مارکیٹ کی قیمتوں کا تعین جمع کرنے والا ایک بار پھر اپ گریڈ
مصنف:نیکی, تخلیق: 2020-05-26 14:25:15, تازہ کاری: 2023-11-02 19:53:34
اپنی مرضی کے مطابق ڈیٹا ماخذ فراہم کرنے کے لئے CSV فارمیٹ فائل درآمد کی حمایت
حال ہی میں ، ایک تاجر کو ایف ایم زیڈ پلیٹ فارم بیک ٹیسٹ سسٹم کے لئے ڈیٹا ماخذ کے طور پر اپنی سی ایس وی فارمیٹ فائل استعمال کرنے کی ضرورت ہے۔ ہمارے پلیٹ فارم کے بیک ٹیسٹ سسٹم میں بہت سارے کام ہیں اور اس کا استعمال آسان اور موثر ہے ، تاکہ جب تک صارفین کے پاس اپنے ڈیٹا ہوں ، وہ ان اعداد و شمار کے مطابق بیک ٹیسٹنگ کرسکیں ، جو اب ہمارے پلیٹ فارم ڈیٹا سینٹر کے ذریعہ تعاون یافتہ تبادلے اور اقسام تک محدود نہیں ہے۔
ڈیزائن کے خیالات
ڈیزائن خیال اصل میں بہت آسان ہے. ہم صرف اس سے پہلے مارکیٹ جمع کرنے کی بنیاد پر تھوڑا سا تبدیل کرنے کی ضرورت ہے. ہم ایک پیرامیٹر شاملisOnlySupportCSVاس بات کا کنٹرول کرنے کے لئے کہ آیا بیک ٹسٹ سسٹم کے لئے صرف سی ایس وی فائل کو ڈیٹا ماخذ کے طور پر استعمال کیا جاتا ہے۔filePathForCSVسی ایس وی ڈیٹا فائل کا راستہ مقرر کرنے کے لئے استعمال کیا جاتا ہے جو سرور پر رکھا جاتا ہے جہاں مارکیٹ کلیکٹر روبوٹ چلتا ہے۔ آخر میں اس پر مبنی ہے کہ آیاisOnlySupportCSVپیرامیٹر پر مقرر کیا گیا ہےTrueفیصلہ کرنے کے لئے کہ کون سا ڈیٹا ماخذ استعمال کرنا ہے (آپ کے ذریعہ جمع کردہ یا CSV فائل میں ڈیٹا) ، یہ تبدیلی بنیادی طور پرdo_GETفنکشنProvider class.
سی ایس وی فائل کیا ہے؟
کوما سے الگ کردہ اقدار ، جسے سی ایس وی بھی کہا جاتا ہے ، کبھی کبھی حروف سے الگ کردہ اقدار کے نام سے جانا جاتا ہے ، کیونکہ علیحدہ کرنے والا حروف بھی کوما نہیں ہوسکتا ہے۔ اس کی فائل ٹیبل کے اعداد و شمار (نمبر اور متن) کو سادہ متن میں اسٹور کرتی ہے۔ سادہ متن کا مطلب ہے کہ فائل حروف کا ایک سلسلہ ہے اور اس میں کوئی ڈیٹا نہیں ہے جس کی تعبیر بائنری نمبر کی طرح کی جائے۔ سی ایس وی فائل میں کسی بھی تعداد میں ریکارڈ ہوتے ہیں ، جن کو کسی نئی لائن کے کردار سے الگ کیا جاتا ہے۔ ہر ریکارڈ فیلڈز پر مشتمل ہوتا ہے ، اور فیلڈز کے مابین علیحدہ کرنے والے دوسرے حروف یا تار ہوتے ہیں ، اور سب سے زیادہ عام کوما یا ٹیب ہوتے ہیں۔ عام طور پر ، تمام ریکارڈوں میں فیلڈز کا ایک ہی ترتیب ہوتا ہے۔ وہ عام طور پر سادہ متن کی فائلیں ہوتے ہیں۔ اس کا استعمال کرنے کی سفارش کی جاتی ہے۔WORDPADیاExcelکھولنے کے لئے.
