Ba hình ảnh để hiểu về máy học: các khái niệm cơ bản, năm trường phái chính và chín thuật toán phổ biến
 0
2506
0
2506
Ba hình ảnh để hiểu về máy học: các khái niệm cơ bản, năm trường phái chính và chín thuật toán phổ biến
- #### Một cái nhìn tổng quan về học máy

Học máy là gì?
Máy học bằng cách phân tích một lượng lớn dữ liệu. Ví dụ, không cần phải được lập trình để nhận ra mèo hoặc khuôn mặt con người, chúng có thể được đào tạo bằng cách sử dụng hình ảnh để tổng hợp và nhận ra mục tiêu cụ thể.
Mối quan hệ giữa học máy và trí tuệ nhân tạo
Học máy (Machine learning) là một môn học về nghiên cứu và thuật toán sử dụng các mô hình tìm kiếm trong dữ liệu và sử dụng các mô hình này để đưa ra dự đoán. Học máy là một phần của lĩnh vực trí tuệ nhân tạo và giao thoa với khám phá tri thức và khai thác dữ liệu.
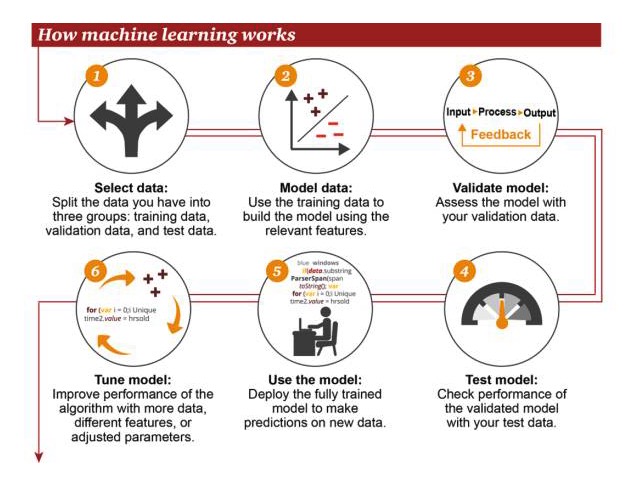
Cách học máy hoạt động
Lựa chọn dữ liệu: chia dữ liệu của bạn thành 3 nhóm: dữ liệu đào tạo, dữ liệu xác thực và dữ liệu thử nghiệm 2 Dữ liệu mô hình: Sử dụng dữ liệu đào tạo để xây dựng mô hình sử dụng các tính năng liên quan 3 Mô hình xác thực: Sử dụng dữ liệu xác thực của bạn để truy cập vào mô hình của bạn 4 Mô hình thử nghiệm: Sử dụng dữ liệu thử nghiệm của bạn để kiểm tra hiệu suất của mô hình đã được xác nhận 5 Sử dụng mô hình: sử dụng mô hình được đào tạo đầy đủ để dự đoán trên dữ liệu mới 6 Mô hình điều chỉnh: sử dụng nhiều dữ liệu, các đặc điểm khác nhau hoặc các tham số được điều chỉnh để nâng cao hiệu suất của thuật toán
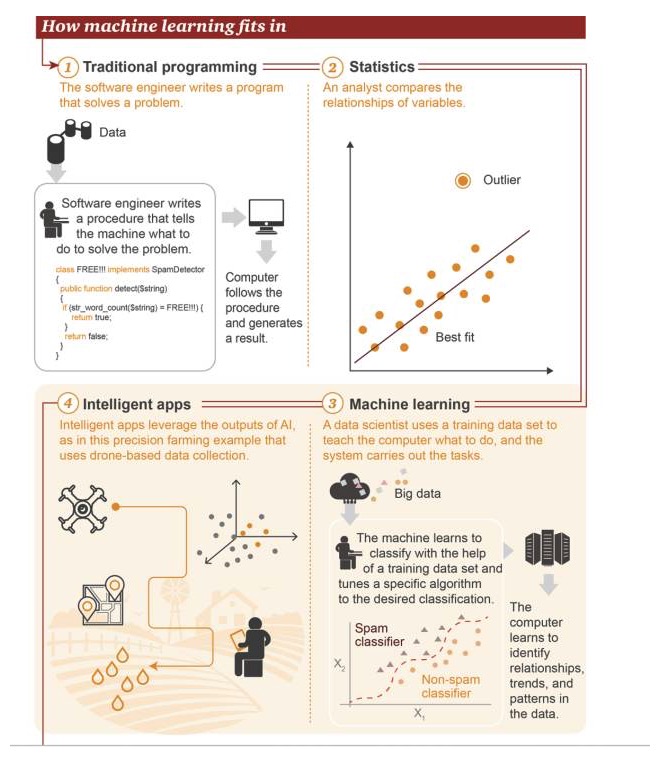
Nơi mà học máy đang ở
