ایک بٹ کوائن ٹریڈنگ روبوٹ بنائیں جو پیسہ نہیں کھوئے گا
مصنف:لیدیہ, تخلیق: 2023-02-01 11:52:21, تازہ کاری: 2023-09-18 19:40:25
ایک بٹ کوائن ٹریڈنگ روبوٹ بنائیں جو پیسہ نہیں کھوئے گا
آئیے اے آئی میں ریفورسمنٹ لرننگ کا استعمال کرتے ہوئے ڈیجیٹل کرنسی ٹریڈنگ روبوٹ بنائیں۔
اس مضمون میں ، ہم بٹ کوائن ٹریڈنگ روبوٹ بنانے کا طریقہ سیکھنے کے لئے ایک بہتر سیکھنے کا فریم نمبر بنائیں گے اور اس کا اطلاق کریں گے۔ اس ٹیوٹوریل میں ، ہم اوپن اے آئی کے جم اور اسٹیبل بیس لائن لائبریری سے پی پی او روبوٹ استعمال کریں گے ، جو اوپن اے آئی بیس لائن لائبریری کی ایک شاخ ہے۔
اوپن اے آئی اور ڈیپ مائنڈ کے ذریعہ گذشتہ چند سالوں میں گہری سیکھنے کے محققین کے لئے فراہم کردہ اوپن سورس سافٹ ویئر کے لئے آپ کا بہت بہت شکریہ۔ اگر آپ نے الفاگو ، اوپن اے آئی فائیو ، الفا اسٹار اور دیگر ٹیکنالوجیز کے ساتھ ان کی حیرت انگیز کامیابیوں کو نہیں دیکھا ہے تو ، آپ گذشتہ سال الگ تھلگ رہ رہے ہوں گے ، لیکن آپ کو ان کی جانچ پڑتال کرنی چاہئے۔
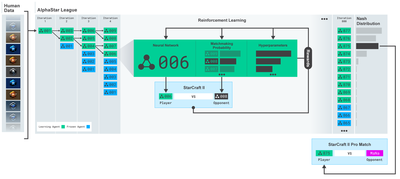
الفا سٹار ٹریننگ:https://deepmind.com/blog/alphastar-mastering-real-time-strategy-game-starcraft-ii/
اگرچہ ہم کچھ بھی متاثر کن نہیں بنائیں گے، لیکن روزانہ کے لین دین میں بٹ کوائن روبوٹ کی تجارت کرنا اب بھی آسان نہیں ہے۔ تاہم، جیسا کہ ٹیڈی روزویلٹ نے ایک بار کہا تھا،
کسی بھی چیز میں کوئی قدر نہیں ہے جو بہت سادہ ہو۔
لہذا، نہ صرف ہمیں خود ہی تجارت کرنا سیکھنا چاہئے، بلکہ روبوٹ کو بھی ہمارے لئے تجارت کرنے دیں۔
منصوبہ

-
مشین لرننگ انجام دینے کے لئے ہمارے روبوٹ کے لئے ایک جم ماحول بنائیں
-
ایک سادہ اور خوبصورت بصری ماحول فراہم کریں
-
ہمارے روبوٹ کو منافع بخش تجارتی حکمت عملی سیکھنے کے لیے تربیت دیں
اگر آپ کو جم ماحول کو شروع سے بنانے کا طریقہ معلوم نہیں ہے ، یا ان ماحول کو دیکھنے کا طریقہ نہیں ہے۔ جاری رکھنے سے پہلے ، براہ کرم اس طرح کے مضمون کو گوگل کرنے کے لئے آزاد محسوس کریں۔ یہ دونوں اقدامات سب سے کم عمر پروگرامرز کے لئے بھی مشکل نہیں ہوں گے۔
آغاز
اس سبق میں ، ہم زیلک کے ذریعہ تیار کردہ کیگل ڈیٹا سیٹ کا استعمال کریں گے۔ اگر آپ سورس کوڈ ڈاؤن لوڈ کرنا چاہتے ہیں تو ، یہ.csv ڈیٹا فائل کے ساتھ ساتھ میرے گٹ ہب ذخیرے میں فراہم کیا جائے گا۔ ٹھیک ہے ، آئیے شروع کریں۔
سب سے پہلے ، آئیے تمام ضروری لائبریریاں درآمد کریں۔ آپ کو لاپتہ لائبریریاں انسٹال کرنے کے لئے پائپ کا استعمال کرنا یقینی بنائیں۔
import gym
import pandas as pd
import numpy as np
from gym import spaces
from sklearn import preprocessing
اگلا ، آئیے ماحول کے ل our اپنا کلاس بنائیں۔ ہمیں پانڈا ڈیٹا فریم نمبر اور اختیاری initial_balance اور lookback_window_size پاس کرنے کی ضرورت ہے ، جو ہر مرحلے میں روبوٹ کے ذریعہ مشاہدہ کردہ ماضی کے وقت کے اقدامات کی تعداد کی نشاندہی کرے گا۔ ہم ہر لین دین کے کمیشن کو 0.075% ، یعنی بٹ میکس کی موجودہ شرح تبادلہ پر ڈیفالٹ کرتے ہیں ، اور سیریل پیرامیٹر کو غلط پر ڈیفالٹ کرتے ہیں ، جس کا مطلب ہے کہ ہمارے ڈیٹا فریم نمبر کو ڈیفالٹ کے ذریعہ بے ترتیب ٹکڑوں سے عبور کیا جائے گا۔
ہم بھی ڈیٹا پر dropna (() اور reset_index (() کو کال کرتے ہیں، پہلے NaN قدر کے ساتھ صف کو حذف کریں، اور پھر فریم نمبر کے انڈیکس کو دوبارہ ترتیب دیں، کیونکہ ہم نے ڈیٹا کو حذف کر دیا ہے.