سی ایس وی فائل فارمیٹ کا عام معیار موجود نہیں ہے ، لیکن کچھ اصول موجود ہیں ، عام طور پر ہر سطر میں ایک ریکارڈ ہوتا ہے ، اور پہلی سطر ہیڈر ہوتی ہے۔ ہر سطر میں موجود ڈیٹا کو کوما سے الگ کیا جاتا ہے۔
مثال کے طور پر، ہم نے جس CSV فائل کو ٹیسٹنگ کے لیے استعمال کیا ہے وہ نوٹ پیڈ کے ذریعے اس طرح کھولی جاتی ہے:
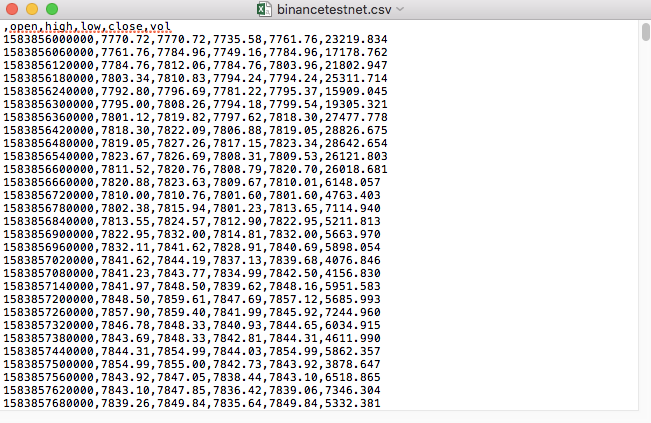
مشاہدہ کیا کہ CSV فائل کی پہلی سطر ٹیبل ہیڈر ہے.
,open,high,low,close,vol
ہمیں صرف ان اعداد و شمار کو تجزیہ اور ترتیب دینے کی ضرورت ہے ، اور پھر اسے بیک ٹیسٹ سسٹم کے کسٹم ڈیٹا ماخذ کے ذریعہ مطلوبہ شکل میں تشکیل دیں۔ ہمارے پچھلے مضمون میں یہ کوڈ پہلے ہی پروسیس ہوچکا ہے ، اور صرف تھوڑا سا ترمیم کرنے کی ضرورت ہے۔
ترمیم شدہ کوڈ
import _thread
import pymongo
import json
import math
import csv
from http.server import HTTPServer, BaseHTTPRequestHandler
from urllib.parse import parse_qs, urlparse
def url2Dict(url):
query = urlparse(url).query
params = parse_qs(query)
result = {key: params[key][0] for key in params}
return result
class Provider(BaseHTTPRequestHandler):
def do_GET(self):
global isOnlySupportCSV, filePathForCSV
try:
self.send_response(200)
self.send_header("Content-type", "application/json")
self.end_headers()
dictParam = url2Dict(self.path)
Log("The custom data source service receives the request,self.path:", self.path, "query parameter:", dictParam)
# At present, the backtest system can only select the exchange name from the list. When adding a custom data source, set it to Binance, that is: Binance
exName = exchange.GetName()
# Note that period is the bottom K-line period
tabName = "%s_%s" % ("records", int(int(dictParam["period"]) / 1000))
priceRatio = math.pow(10, int(dictParam["round"]))
amountRatio = math.pow(10, int(dictParam["vround"]))
fromTS = int(dictParam["from"]) * int(1000)
toTS = int(dictParam["to"]) * int(1000)
# Request data
data = {
"schema" : ["time", "open", "high", "low", "close", "vol"],
"data" : []
}
if isOnlySupportCSV:
# Handle CSV reading, filePathForCSV path
listDataSequence = []
with open(filePathForCSV, "r") as f:
reader = csv.reader(f)
# Get table header
header = next(reader)
headerIsNoneCount = 0
if len(header) != len(data["schema"]):
Log("The CSV file format is wrong, the number of columns is different, please check!", "#FF0000")
return
for ele in header:
for i in range(len(data["schema"])):
if data["schema"][i] == ele or ele == "":
if ele == "":
headerIsNoneCount += 1
if headerIsNoneCount > 1:
Log("The CSV file format is incorrect, please check!", "#FF0000")
return
listDataSequence.append(i)
break
# Read content
while True:
record = next(reader, -1)
if record == -1:
break
index = 0
arr = [0, 0, 0, 0, 0, 0]
for ele in record:
arr[listDataSequence[index]] = int(ele) if listDataSequence[index] == 0 else (int(float(ele) * amountRatio) if listDataSequence[index] == 5 else int(float(ele) * priceRatio))
index += 1
data["data"].append(arr)
Log("data: ", data, "Respond to backtest system requests.")
