

পূর্ববর্তী নিবন্ধটি প্রাথমিকভাবে কেন্দ্রীয় মূল্যের জন্য বিভিন্ন গণনা পদ্ধতি প্রবর্তন করেছে এবং কেন্দ্রীয় মূল্যের একটি পুনর্বিবেচনা দিয়েছে এই নিবন্ধটি এই বিষয়ে গভীরভাবে আলোচনা করছে।
প্রয়োজনীয় তথ্য
অর্ডার ফ্লো ডেটা এবং দশ-স্তরের গভীরতার ডেটা বাস্তব অফার থেকে সংগ্রহ করা হয় এবং আপডেট ফ্রিকোয়েন্সি হল 100ms। আসল অফারে শুধুমাত্র ক্রয়, বিক্রয় এবং প্রতিবন্ধী ডেটা অন্তর্ভুক্ত করা হয়, যা সরলতার স্বার্থে আপাতত ব্যবহার করা হয় না। ডেটা খুব বড় তা বিবেচনা করে, গভীরতার ডেটার মাত্র 100,000 সারি রাখা হয়, এবং গিয়ার-বাই-লেভেল বাজারের অবস্থাও আলাদা কলামে বিভক্ত করা হয়।
python
from datetime import date,datetime
import time
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import ast
%matplotlib inline
python
tick_size = 0.0001
python
trades = pd.read_csv('YGGUSDT_aggTrade.csv',names=['type','event_time', 'agg_trade_id','symbol', 'price', 'quantity', 'first_trade_id', 'last_trade_id',
'transact_time', 'is_buyer_maker'])
python
trades = trades.groupby(['transact_time','is_buyer_maker']).agg({
'transact_time':'last',
'agg_trade_id': 'last',
'price': 'first',
'quantity': 'sum',
'first_trade_id': 'first',
'last_trade_id': 'last',
'is_buyer_maker': 'last',
})
python
trades.index = pd.to_datetime(trades['transact_time'], unit='ms')
trades.index.rename('time', inplace=True)
trades['interval'] = trades['transact_time'] - trades['transact_time'].shift()
python
depths = pd.read_csv('YGGUSDT_depth.csv',names=['type','event_time', 'transact_time','symbol', 'u1', 'u2', 'u3', 'bids','asks'])
python
depths = depths.iloc[:100000]
python
depths['bids'] = depths['bids'].apply(ast.literal_eval).copy()
depths['asks'] = depths['asks'].apply(ast.literal_eval).copy()
python
def expand_bid(bid_data):
expanded = {}
for j, (price, quantity) in enumerate(bid_data):
expanded[f'bid_{j}_price'] = float(price)
expanded[f'bid_{j}_quantity'] = float(quantity)
return pd.Series(expanded)
def expand_ask(ask_data):
expanded = {}
for j, (price, quantity) in enumerate(ask_data):
expanded[f'ask_{j}_price'] = float(price)
expanded[f'ask_{j}_quantity'] = float(quantity)
return pd.Series(expanded)
# 应用到每一行,得到新的df
expanded_df_bid = depths['bids'].apply(expand_bid)
expanded_df_ask = depths['asks'].apply(expand_ask)
# 在原有df上进行扩展
depths = pd.concat([depths, expanded_df_bid, expanded_df_ask], axis=1)
python
