

Recentemente, o termo "destilação" tem sido usado com cada vez mais frequência. Na área de IA, geralmente significa extrair habilidades complexas em estruturas mais compactas e reutilizáveis; e quando aplicado à pesquisa de estratégias, essa lógica também se sustenta. De forma mais direta, trata-se de organizar conhecimentos que originalmente eram dispersos, vagos e dependentes de experiência subjetiva em um sistema que pode ser calculado, verificado e continuamente ajustado.
O projeto crypto-kol-quant tem se tornado bastante popular recentemente, e o que realmente o torna interessante não é quantos KOLs ele captura, nem o uso de LLM, mas sim sua tentativa de fazer algo incomum na pesquisa quantitativa: destilar a experiência de traders em um conjunto de fatores de habilidade computáveis e, em seguida, agregá-los em um sinal de consenso. Essa questão merece ser levada a sério. Porque, se um grupo de traders de longo prazo ativos e com estilos consistentes realmente desenvolveu estruturas cognitivas próprias no mercado, então essas estruturas não deveriam existir apenas em tweets, gráficos e fragmentos de texto; elas também deveriam ter a oportunidade de ser extraídas, organizadas e integradas em uma cadeia de estratégia executável.
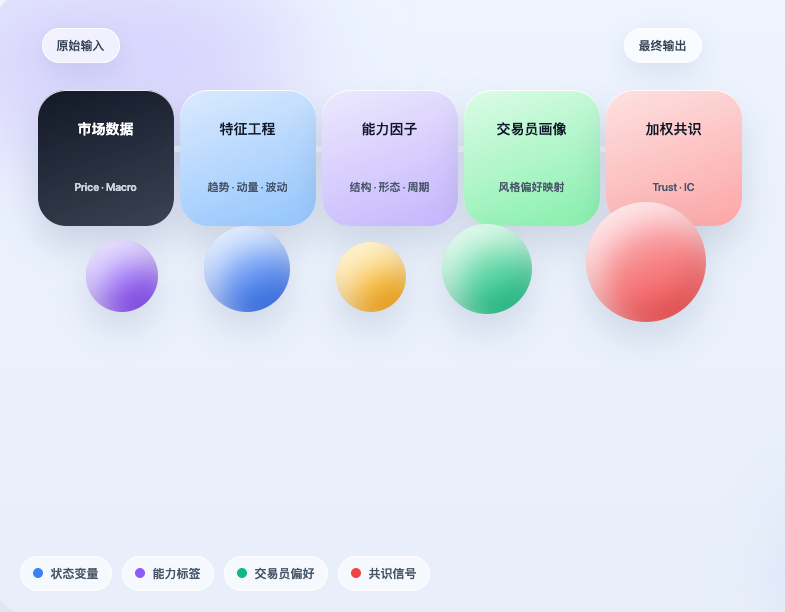
Com base nessa ideia, fizemos uma implementação preliminar no ambiente de quantificação do Inventor. O foco não é simplesmente "copiar" o projeto, mas sim conectar sua lógica central: primeiro obter dados de mercado, depois traduzir o mercado em estados estruturados; em seguida, com base nesses estados, determinar quais habilidades de negociação estão sendo acionadas; então mapear essas habilidades de volta ao perfil do trader; e, por fim, agregar os julgamentos individuais de diferentes traders em um sinal de consenso ponderado. Ainda não é um sistema de negociação maduro, mas pelo menos realiza uma coisa importante: prova que a experiência dos traders pode ser comprimida, estruturada e realmente integrada ao processo de julgamento da estratégia.
O objeto da destilação não são opiniões, mas sim habilidades de negociação
Muitas pessoas, ao encontrar esse tipo de projeto pela primeira vez, tendem a interpretá-lo como uma "estratégia de sentimento de KOL". Mas isso não é preciso. O que o projeto original realmente faz não é simplesmente julgar quem está mais otimista hoje, nem contar quem gritou "comprar" ou "vender", mas sim perguntar mais a fundo: como esse trader entende o mercado? Em que estrutura ele tende a ser otimista? Ele se concentra mais em tendência, posição, padrão, volatilidade ou ambiente macroeconômico? Essas formas de julgamento podem ser organizadas em um conjunto estável de rótulos de habilidade?