self.wfile.write(json.dumps(data).encode())
return
# Connect to the database
Log("Connect to the database service to obtain data, the database: ", exName, "table: ", tabName)
myDBClient = pymongo.MongoClient("mongodb://localhost:27017")
ex_DB = myDBClient[exName]
exRecords = ex_DB[tabName]
# Construct query conditions: greater than a certain value {'age': {'$ gt': 20}} less than a certain value {'age': {'$lt': 20}}
dbQuery = {"$and":[{'Time': {'$gt': fromTS}}, {'Time': {'$lt': toTS}}]}
Log("Query conditions: ", dbQuery, "Number of inquiries: ", exRecords.find(dbQuery).count(), "Total number of databases: ", exRecords.find().count())
for x in exRecords.find(dbQuery).sort("Time"):
# Need to process data accuracy according to request parameters round and vround
bar = [x["Time"], int(x["Open"] * priceRatio), int(x["High"] * priceRatio), int(x["Low"] * priceRatio), int(x["Close"] * priceRatio), int(x["Volume"] * amountRatio)]
data["data"].append(bar)
Log("data: ", data, "Respond to backtest system requests.")
# Write data response
self.wfile.write(json.dumps(data).encode())
except BaseException as e:
Log("Provider do_GET error, e:", e)
def createServer(host):
try:
server = HTTPServer(host, Provider)
Log("Starting server, listen at: %s:%s" % host)
server.serve_forever()
except BaseException as e:
Log("createServer error, e:", e)
raise Exception("stop")
def main():
LogReset(1)
if (isOnlySupportCSV):
try:
# _thread.start_new_thread(createServer, (("localhost", 9090), )) # local test
_thread.start_new_thread(createServer, (("0.0.0.0", 9090), )) # Test on VPS server
Log("Start the custom data source service thread, and the data is provided by the CSV file. ", "#FF0000")
except BaseException as e:
Log("Failed to start the custom data source service!")
Log("Error message: ", e)
raise Exception("stop")
while True:
LogStatus(_D(), "Only start the custom data source service, do not collect data!")
Sleep(2000)
exName = exchange.GetName()
period = exchange.GetPeriod()
Log("collect", exName, "Exchange K-line data,", "K line cycle:", period, "Second")
# Connect to the database service, service address mongodb: //127.0.0.1: 27017 See the settings of mongodb installed on the server
Log("Connect to the mongodb service of the hosting device, mongodb://localhost:27017")
myDBClient = pymongo.MongoClient("mongodb://localhost:27017")
# Create a database
ex_DB = myDBClient[exName]
# Print the current database table
collist = ex_DB.list_collection_names()
Log("mongodb", exName, "collist:", collist)
# Check if the table is deleted
arrDropNames = json.loads(dropNames)
if isinstance(arrDropNames, list):
for i in range(len(arrDropNames)):
dropName = arrDropNames[i]
if isinstance(dropName, str):
if not dropName in collist:
continue
tab = ex_DB[dropName]
Log("dropName:", dropName, "delete:", dropName)
ret = tab.drop()
collist = ex_DB.list_collection_names()
if dropName in collist:
Log(dropName, "failed to delete")
else :
Log(dropName, "successfully deleted")
# Start a thread to provide a custom data source service
try:
# _thread.start_new_thread(createServer, (("localhost", 9090), )) # local test
_thread.start_new_thread(createServer, (("0.0.0.0", 9090), )) # Test on VPS server
Log("Open the custom data source service thread", "#FF0000")
except BaseException as e:
Log("Failed to start the custom data source service!")
