Мысли о высокочастотных торговых стратегиях (2)
Автор:Лидия., Создано: 2023-08-04 17:17:30, Обновлено: 2023-09-12 15:50:31
Мысли о высокочастотных торговых стратегиях (2)
Моделирование накопленной торговой суммы
В предыдущей статье мы вывели выражение для вероятности того, что сумма одной сделки будет больше определенного значения.
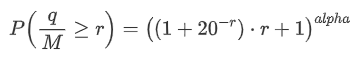
Также нас интересует распределение объема торговли за определенный период времени, которое интуитивно должно быть связано с индивидуальным объемом торговли и частотой заказов.
В [1]:
from datetime import date,datetime
import time
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
В [2]:
trades = pd.read_csv('HOOKUSDT-aggTrades-2023-01-27.csv')
trades['date'] = pd.to_datetime(trades['transact_time'], unit='ms')
trades.index = trades['date']
buy_trades = trades[trades['is_buyer_maker']==False].copy()
buy_trades = buy_trades.groupby('transact_time').agg({
'agg_trade_id': 'last',
'price': 'last',
'quantity': 'sum',
'first_trade_id': 'first',
'last_trade_id': 'last',
'is_buyer_maker': 'last',
'date': 'last',
'transact_time':'last'
})
buy_trades['interval']=buy_trades['transact_time'] - buy_trades['transact_time'].shift()
buy_trades.index = buy_trades['date']
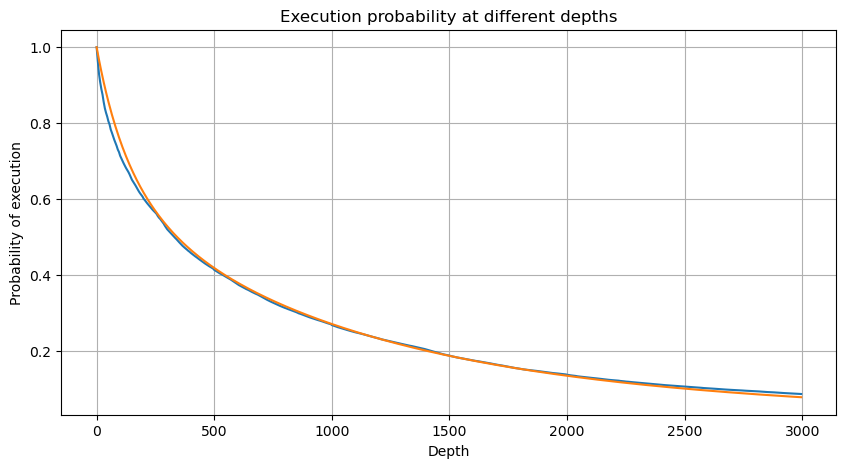
Мы объединяем отдельные суммы сделок с интервалом в 1 секунду, чтобы получить суммарную сумму сделок, исключая периоды без торговой активности. Затем мы подстраиваем эту сумму с использованием распределения, полученного из анализа единого объема сделок, упомянутого ранее. Результаты показывают хорошее соответствие при рассмотрении каждой сделки в течение 1-секундного интервала как одной сделки, эффективно решая проблему. Однако, когда временной интервал увеличивается относительно частоты торговли, мы наблюдаем увеличение ошибок. Дальнейшие исследования показывают, что эта ошибка вызвана коррекционным сроком, введенным распределением Парето. Это предполагает, что по мере увеличения времени и включает в себя больше отдельных сделок, агрегация нескольких сделок более близко приближается к распределению Парето, что требует устранения коррекционного срока.