depths.index = pd.to_datetime(depths['transact_time'], unit='ms')
depths.index.rename('time', inplace=True);
python
trades = trades[trades['transact_time'] < depths['transact_time'].iloc[-1]]
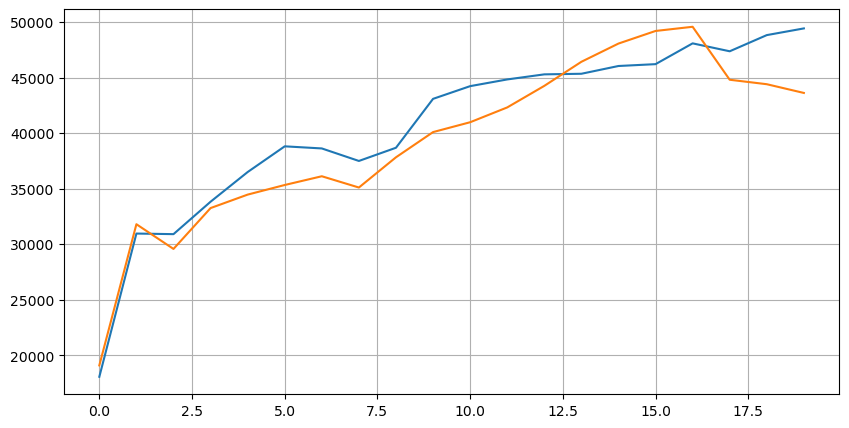
আসুন প্রথমে এই 20টি স্টলের বাজার মূল্যের বণ্টনের দিকে তাকাই, এটি বাজার থেকে যতটা দূরে, তত বেশি মুলতুবি অর্ডারগুলি মোটামুটিভাবে সমান।
python
bid_mean_list = []
ask_mean_list = []
for i in range(20):
bid_mean_list.append(round(depths[f'bid_{i}_quantity'].mean(),0))
ask_mean_list.append(round(depths[f'ask_{i}_quantity'].mean(),0))
plt.figure(figsize=(10, 5))
plt.plot(bid_mean_list);
plt.plot(ask_mean_list);
plt.grid(True)
পূর্বাভাসের নির্ভুলতার মূল্যায়নের সুবিধার্থে গভীরতার ডেটা এবং লেনদেনের ডেটা একত্রিত করুন। এখানে নিশ্চিত করা হয়েছে যে লেনদেনের ডেটা গভীরতার ডেটার চেয়ে পরে এবং পূর্বাভাসিত মান এবং প্রকৃত লেনদেনের মূল্যের মধ্যে গড় বর্গক্ষেত্র ত্রুটি বিলম্ব বিবেচনা না করে সরাসরি গণনা করা হয়। ভবিষ্যদ্বাণীর যথার্থতা পরিমাপ করতে ব্যবহৃত হয়।
ফলাফলগুলি থেকে বিচার করলে, মধ্য_মূল্যের ত্রুটি, ক্রয়-বিক্রয়-একের গড়, ওজন_মধ্য_মূল্যে পরিবর্তন করার পরে, ত্রুটিটি তৎক্ষণাৎ অনেক ছোট হয়ে যায়, এবং ওজনযুক্ত মধ্যম মূল্য সামঞ্জস্য করে এটি কিছুটা উন্নত হয়। গতকালের নিবন্ধটি প্রকাশিত হওয়ার পরে, কেউ রিপোর্ট করেছে যে শুধুমাত্র I^3/2 ব্যবহার করা হয়েছে আমি এটি এখানে পরীক্ষা করে দেখেছি যে ফলাফলটি ভাল। কারণ সম্পর্কে চিন্তা করার পরে, এটি হওয়া উচিত ইভেন্ট ফ্রিকোয়েন্সি -1 এবং 1 এর কাছাকাছি, এটি একটি কম-সম্ভাব্যতা ইভেন্ট যাতে এই কম সম্ভাব্যতাগুলিকে কম সঠিকভাবে ভবিষ্যদ্বাণী করা হয়। অতএব, উচ্চ-ফ্রিকোয়েন্সি ইভেন্টগুলির আরও যত্ন নেওয়ার জন্য, আমি কিছু সমন্বয় করেছি (এগুলি সম্পূর্ণরূপে পরীক্ষার পরামিতি, এবং প্রকৃত রেফারেন্স সামান্য তাৎপর্যপূর্ণ):
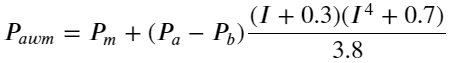
ফলাফল আবার সামান্য ভাল ছিল. আগের প্রবন্ধে যেমন উল্লেখ করা হয়েছে, আরও গভীরতা এবং অর্ডার লেনদেনের ডেটা সহ কৌশলগুলি ভবিষ্যদ্বাণী করা উচিত, ফাঁদে ফেলা এবং প্রতিবন্ধকতা দ্বারা অর্জন করা যেতে পারে এমন উন্নতি ইতিমধ্যেই খুব দুর্বল৷
python
df = pd.merge_asof(trades, depths, on='transact_time', direction='backward')
python
df['spread'] = round(df['ask_0_price'] - df['bid_0_price'],4)
df['mid_price'] = (df['bid_0_price']+ df['ask_0_price']) / 2
df['I'] = (df['bid_0_quantity'] - df['ask_0_quantity']) / (df['bid_0_quantity'] + df['ask_0_quantity'])
df['weight_mid_price'] = df['mid_price'] + df['spread']*df['I']/2