Log("Error message:", e)
raise Exception("stop")
# Create the records table
ex_DB_Records = ex_DB["%s_%d" % ("records", period)]
Log("Start collecting", exName, "K-line data", "cycle:", period, "Open (create) the database table:", "%s_%d" % ("records", period), "#FF0000")
preBarTime = 0
index = 1
while True:
r = _C(exchange.GetRecords)
if len(r) < 2:
Sleep(1000)
continue
if preBarTime == 0:
# Write all BAR data for the first time
for i in range(len(r) - 1):
bar = r[i]
# Write root by root, you need to determine whether the data already exists in the current database table, based on timestamp detection, if there is the data, then skip, if not write
retQuery = ex_DB_Records.find({"Time": bar["Time"]})
if retQuery.count() > 0:
continue
# Write bar to the database table
ex_DB_Records.insert_one({"High": bar["High"], "Low": bar["Low"], "Open": bar["Open"], "Close": bar["Close"], "Time": bar["Time"], "Volume": bar["Volume"]})
index += 1
preBarTime = r[-1]["Time"]
elif preBarTime != r[-1]["Time"]:
bar = r[-2]
# Check before writing data, whether the data already exists, based on time stamp detection
retQuery = ex_DB_Records.find({"Time": bar["Time"]})
if retQuery.count() > 0:
continue
ex_DB_Records.insert_one({"High": bar["High"], "Low": bar["Low"], "Open": bar["Open"], "Close": bar["Close"], "Time": bar["Time"], "Volume": bar["Volume"]})
index += 1
preBarTime = r[-1]["Time"]
LogStatus(_D(), "preBarTime:", preBarTime, "_D(preBarTime):", _D(preBarTime/1000), "index:", index)
# Increase drawing display
ext.PlotRecords(r, "%s_%d" % ("records", period))
Sleep(10000)
رن ٹیسٹ
سب سے پہلے، ہم بازار جمع کرنے والے روبوٹ کو شروع کرتے ہیں۔ ہم روبوٹ میں تبادلہ شامل کرتے ہیں اور روبوٹ کو چلنے دیتے ہیں۔
پیرامیٹر ترتیب:

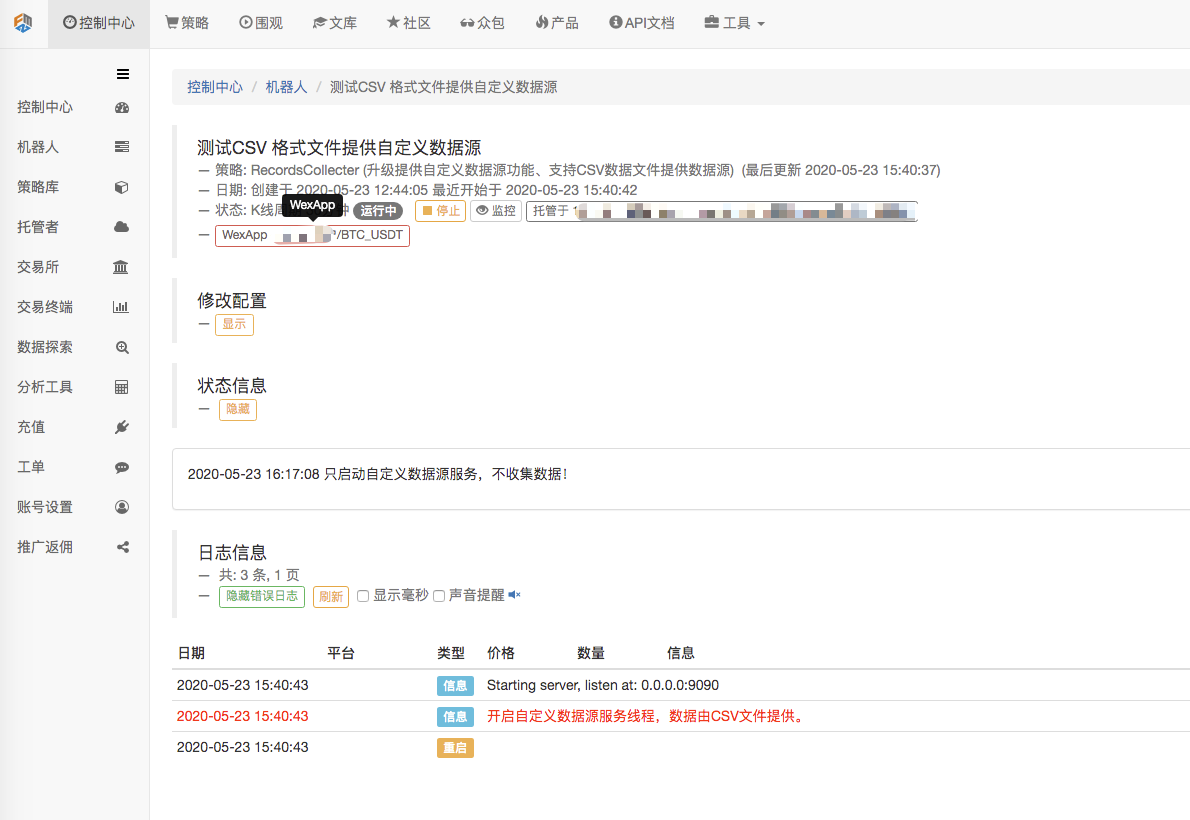
پھر ہم ایک ٹیسٹ کی حکمت عملی بناتے ہیں:
function main() {
Log(exchange.GetRecords())
Log(exchange.GetRecords())
Log(exchange.GetRecords())
}
حکمت عملی بہت سادہ ہے، صرف حاصل کریں اور تین بار K لائن ڈیٹا پرنٹ کریں.
