উচ্চ ফ্রিকোয়েন্সি ট্রেডিং কৌশল সম্পর্কে চিন্তাভাবনা (5)
লেখক:লিডিয়া, সৃষ্টিঃ ২০২৩-০৮-১০ 15:57:27, আপডেটঃ ২০২৩-০৯-১২ 15:51:54
উচ্চ ফ্রিকোয়েন্সি ট্রেডিং কৌশল সম্পর্কে চিন্তাভাবনা (5)
পূর্ববর্তী নিবন্ধে, মধ্যম মূল্য গণনার জন্য বিভিন্ন পদ্ধতি চালু করা হয়েছিল, এবং একটি সংশোধিত মধ্যম মূল্য প্রস্তাব করা হয়েছিল। এই নিবন্ধে, আমরা এই বিষয়ে গভীরভাবে গভীর হবে।
প্রয়োজনীয় তথ্য
আমরা অর্ডার বইয়ের শীর্ষ দশ স্তরের জন্য অর্ডার প্রবাহ ডেটা এবং গভীরতার ডেটা প্রয়োজন, লাইভ ট্রেডিং থেকে 100ms এর আপডেট ফ্রিকোয়েন্সির সাথে সংগ্রহ করা। সরলতার স্বার্থে, আমরা বিড এবং জিজ্ঞাসা মূল্যের জন্য রিয়েল-টাইম আপডেটগুলি অন্তর্ভুক্ত করব না। ডেটা আকার হ্রাস করার জন্য, আমরা মাত্র 100,000 সারি গভীরতার ডেটা রেখেছি এবং টিক-বাই-টিক বাজার ডেটা পৃথক কলামে পৃথক করেছি।
[1]:
from datetime import date,datetime
import time
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import ast
%matplotlib inline
[2] এঃ
tick_size = 0.0001
[3] এঃ
trades = pd.read_csv('YGGUSDT_aggTrade.csv',names=['type','event_time', 'agg_trade_id','symbol', 'price', 'quantity', 'first_trade_id', 'last_trade_id',
'transact_time', 'is_buyer_maker'])
[4] এঃ
trades = trades.groupby(['transact_time','is_buyer_maker']).agg({
'transact_time':'last',
'agg_trade_id': 'last',
'price': 'first',
'quantity': 'sum',
'first_trade_id': 'first',
'last_trade_id': 'last',
'is_buyer_maker': 'last',
})
[5] এঃ
trades.index = pd.to_datetime(trades['transact_time'], unit='ms')
trades.index.rename('time', inplace=True)
trades['interval'] = trades['transact_time'] - trades['transact_time'].shift()
[6] এঃ
depths = pd.read_csv('YGGUSDT_depth.csv',names=['type','event_time', 'transact_time','symbol', 'u1', 'u2', 'u3', 'bids','asks'])
[৭] এঃ
depths = depths.iloc[:100000]
[8] এঃ
depths['bids'] = depths['bids'].apply(ast.literal_eval).copy()
depths['asks'] = depths['asks'].apply(ast.literal_eval).copy()
[৯] এঃ
def expand_bid(bid_data):
expanded = {}
for j, (price, quantity) in enumerate(bid_data):
expanded[f'bid_{j}_price'] = float(price)
expanded[f'bid_{j}_quantity'] = float(quantity)
return pd.Series(expanded)
def expand_ask(ask_data):
expanded = {}
for j, (price, quantity) in enumerate(ask_data):
expanded[f'ask_{j}_price'] = float(price)
expanded[f'ask_{j}_quantity'] = float(quantity)