1 Lập trình truyền thống: Kỹ sư phần mềm viết chương trình để giải quyết vấn đề. Đầu tiên có một số dữ liệu→ Để giải quyết một vấn đề, kỹ sư phần mềm viết một quy trình để cho máy tính biết phải làm gì→ Máy tính thực hiện theo quy trình này, sau đó đưa ra kết quả 2 Thống kê: Nhà phân tích so sánh mối quan hệ giữa các biến 3 Máy học: Các nhà khoa học dữ liệu sử dụng tập dữ liệu đào tạo để dạy máy tính phải làm gì, sau đó hệ thống thực hiện nhiệm vụ đó. Đầu tiên là dữ liệu lớn→ Máy học sử dụng tập dữ liệu đào tạo để phân loại, điều chỉnh thuật toán cụ thể để thực hiện phân loại mục tiêu→ Máy tính có thể học cách nhận ra mối quan hệ, xu hướng và mô hình trong dữ liệu 4 Ứng dụng thông minh: Ứng dụng thông minh sử dụng kết quả của trí tuệ nhân tạo, hình dưới đây là một ví dụ về ứng dụng nông nghiệp chính xác dựa trên dữ liệu thu thập được từ máy bay không người lái

Ứng dụng thực tế của học máy
Có rất nhiều trường hợp ứng dụng cho học máy, và đây là một vài ví dụ, bạn sẽ sử dụng nó như thế nào?
Hình bản và mô hình 3D nhanh: Để xây dựng một cây cầu đường sắt, các nhà khoa học dữ liệu và chuyên gia lĩnh vực của PwC đã áp dụng học máy vào dữ liệu thu thập được từ máy bay không người lái. Sự kết hợp này cho phép giám sát chính xác và phản hồi nhanh chóng trong thành công công việc.
Tăng cường phân tích để giảm rủi ro: Để phát hiện các giao dịch nội bộ, PwC kết hợp học máy và các kỹ thuật phân tích khác để phát triển hồ sơ người dùng toàn diện hơn và hiểu sâu hơn về các hành vi đáng ngờ phức tạp.
Mục tiêu dự đoán hiệu suất tốt nhất: PwC sử dụng học máy và các phương pháp phân tích khác để đánh giá tiềm năng của các con ngựa khác nhau trên sân Melbourne Cup.
- #### Sự phát triển của học máy

Trong nhiều thập kỷ, các “bộ lạc” của các nhà nghiên cứu trí tuệ nhân tạo đã cạnh tranh với nhau để giành quyền thống trị. Bây giờ có phải là lúc các bộ lạc này hợp nhất? Họ cũng có thể phải làm như vậy, bởi vì hợp tác và hợp nhất thuật toán là cách duy nhất để thực hiện trí tuệ nhân tạo chung thực sự (AGI).