df['adjust_mid_price'] = df['mid_price'] + df['spread']*(df['I'])*(df['I']**8+1)/4
df['adjust_mid_price_2'] = df['mid_price'] + df['spread']*df['I']*(df['I']**2+1)/4
df['adjust_mid_price_3'] = df['mid_price'] + df['spread']*df['I']**3/2
df['adjust_mid_price_4'] = df['mid_price'] + df['spread']*(df['I']+0.3)*(df['I']**4+0.7)/3.8
python
print('平均值 mid_price的误差:', ((df['price']-df['mid_price'])**2).sum())
print('挂单量加权 mid_price的误差:', ((df['price']-df['weight_mid_price'])**2).sum())
print('调整后的 mid_price的误差:', ((df['price']-df['adjust_mid_price'])**2).sum())
print('调整后的 mid_price_2的误差:', ((df['price']-df['adjust_mid_price_2'])**2).sum())
print('调整后的 mid_price_3的误差:', ((df['price']-df['adjust_mid_price_3'])**2).sum())
print('调整后的 mid_price_4的误差:', ((df['price']-df['adjust_mid_price_4'])**2).sum())
平均值 mid_price的误差: 0.0048751924999999845
挂单量加权 mid_price的误差: 0.0048373440193987035
调整后的 mid_price的误差: 0.004803654771638586
调整后的 mid_price_2的误差: 0.004808216498329721
调整后的 mid_price_3的误差: 0.004794984755260528
调整后的 mid_price_4的误差: 0.0047909595497071375
দ্বিতীয় গিয়ার গভীরতা বিবেচনা করুন
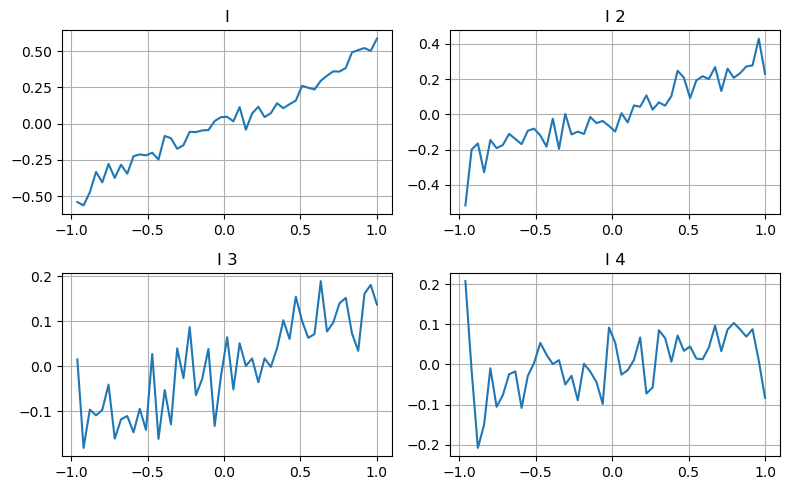
এখানে আমরা একটি নির্দিষ্ট প্রভাবিত পরামিতির বিভিন্ন মান পরিসীমা পরীক্ষা করতে পূর্ববর্তী নিবন্ধের ধারণা ব্যবহার করি এবং লেনদেনের মূল্য পরিবর্তন করে মধ্য-মূল্যে এই পরামিতিটির অবদান পরিমাপ করি। উদাহরণ স্বরূপ, প্রথম গভীরতার চার্টে, আমি যত বাড়ছি, লেনদেনের মূল্য ইতিবাচকভাবে পরিবর্তিত হওয়ার সম্ভাবনা বেশি, যা দেখায় যে আমি একটি ইতিবাচক অবদান রেখেছি।
দ্বিতীয় গিয়ারটি একইভাবে প্রক্রিয়া করা হয়েছিল, এবং এটি পাওয়া গেছে যে প্রভাবটি প্রথম গিয়ারের চেয়ে ছোট হলেও, এটি এখনও উপেক্ষা করা যায় না। তৃতীয় গভীরতাও একটি দুর্বল অবদান রাখে, কিন্তু একঘেয়েতা অনেক খারাপ, এবং গভীর গভীরতার মূলত কোন রেফারেন্স মান নেই।
অবদানের মাত্রার উপর নির্ভর করে, এই তিনটি স্তরের ভারসাম্যহীনতার পরামিতিগুলির জন্য বিভিন্ন ওজন নির্ধারণ করা হয়েছে প্রকৃত পরিদর্শন বিভিন্ন গণনা পদ্ধতির জন্য পূর্বাভাস ত্রুটিকে আরও কমিয়েছে।
python
bins = np.linspace(-1, 1, 50)
df['change'] = (df['price'].pct_change().shift(-1))/tick_size
df['I_bins'] = pd.cut(df['I'], bins, labels=bins[1:])
df['I_2'] = (df['bid_1_quantity'] - df['ask_1_quantity']) / (df['bid_1_quantity'] + df['ask_1_quantity'])
df['I_2_bins'] = pd.cut(df['I_2'], bins, labels=bins[1:])
df['I_3'] = (df['bid_2_quantity'] - df['ask_2_quantity']) / (df['bid_2_quantity'] + df['ask_2_quantity'])