return pd.Series(expanded)
# Apply to each line to get a new df
expanded_df_bid = depths['bids'].apply(expand_bid)
expanded_df_ask = depths['asks'].apply(expand_ask)
# Expansion on the original df
depths = pd.concat([depths, expanded_df_bid, expanded_df_ask], axis=1)
[১০] এঃ
depths.index = pd.to_datetime(depths['transact_time'], unit='ms')
depths.index.rename('time', inplace=True);
[11] এঃ
trades = trades[trades['transact_time'] < depths['transact_time'].iloc[-1]]
এই ২০ টি স্তরে বাজারের বন্টন দেখুন। এটি প্রত্যাশার সাথে সামঞ্জস্যপূর্ণ, বাজারের দাম থেকে যত বেশি অর্ডার স্থাপন করা হয় তত বেশি। উপরন্তু, কিনুন অর্ডার এবং বিক্রয় অর্ডারগুলি প্রায় সমান্তরাল।
[14] এঃ
bid_mean_list = []
ask_mean_list = []
for i in range(20):
bid_mean_list.append(round(depths[f'bid_{i}_quantity'].mean(),0))
ask_mean_list.append(round(depths[f'ask_{i}_quantity'].mean(),0))
plt.figure(figsize=(10, 5))
plt.plot(bid_mean_list);
plt.plot(ask_mean_list);
plt.grid(True)
আউট[14]:
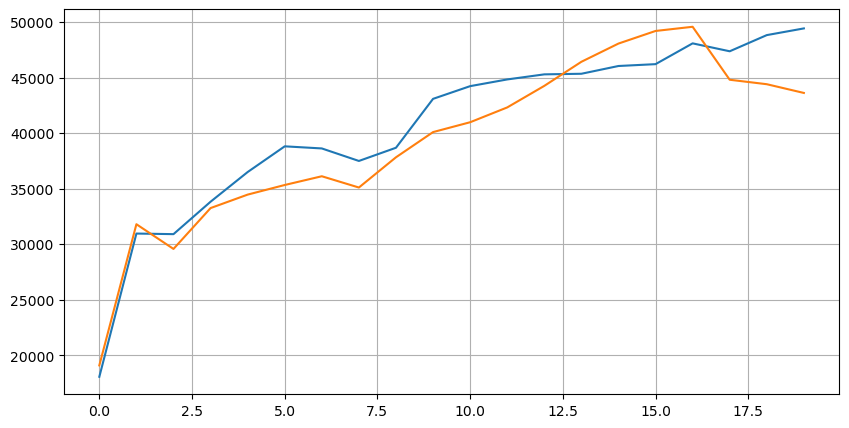
পূর্বাভাসের নির্ভুলতার মূল্যায়ন সহজ করার জন্য গভীরতার ডেটা লেনদেনের ডেটার সাথে একত্রিত করুন। নিশ্চিত করুন যে লেনদেনের ডেটা গভীরতার ডেটার পরে। বিলম্বকে বিবেচনা না করে সরাসরি পূর্বাভাসের মান এবং প্রকৃত লেনদেনের দামের মধ্যে গড় বর্গাকার ত্রুটি গণনা করুন। এটি পূর্বাভাসের নির্ভুলতা পরিমাপ করতে ব্যবহৃত হয়।
ফলাফল থেকে, বিড এবং জিজ্ঞাসা মূল্যের গড় মান (মিড_প্রাইস) এর জন্য ত্রুটি সর্বাধিক। তবে, যখন ওজনযুক্ত মিড_প্রাইসে পরিবর্তন করা হয়, তখন ত্রুটিটি তাত্ক্ষণিকভাবে উল্লেখযোগ্যভাবে হ্রাস পায়। সামঞ্জস্য করা ওজনযুক্ত মিড_প্রাইস ব্যবহার করে আরও উন্নতি পর্যবেক্ষণ করা হয়। কেবলমাত্র আই ^ 3 / 2 ব্যবহারের প্রতিক্রিয়া পাওয়ার পরে, এটি পরীক্ষা করা হয়েছিল এবং ফলাফলগুলি আরও ভাল ছিল বলে মনে করা হয়েছিল। প্রতিফলনের পরে, এটি সম্ভবত ইভেন্টগুলির বিভিন্ন ফ্রিকোয়েন্সির কারণে। যখন আমি -1 এবং 1 এর কাছাকাছি থাকি, এটি কম সম্ভাব্যতার ইভেন্টগুলি উপস্থাপন করে। এই কম সম্ভাব্যতার ইভেন্টগুলির জন্য সংশোধন করার জন্য, উচ্চ-প্রায়োজন ইভেন্টগুলির পূর্বাভাসের নির্ভুলতা হ্রাস পায়। অতএব, উচ্চ-প্রায়োজন ইভেন্টগুলির অগ্রাধিকার দেওয়ার জন্য কিছু সমন্বয় করা হয়েছিল (এই পরামিতিগুলি খাঁটিভাবে ট্রায়াল-এন্ড-ত্রুটি ছিল এবং লাইভ ট্রেডিংয়ে সীমিত ব্যবহারিক গুরুত্ব রয়েছে) ।
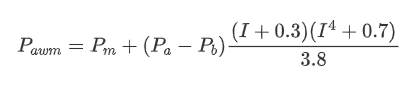