class BitcoinTradingEnv(gym.Env):
"""A Bitcoin trading environment for OpenAI gym"""
metadata = {'render.modes': ['live', 'file', 'none']}
scaler = preprocessing.MinMaxScaler()
viewer = None
def __init__(self, df, lookback_window_size=50,
commission=0.00075,
initial_balance=10000
serial=False):
super(BitcoinTradingEnv, self).__init__()
self.df = df.dropna().reset_index()
self.lookback_window_size = lookback_window_size
self.initial_balance = initial_balance
self.commission = commission
self.serial = serial
# Actions of the format Buy 1/10, Sell 3/10, Hold, etc.
self.action_space = spaces.MultiDiscrete([3, 10])
# Observes the OHCLV values, net worth, and trade history
self.observation_space = spaces.Box(low=0, high=1, shape=(10, lookback_window_size + 1), dtype=np.float16)
ہماری ایکشن اسپیس کو یہاں 3 آپشنز (خرید ، فروخت یا ہولڈ) کے گروپ کے طور پر پیش کیا گیا ہے اور 10 کی رقم کا ایک اور گروپ (1/10 ، 2/10 ، 3/10 ، وغیرہ) ۔ جب ہم خریدنے کا انتخاب کرتے ہیں تو ، ہم بی ٹی سی کی رقم * خود توازن لفظ خریدیں گے۔ فروخت کے ل we ، ہم بی ٹی سی کی رقم * خود.بی ٹی سی_ ہولڈ ویلیو فروخت کریں گے۔ یقینا ، ہولڈنگ رقم کو نظرانداز کرے گی اور کچھ نہیں کرے گی۔
ہماری مشاہدہ_اسپیس کو 0 اور 1 کے درمیان طے شدہ ایک مسلسل تیرتا نقطہ کے طور پر بیان کیا گیا ہے ، اور اس کی شکل ہے (10, lookback_window_size+1). + 1 موجودہ وقت کے مرحلے کا حساب کرنے کے لئے استعمال کیا جاتا ہے۔ ونڈو میں ہر وقت کے مرحلے کے ل we ، ہم OHCLV کی قدر کا مشاہدہ کریں گے۔ ہماری خالص مالیت بی ٹی سی کی تعداد کے برابر ہے جو ہم خریدتے ہیں یا فروخت کرتے ہیں ، اور ان بی ٹی سی پر خرچ کرنے یا وصول کرنے والے ڈالر کی کل رقم۔
اگلا، ہم ماحول کو شروع کرنے کے لئے ری سیٹ کا طریقہ لکھنے کی ضرورت ہے.
def reset(self):
self.balance = self.initial_balance
self.net_worth = self.initial_balance
self.btc_held = 0
self._reset_session()
self.account_history = np.repeat([
[self.net_worth],
[0],
[0],
[0],
[0]
], self.lookback_window_size + 1, axis=1)
self.trades = []
return self._next_observation()
یہاں ہم self._reset_session اور self._next_observation استعمال کرتے ہیں، جن کی ہم نے ابھی تک وضاحت نہیں کی ہے۔ آئیے پہلے ان کی وضاحت کریں۔
تجارتی سیشن
ہمارے ماحول کا ایک اہم حصہ ٹریڈنگ سیشن کا تصور ہے۔ اگر ہم اس روبوٹ کو مارکیٹ سے باہر تعینات کرتے ہیں تو ، ہم اسے ایک وقت میں چند ماہ سے زیادہ کبھی نہیں چلاسکتے ہیں۔ اس وجہ سے ، ہم self.df میں لگاتار فریموں کی تعداد کو محدود کریں گے ، جو ایک وقت میں ہمارے روبوٹ کو دیکھنے والے فریموں کی تعداد ہے۔
ہمارے _reset_session طریقہ کار میں ، ہم پہلے current_step کو 0 پر ری سیٹ کرتے ہیں۔ اگلا ، ہم steps_left کو 1 سے MAX_TRADING_SESSIONS کے درمیان ایک بے ترتیب نمبر پر ترتیب دیں گے ، جسے ہم پروگرام کے اوپری حصے میں بیان کریں گے۔
MAX_TRADING_SESSION = 100000 # ~2 months
اگلا، اگر ہم مسلسل فریموں کی تعداد کو عبور کرنا چاہتے ہیں تو ہمیں اسے پورے فریموں کی تعداد کو عبور کرنے کے لئے ترتیب دینا ہوگا، ورنہ ہم فریم_اسٹارٹ کو سیلف.ڈی ایف میں کسی بے ترتیب نقطہ پر ترتیب دیتے ہیں اور ایک نیا ڈیٹا فریم بناتے ہیں جس کا نام فعال_ڈی ایف ہے، جو صرف سیلف.ڈی ایف کا ایک ٹکڑا ہے اور یہ فریم_اسٹارٹ سے فریم_اسٹارٹ + اقدامات_بائیں تک پہنچ رہا ہے۔
def _reset_session(self):
self.current_step = 0
if self.serial:
self.steps_left = len(self.df) - self.lookback_window_size - 1
self.frame_start = self.lookback_window_size
else:
self.steps_left = np.random.randint(1, MAX_TRADING_SESSION)
self.frame_start = np.random.randint(self.lookback_window_size, len(self.df) - self.steps_left)
self.active_df = self.df[self.frame_start - self.lookback_window_size:self.frame_start + self.steps_left]
بے ترتیب ٹکڑے میں ڈیٹا فریموں کی تعداد کو عبور کرنے کا ایک اہم ضمنی اثر یہ ہے کہ ہمارے روبوٹ کے پاس طویل مدتی تربیت میں استعمال کے ل more زیادہ انوکھے ڈیٹا ہوں گے۔ مثال کے طور پر ، اگر ہم صرف اعداد و شمار کے فریموں کی تعداد کو سیریل انداز میں عبور کرتے ہیں (یعنی ، 0 سے لے کر len ((df)) تک) ، تو ہمارے پاس صرف اعداد و شمار کے فریموں کی تعداد کے طور پر بہت سارے انوکھے ڈیٹا پوائنٹس ہوں گے۔ ہماری مشاہداتی جگہ ہر وقت کے مرحلے میں صرف ایک الگ تعداد میں ریاستوں کا استعمال کرسکتی ہے۔
تاہم ، اعداد و شمار کے سیٹ کے ٹکڑوں کو تصادفی طور پر عبور کرکے ، ہم ابتدائی اعداد و شمار کے سیٹ میں ہر وقت کے مرحلے کے لئے تجارتی نتائج کا ایک زیادہ معنی خیز سیٹ تشکیل دے سکتے ہیں ، یعنی ، تجارتی رویے اور قیمت کے رویے کا امتزاج جو پہلے دیکھا گیا ہے تاکہ مزید منفرد ڈیٹا سیٹ تیار کی جاسکے۔ میں وضاحت کرنے کے لئے ایک مثال دوں گا۔
جب سیریل ماحول کو ری سیٹ کرنے کے بعد وقت کا مرحلہ 10 ہوتا ہے تو ، ہمارا روبوٹ ہمیشہ ایک ہی وقت میں ڈیٹا سیٹ میں چلتا ہے ، اور ہر وقت کے مرحلے کے بعد تین اختیارات ہوتے ہیں: خریدیں ، بیچیں یا تھامیں۔ تینوں اختیارات میں سے ہر ایک کے ل you ، آپ کو ایک اور آپشن کی ضرورت ہوتی ہے: 10٪ ، 20٪ ،... یا مخصوص عمل درآمد کی رقم کا 100٪۔ اس کا مطلب یہ ہے کہ ہمارے روبوٹ کو کسی بھی 103 میں سے 10 ریاستوں میں سے ایک کا سامنا کرنا پڑ سکتا ہے ، مجموعی طور پر 1030 معاملات۔
اب ہمارے بے ترتیب سلائسنگ ماحول پر واپس جائیں۔ جب وقت کا قدم 10 ہوتا ہے تو ، ہمارا روبوٹ اعداد و شمار کے فریموں کی تعداد کے اندر کسی بھی len ((df) وقت کے قدم میں ہوسکتا ہے۔ یہ فرض کرتے ہوئے کہ ہر وقت کے قدم کے بعد ایک ہی انتخاب کیا جاتا ہے ، اس کا مطلب یہ ہے کہ روبوٹ ایک ہی 10 وقت کے اقدامات میں کسی بھی len ((df) کی 30 ویں طاقت کی منفرد حالت کا تجربہ کرسکتا ہے۔
اگرچہ اس سے بڑے اعداد و شمار کے سیٹوں میں کافی شور مچ سکتا ہے ، لیکن مجھے یقین ہے کہ روبوٹ کو ہمارے محدود اعداد و شمار سے زیادہ سیکھنے کی اجازت دینی چاہئے۔ ہم پھر بھی اپنے ٹیسٹ کے اعداد و شمار کو سیریل انداز میں عبور کریں گے تاکہ تازہ ترین اور بظاہر
ایک روبوٹ کی آنکھوں کے ذریعے مشاہدہ
مؤثر بصری ماحول کی مشاہدے کے ذریعے ، یہ اکثر یہ سمجھنے میں مددگار ہوتا ہے کہ ہمارے روبوٹ کے استعمال کرنے والے افعال کی قسم کیا ہے۔ مثال کے طور پر ، یہاں اوپن سی وی کا استعمال کرتے ہوئے انجام دی گئی قابل مشاہدہ جگہ کی نمائش ہے۔
اوپن سی وی کی نمائش کے ماحول کا مشاہدہ
تصویر میں ہر لائن ہمارے مشاہدے کی جگہ میں ایک صف کی نمائندگی کرتی ہے۔ اسی طرح کی تعدد کے ساتھ سرخ لائنوں کی پہلی چار لائنیں OHCL ڈیٹا کی نمائندگی کرتی ہیں ، اور براہ راست نیچے نارنجی اور پیلے رنگ کے نقطے۔ نیچے اتار چڑھاؤ والی نیلی بار روبوٹ کی خالص قیمت کی نمائندگی کرتی ہے ، جبکہ نیچے ہلکی بار روبوٹ کے لین دین کی نمائندگی کرتی ہے۔