df['I_3_bins'] = pd.cut(df['I_3'], bins, labels=bins[1:])
df['I_4'] = (df['bid_3_quantity'] - df['ask_3_quantity']) / (df['bid_3_quantity'] + df['ask_3_quantity'])
df['I_4_bins'] = pd.cut(df['I_4'], bins, labels=bins[1:])
fig, axes = plt.subplots(nrows=2, ncols=2, figsize=(8, 5))
axes[0][0].plot(df.groupby('I_bins')['change'].mean())
axes[0][0].set_title('I')
axes[0][0].grid(True)
axes[0][1].plot(df.groupby('I_2_bins')['change'].mean())
axes[0][1].set_title('I 2')
axes[0][1].grid(True)
axes[1][0].plot(df.groupby('I_3_bins')['change'].mean())
axes[1][0].set_title('I 3')
axes[1][0].grid(True)
axes[1][1].plot(df.groupby('I_4_bins')['change'].mean())
axes[1][1].set_title('I 4')
axes[1][1].grid(True)
plt.tight_layout();
python
df['adjust_mid_price_4'] = df['mid_price'] + df['spread']*(df['I']+0.3)*(df['I']**4+0.7)/3.8
df['adjust_mid_price_5'] = df['mid_price'] + df['spread']*(0.7*df['I']+0.3*df['I_2'])/2
df['adjust_mid_price_6'] = df['mid_price'] + df['spread']*(0.7*df['I']+0.3*df['I_2'])**3/2
df['adjust_mid_price_7'] = df['mid_price'] + df['spread']*(0.7*df['I']+0.3*df['I_2']+0.3)*((0.7*df['I']+0.3*df['I_2'])**4+0.7)/3.8
df['adjust_mid_price_8'] = df['mid_price'] + df['spread']*(0.7*df['I']+0.2*df['I_2']+0.1*df['I_3']+0.3)*((0.7*df['I']+0.3*df['I_2']+0.1*df['I_3'])**4+0.7)/3.8
python
print('调整后的 mid_price_4的误差:', ((df['price']-df['adjust_mid_price_4'])**2).sum())
print('调整后的 mid_price_5的误差:', ((df['price']-df['adjust_mid_price_5'])**2).sum())
print('调整后的 mid_price_6的误差:', ((df['price']-df['adjust_mid_price_6'])**2).sum())
print('调整后的 mid_price_7的误差:', ((df['price']-df['adjust_mid_price_7'])**2).sum())
print('调整后的 mid_price_8的误差:', ((df['price']-df['adjust_mid_price_8'])**2).sum())
调整后的 mid_price_4的误差: 0.0047909595497071375
调整后的 mid_price_5的误差: 0.0047884350488318714
调整后的 mid_price_6的误差: 0.0047778319053133735
调整后的 mid_price_7的误差: 0.004773578540592192
调整后的 mid_price_8的误差: 0.004771415189297518
লেনদেনের ডেটা বিবেচনা করুন
লেনদেন ডেটা সরাসরি দীর্ঘ এবং ছোট ডিগ্রী প্রতিফলিত করে, এটি প্রকৃত অর্থের অংশগ্রহণের পছন্দ, এবং অর্ডার দেওয়ার খরচ অনেক কম, এমনকি প্রতারণার জন্য ইচ্ছাকৃতভাবে অর্ডার দেওয়ার ঘটনাও রয়েছে। অতএব, মধ্যম মূল্যের পূর্বাভাস দেওয়ার সময়, কৌশলটি লেনদেনের ডেটাতে ফোকাস করা উচিত।