В [3]:
df_resampled = buy_trades['quantity'].resample('1S').sum()
df_resampled = df_resampled.to_frame(name='quantity')
df_resampled = df_resampled[df_resampled['quantity']>0]
В [4]:
# Cumulative distribution in 1s
depths = np.array(range(0, 3000, 5))
probabilities = np.array([np.mean(df_resampled['quantity'] > depth) for depth in depths])
mean = df_resampled['quantity'].mean()
alpha = np.log(np.mean(df_resampled['quantity'] > mean))/np.log(2.05)
probabilities_s = np.array([((1+20**(-depth/mean))*depth/mean+1)**(alpha) for depth in depths])
plt.figure(figsize=(10, 5))
plt.plot(depths, probabilities)
plt.plot(depths, probabilities_s)
plt.xlabel('Depth')
plt.ylabel('Probability of execution')
plt.title('Execution probability at different depths')
plt.grid(True)
Выход[4]:
В [5]:
df_resampled = buy_trades['quantity'].resample('30S').sum()
df_resampled = df_resampled.to_frame(name='quantity')
df_resampled = df_resampled[df_resampled['quantity']>0]
depths = np.array(range(0, 12000, 20))
probabilities = np.array([np.mean(df_resampled['quantity'] > depth) for depth in depths])
mean = df_resampled['quantity'].mean()
alpha = np.log(np.mean(df_resampled['quantity'] > mean))/np.log(2.05)
probabilities_s = np.array([((1+20**(-depth/mean))*depth/mean+1)**(alpha) for depth in depths])
alpha = np.log(np.mean(df_resampled['quantity'] > mean))/np.log(2)
probabilities_s_2 = np.array([(depth/mean+1)**alpha for depth in depths]) # No amendment
plt.figure(figsize=(10, 5))
plt.plot(depths, probabilities,label='Probabilities (True)')
plt.plot(depths, probabilities_s, label='Probabilities (Simulation 1)')
plt.plot(depths, probabilities_s_2, label='Probabilities (Simulation 2)')
plt.xlabel('Depth')
plt.ylabel('Probability of execution')
plt.title('Execution probability at different depths')
plt.legend()
plt.grid(True)
Выход[5]:
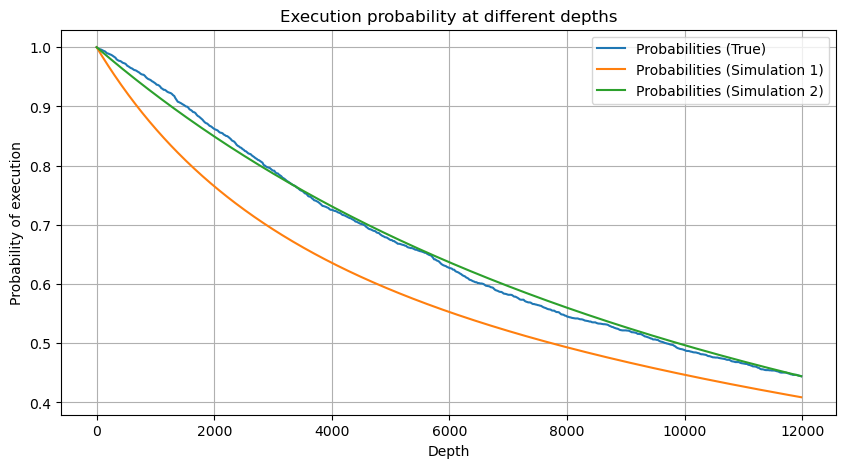
Теперь обобщите общую формулу распределения суммы накопленной торговли за разные периоды времени, используя распределение суммы одной сделки, чтобы соответствовать, вместо того, чтобы рассчитывать отдельно каждый раз.
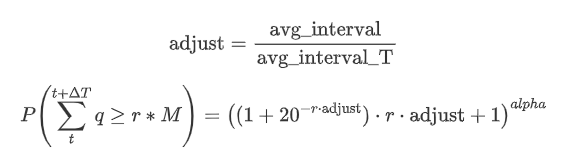
Здесь avg_interval представляет собой средний интервал одиночных транзакций, а avg_interval_T представляет собой средний интервал интервала, который необходимо оценить. Это может показаться немного запутанным. Если мы хотим оценить сумму торговли за 1 секунду, нам нужно вычислить средний интервал между событиями, содержащими транзакции в течение 1 секунды. Если вероятность прибытия ордеров следует распределению Пойсона, она должна быть непосредственно оцениваемой. Однако на самом деле существует значительное отклонение, но я не буду расширять его здесь.
Обратите внимание, что вероятность того, что сумма торговли превысит определенное значение в течение определенного промежутка времени, и фактическая вероятность торговли на этой позиции в глубине должны быть совершенно разными. По мере увеличения времени ожидания увеличивается вероятность изменений в книге ордеров, а торговля также приводит к изменениям в глубине. Поэтому вероятность торговли на той же глубине позиции меняется в режиме реального времени по мере обновления данных.