ফলাফল সামান্য উন্নতি হয়েছে। পূর্ববর্তী নিবন্ধে উল্লিখিত হিসাবে, কৌশলগুলি পূর্বাভাসের জন্য আরও ডেটাতে নির্ভর করা উচিত। আরও গভীরতা এবং অর্ডার লেনদেনের ডেটা প্রাপ্যতার সাথে অর্ডার বইয়ের উপর ফোকাস থেকে প্রাপ্ত উন্নতি ইতিমধ্যে দুর্বল।
[15] এঃ
df = pd.merge_asof(trades, depths, on='transact_time', direction='backward')
[17] এঃ
df['spread'] = round(df['ask_0_price'] - df['bid_0_price'],4)
df['mid_price'] = (df['bid_0_price']+ df['ask_0_price']) / 2
df['I'] = (df['bid_0_quantity'] - df['ask_0_quantity']) / (df['bid_0_quantity'] + df['ask_0_quantity'])
df['weight_mid_price'] = df['mid_price'] + df['spread']*df['I']/2
df['adjust_mid_price'] = df['mid_price'] + df['spread']*(df['I'])*(df['I']**8+1)/4
df['adjust_mid_price_2'] = df['mid_price'] + df['spread']*df['I']*(df['I']**2+1)/4
df['adjust_mid_price_3'] = df['mid_price'] + df['spread']*df['I']**3/2
df['adjust_mid_price_4'] = df['mid_price'] + df['spread']*(df['I']+0.3)*(df['I']**4+0.7)/3.8
[18] এঃ
print('Mean value Error in mid_price:', ((df['price']-df['mid_price'])**2).sum())
print('Error of pending order volume weighted mid_price:', ((df['price']-df['weight_mid_price'])**2).sum())
print('The error of the adjusted mid_price:', ((df['price']-df['adjust_mid_price'])**2).sum())
print('The error of the adjusted mid_price_2:', ((df['price']-df['adjust_mid_price_2'])**2).sum())
print('The error of the adjusted mid_price_3:', ((df['price']-df['adjust_mid_price_3'])**2).sum())
print('The error of the adjusted mid_price_4:', ((df['price']-df['adjust_mid_price_4'])**2).sum())
আউট[18]:
গড় মান ত্রুটি mid_price: 0.0048751924999999845 অর্ডার ভলিউম ওয়াইডেড মিড_প্রাইস ত্রুটিঃ 0.0048373440193987035 সংশোধিত মধ্যম_মূল্যের ত্রুটিঃ 0.004803654771638586 সংশোধিত মধ্যম_মূল্য_২ এর ত্রুটিঃ 0.004808216498329721 সংশোধিত মধ্যম_মূল্য_৩ এর ত্রুটিঃ 0.004794984755260528 সংশোধিত মধ্যম_মূল্য_4: 0.0047909595497071375 এর ত্রুটি
গভীরতার দ্বিতীয় স্তর বিবেচনা করুন
আমরা পূর্ববর্তী নিবন্ধ থেকে পদ্ধতি অনুসরণ করতে পারি একটি পরামিতির বিভিন্ন পরিসীমা পরীক্ষা করতে এবং লেনদেনের দামের পরিবর্তনের উপর ভিত্তি করে মধ্যম_দামে এর অবদান পরিমাপ করতে। গভীরতার প্রথম স্তরের অনুরূপ, যেমন I বৃদ্ধি পায়, লেনদেনের দাম বৃদ্ধি পাওয়ার সম্ভাবনা বেশি, যা I থেকে ইতিবাচক অবদান নির্দেশ করে।