اگر آپ احتیاط سے مشاہدہ کرتے ہیں تو ، آپ خود بھی موم بتی کا نقشہ بناسکتے ہیں۔ تجارتی حجم بار کے نیچے ایک مورس کوڈ انٹرفیس ہے ، جو تجارتی تاریخ کو ظاہر کرتا ہے۔ ایسا لگتا ہے کہ ہمارے روبوٹ کو ہمارے مشاہدے کی جگہ میں موجود اعداد و شمار سے کافی حد تک سیکھنے کے قابل ہونا چاہئے ، لہذا آئیے جاری رکھیں۔ یہاں ہم _next_ مشاہدے کے طریقہ کار کی وضاحت کریں گے ، ہم مشاہدہ کردہ اعداد و شمار کو 0 سے 1 تک پیمانے پر رکھیں گے۔
- یہ ضروری ہے کہ صرف روبوٹ کی طرف سے اب تک مشاہدہ کردہ اعداد و شمار کو بڑھانے کے لئے اہم انحراف کو روکنے کے لئے.
def _next_observation(self):
end = self.current_step + self.lookback_window_size + 1
obs = np.array([
self.active_df['Open'].values[self.current_step:end],
self.active_df['High'].values[self.current_step:end],
self.active_df['Low'].values[self.current_step:end],
self.active_df['Close'].values[self.current_step:end],
self.active_df['Volume_(BTC)'].values[self.current_step:end],])
scaled_history = self.scaler.fit_transform(self.account_history)
obs = np.append(obs, scaled_history[:, -(self.lookback_window_size + 1):], axis=0)
return obs
عمل کریں
ہم نے اپنی مشاہداتی جگہ قائم کی ہے ، اور اب وقت آگیا ہے کہ ہم اپنی سیڑھی کا فنکشن لکھیں ، اور پھر روبوٹ کی شیڈول کارروائی کریں۔ جب بھی self.steps_left == 0 ہمارے موجودہ تجارتی سیشن کے لئے ، ہم اپنا بی ٹی سی فروخت کریں گے اور _reset_session کو کال کریں گے۔ بصورت دیگر ، ہم موجودہ خالص قیمت پر انعام مقرر کریں گے۔ اگر ہمارے پاس فنڈز ختم ہوجاتے ہیں تو ، ہم سچ پر مقرر ہوجائیں گے۔
def step(self, action):
current_price = self._get_current_price() + 0.01
self._take_action(action, current_price)
self.steps_left -= 1
self.current_step += 1
if self.steps_left == 0:
self.balance += self.btc_held * current_price
self.btc_held = 0
self._reset_session()
obs = self._next_observation()
reward = self.net_worth
done = self.net_worth <= 0
return obs, reward, done, {}
تجارتی کارروائی کرنا اتنا ہی آسان ہے جتنا موجودہ_قیمت حاصل کرنا ، انجام دینے کے لئے کارروائیوں کا تعین کرنا اور خریدنے یا فروخت کرنے کی مقدار۔ آئیے جلدی سے _take_action لکھیں تاکہ ہم اپنے ماحول کی جانچ کرسکیں۔
def _take_action(self, action, current_price):
action_type = action[0]
amount = action[1] / 10
btc_bought = 0
btc_sold = 0
cost = 0
sales = 0
if action_type < 1:
btc_bought = self.balance / current_price * amount
cost = btc_bought * current_price * (1 + self.commission)
self.btc_held += btc_bought
self.balance -= cost
elif action_type < 2:
btc_sold = self.btc_held * amount
sales = btc_sold * current_price * (1 - self.commission)
self.btc_held -= btc_sold
self.balance += sales
آخر میں، اسی طریقہ کار کے مطابق، ہم ٹرانزیکشن کو خود ٹریڈز سے منسلک کریں گے اور اپنے خالص مالیت اور اکاؤنٹ کی تاریخ کو اپ ڈیٹ کریں گے.
if btc_sold > 0 or btc_bought > 0:
self.trades.append({
'step': self.frame_start+self.current_step,
'amount': btc_sold if btc_sold > 0 else btc_bought,
'total': sales if btc_sold > 0 else cost,
'type': "sell" if btc_sold > 0 else "buy"
})
self.net_worth = self.balance + self.btc_held * current_price
self.account_history = np.append(self.account_history, [
[self.net_worth],
[btc_bought],
[cost],
[btc_sold],
[sales]
], axis=1)
ہمارا روبوٹ اب ایک نیا ماحول شروع کر سکتا ہے، ماحول کو آہستہ آہستہ مکمل کر سکتا ہے، اور ایسے اقدامات کر سکتا ہے جو ماحول کو متاثر کرتے ہیں۔ اب وقت آگیا ہے کہ تجارت کو دیکھیں.