Năm thể loại
Chữ ký: sử dụng ký hiệu, quy tắc và logic để biểu thị kiến thức và suy luận logic, thuật toán yêu thích nhất là: quy tắc và cây quyết định 2 Bayesian: lấy khả năng xảy ra để suy luận xác suất, thuật toán ưa thích là: Bayes ngây thơ hoặc Markov 3 Liên kết học: sử dụng ma trận xác suất và các nơron cân nặng để nhận diện và quy mô mô động, thuật toán ưa thích là: Mạng thần kinh 4 Tiến hóa học: tạo ra sự thay đổi và sau đó lấy tốt nhất cho mục tiêu cụ thể, thuật toán yêu thích là: thuật toán di truyền 5 Analogizer: để tối ưu hóa hàm theo các điều kiện ràng buộc ((đi càng cao càng tốt, nhưng đồng thời không rời khỏi con đường), thuật toán yêu thích là: hỗ trợ máy vector
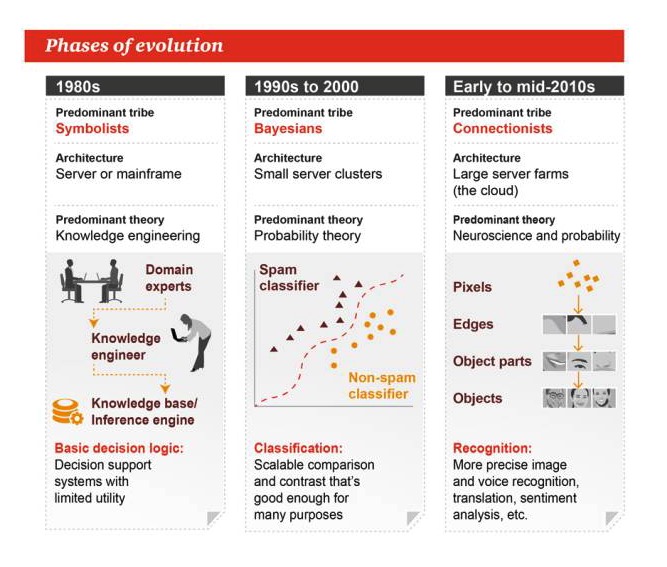
Giai đoạn tiến hóa
Những năm 1980
Phong cách chủ đạo: Symbolism Kiến trúc: máy chủ hoặc máy tính lớn Lý thuyết chủ yếu: Kỹ thuật tri thức Logic quyết định cơ bản: hệ thống hỗ trợ quyết định, hữu ích hạn chế
Những năm 1990 đến 2000
Phong cách: Bayes Kiến trúc: Cụm máy chủ nhỏ Lý thuyết thống trị: Lý thuyết xác suất Phân loại: so sánh hoặc so sánh mở rộng, đủ tốt cho nhiều nhiệm vụ
Đầu đến giữa những năm 2010
Phong cách chính: Liên kết Kiến trúc: trang trại máy chủ lớn Giả thuyết chính: Khoa học thần kinh và xác suất Xác định: nhận dạng hình ảnh và âm thanh chính xác hơn, dịch thuật, phân tích cảm xúc, v.v.