দ্বিতীয় গভীরতার স্তরে একই পদ্ধতি প্রয়োগ করে, আমরা দেখতে পাই যে যদিও প্রভাবটি প্রথম স্তরের তুলনায় কিছুটা ছোট, এটি এখনও উল্লেখযোগ্য এবং উপেক্ষা করা উচিত নয়। তৃতীয় গভীরতার স্তরটিও একটি দুর্বল অবদান দেখায়, তবে কম এককতা সহ। গভীরতর গভীরতার সামান্য রেফারেন্স মান রয়েছে।
বিভিন্ন অবদানের উপর ভিত্তি করে, আমরা ভারসাম্যহীনতার পরামিতিগুলির এই তিনটি স্তরের জন্য বিভিন্ন ওজন নির্ধারণ করি। বিভিন্ন গণনার পদ্ধতি পরীক্ষা করে, আমরা ভবিষ্যদ্বাণী ত্রুটির আরও হ্রাস লক্ষ্য করি।
[19] এঃ
bins = np.linspace(-1, 1, 50)
df['change'] = (df['price'].pct_change().shift(-1))/tick_size
df['I_bins'] = pd.cut(df['I'], bins, labels=bins[1:])
df['I_2'] = (df['bid_1_quantity'] - df['ask_1_quantity']) / (df['bid_1_quantity'] + df['ask_1_quantity'])
df['I_2_bins'] = pd.cut(df['I_2'], bins, labels=bins[1:])
df['I_3'] = (df['bid_2_quantity'] - df['ask_2_quantity']) / (df['bid_2_quantity'] + df['ask_2_quantity'])
df['I_3_bins'] = pd.cut(df['I_3'], bins, labels=bins[1:])
df['I_4'] = (df['bid_3_quantity'] - df['ask_3_quantity']) / (df['bid_3_quantity'] + df['ask_3_quantity'])
df['I_4_bins'] = pd.cut(df['I_4'], bins, labels=bins[1:])
fig, axes = plt.subplots(nrows=2, ncols=2, figsize=(8, 5))
axes[0][0].plot(df.groupby('I_bins')['change'].mean())
axes[0][0].set_title('I')
axes[0][0].grid(True)
axes[0][1].plot(df.groupby('I_2_bins')['change'].mean())
axes[0][1].set_title('I 2')
axes[0][1].grid(True)
axes[1][0].plot(df.groupby('I_3_bins')['change'].mean())
axes[1][0].set_title('I 3')
axes[1][0].grid(True)
axes[1][1].plot(df.groupby('I_4_bins')['change'].mean())
axes[1][1].set_title('I 4')
axes[1][1].grid(True)
plt.tight_layout();
আউট[19]:
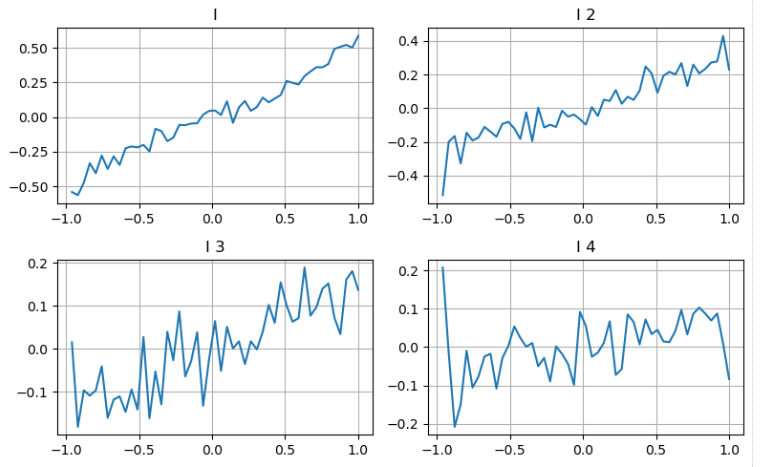
[২০] এঃ
df['adjust_mid_price_4'] = df['mid_price'] + df['spread']*(df['I']+0.3)*(df['I']**4+0.7)/3.8
df['adjust_mid_price_5'] = df['mid_price'] + df['spread']*(0.7*df['I']+0.3*df['I_2'])/2
df['adjust_mid_price_6'] = df['mid_price'] + df['spread']*(0.7*df['I']+0.3*df['I_2'])**3/2
df['adjust_mid_price_7'] = df['mid_price'] + df['spread']*(0.7*df['I']+0.3*df['I_2']+0.3)*((0.7*df['I']+0.3*df['I_2'])**4+0.7)/3.8
df['adjust_mid_price_8'] = df['mid_price'] + df['spread']*(0.7*df['I']+0.2*df['I_2']+0.1*df['I_3']+0.3)*((0.7*df['I']+0.3*df['I_2']+0.1*df['I_3'])**4+0.7)/3.8
[২১] এঃ
print('The error of the adjusted mid_price_4:', ((df['price']-df['adjust_mid_price_4'])**2).sum())