ہماری روبوٹ تجارت کو دیکھو
ہمارے رینڈرنگ کا طریقہ اتنا ہی آسان ہوسکتا ہے جتنا پرنٹ (self.net_word) کو کال کرنا ، لیکن یہ کافی دلچسپ نہیں ہے۔ اس کے بجائے ، ہم ایک سادہ موم بتی کا چارٹ تیار کریں گے ، جس میں تجارتی حجم کے کالم اور ہماری خالص مالیت کا علیحدہ چارٹ موجود ہے۔
ہم کوڈ میں حاصل کریں گےStockTrackingGraph.pyمیرے پچھلے مضمون سے اور اسے بٹ کوائن ماحول کے مطابق ڈھانپنے کے لیے دوبارہ ڈیزائن کریں۔ آپ میرا کوڈ گٹ ہب سے حاصل کر سکتے ہیں۔
پہلی تبدیلی جو ہمیں کرنے کی ضرورت ہے وہ یہ ہے کہ ہم self.df ['تاریخ '] کو self.df [
from datetime import datetime
سب سے پہلے، datetime لائبریری درآمد، اور پھر ہم ہر ٹائم اسٹیمپ اور strftime سے UTC تار حاصل کرنے کے لئے utcfromtimestamp طریقہ استعمال کریں گے تاکہ یہ ایک تار کے طور پر فارمیٹ کیا جاتا ہے: Y-m-d H: M شکل.
date_labels = np.array([datetime.utcfromtimestamp(x).strftime('%Y-%m-%d %H:%M') for x in self.df['Timestamp'].values[step_range]])
آخر میں ، ہم اپنے ڈیٹا سیٹ سے ملنے کے لئے خود کو تبدیل کریں گے۔ ڈی ایف ['حجم '] خود کو۔ ڈی ایف [
def render(self, mode='human', **kwargs):
if mode == 'human':
if self.viewer == None:
self.viewer = BitcoinTradingGraph(self.df,
kwargs.get('title', None))
self.viewer.render(self.frame_start + self.current_step,
self.net_worth,
self.trades,
window_size=self.lookback_window_size)
اب ہم اپنے روبوٹس کو بٹ کوائنز کی تجارت کرتے دیکھ سکتے ہیں۔
ہمارے روبوٹ کو میٹ پلٹلب کے ساتھ تجارت کرتے ہوئے تصور کریں
گرین فینٹم لیبل بی ٹی سی کی خریداری کی نمائندگی کرتا ہے ، اور سرخ فینٹم لیبل فروخت کی نمائندگی کرتا ہے۔ اوپری دائیں کونے میں سفید لیبل روبوٹ کی موجودہ خالص قیمت ہے ، اور نیچے دائیں کونے میں لیبل بٹ کوائن کی موجودہ قیمت ہے۔ یہ آسان اور خوبصورت ہے۔ اب ، یہ وقت ہے کہ ہم اپنے روبوٹ کو تربیت دیں اور دیکھیں کہ ہم کتنا پیسہ کما سکتے ہیں!
تربیت کا وقت
پچھلے مضمون میں مجھے موصول ہونے والی تنقیدوں میں سے ایک کراس ویلیڈیشن کی کمی اور اعداد و شمار کو ٹریننگ سیٹوں اور ٹیسٹ سیٹوں میں تقسیم کرنے میں ناکامی تھی۔ اس کا مقصد حتمی ماڈل کی درستگی کو نئے اعداد و شمار پر جانچنا ہے جو پہلے کبھی نہیں دیکھا گیا تھا۔ اگرچہ اس مضمون کا یہ مرکز نہیں ہے ، لیکن یہ واقعی بہت اہم ہے۔ کیونکہ ہم ٹائم سیریز کے اعداد و شمار کا استعمال کرتے ہیں ، لہذا ہمارے پاس کراس ویلیڈیشن میں بہت سارے انتخاب نہیں ہیں۔
مثال کے طور پر ، کراس ویلیڈیشن کی ایک عام شکل کو ک-فولڈ ویلیڈیشن کہا جاتا ہے۔ اس ویلیڈیشن میں ، آپ ڈیٹا کو ک برابر گروپوں میں تقسیم کرتے ہیں ، ایک ایک کرکے ، انفرادی طور پر ، ٹیسٹ گروپ کے طور پر اور باقی ڈیٹا کو ٹریننگ گروپ کے طور پر استعمال کرتے ہیں۔ تاہم ، ٹائم سیریز کے اعداد و شمار وقت پر بہت منحصر ہیں ، جس کا مطلب ہے کہ بعد کے اعداد و شمار پچھلے اعداد و شمار پر بہت منحصر ہیں۔ لہذا ک-فولڈ کام نہیں کرے گا ، کیونکہ ہمارا روبوٹ تجارت سے پہلے مستقبل کے اعداد و شمار سے سیکھے گا ، جو ایک غیر منصفانہ فائدہ ہے۔
جب وقت کی سیریز کے اعداد و شمار پر لاگو کیا جاتا ہے تو ، وہی نقص زیادہ تر دیگر کراس ویلیڈیشن حکمت عملیوں پر لاگو ہوتا ہے۔ لہذا ، ہمیں صرف مکمل ڈیٹا فریم نمبر کا ایک حصہ فریم نمبر سے کچھ مرضی کے مطابق اشاریوں تک ٹریننگ سیٹ کے طور پر استعمال کرنے کی ضرورت ہے ، اور باقی ڈیٹا کو ٹیسٹ سیٹ کے طور پر استعمال کریں۔
slice_point = int(len(df) - 100000)
train_df = df[:slice_point]
test_df = df[slice_point:]
اگلا، چونکہ ہمارے ماحول کو صرف ایک ہی اعداد و شمار کے فریم کو سنبھالنے کے لئے ترتیب دیا گیا ہے، ہم دو ماحول بنائیں گے، ایک تربیت کے اعداد و شمار کے لئے اور ایک ٹیسٹ کے اعداد و شمار کے لئے.