В [6]:
df_resampled = buy_trades['quantity'].resample('2S').sum()
df_resampled = df_resampled.to_frame(name='quantity')
df_resampled = df_resampled[df_resampled['quantity']>0]
depths = np.array(range(0, 6500, 10))
probabilities = np.array([np.mean(df_resampled['quantity'] > depth) for depth in depths])
mean = buy_trades['quantity'].mean()
adjust = buy_trades['interval'].mean() / 2620
alpha = np.log(np.mean(buy_trades['quantity'] > mean))/0.7178397931503168
probabilities_s = np.array([((1+20**(-depth*adjust/mean))*depth*adjust/mean+1)**(alpha) for depth in depths])
plt.figure(figsize=(10, 5))
plt.plot(depths, probabilities)
plt.plot(depths, probabilities_s)
plt.xlabel('Depth')
plt.ylabel('Probability of execution')
plt.title('Execution probability at different depths')
plt.grid(True)
Выход[6]:
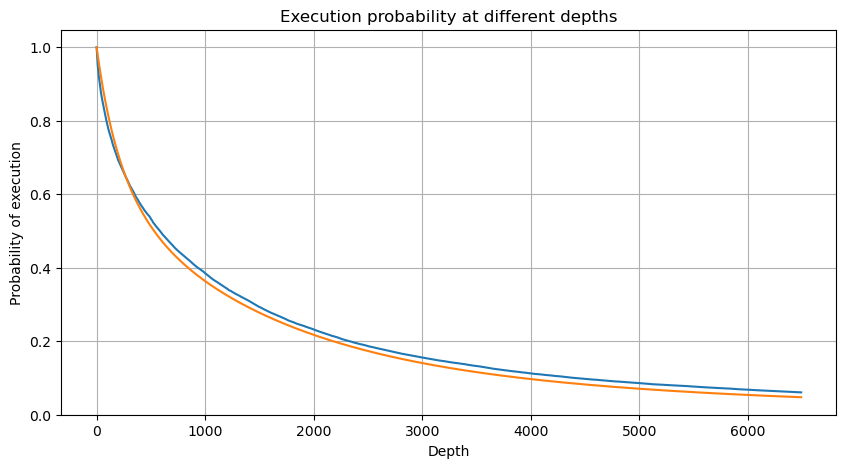
Влияние цен на единую торговлю
Данные о торговле ценны, и есть еще много данных, которые можно извлечь. Мы должны уделять пристальное внимание влиянию заказов на цены, поскольку это влияет на позиционирование стратегий. Аналогично, агрегируя данные на основе transact_time, мы вычисляем разницу между последней ценой и первой ценой. Если есть только один заказ, разница в цене равна 0. Интересно, что есть несколько результатов данных, которые являются отрицательными, что может быть связано с порядком данных, но мы не будем углубляться в это здесь.
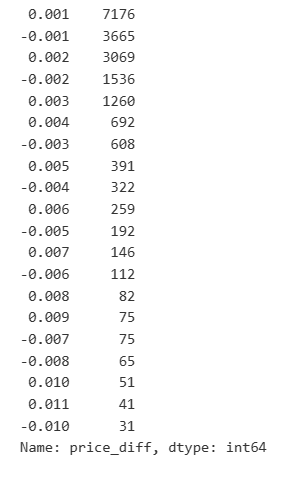
Результаты показывают, что доля сделок, которые не вызывали никакого влияния, составляет до 77%, в то время как доля сделок, вызывающих движение цены на 1 клик, составляет 16,5%, 2 клик - 3,7%, 3 клик - 1,2%, а более 4 клик - менее 1%.
Анализирована также сумма торговли, вызывающая соответствующую разницу в ценах, за исключением искажений, вызванных чрезмерным воздействием. Она показывает линейную связь, с приблизительно 1 тиком колебаний цен, вызванных каждыми 1000 единицами суммы. Это также может быть понято как среднее число порядка 1000 единиц заказов, размещенных вблизи каждого уровня цены в книге заказов.
