'] > depth) for depth in depths])
mean = df_resampled['quantity'].mean()
alpha = np.log(np.mean(df_resampled['quantity'] > mean))/np.log(2.05)
probabilities_s = np.array([((1+20**(-depth/mean))*depth/mean+1)**(alpha) for depth in depths])
alpha = np.log(np.mean(df_resampled['quantity'] > mean))/np.log(2)
probabilities_s_2 = np.array([(depth/mean+1)**alpha for depth in depths]) # No amendment
plt.figure(figsize=(10, 5))
plt.plot(depths, probabilities,label='Probabilities (True)')
plt.plot(depths, probabilities_s, label='Probabilities (Simulation 1)')
plt.plot(depths, probabilities_s_2, label='Probabilities (Simulation 2)')
plt.xlabel('Depth')
plt.ylabel('Probability of execution')
plt.title('Execution probability at different depths')
plt.legend()
plt.grid(True)
Fora[5]:
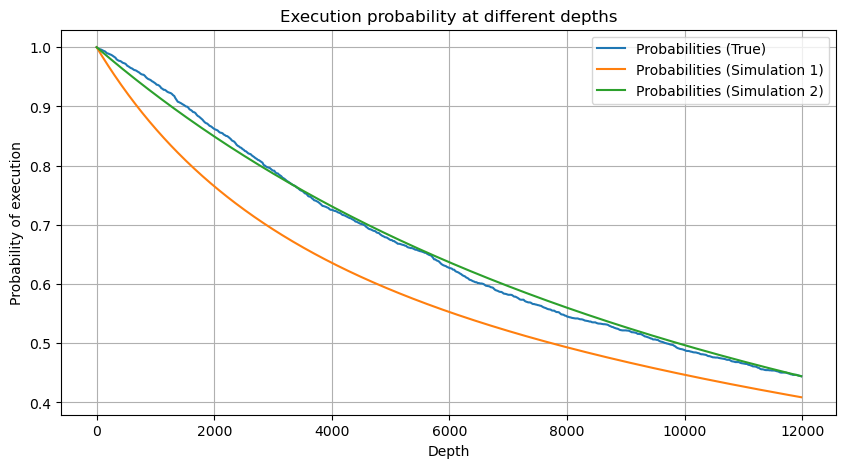
Agora resumir uma fórmula geral para a distribuição do montante de negociação acumulado para diferentes períodos de tempo, usando a distribuição do montante de transação única para caber, em vez de calcular separadamente a cada vez.
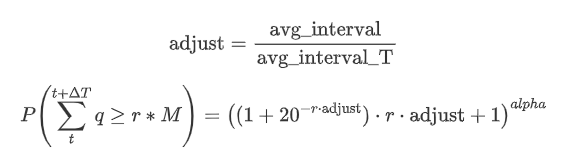
Aqui, avg_interval representa o intervalo médio de transações individuais, e avg_interval_T representa o intervalo médio do intervalo que precisa ser estimado. Pode parecer um pouco confuso. Se quisermos estimar o valor de negociação por 1 segundo, precisamos calcular o intervalo médio entre eventos contendo transações dentro de 1 segundo. Se a probabilidade de chegada de ordens seguir uma distribuição de Poisson, ela deve ser diretamente estimável. No entanto, na realidade, há um desvio significativo, mas não vou detalhá-lo aqui.
Observe que a probabilidade de o valor de negociação exceder um valor específico dentro de um determinado intervalo de tempo e a probabilidade real de negociação nessa posição na profundidade devem ser bastante diferentes. À medida que o tempo de espera aumenta, a possibilidade de alterações na carteira de ordens aumenta, e a negociação também leva a mudanças na profundidade. Portanto, a probabilidade de negociação na mesma posição de profundidade muda em tempo real à medida que os dados são atualizados.
