Создайте робот для торговли биткойнами, который не будет терять деньги
Автор:Лидия., Создано: 2023-02-01 11:52:21, Обновлено: 2023-09-18 19:40:25
Создайте биткойн-торговый робот, который не потеряет деньги
Давайте воспользуемся обучением в искусственном интеллекте, чтобы построить робота для торговли цифровой валютой.
В этой статье мы создадим и применим расширенный учебный рамный номер, чтобы узнать, как сделать торговый робот Bitcoin.
Большое спасибо за программное обеспечение с открытым исходным кодом, предоставленное OpenAI и DeepMind для исследователей глубокого обучения за последние несколько лет.
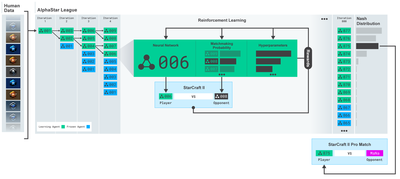
Обучение AlphaStar:https://deepmind.com/blog/alphastar-mastering-real-time-strategy-game-starcraft-ii/
Несмотря на то, что мы не создадим ничего впечатляющего, по-прежнему непросто торговать биткойн-роботами в повседневных транзакциях.
Нет никакой ценности в том, что слишком просто.
Поэтому мы должны не только научиться торговать сами, но и позволить роботам торговать за нас.
План

-
Создать спортзал для нашего робота для выполнения машинного обучения
-
Создание простой и элегантной визуальной среды
-
Обучить нашего робота выгодной торговой стратегии
Если вы не знакомы с тем, как создавать спортивные среды с нуля, или как просто визуализировать эти среды. Перед тем как продолжить, пожалуйста, не стесняйтесь искать в Google статью такого рода. Эти два действия не будут трудными даже для самых начинающих программистов.
Начало
В этом уроке мы будем использовать набор данных Kaggle, созданный Zielak. Если вы хотите загрузить исходный код, он будет предоставлен в моем хранилище Github, вместе с файлом данных.csv. Хорошо, давайте начнем.
Во-первых, давайте импортируем все необходимые библиотеки.
import gym
import pandas as pd
import numpy as np
from gym import spaces
from sklearn import preprocessing
Далее, давайте создадим наш класс для окружающей среды. Нам нужно передать номер рамки данных Pandas и необязательный initial_balance и lookback_window_size, которые укажут количество прошлых временных шагов, наблюдавшихся роботом на каждом шаге. Мы по умолчанию устанавливаем комиссию каждой транзакции на 0,075%, то есть текущий обменный курс Bitmex, и по умолчанию серийный параметр на false, что означает, что наш номер рамки данных будет пересекаться случайными фрагментами по умолчанию.
Мы также вызываем dropna() и reset_index() на данные, сначала удаляем строку с значением NaN, а затем сбрасываем индекс номера кадра, потому что мы удалили данные.
class BitcoinTradingEnv(gym.Env):
"""A Bitcoin trading environment for OpenAI gym"""
metadata = {'render.modes': ['live', 'file', 'none']}
scaler = preprocessing.MinMaxScaler()
viewer = None
def __init__(self, df, lookback_window_size=50,
commission=0.00075,
initial_balance=10000
serial=False):
super(BitcoinTradingEnv, self).__init__()
self.df = df.dropna().reset_index()
self.lookback_window_size = lookback_window_size
self.initial_balance = initial_balance
self.commission = commission
self.serial = serial
# Actions of the format Buy 1/10, Sell 3/10, Hold, etc.
self.action_space = spaces.MultiDiscrete([3, 10])
# Observes the OHCLV values, net worth, and trade history
self.observation_space = spaces.Box(low=0, high=1, shape=(10, lookback_window_size + 1), dtype=np.float16)
Наш action_space представлен как группа из 3 опционов (купить, продать или удержать) здесь и еще одна группа из 10 сумм (1/10, 2/10, 3/10, и т. д.). Когда мы выбираем купить, мы купим сумму * self.balance слово BTC. Для продажи, мы продадим сумму * self.btc_held стоимость BTC. Конечно, удержание будет игнорировать сумму и ничего не делать.