В [7]:
diff_df = trades[trades['is_buyer_maker']==False].groupby('transact_time')['price'].agg(lambda x: abs(round(x.iloc[-1] - x.iloc[0],3)) if len(x) > 1 else 0)
buy_trades['diff'] = buy_trades['transact_time'].map(diff_df)
В [8]:
diff_counts = buy_trades['diff'].value_counts()
diff_counts[diff_counts>10]/diff_counts.sum()
Вне[8]:
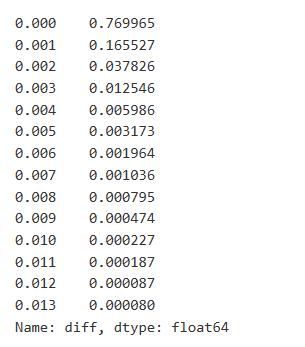
В [9]:
diff_group = buy_trades.groupby('diff').agg({
'quantity': 'mean',
'diff': 'last',
})
В [10]:
diff_group['quantity'][diff_group['diff']>0][diff_group['diff']<0.01].plot(figsize=(10,5),grid=True);
Выход[10]:
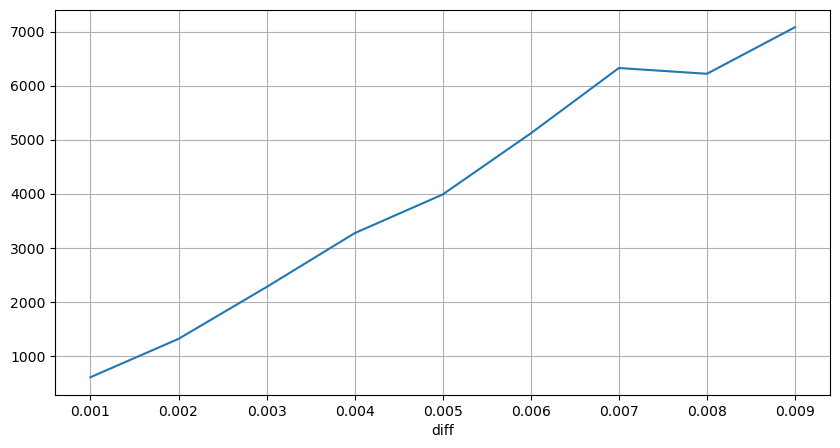
Влияние на цены за фиксированный интервал
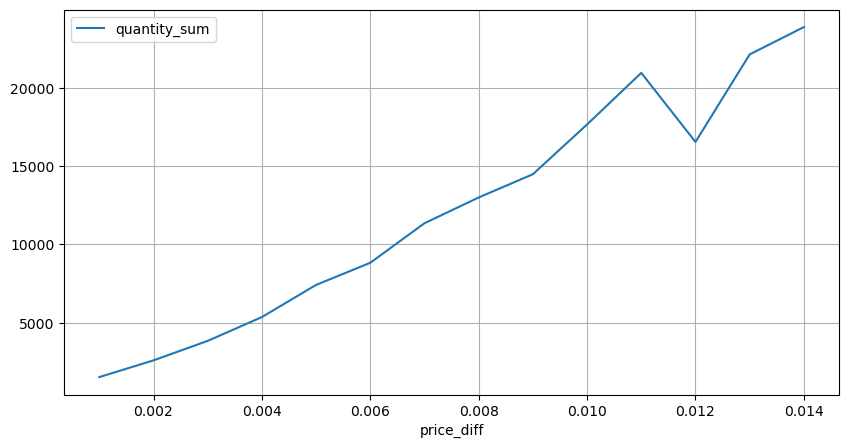
Давайте проанализируем влияние цены в течение 2-секундного интервала. Разница здесь заключается в том, что могут быть отрицательные значения. Однако, поскольку мы рассматриваем только заказы на покупку, влияние на симметричную позицию будет на один тик выше. Продолжая наблюдать взаимосвязь между объемом торговли и воздействием, мы рассматриваем только результаты, превышающие 0. Вывод похож на один заказ, показывающий приблизительную линейную связь, при которой для каждого тика требуется примерно 2000 единиц суммы.