بیک ٹیسٹ پیج پر ، بیک ٹیسٹ سسٹم کے ڈیٹا ماخذ کو کسٹم ڈیٹا ماخذ کے طور پر ترتیب دیں ، اور اس سرور کا پتہ پُر کریں جہاں مارکیٹ کلیکٹر روبوٹ چلتا ہے۔ چونکہ ہماری CSV فائل میں ڈیٹا 1 منٹ کی K لائن ہے۔ لہذا جب بیک ٹیسٹ کرتے ہیں تو ، ہم K لائن مدت کو 1 منٹ پر مقرر کرتے ہیں۔
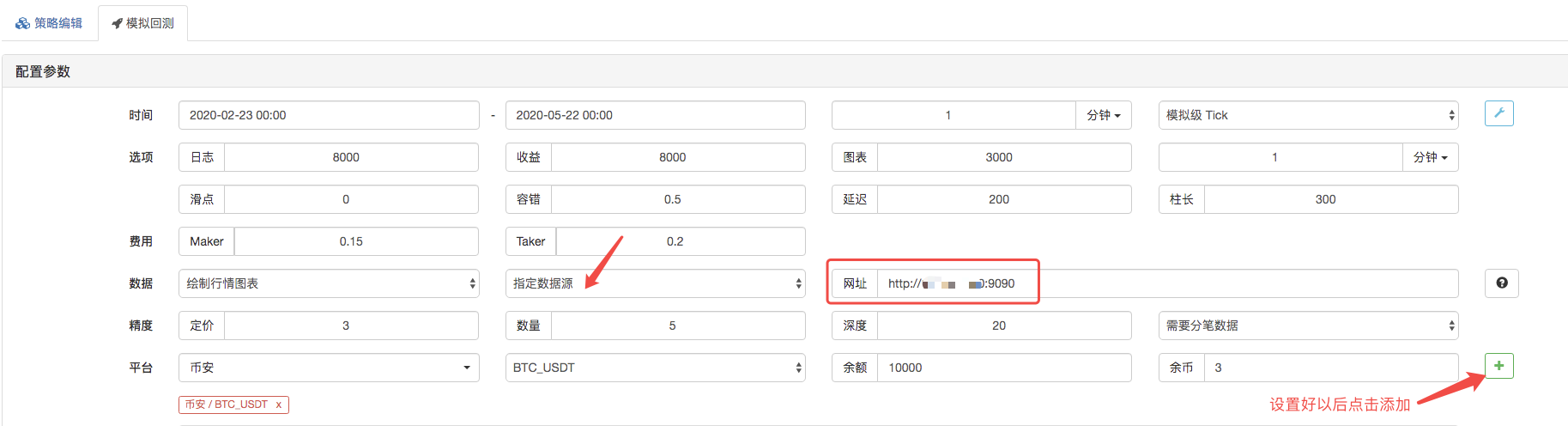
بیک ٹیسٹ شروع کرنے کے لئے کلک کریں، اور مارکیٹ جمع کرنے والا روبوٹ ڈیٹا کی درخواست وصول کرتا ہے:

بیک ٹسٹ سسٹم کی عملدرآمد کی حکمت عملی مکمل ہونے کے بعد، ڈیٹا ماخذ میں K لائن کے اعداد و شمار کی بنیاد پر ایک K لائن چارٹ تیار کیا جاتا ہے.