Наше observation_space определено как непрерывная плавающая точка, установленная между 0 и 1, и его форма (10, lookback_window_size+1). + 1 используется для расчета текущего временного шага. Для каждого временного шага в окне мы будем наблюдать значение OHCLV. Наше чистое состояние равно количеству BTC, которые мы покупаем или продаем, и общей сумме долларов, которые мы тратим или получаем на эти BTC.
Далее нам нужно написать метод сброса для инициализации среды.
def reset(self):
self.balance = self.initial_balance
self.net_worth = self.initial_balance
self.btc_held = 0
self._reset_session()
self.account_history = np.repeat([
[self.net_worth],
[0],
[0],
[0],
[0]
], self.lookback_window_size + 1, axis=1)
self.trades = []
return self._next_observation()
Здесь мы используем self._reset_session и self._next_observation, которые мы еще не определили. Давайте сначала их определим.
Торговая сессия
Важной частью нашей среды является концепция торговых сеансов. Если мы развернем этого робота за пределами рынка, мы никогда не сможем запустить его более нескольких месяцев за раз. По этой причине мы ограничим количество последовательных кадров в self.df, которое является числом кадров, которые наш робот может видеть в одно и то же время.
В нашем методе _reset_session мы сначала сбросим текущий_шаг на 0. Далее мы установим steps_left на случайное число от 1 до MAX_TRADING_SESSIONS, которое мы определим в верхней части программы.
MAX_TRADING_SESSION = 100000 # ~2 months
Далее, если мы хотим пересечь количество кадров последовательно, мы должны установить его, чтобы пересечь все количество кадров, в противном случае мы устанавливаем frame_start в случайную точку в self.df и создаем новый кадр данных под названием active_df, который является просто кусочком self.df и он получает от frame_start к frame_start + steps_left.
def _reset_session(self):
self.current_step = 0
if self.serial:
self.steps_left = len(self.df) - self.lookback_window_size - 1
self.frame_start = self.lookback_window_size
else:
self.steps_left = np.random.randint(1, MAX_TRADING_SESSION)
self.frame_start = np.random.randint(self.lookback_window_size, len(self.df) - self.steps_left)
self.active_df = self.df[self.frame_start - self.lookback_window_size:self.frame_start + self.steps_left]
Важным побочным эффектом пересечения числа кадров данных в случайном разрезе является то, что наш робот будет иметь более уникальные данные для использования в долгосрочной подготовке. Например, если мы пересечем количество кадров данных только последовательно (то есть от 0 до len ((df)), у нас будет только столько же уникальных точек данных, сколько количество кадров данных. Наше наблюдение пространство может использовать только дискретное количество состояний на каждом этапе времени.
Тем не менее, проходя по кусочкам набора данных случайным образом, мы можем создать более значимый набор результатов торговли для каждого временного шага в начальном наборе данных, то есть комбинацию поведения торговли и поведения цен, наблюдаемого ранее, чтобы создать более уникальные наборы данных.
Когда временной шаг после сброса серийной среды равен 10, наш робот всегда будет работать в наборе данных в одно и то же время, и после каждого временного шага есть три варианта: купить, продать или удержать. Для каждого из трех вариантов вам нужен другой вариант: 10%, 20%,... или 100% от конкретной суммы реализации. Это означает, что наш робот может столкнуться с одним из 10 состояний из любых 103, в общей сложности 1030 случаев.
Теперь вернемся к нашей среде случайного нарезания. Когда временной шаг равен 10, наш робот может находиться в любом временном шаге len ((df) в пределах количества кадров данных. Предполагая, что после каждого временного шага делается один и тот же выбор, это означает, что робот может испытать уникальное состояние любого len ((df) к 30-й степени в тех же 10 временных шагах.
Несмотря на то, что это может привести к значительному шуму в больших наборах данных, я считаю, что роботам следует позволить больше узнать из наших ограниченных данных. Мы все равно будем проходить наши тестовые данные последовательно, чтобы получить самые свежие и, казалось бы, "реальные" данные, чтобы получить более точное понимание благодаря эффективности алгоритма.