В [11]:
df_resampled = buy_trades.resample('2S').agg({
'price': ['first', 'last', 'count'],
'quantity': 'sum'
})
df_resampled['price_diff'] = round(df_resampled[('price', 'last')] - df_resampled[('price', 'first')],3)
df_resampled['price_diff'] = df_resampled['price_diff'].fillna(0)
result_df_raw = pd.DataFrame({
'price_diff': df_resampled['price_diff'],
'quantity_sum': df_resampled[('quantity', 'sum')],
'data_count': df_resampled[('price', 'count')]
})
result_df = result_df_raw[result_df_raw['price_diff'] != 0]
В [12]:
result_df['price_diff'][abs(result_df['price_diff'])<0.016].value_counts().sort_index().plot.bar(figsize=(10,5));
Выход[12]:
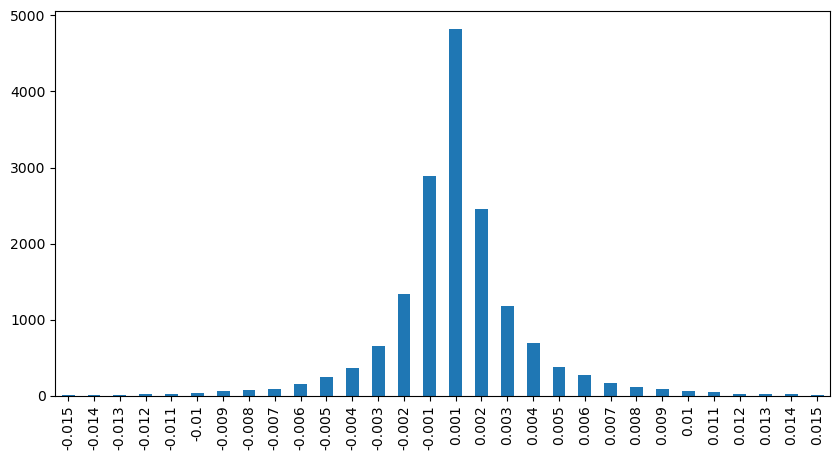
В [23]:
result_df['price_diff'].value_counts()[result_df['price_diff'].value_counts()>30]
Выход[23]:
В [14]:
diff_group = result_df.groupby('price_diff').agg({ 'quantity_sum': 'mean'})
В [15]:
diff_group[(diff_group.index>0) & (diff_group.index<0.015)].plot(figsize=(10,5),grid=True);
Выход[15]:
Влияние объема торговли на цены
Ранее мы определяли сумму торговли, необходимую для изменения тика, но она была неточной, поскольку основывалась на предположении, что воздействие уже произошло.
В этом анализе данные выбираются каждые 1 секунду, причем каждый шаг представляет собой 100 единиц величины. Затем мы рассчитали изменения цен в пределах этого диапазона величины. Вот некоторые ценные выводы:
- Когда сумма ордера на покупку ниже 500, ожидаемое изменение цены является снижением, что ожидается, поскольку есть также ордера на продажу, влияющие на цену.
- При более низких объемах торговли существует линейная связь, что означает, что чем больше объем торговли, тем больше увеличение цены.
- По мере увеличения объема ордера на покупку изменение цены становится более значительным. Это часто указывает на прорыв цены, который может позже регрессировать. Кроме того, выборка фиксированных интервалов увеличивает нестабильность данных.
- Важно обратить внимание на верхнюю часть диаграммы рассеивания, которая соответствует увеличению цены с объемом торговли.
- Для этой конкретной торговой пары мы предоставляем примерную версию взаимосвязи между объемом торговли и изменением цены.