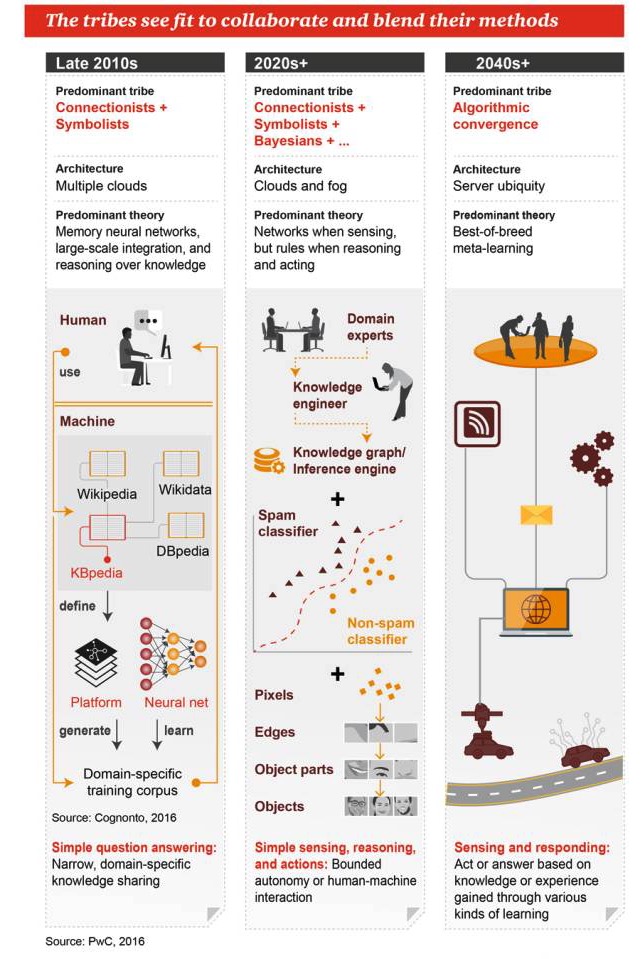
Các thể loại này có thể hợp tác và kết hợp các phương pháp riêng của họ.
Cuối những năm 2010
Phong cách chủ đạo: Chủ nghĩa liên kết + Chủ nghĩa biểu tượng Kiến trúc: Nhiều đám mây Các lý thuyết chủ đạo: Mạng thần kinh trí nhớ, hội nhập quy mô lớn, lý luận dựa trên tri thức Những câu hỏi và câu trả lời đơn giản: chia sẻ kiến thức trong một phạm vi hạn chế và cụ thể
Những năm 2020+
Các thể loại chủ đạo: Liên kết + biểu tượng + Bayes + … Kiến trúc: điện toán đám mây và điện toán sương mù Lý thuyết thống trị: Có mạng lưới khi nhận thức, có quy tắc khi suy luận và làm việc Nhận thức, suy luận và hành động đơn giản: tự động hóa hoặc tương tác người máy có giới hạn
Những năm 2040+
Các thể loại phổ biến: Sự kết hợp của các thuật toán Kiến trúc: máy chủ ở khắp mọi nơi Giả thuyết chủ đạo: sự kết hợp tốt nhất của meta-learning Nhận thức và đáp ứng: hành động hoặc trả lời dựa trên kiến thức hoặc kinh nghiệm thu được thông qua nhiều cách học
- #### 3, Các thuật toán học máy

Bạn nên sử dụng thuật toán học máy nào? Điều này phụ thuộc rất nhiều vào bản chất và số lượng dữ liệu có sẵn và mục tiêu đào tạo của bạn trong từng trường hợp sử dụng cụ thể. Đừng sử dụng các thuật toán phức tạp nhất, trừ khi kết quả của nó xứng đáng với chi phí và tài nguyên đắt tiền.
Cây quyết định: Trong quá trình trả lời từng bước, phân tích cây quyết định điển hình sẽ sử dụng các biến phân tầng hoặc các nút quyết định, ví dụ, phân loại một người dùng nhất định là đáng tin cậy hoặc không đáng tin cậy.