train_env = DummyVecEnv([lambda: BitcoinTradingEnv(train_df, commission=0, serial=False)])
test_env = DummyVecEnv([lambda: BitcoinTradingEnv(test_df, commission=0, serial=True)])
اب، ہمارے ماڈل کو تربیت دینا اتنا ہی آسان ہے جتنا ہمارے ماحول کا استعمال کرتے ہوئے ایک روبوٹ بنانا اور ماڈل.لرن کو کال کرنا۔
model = PPO2(MlpPolicy,
train_env,
verbose=1,
tensorboard_log="./tensorboard/")
model.learn(total_timesteps=50000)
یہاں ، ہم ٹینسر پلیٹوں کا استعمال کرتے ہیں ، لہذا ہم اپنے ٹینسر فلو چارٹس کو آسانی سے دیکھ سکتے ہیں اور اپنے روبوٹ کے بارے میں کچھ مقداری اشارے دیکھ سکتے ہیں۔ مثال کے طور پر ، مندرجہ ذیل 200،000 سے زیادہ وقت کے اقدامات والے بہت سارے روبوٹ کے رعایتی انعامات کا چارٹ ہے:
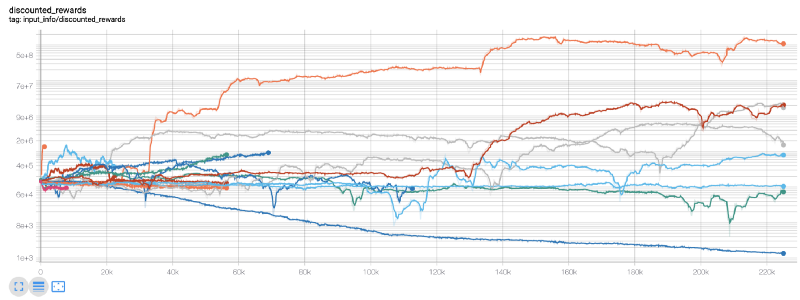
واہ، ایسا لگتا ہے کہ ہمارا روبوٹ بہت منافع بخش ہے۔ ہمارا بہترین روبوٹ 200،000 قدموں میں 1000 گنا توازن بھی حاصل کرسکتا ہے، اور باقی اوسطاً کم از کم 30 گنا بڑھ جائے گا!
اس وقت، میں نے احساس ہوا کہ ماحول میں ایک غلطی تھی... مسئلے کو ٹھیک کرنے کے بعد، یہ نیا انعام چارٹ ہے:
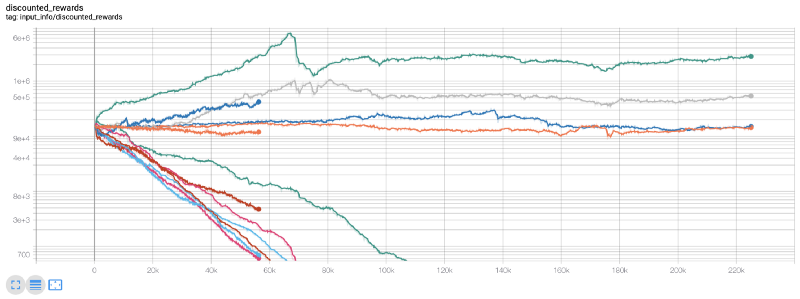
جیسا کہ آپ دیکھ سکتے ہیں ، ہمارے کچھ روبوٹ اچھی طرح سے کام کر رہے ہیں ، جبکہ دوسرے دیوالیہ ہو رہے ہیں۔ تاہم ، اچھی کارکردگی کے حامل روبوٹ زیادہ سے زیادہ ابتدائی توازن کے 10 گنا یا 60 گنا تک پہنچ سکتے ہیں۔ مجھے یہ تسلیم کرنا ہوگا کہ تمام منافع بخش مشینوں کو بغیر کمیشن کے تربیت اور تجربہ کیا جاتا ہے ، لہذا ہمارے روبوٹ کے لئے کوئی حقیقی پیسہ کمانا غیر حقیقت پسندانہ ہے۔ لیکن کم از کم ہمیں راستہ مل گیا!