Uma vez que a pergunta é formulada dessa forma, o foco da estratégia muda. O sistema não se importa mais com uma afirmação em si, mas sim com a metodologia por trás dela. Em outras palavras, o que essa estratégia realmente destila não é texto, mas sim o conhecimento de negociação em si. Ela tenta traduzir a experiência subjetiva, que originalmente dependia da compreensão humana, em habilidades regradas que um programa pode identificar e invocar. Essa é a maior diferença em relação aos modelos de sentimento comuns: não é para julgar o quão quente está o sentimento do mercado, mas sim para reconstruir como diferentes estruturas de negociação reagem no mercado atual.
Primeiro passo: traduzir o mercado em variáveis de estado
Para que a destilação realmente se concretize, o primeiro passo não é previsão, mas sim engenharia de características. A razão é simples: a linguagem dos traders é feita para humanos, não para programas. Por exemplo, a frase "o preço recuou para a média móvel chave, é um bom ponto de reentrada" é fácil de entender para um trader, mas para um programa, ela primeiro precisa ser decomposta: qual é a média móvel chave, é de 50 ou 200 dias? O preço atual está próximo dessa média? A tendência foi quebrada? Há sinais de absorção?
Portanto, a primeira coisa que o sistema precisa fazer não é dar uma conclusão de compra ou venda, mas converter os dados brutos do mercado em um conjunto de estados estruturados. A camada mais básica aqui é usar o preço para construir características de tendência e momentum. Variáveis como médias móveis, médias exponenciais, RSI, MACD não são para empilhar indicadores, mas para responder a uma pergunta simples: em que estado o mercado se encontra aproximadamente agora?

O código chave é:
python
# Usar médias móveis de diferentes períodos para descrever a posição do preço em relação à tendência
f['ma20'] = _sma(c,20)
f['ma50'] = _sma(c,50)
f['ma100'] = _sma(c,100)
f['ma200'] = _sma(c,200)
# Médias exponenciais são mais sensíveis a mudanças recentes de preço
f['ema20'] = _ema(c,20)
f['ema50'] = _ema(c,50)
# RSI usado para descrever se o mercado entrou em condição de sobrecompra ou sobrevenda, ou se o momentum está enfraquecendo
f['rsi14'] = _rsi(c,14)
# MACD e sua linha de sinal, histograma, usados para observar tendência e mudanças de momentum
ml, ms, mh = _macd(c)
f['macd'] = ml
f['macd_sig'] = ms
f['macd_hist'] = mh
O que este código faz não é complicado. As médias móveis ajudam o sistema a determinar a posição do preço atual em relação à tendência de longo prazo, enquanto o RSI e o MACD descrevem se o momentum está se fortalecendo ou enfraquecendo. Ainda não se trata de um julgamento de negociação, apenas de estabelecer uma camada de "descrição do estado do mercado".
Em seguida, o sistema também precisa adicionar volatilidade e relações de posição, porque muitos julgamentos de negociação não dependem apenas da tendência, mas também de "estamos em um período de contração de volatilidade?" e "o preço está próximo de uma máxima ou mínima de intervalo?".