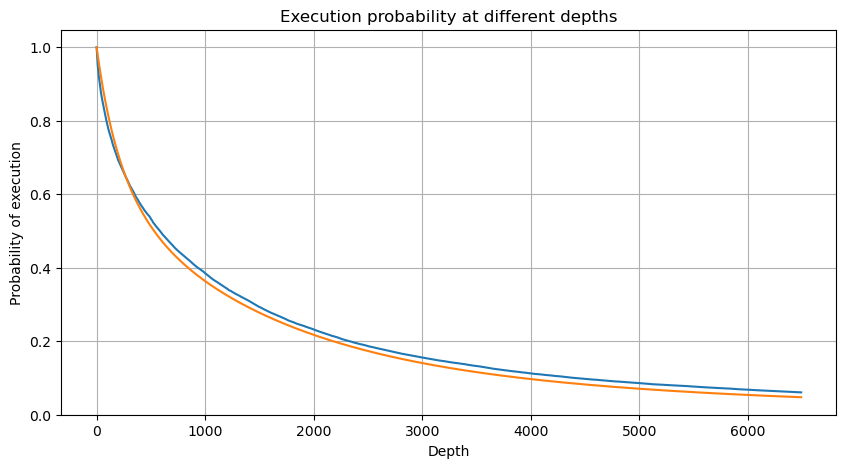
Em [6]:
df_resampled = buy_trades['quantity'].resample('2S').sum()
df_resampled = df_resampled.to_frame(name='quantity')
df_resampled = df_resampled[df_resampled['quantity']>0]
depths = np.array(range(0, 6500, 10))
probabilities = np.array([np.mean(df_resampled['quantity'] > depth) for depth in depths])
mean = buy_trades['quantity'].mean()
adjust = buy_trades['interval'].mean() / 2620
alpha = np.log(np.mean(buy_trades['quantity'] > mean))/0.7178397931503168
probabilities_s = np.array([((1+20**(-depth*adjust/mean))*depth*adjust/mean+1)**(alpha) for depth in depths])
plt.figure(figsize=(10, 5))
plt.plot(depths, probabilities)
plt.plot(depths, probabilities_s)
plt.xlabel('Depth')
plt.ylabel('Probability of execution')
plt.title('Execution probability at different depths')
plt.grid(True)
Fora[6]:
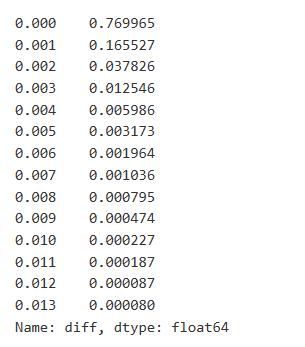
Impacto dos preços no comércio único
Os dados comerciais são valiosos, e ainda há muitos dados que podem ser extraídos. Devemos prestar muita atenção ao impacto das ordens nos preços, pois isso afeta o posicionamento das estratégias. Da mesma forma, agregando dados baseados no transact_time, calcula-se a diferença entre o último preço e o primeiro preço. Se houver apenas uma ordem, a diferença de preço é 0.
Os resultados mostram que a proporção de negociações que não causaram qualquer impacto é tão alta quanto 77%, enquanto a proporção de negociações que causaram um movimento de preço de 1 tick é de 16,5%, 2 ticks é de 3,7%, 3 ticks é de 1,2%, e mais de 4 ticks é inferior a 1%.
O volume de transacções que causa a diferença de preço correspondente também foi analisado, excluindo distorções causadas por impacto excessivo.