Наблюдение глазами робота
Благодаря эффективному визуальному наблюдению за окружающей средой часто полезно понять тип функций, которые будет использовать наш робот.
Наблюдение среды визуализации OpenCV
Каждая линия на изображении представляет собой ряд в нашем observation_space. Первые четыре линии красных линий с аналогичной частотой представляют данные OHCL, а оранжевые и желтые точки непосредственно ниже представляют объем торговли. Колебающаяся синяя полоса ниже представляет чистую стоимость робота, а более легкая полоса ниже представляет транзакцию робота.
Если внимательно наблюдать, можно даже самостоятельно сделать карту свечей. Под строкой объема торговли находится интерфейс с кодом Морзе, отображающий историю торговли. Похоже, наш робот должен быть в состоянии достаточно учиться из данных в нашем observation_space, так что давайте продолжим. Здесь мы определим метод _next_observation, мы масштабируем наблюдаемые данные от 0 до 1.
- Важно расширить только данные, наблюдаемые роботом до сих пор, чтобы предотвратить ведущее отклонение.
def _next_observation(self):
end = self.current_step + self.lookback_window_size + 1
obs = np.array([
self.active_df['Open'].values[self.current_step:end],
self.active_df['High'].values[self.current_step:end],
self.active_df['Low'].values[self.current_step:end],
self.active_df['Close'].values[self.current_step:end],
self.active_df['Volume_(BTC)'].values[self.current_step:end],])
scaled_history = self.scaler.fit_transform(self.account_history)
obs = np.append(obs, scaled_history[:, -(self.lookback_window_size + 1):], axis=0)
return obs
Примите меры.
Мы установили наше пространство наблюдения, и теперь пришло время написать нашу функцию лестницы, а затем выполнить запланированное действие робота. Всякий раз, когда self.steps_left == 0 для нашей текущей торговой сессии, мы продадим наш BTC и вызовем _reset_session(). В противном случае мы установим вознаграждение на текущую чистую стоимость. Если у нас закончатся средства, мы установим выполненное на True.
def step(self, action):
current_price = self._get_current_price() + 0.01
self._take_action(action, current_price)
self.steps_left -= 1
self.current_step += 1
if self.steps_left == 0:
self.balance += self.btc_held * current_price
self.btc_held = 0
self._reset_session()
obs = self._next_observation()
reward = self.net_worth
done = self.net_worth <= 0
return obs, reward, done, {}
Принятие торгового действия так же просто, как получение текущей_цены, определение действий, которые должны быть выполнены, и количество, которое нужно купить или продать.
def _take_action(self, action, current_price):
action_type = action[0]
amount = action[1] / 10
btc_bought = 0
btc_sold = 0
cost = 0
sales = 0
if action_type < 1:
btc_bought = self.balance / current_price * amount
cost = btc_bought * current_price * (1 + self.commission)
self.btc_held += btc_bought
self.balance -= cost
elif action_type < 2:
btc_sold = self.btc_held * amount
sales = btc_sold * current_price * (1 - self.commission)
self.btc_held -= btc_sold
self.balance += sales
Наконец, в том же методе, мы будем привязывать транзакцию к самостоятельной торговле и обновлять нашу чистую стоимость и историю счета.
if btc_sold > 0 or btc_bought > 0:
self.trades.append({
'step': self.frame_start+self.current_step,
'amount': btc_sold if btc_sold > 0 else btc_bought,
'total': sales if btc_sold > 0 else cost,
'type': "sell" if btc_sold > 0 else "buy"
})
self.net_worth = self.balance + self.btc_held * current_price
self.account_history = np.append(self.account_history, [
[self.net_worth],
[btc_bought],
[cost],
[btc_sold],
[sales]
], axis=1)
Наш робот может начинать новую среду сейчас, постепенно завершать среду и предпринимать действия, влияющие на окружающую среду.
Смотрите на торговлю наших роботов.
Наш метод рендеринга может быть таким же простым, как вызов print (self.net_word), но это недостаточно интересно. Вместо этого мы нарисуем простой график свечей, который содержит отдельный график столбца объема торговли и нашего чистой стоимости.