Tính năng: Có khả năng đánh giá một loạt các đặc điểm, phẩm chất và tính chất khác nhau của người, địa điểm và vật Ví dụ về tình huống: đánh giá tín dụng dựa trên quy tắc, dự đoán kết quả đua ngựa
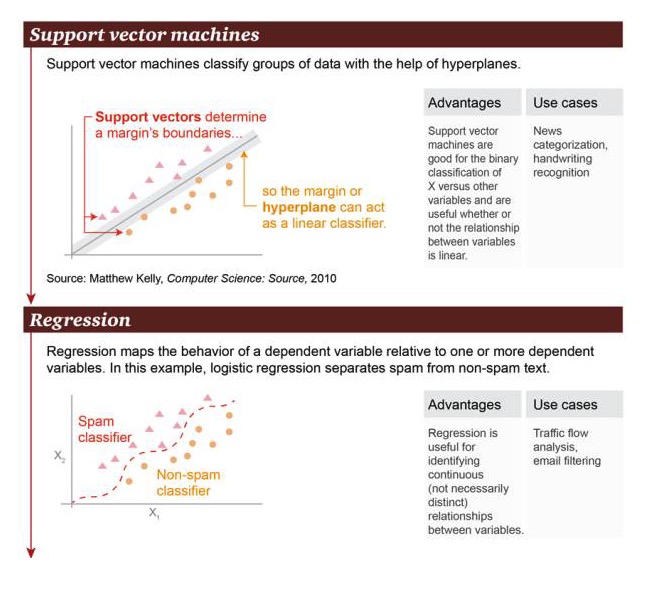
Máy vector hỗ trợ: dựa trên siêu phẳng, máy vector hỗ trợ có thể phân loại các nhóm dữ liệu.
Ưu điểm: Hỗ trợ máy vector giỏi trong việc phân loại nhị phân giữa biến X và các biến khác, bất kể mối quan hệ của chúng có tuyến tính hay không Ví dụ: phân loại tin tức, nhận dạng chữ viết tay.
Regression: Regression có thể phác thảo mối quan hệ trạng thái giữa biến nhân và một hoặc nhiều biến nhân. Trong ví dụ này, phân biệt thư rác và thư không rác.
Ưu điểm: Phục hồi có thể được sử dụng để xác định mối quan hệ liên tục giữa các biến, ngay cả khi mối quan hệ này không rõ ràng Ví dụ: phân tích lưu lượng giao thông đường bộ, lọc thư
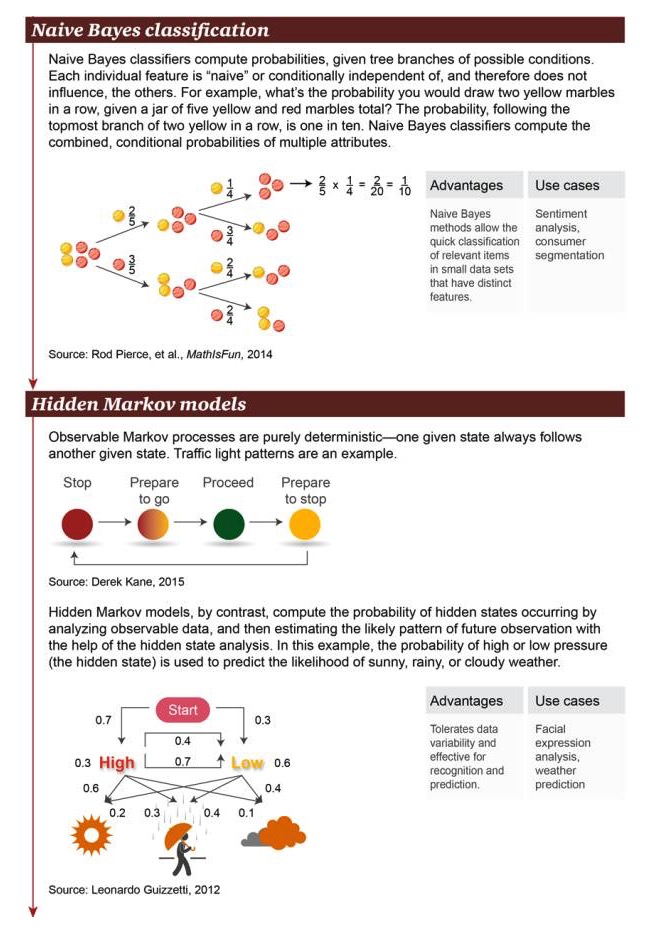
Phân loại Bayes ngây thơ: Phân loại Bayes ngây thơ được sử dụng để tính toán xác suất phân nhánh của các điều kiện có thể. Mỗi đặc điểm độc lập là “ngây thơ” hoặc độc lập với điều kiện, vì vậy chúng không ảnh hưởng đến các đối tượng khác. Ví dụ: trong một hộp có tổng cộng 5 quả bóng nhỏ màu vàng và đỏ, xác suất lấy hai quả bóng nhỏ màu vàng liên tiếp là bao nhiêu?
