8
Follow
1364
Followers
FMZ平台Python爬虫应用初探--爬取币安公告内容
Created 2021-11-12 17:08:26 Updated 2024-12-04 21:18:45
15
4335

FMZ平台Python爬虫应用初探--爬取币安公告内容
最近看了一下社区、文库里还没有关于Python爬虫的相关资料,基于作为一个QUANT全面发展的精神。非常非常浅显的学习了一下爬虫相关的概念和知识。了解一番之后发现「爬虫技术」这个“坑”还挺大,本篇只是作为初探「爬虫技术」。在FMZ量化交易平台上关于爬虫技术做一个最最简单的实践。
需求
对于喜欢打新的交易者,总是希望在第一时间获取交易所上币信息。人工一直盯着交易所网站显然不现实。那么就需求使用爬虫脚本监控交易所公告页面,检测新的公告以便在第一时间得到通知、提醒。
初探
用一个非常简单的程序来作为入门(真正的强大的爬虫脚本远远复杂的多,先慢慢来)。程序逻辑十分简单,就是让程序不停的访问交易所的公告页面,解析获取的HTML内容,检测特定的标签内容是否更新。
实施代码
可以用一些好用的爬虫框架。不过考虑到需求很简单,直接编写也可以。
需要用到python的库:
requests,可以简单理解为用来访问网页的库。
bs4,可以简单理解为用来解析网页HTML代码的库。
代码:
from bs4 import BeautifulSoup
import requests
urlBinanceAnnouncement = "https://www.binancezh.io/en/support/announcement/c-48?navId=48" # 币安公告页面地址
def openUrl(url):
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.108 Safari/537.36'}
r = requests.get(url, headers=headers) # 使用requests库访问url,即币安的公告网页地址
if r.status_code == 200:
r.encoding = 'utf-8'
# Log("success! {}".format(url))
return r.text # 访问成功的话返回网页内容文本
else:
Log("failed {}".format(url))
def main():
preNews_href = ""
lastNews = ""
Log("watching...", urlBinanceAnnouncement, "#FF0000")
while True:
ret = openUrl(urlBinanceAnnouncement)
if ret:
soup = BeautifulSoup(ret, 'html.parser') # 把网页文本解析为对象
lastNews_href = soup.find('a', class_='css-1ej4hfo')["href"] # 查找特定的标签,获取href
lastNews = soup.find('a', class_='css-1ej4hfo').get_text() # 获取这个标签中的内容
if preNews_href == "":
preNews_href = lastNews_href
if preNews_href != lastNews_href: # 检测到标签发生变动,即有新的公告产生
Log("New Cryptocurrency Listing update!") # 打印提示信息
preNews_href = lastNews_href
LogStatus(_D(), "\n", "preNews_href:", preNews_href, "\n", "news:", lastNews)
Sleep(1000 * 10)
运行
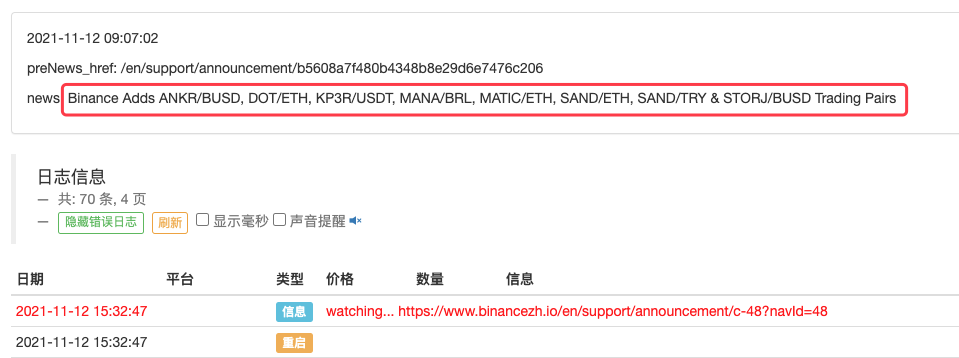
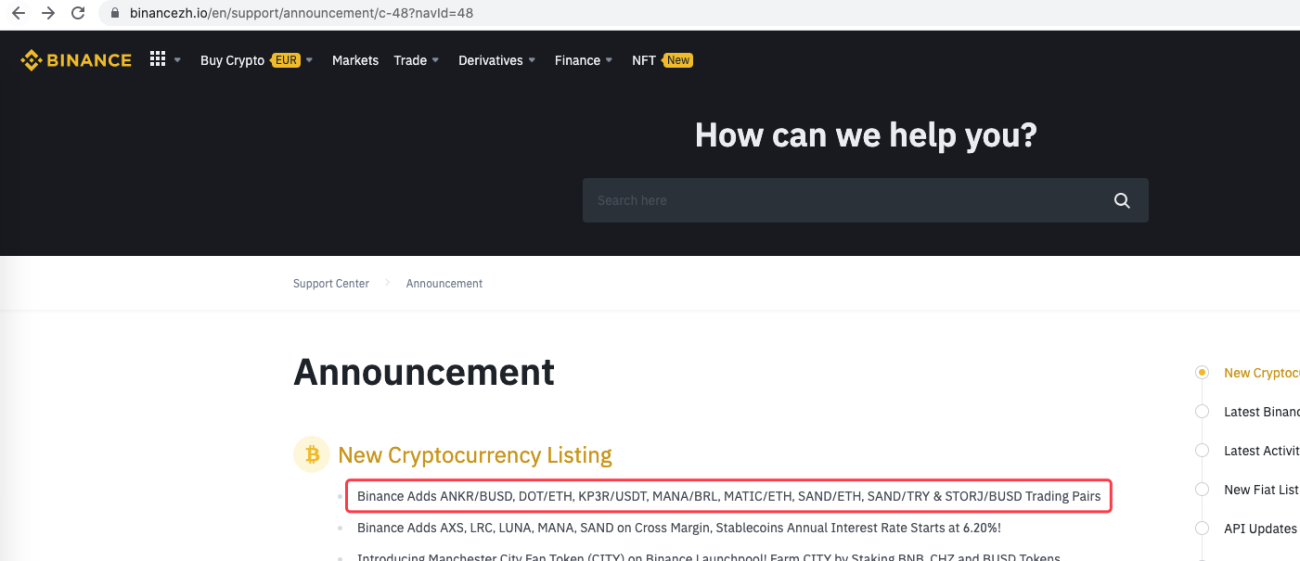
甚至可以再加以扩展,例如检测到有新公告出现。分析公告中上新的币种,自动下单打新交易。
Related Recommendations
Visualization module to build trading strategies - in-depthUse the KLineChart function to make strategy drawing design easierJavaScript strategy backtesting is debugged in DevTools of Chrome browserDetailed Explanation of Equilibrium & Grid StrategiesDesign a Multiple-Chart Plotting LibraryRSI2 Mean Reversion Strategy using in futuresThe futures and cryptocurrency API explanationQuickly implement a semi-automatic quantitative trading toolIntroducing the Aroon indicatorPreliminary Study on Backtesting of Digital Currency Options Strategy
Comment
All comments (15)

Traceback (most recent call last): File "<string>", line 999, in init_ctx File "<string>", line 1, in <module> ModuleNotFoundError: No module named 'bs4'
复制代码到实盘提示错误,是不是缺失python的库。怎么添加库到托管着呢。
4 years ago


作者你好,我也写了一个爬币安公告的爬虫,不管是用那个api接口还是主页的爬虫都有30s延迟,不知道你有没有解决这个问题,可以交流下吗,我的vx ShawnQiang1125
4 years ago


- 1