O código correspondente é:
python
# O retorno logarítmico é a base para calcular a volatilidade
logr = np.log(c / c.shift(1))
# Volatilidade anualizada dos últimos 30 dias, para medir o nível de volatilidade atual do mercado
f['rv30'] = logr.rolling(30, min_periods=10).std() * np.sqrt(365)
# Máximas e mínimas dos últimos 20 e 50 dias, para determinar a posição do preço
f['high_20d'] = h.rolling(20, min_periods=1).max()
f['low_20d'] = l.rolling(20, min_periods=1).min()
f['high_50d'] = h.rolling(50, min_periods=1).max()
f['low_50d'] = l.rolling(50, min_periods=1).min()
Aqui, rv30 representa o nível de volatilidade anualizada dos últimos 30 dias, enquanto as máximas e mínimas do intervalo ajudam o sistema a determinar em que posição o preço atual se encontra dentro da estrutura de preços recente. Além disso, o fundo macroeconômico também é incorporado ao espaço de estados. Porque um tipo de trader não olha apenas para o preço da criptomoeda, mas também observa o índice Dólar, o apetite ao risco do mercado de ações e o ambiente de taxas de juros. A forma como o código lida com isso é primeiro alinhar essas variáveis diariamente e depois convertê-las em estados legíveis:
python
# DXY como variável de fundo para a força do dólar
if 'DXY' in macro:
dxy = _align(macro['DXY'])
f['dxy_ret_20d'] = dxy.pct_change(20)
f['dxy_trend_down'] = (dxy.pct_change(20) < -0.01).astype(int)
# SPX como variável de fundo para apetite ao risco
if 'SPX' in macro:
spx = _align(macro['SPX'])
f['spx_ret_20d'] = spx.pct_change(20)
f['spx_trend_up'] = (spx.pct_change(20) > 0).astype(int)
O significado desta etapa pode ser resumido em uma frase: primeiro, traduzir "como está o mercado agora" em estados estruturados que a máquina pode ler continuamente. Sem essa camada, a destilação subsequente não teria base.
Segundo passo: transformar a experiência subjetiva em fatores de habilidade
Apenas as características não são suficientes, porque elas apenas descrevem o mercado, não expressam diretamente "o que esse estado significa". O próximo passo é escrever a experiência do trader como regras, ou seja, com base nessas variáveis de estado atuais, determinar quais habilidades de negociação estão sendo acionadas.
Esta etapa é onde a "destilação" da estratégia é mais forte. Porque aqui não se trata mais de dizer abstratamente "certa estrutura é importante", mas sim de escrevê-la como condições de programa. Os fatores de habilidade incluídos na implementação atual cobrem várias áreas: padrões, estrutura, indicadores, ciclos e macroeconomia. Por exemplo, algumas habilidades vêm do reconhecimento de padrões, como bandeiras de alta, bandeiras de baixa, topos e fundos duplos, ombro-cabeça-ombro, triângulos; outras vêm da análise estrutural, como frameworks Wyckoff, SMC, ICT; outras vêm dos próprios indicadores, como divergência de RSI, cruzamento de médias móveis (golden cross/death cross), compressão e rompimento de Bollinger; e outras vêm de ciclos e ambiente macro, como ciclo de halving, alternância entre mercado de tendência e mercado lateral, queda do DXY, recuperação do apetite ao risco, etc.
Um exemplo típico é a "continuação de tendência com recuo". Muitos traders têm experiência semelhante: se a tendência de longo prazo ainda está para cima, o preço recua para a média móvel chave e o candle atual mostra absorção, isso geralmente significa continuação da tendência. A expressão do programa é muito direta:
python
# Verificar se o preço atual está próximo da média móvel de 50 dias
near_ma50 = abs(close - ma50_v) / close < 0.02 if close > 0 else False
