

引言:Harness Engineer 思想
最近在 AI/ML 工程社区里,有一种思维方式被越来越广泛地讨论——Harness Engineer。
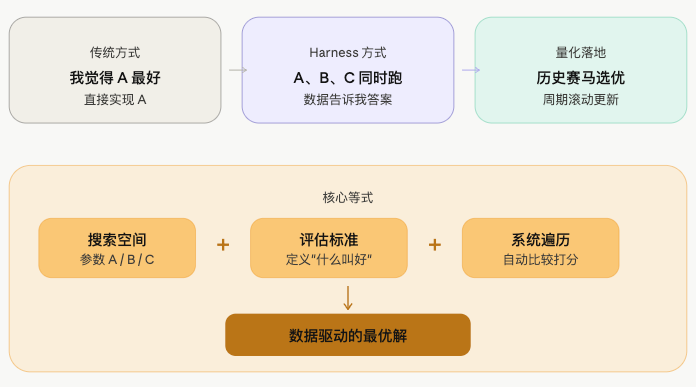
它的核心理念很简单:
与其自己拍脑袋给答案,不如搭一个框架,让数据和实验自己找答案。
传统工程师的方式是:我认为参数 A 好,我来写代码实现 A。Harness Engineer 的方式是:我不知道 A、B、C 哪个好,我来搭一个框架,让 A、B、C 同时跑,数据告诉我答案。
工程师负责定义搜索空间和评估标准,系统负责在空间里自动寻优。这种思想在 ML 里对应的是 walk-forward optimization、AutoML;在量化里,其实也有天然的落地场景。
妖币:趋势最明显的战场
在加密货币合约市场中,有一类币种值得特别关注——交易量极大的"妖币"。
这类币种有几个共同特征:
- 资金高度集中,主力行为明显
- 趋势延续性相对较强,一旦启动往往持续时间较长
- 波动率高,部分高成交量币种在特定时期表现出较强的趋势性,均线策略在这类标的上历史回测表现相对较好
正因如此,在这类币种上使用经典的双均线穿叉策略,是一个朴素而合理的切入点。快线上穿慢线,趋势启动,跟进;快线下穿慢线,趋势反转,离场。逻辑简单,但在趋势明显的标的上,历史表现往往并不差。
问题只有一个:哪些币是妖币?用哪组均线参数?
这两个问题,如果靠人工判断,主观性太强,换一个人可能得出完全不同的答案。而且市场是动态的,今天的妖币不一定是明天的妖币,今天有效的参数组合也可能明天就失效。
这正是 Harness Engineer 思想登场的地方。
与其人工选币、人工调参,不如把这两个问题都交给框架去解决——定义好评估标准,让历史数据在候选空间里自己跑出答案。人只需要决定用什么标准衡量好坏,剩下的交给系统。
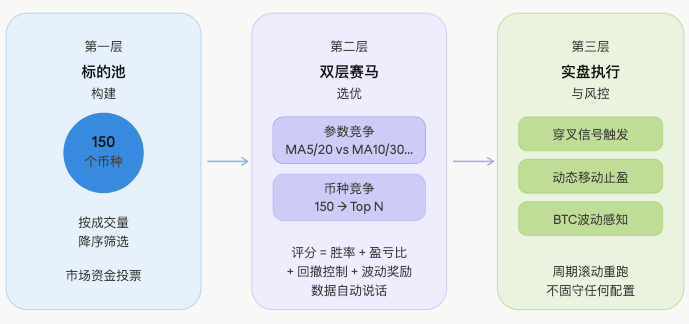
基于这个思路,整个策略被设计成一套滚动筛选框架,分三层运作。
策略架构:两层赛马机制
第一层:标的池构建
从全市场合约品种中,按美元成交量降序取前 150 个币种作为候选池。
为什么是成交量?因为成交量大的地方,资金最集中,趋势最容易形成,妖币也最密集。这一步不做主观判断,纯粹让市场资金投票,谁的交易量大谁进池子。
javascript
const filtered = tickers
.filter(t => t.Symbol.endsWith('USDT.swap'))
.map(t => ({ symbol: t.Symbol, quoteVolume: t.Last * t.Volume }))
.sort((a, b) => b.quoteVolume - a.quoteVolume)
.slice(0, topN)
.map(t => t.symbol);
逻辑非常直接:过滤 USDT 合约品种,计算美元成交量,降序排列,取前 N 个。没有任何主观判断,市场资金自己投票。
第二层:双层赛马选优
这是整个策略最核心的部分,也是 Harness 思想体现最明显的地方。
正确的执行顺序是这样的:
⚠️ 注意:用最优参数的分数代表该币的能力,本身隐含了一定的过拟合风险——在历史上表现最好的参数,不一定在未来同样有效。这个局限性在文章后半部分会进一步讨论。
回测过程
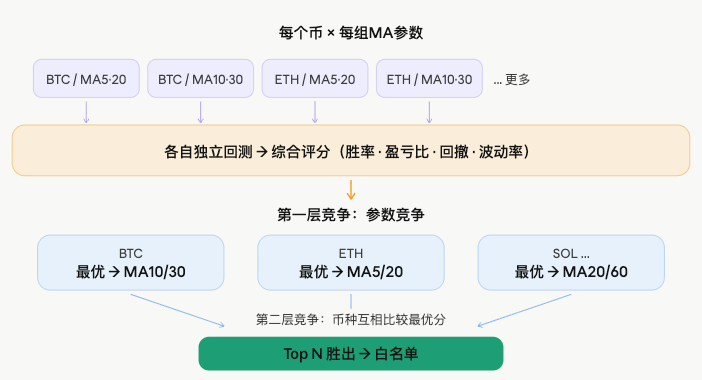
对候选池中每一个币种,同时跑多组 MA 参数组合,每组参数在历史 K 线上独立运行,模拟真实的穿叉开平仓逻辑:
javascript
// 遍历每个币种 × 每组参数组合
for (const params of maParamsList) {
const bt = backtest_MA(records, params.fast, params.slow);
// 每组回测独立得出:胜率、盈亏比、最大回撤、信号次数
}
每次回测的核心逻辑是标准的双均线穿叉:
javascript
const crossUp = fastMA[i-1] <= slowMA[i-1] && fastMA[i] > slowMA[i];
const crossDown = fastMA[i-1] >= slowMA[i-1] && fastMA[i] < slowMA[i];
if (crossUp) position = { side: 'long', entryPrice: records[i].Close };
if (crossDown) position = { side: 'short', entryPrice: records[i].Close };
综合评分
回测完成后,对每组参数的回测结果进行综合评分。评分由两部分构成:
标准化权重评分(合计系数 0.80):
javascript
const score =
Math.min(bt.winRate * 100, 100) * 0.30 // 胜率,上限封顶100
+ Math.min(bt.profitFactor * 20, 60) * 0.30 // 盈亏比,上限封顶60
+ Math.max(0, 1 - bt.maxDrawdown / maxMDD) * 100 * 0.20 // 最大回撤控制
+ volPct * volPctBonus // 波动率分位奖励加分项
波动率分位奖励加分项:最后一项 volPct × volPctBonus(默认系数为 10)是独立于权重体系之外的奖励项,用于在同等评分条件下,倾向选择当前波动率处于历史较高分位的币种——因为这类币种往往趋势更为活跃。
需要说明的是,这套权重和奖励系数均为经验设定,并非通过优化得出,实际使用中可根据市场环境进一步调整。
第一层竞争:参数竞争
同一个币的多组参数各自得出评分,取最高分的那组作为该币的代表分数和最优参数:
javascript
if (score > bestScore) {
bestScore = score;
bestResult = bt;
bestParams = params; // 记录当前历史表现最优的参数组合
}
第二层竞争:币种竞争
所有币种各自拿出自己的最优分,排序后取 Top N 进入白名单:
javascript
results.sort((a, b) => b.score - a.score);
const whitelist = results.slice(0, topCoins).map(r => r.coin);
最终输出的,是每个白名单币种对应的专属最优均线参数,而不是一套参数打天下。
第三层:实盘执行与风控
用筛选出来的配置进行实盘交易,同时叠加多层风控机制:
信号触发:实时检测白名单币种的均线穿叉状态,金叉做多,死叉做空:
javascript
const crossUp = fastPrev <= slowPrev && fastCur > slowCur;
const crossDown = fastPrev >= slowPrev && fastCur < slowCur;
if (crossUp) longList.push(sym);