print('The error of the adjusted mid_price_5:', ((df['price']-df['adjust_mid_price_5'])**2).sum())
print('The error of the adjusted mid_price_6:', ((df['price']-df['adjust_mid_price_6'])**2).sum())
print('The error of the adjusted mid_price_7:', ((df['price']-df['adjust_mid_price_7'])**2).sum())
print('The error of the adjusted mid_price_8:', ((df['price']-df['adjust_mid_price_8'])**2).sum())
আউট[21]:
সংশোধিত মধ্যম_মূল্য_4: 0.0047909595497071375 এর ত্রুটি সংশোধিত মধ্যম_মূল্য_৫ এর ত্রুটিঃ ০.০০৪৭৮৮৮৪৩৫০৪৮৮৩১৮৭১৪ সংশোধিত মধ্যম_মূল্য_৬ এর ত্রুটিঃ 0.0047778319053133735 সংশোধিত মিড_প্রাইস_৭ এর ত্রুটিঃ ০.০০৪৭৭৩৫৭৮৫৪০৫৯২১৯২ সংশোধিত মধ্যম_মূল্য_৮ এর ত্রুটিঃ 0.004771415189297518
লেনদেনের তথ্য বিবেচনা করা
লেনদেনের তথ্য সরাসরি লং এবং শর্ট পজিশনের পরিধি প্রতিফলিত করে। সব পরে, লেনদেনের সাথে বাস্তব অর্থ জড়িত, যখন অর্ডার স্থাপন অনেক কম খরচ এবং এমনকি ইচ্ছাকৃত প্রতারণা জড়িত হতে পারে। অতএব, যখন mid_price পূর্বাভাস, কৌশল লেনদেনের তথ্য উপর ফোকাস করা উচিত।
ফর্মের দিক থেকে, আমরা অর্ডার আগমনের গড় পরিমাণের ভারসাম্যহীনতাকে VI হিসাবে সংজ্ঞায়িত করতে পারি, যেখানে Vb এবং Vs যথাক্রমে একক সময় ব্যবধানের মধ্যে ক্রয় এবং বিক্রয় আদেশের গড় পরিমাণকে উপস্থাপন করে।
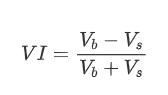
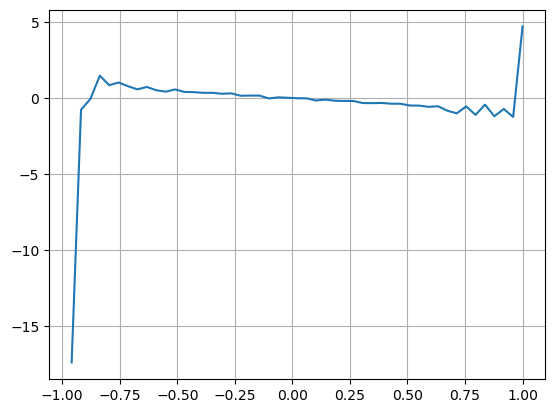
ফলাফলগুলি দেখায় যে স্বল্প সময়ের মধ্যে আগমনের পরিমাণের দাম পরিবর্তনের পূর্বাভাসের উপর সবচেয়ে উল্লেখযোগ্য প্রভাব রয়েছে। যখন VI 0.1 এবং 0.9 এর মধ্যে থাকে, তখন এটি দামের সাথে নেতিবাচকভাবে সম্পর্কিত হয়, যখন এই ব্যাপ্তির বাইরে, এটি দামের সাথে ইতিবাচকভাবে সম্পর্কিত হয়। এটি পরামর্শ দেয় যে যখন বাজারটি চরম নয় এবং মূলত দোলায়, তখন দামটি গড়ের দিকে ফিরে আসে। তবে, চরম বাজারের পরিস্থিতিতে, যেমন যখন প্রচুর সংখ্যক কেনার অর্ডারগুলি বিক্রয় অর্ডারগুলিকে অপ্রতিরোধ্য করে তোলে, তখন একটি প্রবণতা উদ্ভূত হয়। এমনকি এই নিম্ন সম্ভাব্যতার দৃশ্যকল্পগুলি বিবেচনা না করেও, প্রবণতা এবং VI এর মধ্যে একটি নেতিবাচক রৈখিক সম্পর্ক অনুমান করে মধ্যম_মূল্যের পূর্বাভাসের ত্রুটি উল্লেখযোগ্যভাবে হ্রাস পায়। সহগ
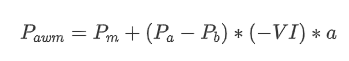
[22]-এঃ
alpha=0.1
[২৩] এঃ
df['avg_buy_interval'] = None
df['avg_sell_interval'] = None
df.loc[df['is_buyer_maker'] == True, 'avg_buy_interval'] = df[df['is_buyer_maker'] == True]['transact_time'].diff().ewm(alpha=alpha).mean()