Ưu điểm: Phương pháp Bayesian đơn giản cho phép phân loại nhanh đối tượng có liên quan có đặc điểm đáng chú ý trên một tập dữ liệu nhỏ Ví dụ: phân tích cảm xúc, phân loại người tiêu dùng
Mô hình Markov ẩn: mô hình Markov ẩn là quá trình hiển thị sự chắc chắn hoàn toàn rằng một trạng thái nhất định thường đi kèm với một trạng thái khác. Đèn giao thông là một ví dụ. Ngược lại, mô hình Markov ẩn tính toán sự xuất hiện của trạng thái ẩn bằng cách phân tích dữ liệu có thể nhìn thấy. Tiếp theo, nhờ phân tích trạng thái ẩn, mô hình Markov ẩn có thể ước tính các mô hình quan sát tương lai có thể. Trong trường hợp này, xác suất áp suất cao hoặc thấp (đây là trạng thái ẩn) có thể được sử dụng để dự đoán xác suất ngày trời rực rỡ, mưa và nhiều mây.
Ưu điểm: cho phép dữ liệu thay đổi, phù hợp cho hoạt động nhận dạng và dự đoán Ví dụ như phân tích biểu cảm khuôn mặt, dự báo thời tiết.
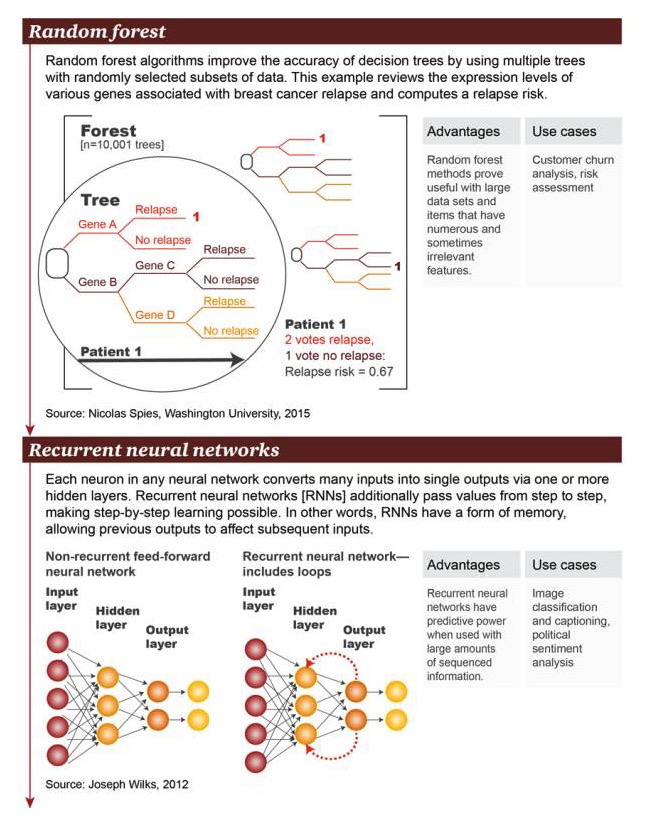
Rừng ngẫu nhiên: thuật toán rừng ngẫu nhiên cải thiện độ chính xác của cây quyết định bằng cách sử dụng nhiều cây với các tập hợp dữ liệu được chọn ngẫu nhiên. Ví dụ này đã xem xét một số lượng lớn các gen liên quan đến tái phát ung thư vú ở cấp độ biểu hiện gen và tính toán nguy cơ tái phát.