آئیے اپنے روبوٹ کو ٹیسٹ ماحول میں آزمائیں (نئے ڈیٹا کا استعمال کرتے ہوئے جو انہوں نے پہلے کبھی نہیں دیکھا ہے) یہ دیکھنے کے لئے کہ وہ کیسے برتاؤ کریں گے۔
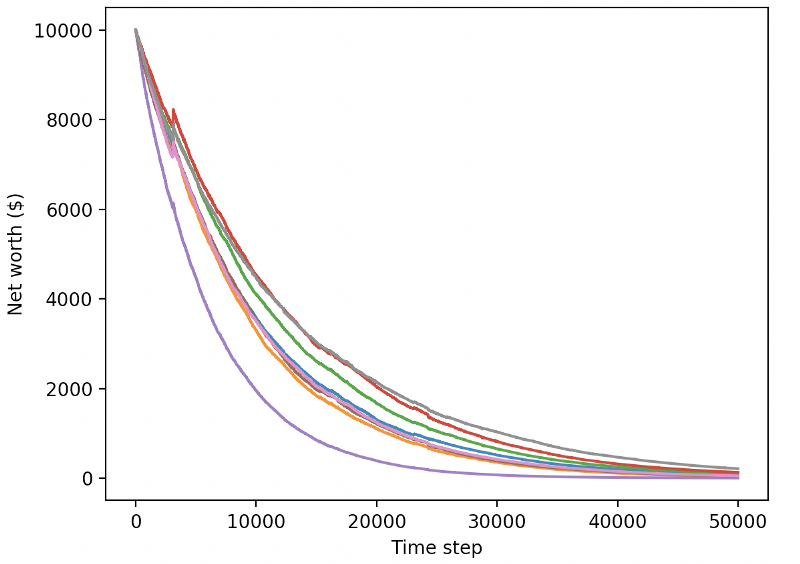
ہمارے اچھی طرح تربیت یافتہ روبوٹ نئے ٹیسٹ کے اعداد و شمار کی تجارت کرتے وقت دیوالیہ ہو جائے گا
واضح طور پر ، ہمارے پاس ابھی بہت کام کرنا باقی ہے۔ موجودہ پی پی او 2 روبوٹ کے بجائے مستحکم بیس لائن کے ساتھ اے 2 سی کا استعمال کرنے کے لئے ماڈل کو تبدیل کرکے ، ہم اس ڈیٹا سیٹ پر اپنی کارکردگی کو بہت بہتر بنا سکتے ہیں۔ آخر میں ، شان اوگورمین کی تجویز کے مطابق ، ہم اپنے انعامی فنکشن کو تھوڑا سا اپ ڈیٹ کرسکتے ہیں ، تاکہ ہم خالص مالیت میں انعام شامل کرسکیں ، نہ کہ صرف اعلی خالص مالیت کا احساس کریں اور وہاں رہیں۔
reward = self.net_worth - prev_net_worth
یہ دونوں تبدیلیاں اکیلے ٹیسٹ ڈیٹا سیٹ کی کارکردگی کو بہت بہتر بنا سکتی ہیں، اور جیسا کہ آپ نیچے دیکھ سکتے ہیں، ہم آخر کار نئے ڈیٹا سے فائدہ اٹھانے میں کامیاب ہوگئے جو ٹریننگ سیٹ میں دستیاب نہیں تھے۔
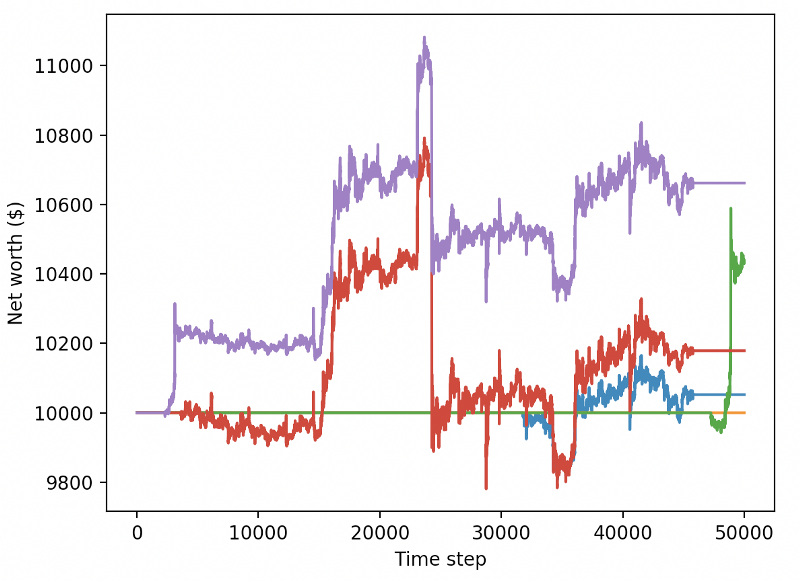
لیکن ہم بہتر کر سکتے ہیں۔ ان نتائج کو بہتر بنانے کے لیے ہمیں اپنے سپر پیرامیٹرز کو بہتر بنانے اور اپنے روبوٹس کو زیادہ وقت تک تربیت دینے کی ضرورت ہے۔ وقت آگیا ہے کہ جی پی یو کام کرنا شروع کرے اور تمام سلنڈروں پر فائرنگ کرے!