df.loc[df['is_buyer_maker'] == False, 'avg_sell_interval'] = df[df['is_buyer_maker'] == False]['transact_time'].diff().ewm(alpha=alpha).mean()
[২৪] এঃ
df['avg_buy_quantity'] = None
df['avg_sell_quantity'] = None
df.loc[df['is_buyer_maker'] == True, 'avg_buy_quantity'] = df[df['is_buyer_maker'] == True]['quantity'].ewm(alpha=alpha).mean()
df.loc[df['is_buyer_maker'] == False, 'avg_sell_quantity'] = df[df['is_buyer_maker'] == False]['quantity'].ewm(alpha=alpha).mean()
[২৫] এঃ
df['avg_buy_quantity'] = df['avg_buy_quantity'].fillna(method='ffill')
df['avg_sell_quantity'] = df['avg_sell_quantity'].fillna(method='ffill')
df['avg_buy_interval'] = df['avg_buy_interval'].fillna(method='ffill')
df['avg_sell_interval'] = df['avg_sell_interval'].fillna(method='ffill')
df['avg_buy_rate'] = 1000 / df['avg_buy_interval']
df['avg_sell_rate'] =1000 / df['avg_sell_interval']
df['avg_buy_volume'] = df['avg_buy_rate']*df['avg_buy_quantity']
df['avg_sell_volume'] = df['avg_sell_rate']*df['avg_sell_quantity']
[২৬] এঃ
df['I'] = (df['bid_0_quantity']- df['ask_0_quantity']) / (df['bid_0_quantity'] + df['ask_0_quantity'])
df['OI'] = (df['avg_buy_rate']-df['avg_sell_rate']) / (df['avg_buy_rate'] + df['avg_sell_rate'])
df['QI'] = (df['avg_buy_quantity']-df['avg_sell_quantity']) / (df['avg_buy_quantity'] + df['avg_sell_quantity'])
df['VI'] = (df['avg_buy_volume']-df['avg_sell_volume']) / (df['avg_buy_volume'] + df['avg_sell_volume'])
[২৭] এঃ
bins = np.linspace(-1, 1, 50)
df['VI_bins'] = pd.cut(df['VI'], bins, labels=bins[1:])
plt.plot(df.groupby('VI_bins')['change'].mean());
plt.grid(True)
আউট[২৭]:
[২৮] এঃ
df['adjust_mid_price'] = df['mid_price'] + df['spread']*df['I']/2
df['adjust_mid_price_9'] = df['mid_price'] + df['spread']*(-df['OI'])*2
df['adjust_mid_price_10'] = df['mid_price'] + df['spread']*(-df['VI'])*1.4
[২৯] এঃ
print('The error of the adjusted mid_price:', ((df['price']-df['adjust_mid_price'])**2).sum())
print('The error of the adjusted mid_price_9:', ((df['price']-df['adjust_mid_price_9'])**2).sum())
print('The error of the adjusted mid_price_10:', ((df['price']-df['adjust_mid_price_10'])**2).sum())
আউট[29]:
সংশোধিত মধ্যম_মূল্যের ত্রুটিঃ 0.0048373440193987035 সংশোধিত মধ্যম_মূল্য_৯ এর ত্রুটিঃ 0.004629586542840461 সংশোধিত মধ্যম_মূল্য_১০ এর ত্রুটিঃ ০.০০৪৪০১৭৯০২৮৭১৬৭২০৬