Em [7]:
diff_df = trades[trades['is_buyer_maker']==False].groupby('transact_time')['price'].agg(lambda x: abs(round(x.iloc[-1] - x.iloc[0],3)) if len(x) > 1 else 0)
buy_trades['diff'] = buy_trades['transact_time'].map(diff_df)
Em [8]:
diff_counts = buy_trades['diff'].value_counts()
diff_counts[diff_counts>10]/diff_counts.sum()
Fora[8]:
Em [9]:
diff_group = buy_trades.groupby('diff').agg({
'quantity': 'mean',
'diff': 'last',
})
Em [10]:
diff_group['quantity'][diff_group['diff']>0][diff_group['diff']<0.01].plot(figsize=(10,5),grid=True);
Fora[10]:
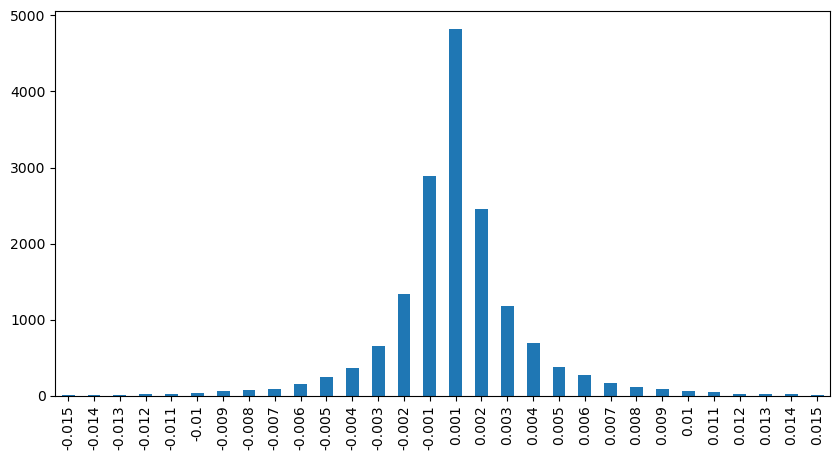
Efeito sobre os preços de intervalos fixos
Vamos analisar o impacto do preço dentro de um intervalo de 2 segundos. A diferença aqui é que pode haver valores negativos. No entanto, como estamos considerando apenas ordens de compra, o impacto na posição simétrica seria um tique maior. Continuando a observar a relação entre o valor do comércio e o impacto, só consideramos resultados maiores que 0.
Em [11]:
df_resampled = buy_trades.resample('2S').agg({
'price': ['first', 'last', 'count'],
'quantity': 'sum'
})
df_resampled['price_diff'] = round(df_resampled[('price', 'last')] - df_resampled[('price', 'first')],3)
df_resampled['price_diff'] = df_resampled['price_diff'].fillna(0)
result_df_raw = pd.DataFrame({
'price_diff': df_resampled['price_diff'],
'quantity_sum': df_resampled[('quantity', 'sum')],
'data_count': df_resampled[('price', 'count')]
})
result_df = result_df_raw[result_df_raw['price_diff'] != 0]
Em [12]:
result_df['price_diff'][abs(result_df['price_diff'])<0.016].value_counts().sort_index().plot.bar(figsize=(10,5));
Fora[12]:
Em [23]:
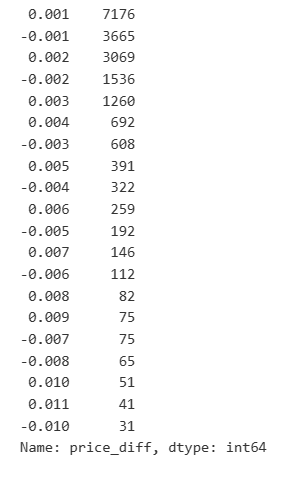
result_df['price_diff'].value_counts()[result_df['price_diff'].value_counts()>30]
Fora[23]:
Em [14]:
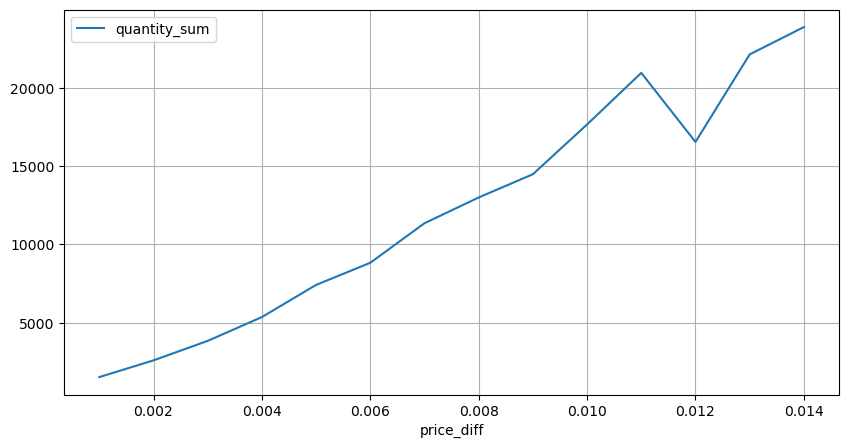
diff_group = result_df.groupby('price_diff').agg({ 'quantity_sum': 'mean'})
Em [15]:
diff_group[(diff_group.index>0) & (diff_group.index<0.015)].plot(figsize=(10,5),grid=True);