ফর্মটি বিবেচনা করে, যথাক্রমে ক্রয় অর্ডার এবং বিক্রয় অর্ডারের ইউনিট ইভেন্টের মধ্যে গড় পরিমাণের প্রতিনিধিত্ব করতে গড় অর্ডার আগমনের পরিমাণ ভারসাম্যহীনতা VI, Vb এবং Vs নির্ধারণ করুন।
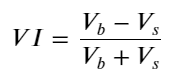
ফলাফলগুলি দেখায় যে অল্প সময়ের মধ্যে আগমনের পরিমাণ মূল্য পরিবর্তনের পূর্বাভাস দেওয়ার ক্ষেত্রে সবচেয়ে তাৎপর্যপূর্ণ হয় যখন VI (0.1-0.9) এর মধ্যে হয়, এটি মূল্যের সাথে নেতিবাচকভাবে সম্পর্কিত, যদিও এটি সীমার বাইরে, এটি দ্রুত ইতিবাচকভাবে সম্পর্কিত। দাম এটি পরামর্শ দেয় যে যখন বাজার চরম না হয়, তখন বাজার প্রধানত ওঠানামা করবে এবং যখন বাজার চরম হবে, যদি প্রচুর সংখ্যক ক্রয় আদেশ বিক্রয়ের আদেশগুলিকে ছাপিয়ে যায়, একটি প্রবণতা দেখা দেবে। এমনকি যদি এই কম-সম্ভাব্যতার পরিস্থিতিগুলিকে বিবেচনায় না নেওয়া হয়, কেবলমাত্র ধরে নেওয়া হয় যে প্রবণতা এবং VI একটি নেতিবাচক রৈখিক সম্পর্ককে সন্তুষ্ট করে, মধ্যম মূল্যের পূর্বাভাস ত্রুটি উল্লেখযোগ্যভাবে কমে যায়। সূত্রে a সহগকে উপস্থাপন করে।
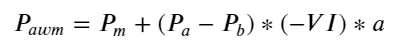
python
alpha=0.1
python
df['avg_buy_interval'] = None
df['avg_sell_interval'] = None
df.loc[df['is_buyer_maker'] == True, 'avg_buy_interval'] = df[df['is_buyer_maker'] == True]['transact_time'].diff().ewm(alpha=alpha).mean()
df.loc[df['is_buyer_maker'] == False, 'avg_sell_interval'] = df[df['is_buyer_maker'] == False]['transact_time'].diff().ewm(alpha=alpha).mean()
python
df['avg_buy_quantity'] = None
df['avg_sell_quantity'] = None
df.loc[df['is_buyer_maker'] == True, 'avg_buy_quantity'] = df[df['is_buyer_maker'] == True]['quantity'].ewm(alpha=alpha).mean()
df.loc[df['is_buyer_maker'] == False, 'avg_sell_quantity'] = df[df['is_buyer_maker'] == False]['quantity'].ewm(alpha=alpha).mean()
python
df['avg_buy_quantity'] = df['avg_buy_quantity'].fillna(method='ffill')
df['avg_sell_quantity'] = df['avg_sell_quantity'].fillna(method='ffill')
df['avg_buy_interval'] = df['avg_buy_interval'].fillna(method='ffill')
df['avg_sell_interval'] = df['avg_sell_interval'].fillna(method='ffill')
df['avg_buy_rate'] = 1000 / df['avg_buy_interval']
df['avg_sell_rate'] =1000 / df['avg_sell_interval']
df['avg_buy_volume'] = df['avg_buy_rate']*df['avg_buy_quantity']
df['avg_sell_volume'] = df['avg_sell_rate']*df['avg_sell_quantity']
python
df['I'] = (df['bid_0_quantity']- df['ask_0_quantity']) / (df['bid_0_quantity'] + df['ask_0_quantity'])
df['OI'] = (df['avg_buy_rate']-df['avg_sell_rate']) / (df['avg_buy_rate'] + df['avg_sell_rate'])