বিস্তৃত মধ্যম মূল্য
অর্ডার বুকের ভারসাম্যহীনতা এবং লেনদেনের ডেটা উভয়ই মধ্যম_মূল্য পূর্বাভাসের জন্য সহায়ক বলে বিবেচনা করে, আমরা এই দুটি পরামিতি একসাথে একত্রিত করতে পারি। এই ক্ষেত্রে ওজনের বরাদ্দটি অনিচ্ছাকৃত এবং সীমান্তের শর্তগুলি বিবেচনা করে না। চরম ক্ষেত্রে, পূর্বাভাসিত মধ্যম_মূল্য বিড এবং জিজ্ঞাসা মূল্যের মধ্যে পড়তে পারে না। তবে, যতক্ষণ পূর্বাভাসের ত্রুটি হ্রাস করা যায়, এই বিবরণগুলি খুব বেশি উদ্বেগের বিষয় নয়।
শেষ পর্যন্ত, পূর্বাভাসের ত্রুটি 0.00487 থেকে 0.0043 এ হ্রাস পেয়েছে। এই মুহুর্তে, আমরা বিষয়টিতে আরও গভীরভাবে প্রবেশ করব না। মাঝারি_মূল্য পূর্বাভাসের ক্ষেত্রে এখনও অনেকগুলি দিক অনুসন্ধান করতে হবে, কারণ এটি মূলত মূল্য নিজেই পূর্বাভাস দিচ্ছে। প্রত্যেককে তাদের নিজস্ব পদ্ধতি এবং কৌশলগুলি চেষ্টা করার জন্য উত্সাহিত করা হয়।
[৩০] এঃ
#Note that the VI needs to be delayed by one to use
df['CI'] = -1.5*df['VI'].shift()+0.7*(0.7*df['I']+0.2*df['I_2']+0.1*df['I_3'])**3
[31]:
df['adjust_mid_price_11'] = df['mid_price'] + df['spread']*(df['CI'])
print('The error of the adjusted mid_price_11:', ((df['price']-df['adjust_mid_price_11'])**2).sum())
আউট[31]:
সংশোধিত মধ্যম_মূল্য_১১ এর ত্রুটিঃ ০.০০৪৩০০১৯৪১৪১২৫৬৩৫৭৫
সংক্ষিপ্তসার
এই নিবন্ধটি গভীরতার ডেটা এবং লেনদেনের ডেটা একত্রিত করে মধ্যম মূল্যের গণনার পদ্ধতি আরও উন্নত করতে। এটি নির্ভুলতা পরিমাপ করার একটি পদ্ধতি সরবরাহ করে এবং মূল্য পরিবর্তনের পূর্বাভাসের নির্ভুলতা উন্নত করে। সামগ্রিকভাবে, পরামিতিগুলি কঠোর নয় এবং কেবলমাত্র রেফারেন্সের জন্য। আরও নির্ভুল মধ্যম মূল্যের সাথে, পরবর্তী পদক্ষেপটি ব্যবহারিক অ্যাপ্লিকেশনগুলিতে মধ্যম মূল্য ব্যবহার করে ব্যাকটেস্টিং করা। বিষয়বস্তুর এই অংশটি বিস্তৃত, তাই আপডেটগুলি কিছু সময়ের জন্য বিরতি দেওয়া হবে।
- বিটকয়েনের জন্য ডেল্টা হিজিংয়ের জন্য হাসি কার্ভ ব্যবহার করুন
- উচ্চ ফ্রিকোয়েন্সি ট্রেডিং কৌশল সম্পর্কে চিন্তাভাবনা (4)
- হাই ফ্রিকোয়েন্সি ট্রেডিং কৌশল সম্পর্কে চিন্তাভাবনা (5)
- হাই ফ্রিকোয়েন্সি ট্রেডিং কৌশল চিন্তা ((4)
- উচ্চ ফ্রিকোয়েন্সি ট্রেডিং কৌশল সম্পর্কে চিন্তাভাবনা (3)
- হাই ফ্রিকোয়েন্সি ট্রেডিং কৌশল সম্পর্কে চিন্তাভাবনা (3)
- উচ্চ ফ্রিকোয়েন্সি ট্রেডিং কৌশল সম্পর্কে চিন্তাভাবনা (2)
- হাই ফ্রিকোয়েন্সি ট্রেডিং কৌশল সম্পর্কে চিন্তাভাবনা (২)
- উচ্চ ফ্রিকোয়েন্সি ট্রেডিং কৌশল সম্পর্কে চিন্তাভাবনা (1)
- হাই ফ্রিকোয়েন্সি ট্রেডিং কৌশল সম্পর্কে চিন্তা ((1))
- ফিটু সিকিউরিটিজ কনফিগারেশন বর্ণনা নথি