اب تک ، یہ مضمون تھوڑا سا لمبا رہا ہے ، اور ہمارے پاس ابھی بھی بہت ساری تفصیلات پر غور کرنا ہے ، لہذا ہم یہاں آرام کرنے کا ارادہ رکھتے ہیں۔ اگلے مضمون میں ، ہم اپنے مسئلے کی جگہ کے لئے بہترین ہائپر پیرامیٹرز کو تقسیم کرنے اور CUDA کا استعمال کرتے ہوئے GPU پر تربیت / جانچ کے لئے تیاری کرنے کے لئے بایسن کی اصلاح کا استعمال کریں گے۔
نتیجہ
اس مضمون میں ، ہم صفر سے منافع بخش بٹ کوائن ٹریڈنگ روبوٹ بنانے کے لئے تقویت سیکھنے کا استعمال شروع کرتے ہیں۔ ہم مندرجہ ذیل کاموں کو مکمل کرسکتے ہیں۔
-
اوپن اے آئی کے جم کا استعمال کرتے ہوئے شروع سے ہی بٹ کوائن ٹریڈنگ کا ماحول بنائیں۔
-
ماحولیات کی نمائش کی تعمیر کے لئے Matplotlib استعمال کریں.
-
ہمارے روبوٹ کو تربیت دینے اور جانچنے کے لیے سادہ کراس ویلیڈیشن کا استعمال کریں۔
-
منافع حاصل کرنے کے لیے ہمارے روبوٹ کو تھوڑا سا ایڈجسٹ کریں۔
اگرچہ ہمارا تجارتی روبوٹ اتنا منافع بخش نہیں تھا جتنا ہم نے امید کی تھی ، لیکن ہم پہلے ہی صحیح سمت میں آگے بڑھ رہے ہیں۔ اگلی بار ، ہم اس بات کو یقینی بنائیں گے کہ ہمارے روبوٹ مستقل طور پر مارکیٹ کو شکست دے سکیں۔ ہم دیکھیں گے کہ ہمارے تجارتی روبوٹ حقیقی وقت کے اعداد و شمار پر کس طرح کارروائی کرتے ہیں۔ براہ کرم میرے اگلے مضمون اور ویوا بٹ کوائن کی پیروی جاری رکھیں!
- کریپٹوکرنسی مارکیٹ میں بنیادی تجزیہ کی مقدار: اعداد و شمار کو اپنے لئے بولنے دیں!
- ایک بار پھر ، ہم نے ایک بار پھر اس بات کا یقین کرلیا ہے کہ یہ ایک بہت بڑا مسئلہ ہے ، لیکن ہم اس کے بارے میں مزید نہیں جانتے ہیں۔
- کوانٹائزڈ ٹرانزیکشنز کے لیے ایک لازمی ٹول۔
- ہر چیز پر قابو پانا - ایف ایم زیڈ ٹریڈنگ ٹرمینل کا نیا ورژن (ٹی آر بی آربیٹریج سورس کوڈ کے ساتھ) کا تعارف
- FMZ کے نئے ورژن کے ٹرانزیکشن ٹرمینل کے بارے میں سب کچھ جاننے کے لئے یہاں کلک کریں
- ایف ایم زیڈ کوانٹ: کریپٹوکرنسی مارکیٹ میں مشترکہ تقاضوں کے ڈیزائن مثالوں کا تجزیہ (II)
- 80 لائنوں کے کوڈ میں ہائی فریکوئینسی حکمت عملی کے ساتھ دماغ کے بغیر سیلز بوٹس کا استحصال کیسے کریں
- ایف ایم زیڈ کیوٹیفیکیشن: کریپٹوکرنسی مارکیٹ میں عام ضروریات کے ڈیزائن کی مثالوں کا تجزیہ (ب)
- 80 لائنوں کے کوڈ کے ساتھ ہائی فریکوئینسی کی حکمت عملی کے ساتھ فروخت کے لیے بے دماغ روبوٹ کا استحصال کیسے کیا گیا؟
- ایف ایم زیڈ کوانٹ: کریپٹوکرنسی مارکیٹ میں مشترکہ تقاضوں کے ڈیزائن مثالوں کا تجزیہ (I)
- ایف ایم زیڈ کیوٹیفیکیشن: کریپٹوکرنسی مارکیٹ میں عام ضروریات کے ڈیزائن کی مثالوں کا تجزیہ (1)