Fora [1]:
Impacto do montante do comércio sobre os preços
Anteriormente, determinámos o montante das transacções necessárias para uma alteração de tick, mas não era preciso, uma vez que se baseava na suposição de que o impacto já se tinha verificado.
Nessa análise, os dados são amostrados a cada 1 segundo, com cada passo representando 100 unidades de quantidade.
- Quando o montante da ordem de compra é inferior a 500, a variação esperada do preço é uma diminuição, o que é esperado, uma vez que também existem ordens de venda que afetam o preço.
- Em quantidades de comércio mais baixas, há uma relação linear, o que significa que quanto maior o valor do comércio, maior o aumento do preço.
- A medida que o valor da ordem de compra aumenta, a mudança de preço se torna mais significativa. Isso muitas vezes indica um avanço de preço, que pode posteriormente regredir. Além disso, a amostragem de intervalo fixo aumenta a instabilidade dos dados.
- É importante prestar atenção à parte superior do gráfico de dispersão, que corresponde ao aumento do preço com o montante do comércio.
- Para este par de negociação específico, fornecemos uma versão aproximada da relação entre o valor do comércio e a mudança de preço.
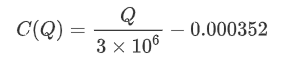
Onde
Em [16]:
df_resampled = buy_trades.resample('1S').agg({
'price': ['first', 'last', 'count'],
'quantity': 'sum'
})
df_resampled['price_diff'] = round(df_resampled[('price', 'last')] - df_resampled[('price', 'first')],3)
df_resampled['price_diff'] = df_resampled['price_diff'].fillna(0)
result_df_raw = pd.DataFrame({
'price_diff': df_resampled['price_diff'],
'quantity_sum': df_resampled[('quantity', 'sum')],
'data_count': df_resampled[('price', 'count')]
})
result_df = result_df_raw[result_df_raw['price_diff'] != 0]
Em [24]:
df = result_df.copy()
bins = np.arange(0, 30000, 100) #
labels = [f'{i}-{i+100-1}' for i in bins[:-1]]
df.loc[:, 'quantity_group'] = pd.cut(df['quantity_sum'], bins=bins, labels=labels)