Мы получим код вStockTrackingGraph.pyВы можете получить код из моего Github.
Первое изменение, которое мы должны сделать, это обновить self.df ['Date '] на self.df [
from datetime import datetime
Во-первых, импортируйте библиотеку времени даты, а затем мы будем использовать метод utcfromtimestamp для получения строки UTC от каждой отметки времени и strftime, чтобы она была отформатирована как строка: формат Y-m-d H:M.
date_labels = np.array([datetime.utcfromtimestamp(x).strftime('%Y-%m-%d %H:%M') for x in self.df['Timestamp'].values[step_range]])
Наконец, мы изменим self. df['Volume '] на self. df[
def render(self, mode='human', **kwargs):
if mode == 'human':
if self.viewer == None:
self.viewer = BitcoinTradingGraph(self.df,
kwargs.get('title', None))
self.viewer.render(self.frame_start + self.current_step,
self.net_worth,
self.trades,
window_size=self.lookback_window_size)
Теперь мы можем наблюдать, как наши роботы торгуют биткойнами.
Визуализируйте торговлю нашего робота с Matplotlib
Зеленый фантомный ярлык представляет покупку BTC, а красный фантомный ярлык представляет продажу. Белый ярлык в правом верхнем углу - текущая чистая стоимость робота, а ярлык в правом нижнем углу - текущая цена Биткоина. Это просто и элегантно. Теперь пришло время обучить наших роботов и посмотреть, сколько денег мы можем заработать!
Время обучения
Одной из критик, которую я получил в предыдущей статье, было отсутствие перекрестной валидации и неспособность разделить данные на учебные наборы и тестовые наборы. Целью этого является проверка точности конечной модели на новых данных, которые никогда раньше не были замечены. Хотя это не является фокусом этой статьи, это действительно очень важно. Поскольку мы используем данные временных рядов, у нас нет много вариантов в перекрестной валидации.
Например, распространенная форма перекрестной проверки называется k-fold validation. При этой проверке вы делите данные на k равных групп, одну за другой, индивидуально, как тестовую группу и используете остальные данные как тренировочную группу. Однако данные временных рядов сильно зависят от времени, что означает, что последующие данные сильно зависят от предыдущих данных. Таким образом, k-fold не будет работать, потому что наш робот будет учиться на будущих данных перед торговлей, что является несправедливым преимуществом.
При применении к данным временных рядов тот же недостаток применяется к большинству других стратегий перекрестной проверки. Поэтому нам нужно использовать только часть полного номера кадров данных в качестве учебного набора от номера кадров к некоторым произвольным индексам, а остальные данные использовать в качестве тестового набора.
slice_point = int(len(df) - 100000)
train_df = df[:slice_point]
test_df = df[slice_point:]
Далее, поскольку наша среда настроена только для обработки одного числа данных, мы создадим две среды, одну для данных обучения и одну для данных теста.
train_env = DummyVecEnv([lambda: BitcoinTradingEnv(train_df, commission=0, serial=False)])
test_env = DummyVecEnv([lambda: BitcoinTradingEnv(test_df, commission=0, serial=True)])
Обучение нашей модели так же просто, как создание робота, использующего нашу среду, и вызов model.learn.
model = PPO2(MlpPolicy,
train_env,
verbose=1,
tensorboard_log="./tensorboard/")
model.learn(total_timesteps=50000)
Здесь мы используем тензорные таблицы, чтобы мы могли легко визуализировать наши тензорные графики потока и просматривать некоторые количественные показатели о нашем роботе.
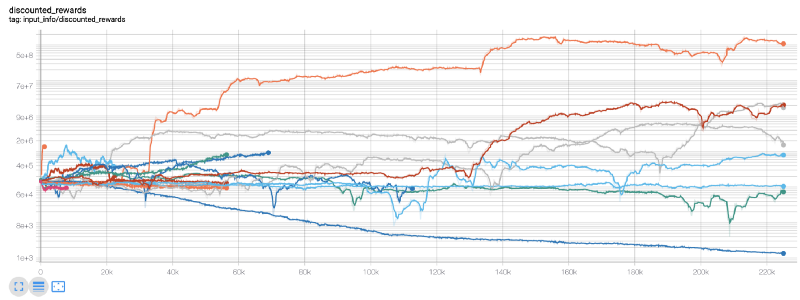
Наш лучший робот может достичь равновесия в 1000 раз за 200 000 шагов, а остальные будут увеличиваться в среднем как минимум в 30 раз!