df['QI'] = (df['avg_buy_quantity']-df['avg_sell_quantity']) / (df['avg_buy_quantity'] + df['avg_sell_quantity'])
df['VI'] = (df['avg_buy_volume']-df['avg_sell_volume']) / (df['avg_buy_volume'] + df['avg_sell_volume'])
python
bins = np.linspace(-1, 1, 50)
df['VI_bins'] = pd.cut(df['VI'], bins, labels=bins[1:])
plt.plot(df.groupby('VI_bins')['change'].mean());
plt.grid(True)
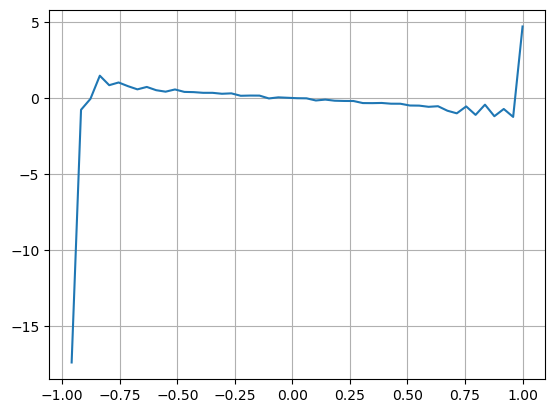
python
df['adjust_mid_price'] = df['mid_price'] + df['spread']*df['I']/2
df['adjust_mid_price_9'] = df['mid_price'] + df['spread']*(-df['OI'])*2
df['adjust_mid_price_10'] = df['mid_price'] + df['spread']*(-df['VI'])*1.4
python
print('调整后的mid_price 的误差:', ((df['price']-df['adjust_mid_price'])**2).sum())
print('调整后的mid_price_9 的误差:', ((df['price']-df['adjust_mid_price_9'])**2).sum())
print('调整后的mid_price_10的误差:', ((df['price']-df['adjust_mid_price_10'])**2).sum())
调整后的mid_price 的误差: 0.0048373440193987035
调整后的mid_price_9 的误差: 0.004629586542840461
调整后的mid_price_10的误差: 0.004401790287167206
বিস্তৃত গড় মূল্য
মুলতুবি থাকা অর্ডার ভলিউম এবং লেনদেন ডেটা উভয়ই মধ্যম মূল্যের পূর্বাভাস দিতে সহায়ক, এই দুটি পরামিতি একসাথে একত্রিত করা যেতে পারে এবং এখানে সীমানা শর্তাবলী বিবেচনা করে না এটি একটি কেনা এবং একটি বিক্রির মধ্যে নয়, তবে যতক্ষণ না ত্রুটিটি হ্রাস করা যায়, আমি এই বিবরণগুলি সম্পর্কে চিন্তা করি না৷
প্রাথমিক 0.00487 থেকে 0.0043-এ নেমে এসেছে আমরা এখনও মাঝামাঝি দামের বিষয়ে অনেক কিছু জানার চেষ্টা করব .
python
#注意VI需要延后一个使用
df['price_change'] = np.log(df['price']/df['price'].rolling(40).mean())
df['CI'] = -1.5*df['VI'].shift()+0.7*(0.7*df['I']+0.2*df['I_2']+0.1*df['I_3'])**3 + 150*df['price_change'].shift(1)
python
df['adjust_mid_price_11'] = df['mid_price'] + df['spread']*(df['CI'])
print('调整后的mid_price_11的误差:', ((df['price']-df['adjust_mid_price_11'])**2).sum())
调整后的mid_price_11的误差: 0.00421125960463469
সারসংক্ষেপ
এই নিবন্ধটি মধ্যম মূল্যের গণনা পদ্ধতিকে আরও উন্নত করতে গভীরতার ডেটা এবং লেনদেন ডেটাকে একত্রিত করে এই নিবন্ধটি সঠিকতা পরিমাপ করার একটি পদ্ধতি প্রদান করে এবং মূল্য পরিবর্তনের পূর্বাভাসগুলির সঠিকতা উন্নত করে৷ সামগ্রিকভাবে, বিভিন্ন পরামিতি কঠোর নয় এবং শুধুমাত্র রেফারেন্সের জন্য। আরও সঠিক মধ্যম মূল্যের সাথে, পরবর্তী পদক্ষেপটি হল ব্যাকটেস্টিংয়ের জন্য মধ্যম মূল্য প্রয়োগ করা, এই অংশে প্রচুর সামগ্রী রয়েছে, তাই আমরা আপডেট করার জন্য কিছুক্ষণ বিরতি দেব।