grouped = df.groupby('quantity_group')['price_diff'].mean()
Em [25]:
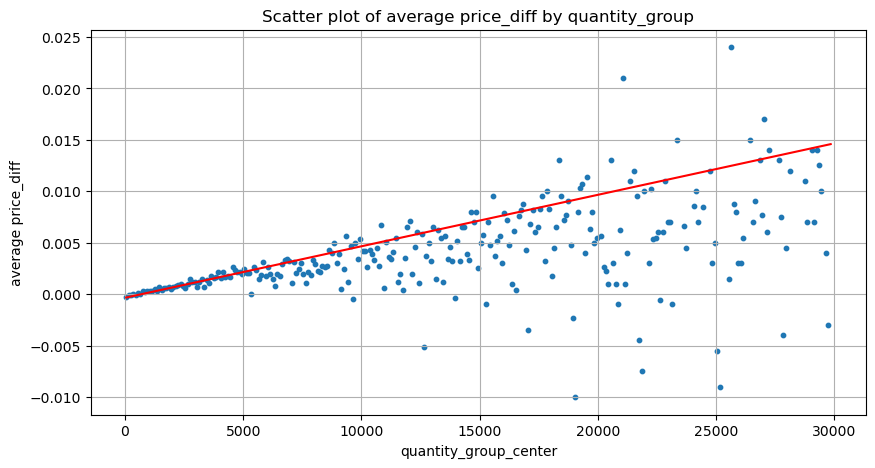
grouped_df = pd.DataFrame(grouped).reset_index()
grouped_df['quantity_group_center'] = grouped_df['quantity_group'].apply(lambda x: (float(x.split('-')[0]) + float(x.split('-')[1])) / 2)
plt.figure(figsize=(10,5))
plt.scatter(grouped_df['quantity_group_center'], grouped_df['price_diff'],s=10)
plt.plot(grouped_df['quantity_group_center'], np.array(grouped_df['quantity_group_center'].values)/2e6-0.000352,color='red')
plt.xlabel('quantity_group_center')
plt.ylabel('average price_diff')
plt.title('Scatter plot of average price_diff by quantity_group')
plt.grid(True)
Fora[25]:
Em [19]:
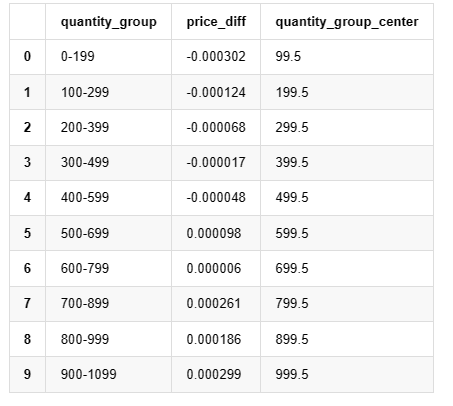
grouped_df.head(10)
Fora [1]: Não, não, não, não, não, não, não, não...
Posicionamento preliminar de ordens ótimas
Com a modelagem do valor do comércio e o modelo aproximado do impacto do preço correspondente ao valor do comércio, parece ser possível calcular a colocação de ordem ideal.
- Suponha-se que o preço regressar ao seu valor original após o impacto (o que é altamente improvável e exigiria uma análise mais aprofundada da alteração do preço após o impacto).
- Suponhamos que a distribuição do volume de transacções e da frequência de ordens durante este período siga um padrão pré-estabelecido (o que também é impreciso, uma vez que estamos a estimar com base em dados de um dia e as transacções apresentam fenômenos claros de agrupamento).
- Suponha que apenas uma ordem de venda ocorra durante o tempo simulado e, em seguida, seja fechada.
- Suponha que após a execução da ordem, existam outras ordens de compra que continuam a aumentar o preço, especialmente quando o valor é muito baixo.
Vamos começar por escrever um simples retorno esperado, que é a probabilidade de ordens de compra cumulativas excederem Q dentro de 1 segundo, multiplicado pela taxa de retorno esperada (ou seja, o impacto do preço).