В это время я понял, что в среде произошла ошибка... после исправления ошибки, вот новая таблица вознаграждений:
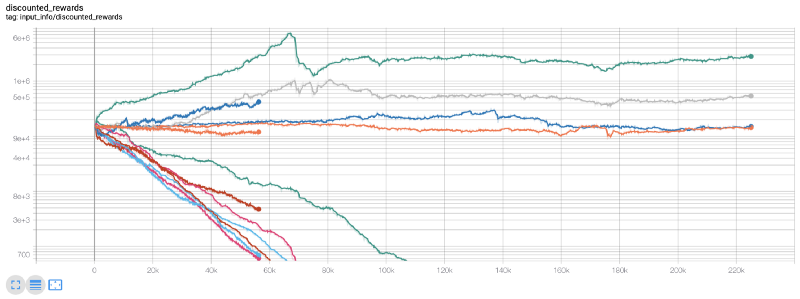
Как видите, некоторые из наших роботов хорошо работают, в то время как другие обанкрощаются. Тем не менее, роботы с хорошей производительностью могут достичь в 10 раз или даже в 60 раз больше первоначального баланса. Я должен признать, что все прибыльные машины обучаются и испытываются без комиссии, поэтому нереально для наших роботов зарабатывать реальные деньги. Но по крайней мере, мы нашли способ!
Давайте проверим наших роботов в тестовой среде (используя новые данные, которые они никогда не видели раньше), чтобы увидеть, как они будут себя вести.
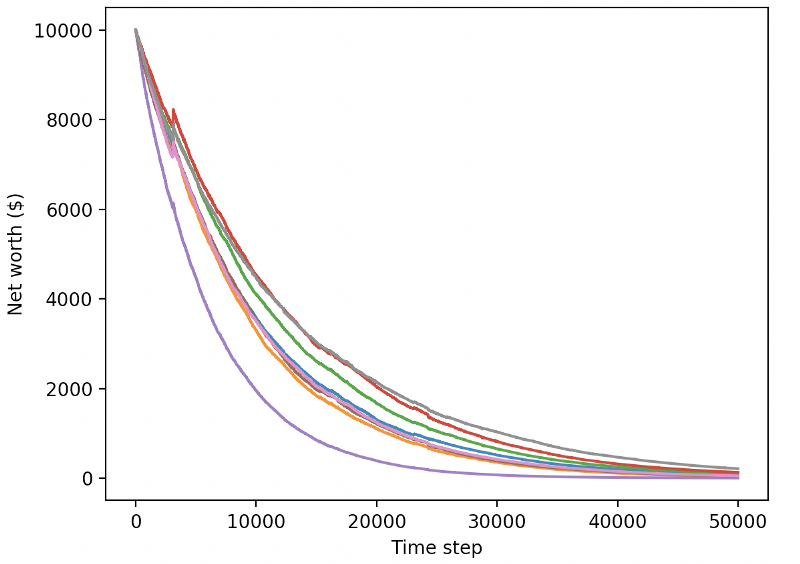
Наши хорошо обученные роботы обанкротятся при обмене новыми тестовыми данными.
Очевидно, нам еще предстоит много работы. Просто переключив модели на использование A2C со стабильной базовой линией вместо текущего робота PPO2, мы можем значительно улучшить нашу производительность на этом наборе данных. Наконец, согласно предложению Шона О'Гормана, мы можем немного обновить функцию вознаграждения, чтобы мы могли добавить вознаграждение к чистой стоимости, а не просто реализовать высокую чистую стоимость и остаться там.
reward = self.net_worth - prev_net_worth
Эти два изменения сами по себе могут значительно улучшить производительность тестового набора данных, и, как вы можете видеть ниже, мы наконец-то смогли извлечь выгоду из новых данных, которые не были доступны в учебном наборе.