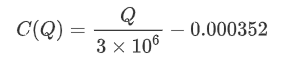
где
В [16]:
df_resampled = buy_trades.resample('1S').agg({
'price': ['first', 'last', 'count'],
'quantity': 'sum'
})
df_resampled['price_diff'] = round(df_resampled[('price', 'last')] - df_resampled[('price', 'first')],3)
df_resampled['price_diff'] = df_resampled['price_diff'].fillna(0)
result_df_raw = pd.DataFrame({
'price_diff': df_resampled['price_diff'],
'quantity_sum': df_resampled[('quantity', 'sum')],
'data_count': df_resampled[('price', 'count')]
})
result_df = result_df_raw[result_df_raw['price_diff'] != 0]
В [24]:
df = result_df.copy()
bins = np.arange(0, 30000, 100) #
labels = [f'{i}-{i+100-1}' for i in bins[:-1]]
df.loc[:, 'quantity_group'] = pd.cut(df['quantity_sum'], bins=bins, labels=labels)
grouped = df.groupby('quantity_group')['price_diff'].mean()
В [25]:
grouped_df = pd.DataFrame(grouped).reset_index()
grouped_df['quantity_group_center'] = grouped_df['quantity_group'].apply(lambda x: (float(x.split('-')[0]) + float(x.split('-')[1])) / 2)
plt.figure(figsize=(10,5))
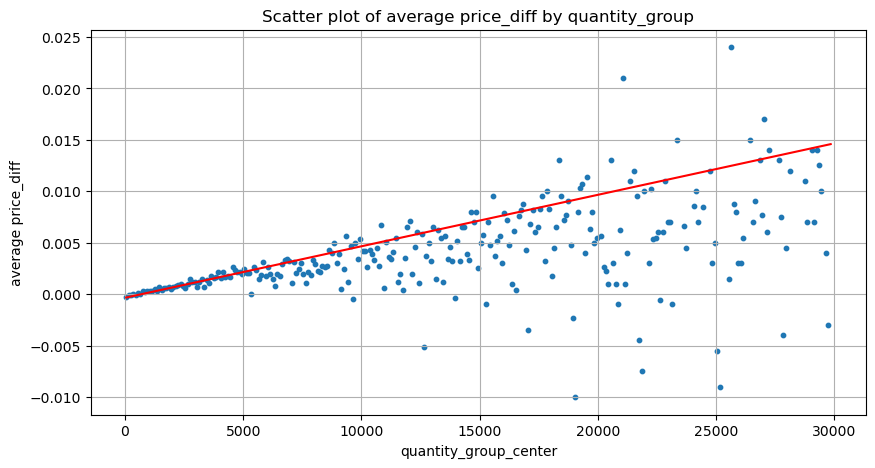
plt.scatter(grouped_df['quantity_group_center'], grouped_df['price_diff'],s=10)
plt.plot(grouped_df['quantity_group_center'], np.array(grouped_df['quantity_group_center'].values)/2e6-0.000352,color='red')
plt.xlabel('quantity_group_center')
plt.ylabel('average price_diff')
plt.title('Scatter plot of average price_diff by quantity_group')
plt.grid(True)
Выход[25]:
В [19]:
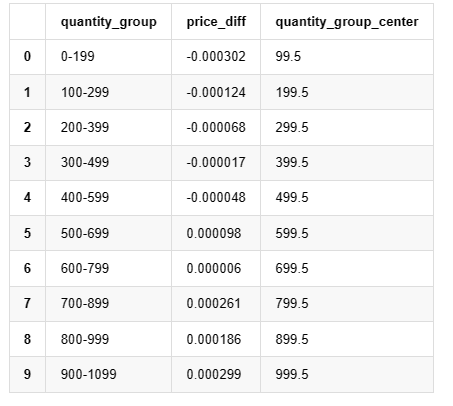
grouped_df.head(10)
Выход[19]: ,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,.
Предварительное размещение оптимального заказа
С помощью моделирования объема торговли и примерной модели влияния цены, соответствующей объему торговли, кажется возможным вычислить оптимальное размещение ордера.
- Предположим, что цена возвращается к первоначальному значению после воздействия (что крайне маловероятно и потребует дальнейшего анализа изменения цен после воздействия).
- Предположим, что распределение объема торговли и частоты заказов в течение этого периода следует за заданной схемой (что также неточно, поскольку мы оцениваем на основе данных одного дня, и торговля демонстрирует явные явления кластеризации).
- Предположим, что в течение симулируемого времени происходит только один ордер на продажу, а затем он закрывается.
- Предположим, что после выполнения ордера есть другие ордера на покупку, которые продолжают подталкивать цену вверх, особенно когда сумма очень низкая.
Давайте начнем с записи простой ожидаемой доходности, которая представляет собой вероятность того, что суммарные заказы на покупку превысят Q в течение 1 секунды, умноженные на ожидаемый показатель доходности (т.е. влияние цены).