# Se a média móvel de 50 dias ainda está acima da média de 200 dias, e após o recuo para a média há um candle de alta com absorção
# então marcar como um sinal de habilidade de continuação de tendência
s['cap_014_trend_pullback_continuation'] = 0.6 if (ma50_gt and near_ma50 and is_green) else 0.0
Não há mistério aqui, apenas a decomposição de uma linguagem humana em várias condições que a máquina pode verificar uma a uma. Outro exemplo é o "rompimento da compressão de Bollinger". Para muitos traders, uma contração prolongada da volatilidade seguida por uma expansão repentina para cima ou para baixo geralmente significa uma nova escolha de direção. A regra correspondente é:
python
# Se a largura da banda de Bollinger do candle anterior estiver abaixo do limite de compressão, considerar como contração de volatilidade
squeezed = bb_w_p1 < bb_w20_p1 if bb_w20_p1 > 0 else False
# Após a contração, rompimento para cima da banda superior dá sinal positivo; rompimento para baixo da banda inferior dá sinal negativo
s['cap_021_bollinger_squeeze_breakout'] = (
0.6 if (squeezed and close > bb_u) else
-0.6 if (squeezed and close < bb_l) else 0.0
)
O tratamento dos fatores macro é semelhante. Para um tipo de trader mais voltado para o macro, o BTC não é uma série de preços completamente isolada; ele é influenciado pelo dólar, mercado de ações e ambiente de taxas de juros. Portanto, esses entendimentos também são escritos como julgamentos de habilidade:
python
# A queda do DXY geralmente é vista como um cenário positivo para o BTC
s['cap_027_dxy_inverse_btc'] = 0.4 if (not _nm(dxy_r20) and dxy_r20 < -0.01) else 0.0
# A alta do S&P pode ser vista como melhora no apetite ao risco
s['cap_028_spx_risk_on_off'] = 0.4 if (not _nm(spx_r20) and spx_r20 > 0.02) else 0.0
# A queda das taxas de curto prazo pode ser vista como melhora marginal de liquidez
s['cap_029_yields_liquidity'] = 0.4 if (not _nm(y_r20) and y_r20 < -0.02) else 0.0
O que realmente importa nesta camada não é quantas regras ela escreve, mas que ela conclui o passo mais crítico da destilação: comprimir julgamentos que antes só podiam ser entendidos subjetivamente em condições computáveis. Vale notar que, na versão atual, a maioria dos fatores de capacidade ainda é do tipo de ativação condicional, não de pontuação contínua. Isso significa que o sistema se comporta mais como um juízo sobre se uma determinada estrutura se estabelece, em vez de reavaliar constantemente cada pequena flutuação. Isso também determina que, atualmente, ele é mais adequado para julgamentos diários ou de média/baixa frequência, e não para negociações de alta frequência.
Terceiro passo: fatores não são somados diretamente, mas mapeados de volta ao perfil do trader
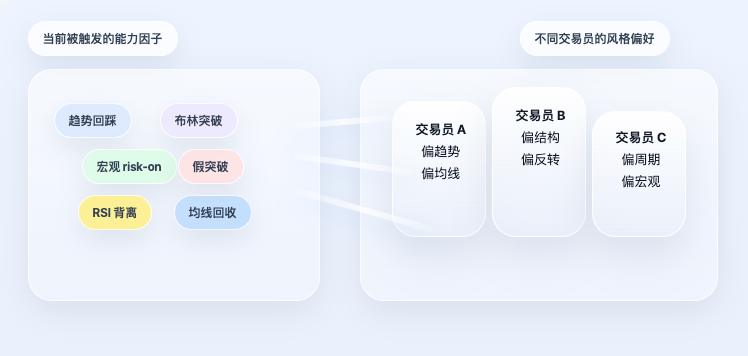
Se a estratégia parasse na camada de fatores, ela ainda seria apenas um sistema de regras comum. O que torna o projeto original mais especial é que ele não parou por aqui, mas avançou mais um passo: os fatores não determinam diretamente a direção; primeiro eles são mapeados de volta ao perfil do trader.
Este ponto é crucial. Porque, na realidade, traders não "usam todas as capacidades igualmente". Alguns tendem a seguir tendências, outros preferem estruturas, outros focam em ciclos, outros em macro. Mesmo diante do mesmo estado de mercado, pessoas diferentes se concentram em aspectos completamente distintos. Portanto, o sistema não simplesmente tira a média de todos os fatores. Primeiro, ele lê as preferências de capacidade de cada trader e, em seguida, calcula um sinal pessoal para ele com base no estado atual dos fatores.