Ưu điểm: Phương pháp rừng ngẫu nhiên đã được chứng minh là hữu ích cho các bộ dữ liệu lớn và các mục có rất nhiều và đôi khi không liên quan đến đặc điểm Ví dụ về tình huống: Phân tích lưu lượng người dùng, đánh giá rủi ro
Mạng thần kinh lặp đi lặp lại: Trong mạng thần kinh tùy ý, mỗi tế bào thần kinh chuyển đổi rất nhiều đầu vào thành một đầu ra thông qua 1 hoặc nhiều lớp ẩn. Mạng thần kinh lặp đi lặp lại (RNN) sẽ truyền giá trị thêm từng lớp, cho phép học tập từng lớp trở nên có thể. Nói cách khác, RNN tồn tại một dạng bộ nhớ, cho phép đầu ra trước ảnh hưởng đến đầu ra sau.
Ưu điểm: Mạng thần kinh tuần hoàn có khả năng dự đoán khi có nhiều thông tin có trật tự Ví dụ như phân loại hình ảnh và thêm phụ đề, phân tích cảm xúc chính trị.

Các mạng lưới thần kinh vòng lặp có liên quan đến bộ nhớ ngắn hạn dài (LSTM) và các mạng lưới thần kinh vòng lặp có liên quan đến các mạng lưới thần kinh vòng lặp có liên quan đến các mạng lưới thần kinh vòng lặp có liên quan đến các mạng lưới thần kinh vòng lặp có liên quan đến các mạng lưới thần kinh vòng quanh có liên quan đến các mạng lưới thần kinh vòng quanh có liên quan đến các mạng lưới thần kinh vòng quanh có liên quan đến các mạng lưới thần kinh vòng quanh có liên quan đến các mạng lưới thần kinh vòng quanh có liên quan đến các mạng lưới thần kinh vòng quanh có liên quan đến các mạng lưới thần kinh vòng quanh có liên quan đến các mạng lưới thần kinh vòng quanh có liên quan đến các mạng lưới thần kinh vòng quanh có liên quan đến các mạng lưới thần kinh vòng quanh có liên quan đến các mạng lưới thần kinh vòng quanh có liên quan đến các mạng lưới thần kinh vòng quanh có liên quan đến các mạng lưới thần kinh vòng quanh có liên quan đến các mạng lưới thần kinh vòng quanh có liên quan đến các mạng lưới thần kinh tế có liên quan đến các mạng lưới thần kinh tế có liên quan đến các mạng lưới thần kinh tế có liên quan đến các mạng lưới thần kinh tế
Ưu điểm: Mạng thần kinh chu kỳ có trí nhớ ngắn hạn và chu kỳ điều khiển cửa có các lợi thế tương tự như các mạng thần kinh chu kỳ khác, nhưng chúng được sử dụng thường xuyên hơn vì chúng có khả năng ghi nhớ tốt hơn Ví dụ: xử lý ngôn ngữ tự nhiên, dịch
Mạng thần kinh xoắn (convolutional neural network): Xúc tụ là sự kết hợp của trọng lượng từ các lớp tiếp theo, có thể được sử dụng để đánh dấu các lớp đầu ra.
Ưu điểm: Mạng nơ ron xoắn rất hữu ích khi có các tập dữ liệu rất lớn, nhiều đặc điểm và các nhiệm vụ phân loại phức tạp Ví dụ như nhận dạng hình ảnh, chuyển đổi văn bản, phát hiện thuốc.
- #### Hình ảnh:
http://usblogs.pwc.com/emerging-technology/a-look-at-machine-learning-infographic/
http://usblogs.pwc.com/emerging-technology/machine-learning-methods-infographic/
http://usblogs.pwc.com/emerging-technology/machine-learning-evolution-infographic/
Tóm tắt từ Big Data Land