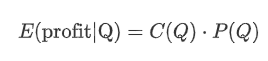
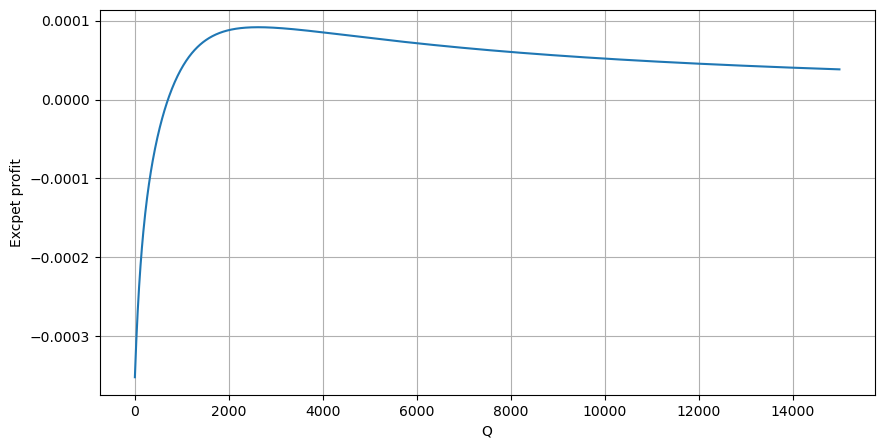
Com base no gráfico, o retorno esperado máximo é de aproximadamente 2500, o que é cerca de 2,5 vezes o valor médio da negociação. Isso sugere que a ordem de venda deve ser colocada em uma posição de preço de 2500. É importante enfatizar que o eixo horizontal representa o valor da negociação dentro de 1 segundo e não deve ser equiparado à posição de profundidade. Além disso, essa análise é baseada em dados de negociações e carece de dados de profundidade importantes.
Resumo
Descobrimos que a distribuição do valor do comércio em diferentes intervalos de tempo é uma escalada simples da distribuição dos valores individuais do comércio. Também desenvolvemos um modelo de retorno esperado simples baseado no impacto do preço e na probabilidade do comércio. Os resultados deste modelo se alinham com nossas expectativas, mostrando que se o valor da ordem de venda for baixo, ele indica uma diminuição do preço e uma certa quantidade é necessária para o potencial de lucro. A probabilidade diminui à medida que o valor do comércio aumenta, com um tamanho ideal no meio, o que representa a estratégia ideal de colocação de pedidos. No entanto, este modelo ainda é muito simplista. No próximo artigo, aprofundarei mais neste tópico.
Em [20]:
# Cumulative distribution in 1s
df_resampled = buy_trades['quantity'].resample('1S').sum()
df_resampled = df_resampled.to_frame(name='quantity')
df_resampled = df_resampled[df_resampled['quantity']>0]
depths = np.array(range(0, 15000, 10))
mean = df_resampled['quantity'].mean()
alpha = np.log(np.mean(df_resampled['quantity'] > mean))/np.log(2.05)
probabilities_s = np.array([((1+20**(-depth/mean))*depth/mean+1)**(alpha) for depth in depths])
profit_s = np.array([depth/2e6-0.000352 for depth in depths])
plt.figure(figsize=(10, 5))
plt.plot(depths, probabilities_s*profit_s)
plt.xlabel('Q')
plt.ylabel('Excpet profit')
plt.grid(True)
Fora [1]:
- Delta hedge com curva de sorrisos para opções de Bitcoin
- Reflexões sobre estratégias de negociação de alta frequência (5)
- Reflexões sobre estratégias de negociação de alta frequência (4)
- Pensamento sobre estratégias de negociação de alta frequência (5)
- Pensamento sobre estratégias de negociação de alta frequência (4)
- Reflexões sobre estratégias de negociação de alta frequência (3)
- Reflexões sobre estratégias de negociação de alta frequência (3)
- Pensamento sobre estratégias de negociação de alta frequência (2)
- Reflexões sobre estratégias de negociação de alta frequência (1)
- Reflexões sobre estratégias de negociação de alta frequência (1)
- Documento de Descrição da Configuração dos Títulos Futu
- FMZ Quant Uniswap V3 Guia de operações relacionadas com a liquidez dos bancos de câmbio (parte 1)
- FMZ Quantificação Uniswap V3 Guia de operação relacionado à liquidez do reservatório de câmbio (1)