A lógica correspondente de leitura do perfil é a seguinte:
python
# Lê os fatores de capacidade usados por cada trader no perfil e seus pesos
caps = {c['id']: float(c.get('weight', 0.5))
for c in p.get('capabilities_used', [])}
profiles.append({
'handle': p.get('handle', item['name'][:-5]),
'caps': caps
})
Cada perfil essencialmente responde a uma pergunta: em quais fatores de capacidade esse trader confia mais e qual o peso dessas capacidades em seu quadro de análise. De posse desse perfil, o sistema então calcula o "sinal pessoal" de cada trader no mercado atual:
python
for p in profiles:
sig = 0.0
wt = 0.0
# Percorre todos os fatores de capacidade que o trader acompanha
for cap_id, w in p['caps'].items():
score = factor_scores.get(cap_id, 0.0)
# Pontuação do fator atual multiplicada pelo peso de preferência do trader por esse fator
sig += w * score
wt += abs(w)
# Normaliza para obter o sinal pessoal do trader no mercado atual
trader_raw = sig / wt if wt > 0 else 0.0
Ao ver isso, já dá para sentir que o sabor deste sistema é bem diferente. Ele não está mais apenas olhando "quais fatores acenderam", mas está reconstruindo aproximadamente algo: se colocássemos o mercado de hoje nas mãos desses 99 traders, como cada um deles o avaliaria.
Quarto passo: do sinal pessoal ao consenso ponderado
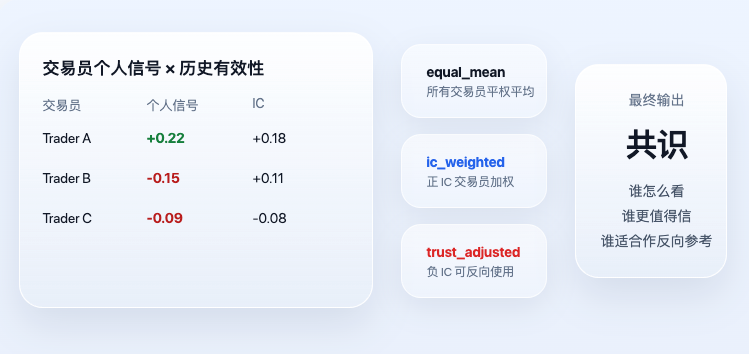
Quando o sinal pessoal de cada trader é calculado, o sistema entra na verdadeira camada de consenso. O "consenso" aqui não é uma simples votação, muito menos quem grita mais alto decide, mas considera ainda a efetividade histórica.
Os dois resultados mais importantes no código atual são ic_weighted e trust_adjusted. A lógica central correspondente é:
python
# Primeiro, pondera positivamente os traders com IC positivo para obter ic_weighted
pos_w = sum(max(t['ic'], 0) for t in trader_signals)
ic_wt = (
sum(t['signal'] * max(t['ic'], 0) for t in trader_signals) / pos_w
if pos_w > 0 else 0.0
)
# trust_adjusted vai além:
# IC positivo é usado na direção original, IC negativo é invertido,
# e depois ponderado pelo valor absoluto do IC
abs_w = sum(abs(t['ic']) for t in trader_signals)
trust = (
sum((t['signal'] if t['ic'] >= 0 else -t['signal']) * abs(t['ic'])
for t in trader_signals) / abs_w
if abs_w > 0 else 0.0
)
Este trecho expressa dois princípios muito simples, mas extremamente importantes. Primeiro, traders historicamente mais eficazes têm maior peso hoje. Segundo, traders com IC negativo no histórico não são descartados, mas podem ser usados como indicadores contrários. Portanto, o trust_adjusted final não é um simples "o que todos acham", mas sim "quem acha o quê, e em quem vale mais a pena confiar".
É por isso que este sistema é diferente de modelos de sentimento comuns. Ele não está contando quantas vozes existem, mas fazendo uma agregação cognitiva com verificação histórica. Se pudéssemos condensar todo o método em uma frase, seria: primeiro transformar o mercado em variáveis de estado, depois mapear essas variáveis em fatores de capacidade, depois mapear os fatores de capacidade em sinais pessoais dos traders e, finalmente, agregar esses sinais pessoais em um julgamento de consenso ponderado pela efetividade histórica.