if (crossDown && allowShort) shortList.push(sym);
移动止盈:浮盈达到触发阈值后启动,且回撤阈值随浮盈动态收紧。三档阈值为经验设定,核心逻辑是浮盈越高、对回撤的容忍越小,锁住已有利润:
javascript
function getDynamicTrailDrawdown(maxPnl) {
if (maxPnl >= 7) return 3; // 浮盈高,回撤容忍收紧
if (maxPnl >= 4) return 2;
return 1.5; // 浮盈低,给行情多一点空间
}
市场状态感知:检测 BTC 波动率分位,高波动环境自动降低仓位系数,极端行情直接禁止做空:
javascript
if (marketState === 'volatile') positionScaleDown = 0.5;
else if (marketState === 'high_vol') positionScaleDown = 0.8;
else if (marketState === 'low_vol') positionScaleDown = 0.7;
整个筛选流程周期性滚动重跑,不固守某一套配置,随市场动态更新白名单和参数。
底层假设:趋势的延续性
这套框架能成立,依赖一个核心假设:
近期历史中表现好的币种和参数,在接下来短期内仍有一定的延续性。
这不是玄学,背后有一定的市场逻辑支撑——资金惯性、市场情绪的延续、主力行为的连贯性,都会让趋势在一定时间窗口内保持有效。
但需要诚实地说:这个假设没有经过严格的统计验证,它更多是一种经验性判断。框架能否在实盘中持续有效,最终还是要靠真实交易数据来检验。
和真正的 Harness Engineer 有什么区别
必须说清楚这一点。
这个策略有 Harness 的形,但和真正的 Harness Engineer 体系相比,仍有明显差距:
| 维度 | 真正的 Harness | 这个策略 |
|---|---|---|
| 样本分割 | 训练集 + 验证集 + holdout 测试集 | 全量历史数据回测,无样本外验证 |
| 过拟合防护 | 有明确的泛化性检验 | 依赖参数多样性部分对冲,不完整 |
| 实验隔离 | 每个变体独立运行互不影响 | 共享同一份 K 线,有隐性耦合 |
| 上线门槛 | 需通过 validation 才能部署 | 评分最高直接上线,无二次验证层 |
| 误差叠加 | 各层评估独立 | 两层赛马均基于历史最优,误差叠加 |
核心差距在于:真正的 Harness 会追问"这个结果在样本外还成立吗",而这个策略两层赛马选出来的"最优",本质上都是历史最优——参数层面的过拟合,叠加了币种层面的过拟合,能否延续到未来,是一个永远开放的问题。
结语:刻舟求剑,还是值得一试?
在量化世界里,预测从来就是一件极难的事。
不少人会说,用历史数据选参数再去实盘,本质上是刻舟求剑——剑已经落水了,你在船上刻的那道痕,并不能帮你找到它。市场会变,有效的参数会失效,今天的妖币明天可能归于平淡,昨天的最优均线今天可能就是噪音。
这个批评并非没有道理。
但话说回来,该做的尝试,还是应该去做。
量化的本质,从来不是找到一个永远正确的答案,而是在不确定性中系统性地提高胜率。即便是刻舟求剑,你也得先有一条船、先刻上那道痕——定位了策略(舟),本身就是量化的开始。
当然,框架本身不保证盈利。有了框架只是起点,真正的价值在于持续执行和迭代:白名单可以调,评分权重可以改,参数空间可以扩,止盈止损可以优化。每一次调整,都是一次新的实验,都是在让这套框架更接近真正的 Harness。
路是走出来的,不是想出来的。
- 1