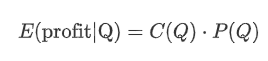
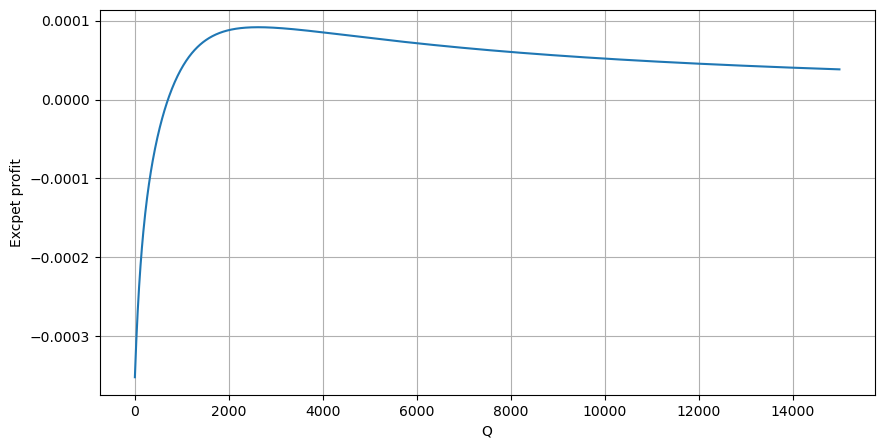
Основываясь на графике, максимальная ожидаемая доходность составляет приблизительно 2500, что примерно в 2,5 раза превышает среднюю сумму торговли. Это предполагает, что ордер на продажу должен быть размещен на ценовой позиции 2500. Важно подчеркнуть, что горизонтальная ось представляет собой сумму торговли в течение 1 секунды и не должна быть приравнена к глубинной позиции. Кроме того, этот анализ основан на данных о сделках и не имеет важных данных о глубине.
Резюме
Мы обнаружили, что распределение объема торговли в разные временные интервалы является простым масштабированием распределения отдельных объемов торговли. Мы также разработали простую модель ожидаемой доходности, основанную на влиянии цены и вероятности торговли. Результаты этой модели соответствуют нашим ожиданиям, показывая, что если сумма ордера на продажу низкая, это указывает на снижение цены, и определенная сумма необходима для потенциала прибыли. Вероятность уменьшается по мере увеличения объема торговли, с оптимальным размером между ними, что представляет собой оптимальную стратегию размещения заказов. Однако эта модель все еще слишком упрощена. В следующей статье я углублюсь в эту тему.
В [20]:
# Cumulative distribution in 1s
df_resampled = buy_trades['quantity'].resample('1S').sum()
df_resampled = df_resampled.to_frame(name='quantity')
df_resampled = df_resampled[df_resampled['quantity']>0]
depths = np.array(range(0, 15000, 10))
mean = df_resampled['quantity'].mean()
alpha = np.log(np.mean(df_resampled['quantity'] > mean))/np.log(2.05)
probabilities_s = np.array([((1+20**(-depth/mean))*depth/mean+1)**(alpha) for depth in depths])
profit_s = np.array([depth/2e6-0.000352 for depth in depths])
plt.figure(figsize=(10, 5))
plt.plot(depths, probabilities_s*profit_s)
plt.xlabel('Q')
plt.ylabel('Excpet profit')
plt.grid(True)
Выход[20]:
- Дельта-хеджирование опционов на биткоин с помощью кривой улыбки
- Мысли о высокочастотных торговых стратегиях (5)
- Мысли о высокочастотных торговых стратегиях (4)
- Размышления о стратегии высокочастотного трейдинга (5)
- Размышления о стратегии высокочастотного трейдинга (4)
- Мысли о высокочастотных торговых стратегиях (3)
- Размышления о стратегии высокочастотного трейдинга (3)
- Размышления о стратегии высокочастотного трейдинга (2)
- Мысли о высокочастотных торговых стратегиях (1)
- Размышления о стратегии высокочастотного трейдинга (1)
- Документ описания конфигурации Futu Securities
- FMZ Quant Uniswap V3 Руководство по операциям, связанным с ликвидностью биржевых пулов (часть 1)
- FMZ количественный Uniswap V3 Сменный бассейн ликвидности соответствующие руководства по эксплуатации (часть 1)