O que a implementação no FMZ realmente fez funcionar
Se ficasse apenas como projeto de pesquisa, esse sistema seria mais um "analisador de consenso". Já a implementação no FMZ focou em realmente conectar toda a cadeia, permitindo que ela opere continuamente. O código mais central tem apenas três linhas:
python
# Primeiro passo: transformar os dados brutos de mercado e variáveis macro em estado estruturado
feat_df = build_features(records, macro if macro else None)
# Segundo passo: avaliar quais fatores de capacidade são ativados com base nas variáveis de estado
factor_scores = evaluate_factors(feat_df)
# Terceiro passo: mapear os fatores de capacidade de volta aos perfis dos traders e agregar em um resultado de consenso
consensus = compute_consensus(factor_scores)
Essas três linhas são praticamente as três abstrações mais importantes de toda a estratégia. A primeira camada cuida do estado do mercado, a segunda do julgamento de capacidades, e a terceira do consenso dos traders. É claro que depois vêm a camada de execução, a de gerenciamento de risco e a de exibição de estado, mas do ponto de vista da lógica de pesquisa, a parte mais crucial já está completamente estabelecida. Ou seja, o significado mais importante dessa implementação não está em quantos detalhes operacionais ela adicionou, mas em que, no projeto original, os perfis de capacidade não são mais apenas arquivos estáticos, os fatores não são mais apenas resultados de pesquisa, o consenso não é mais apenas um número em um relatório — eles foram integrados em um fluxo contínuo de julgamento.
Por que ainda é apenas um protótipo
Claro, essa implementação não é o estado final. O código atual usa um quadro diário do BTC, por isso é mais adequado para julgamentos de consenso de média/baixa frequência, não para sistemas de negociação de alta frequência. Seu núcleo ainda gira em torno de estruturas diárias, posições de ciclo, contexto macro e preferências de capacidade dos traders. Além disso, os perfis dos traders e o IC ainda são estáticos, não entraram em fase de evolução online. Ou seja, embora o sistema tenha dado o primeiro passo na "destilação de conhecimento", ele ainda não alcançou totalmente a "autocorreção do conhecimento destilado".
Mas isso não impede que ele já tenha demonstrado algo muito importante: a experiência dos traders pode ser comprimida em camadas, estruturada e realmente inserida na cadeia de estratégias. Seu valor não está em já gerar retornos estáveis, mas em ter avançado um caminho de pesquisa que antes existia apenas no conceito para uma fase executável. Quanto a como esses fatores de capacidade devem evoluir, como os pesos dos traders devem ser atualizados, como o consenso deve ser continuamente calibrado no mercado real — ainda são questões que exigem mais dados de operação para responder.
Conclusão
O que realmente faz crypto-kol-quant inspirador não é quantos conceitos populares ele usa, mas que ele deu um passo adiante em algo difícil de sistematizar: transformar a experiência dos traders — de expressão em capacidade, de capacidade em fator, e de fator em consenso. E a implementação no FMZ fez exatamente isso: tornar essa cadeia de destilação funcional. Ela não exagera ao se apresentar como estado final, nem tenta esconder que ainda é apenas um protótipo inicial. Mas, pelo menos, ela provou que a experiência de negociação não precisa ficar apenas em gráficos e palavras; ela pode ser destilada, estruturada, executada e até colocada em um sistema que julga o mercado continuamente.
Se a quantificação tradicional é boa em encontrar padrões em séries de preços, a direção que realmente vale a pena explorar neste tipo de estratégia talvez seja: extrair padrões da cognição humana e, em seguida, fazer com que esses padrões participem do mercado. E isso pode ser o aspecto mais digno de atenção da "destilação" na pesquisa de estratégias.
Projeto original: 锁妖塔 Skill — 炼化99个加密交易员
Agradecimentos especiais ao usuário "GiantBin" pelas ideias e sugestões. Se você tiver boas ideias, fique à vontade para compartilhar e discutir.
- 1