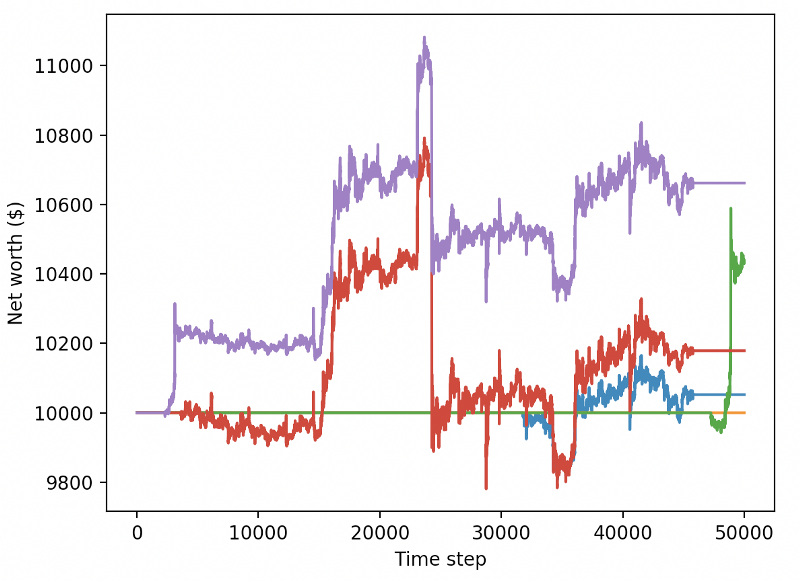
Но мы можем сделать лучше. Чтобы улучшить эти результаты, нам нужно оптимизировать наши супер параметры и обучать наших роботов дольше. Пришло время для GPU начать работать и стрелять на всех цилиндрах!
До сих пор эта статья была немного длинной, и нам еще предстоит рассмотреть много деталей, поэтому мы планируем сделать здесь перерыв. В следующей статье мы будем использовать бейесовскую оптимизацию для разделения лучших гиперпараметров для нашего проблемного пространства и подготовки к обучению / тестированию на GPU с использованием CUDA.
Заключение
В этой статье мы начнем использовать обучение усиления для создания прибыльного робота для торговли биткойнами с нуля.
-
Создайте среду для торговли биткойнами с нуля, используя тренажерный зал OpenAI.
-
Используйте Matplotlib для создания визуализации окружающей среды.
-
Используйте простое перекрестное подтверждение для обучения и тестирования нашего робота.
-
Легко настраивайте наших роботов, чтобы получить прибыль.
Хотя наш торговый робот не был таким прибыльным, как мы надеялись, мы уже движемся в правильном направлении. В следующий раз мы обеспечим, чтобы наши роботы могли последовательно побеждать рынок. Мы увидим, как наши торговые роботы обрабатывают данные в режиме реального времени. Пожалуйста, продолжайте следить за моей следующей статьей и Viva Bitcoin!
- Количественный анализ фундаментального анализа на рынке криптовалют: пусть данные говорят сами за себя!
- Не стоит больше верить всяким хитроумным учителям, которые говорят, что данные объективны.
- Необходимый инструмент для количественной торговли - изобретатель модуля количественного исследования данных
- Освоение всего - Введение в FMZ Новая версия торгового терминала (с TRB Arbitrage Source Code)
- Ознакомьтесь с новым типом терминала FMZ (с кодом TRB)
- FMZ Quant: Анализ общих требований Примеры проектирования на рынке криптовалют (II)
- Как использовать бесмозговых роботов с высокочастотной стратегией в 80 строках кода
- Квалификация FMZ: Анализ примеров дизайна общих потребностей на рынке криптовалют (II)
- Как использовать высокочастотную стратегию 80-линейного кода для эксплуатации безмозговых роботов
- FMZ Quant: Анализ общих требований Примеры проектирования на рынке криптовалют (I)
- Квалификация FMZ: Анализ примеров дизайна общих потребностей на рынке криптовалют (1)