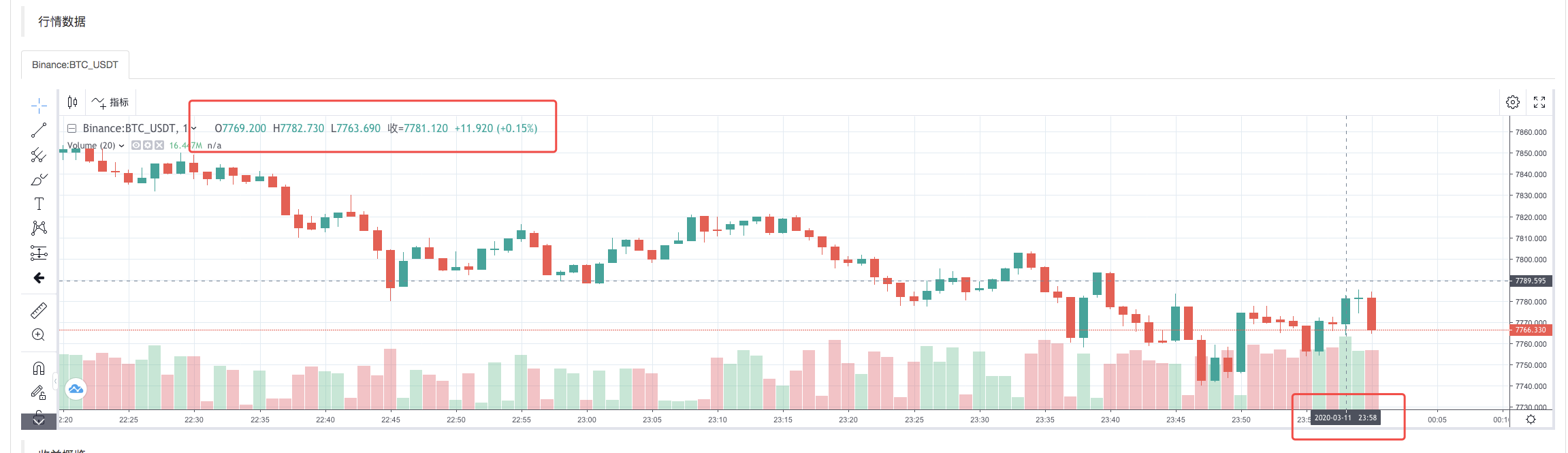
فائل کے اعداد و شمار کا موازنہ کریں:

- کریپٹوکرنسی مارکیٹ میں بنیادی تجزیہ کی مقدار: اعداد و شمار کو اپنے لئے بولنے دیں!
- ایک بار پھر ، ہم نے ایک بار پھر اس بات کا یقین کرلیا ہے کہ یہ ایک بہت بڑا مسئلہ ہے ، لیکن ہم اس کے بارے میں مزید نہیں جانتے ہیں۔
- کوانٹائزڈ ٹرانزیکشنز کے لیے ایک لازمی ٹول۔
- ہر چیز پر قابو پانا - ایف ایم زیڈ ٹریڈنگ ٹرمینل کا نیا ورژن (ٹی آر بی آربیٹریج سورس کوڈ کے ساتھ) کا تعارف
- FMZ کے نئے ورژن کے ٹرانزیکشن ٹرمینل کے بارے میں سب کچھ جاننے کے لئے یہاں کلک کریں
- ایف ایم زیڈ کوانٹ: کریپٹوکرنسی مارکیٹ میں مشترکہ تقاضوں کے ڈیزائن مثالوں کا تجزیہ (II)
- 80 لائنوں کے کوڈ میں ہائی فریکوئینسی حکمت عملی کے ساتھ دماغ کے بغیر سیلز بوٹس کا استحصال کیسے کریں
- ایف ایم زیڈ کیوٹیفیکیشن: کریپٹوکرنسی مارکیٹ میں عام ضروریات کے ڈیزائن کی مثالوں کا تجزیہ (ب)
- 80 لائنوں کے کوڈ کے ساتھ ہائی فریکوئینسی کی حکمت عملی کے ساتھ فروخت کے لیے بے دماغ روبوٹ کا استحصال کیسے کیا گیا؟
- ایف ایم زیڈ کوانٹ: کریپٹوکرنسی مارکیٹ میں مشترکہ تقاضوں کے ڈیزائن مثالوں کا تجزیہ (I)
- ایف ایم زیڈ کیوٹیفیکیشن: کریپٹوکرنسی مارکیٹ میں عام ضروریات کے ڈیزائن کی مثالوں کا تجزیہ (1)