ডিজিটাল মুদ্রা ফ্যাক্টর মডেল
লেখক:লিডিয়া, সৃষ্টিঃ ২০২২-১০-২৪ 17:37:50, আপডেটঃ ২০২৩-০৯-১৫ ২০ঃ৫৯ঃ৩৮
ফ্যাক্টর মডেল ফ্রেমওয়ার্ক
স্টক মার্কেটের মাল্টি-ফ্যাক্টর মডেল সম্পর্কিত গবেষণা প্রতিবেদনগুলি সমৃদ্ধ তত্ত্ব এবং অনুশীলনের সাথে প্রচুর পরিমাণে রয়েছে। ডিজিটাল মুদ্রা বাজারে মুদ্রার সংখ্যা, মোট বাজার মূল্য, ট্রেডিং ভলিউম, ডেরিভেটিভ মার্কেট ইত্যাদি নির্বিশেষে, ফ্যাক্টর গবেষণা পরিচালনা করা যথেষ্ট। এই কাগজটি মূলত পরিমাণগত কৌশলগুলির শিক্ষানবিশদের জন্য এবং জটিল গাণিতিক নীতি এবং পরিসংখ্যান বিশ্লেষণ জড়িত হবে না। এটি ফ্যাক্টর গবেষণা জন্য একটি সহজ কাঠামো তৈরির জন্য ডেটা উত্স হিসাবে বাইনান্স চিরন্তন ভবিষ্যত বাজার ব্যবহার করবে, যা ফ্যাক্টর সূচকগুলি মূল্যায়নের জন্য সুবিধাজনক।
ফ্যাক্টরটি একটি সূচক হিসাবে বিবেচিত হতে পারে এবং একটি অভিব্যক্তি লিখতে পারে। ফ্যাক্টরটি ক্রমাগত পরিবর্তন হয়, ভবিষ্যতের আয় তথ্য প্রতিফলিত করে। সাধারণভাবে, ফ্যাক্টরটি একটি বিনিয়োগের যুক্তি উপস্থাপন করে।
উদাহরণস্বরূপ, ক্লোজিং প্রাইস ফ্যাক্টরের পিছনে অনুমানটি হ'ল স্টক মূল্য ভবিষ্যতের উপার্জন পূর্বাভাস দিতে পারে এবং স্টক মূল্য যত বেশি হবে, ভবিষ্যতের উপার্জন তত বেশি হবে (বা কম হতে পারে) । প্রকৃতপক্ষে, এই ফ্যাক্টরটির উপর ভিত্তি করে একটি পোর্টফোলিও তৈরি করা নিয়মিত রাউন্ডে উচ্চমূল্যের স্টক কেনার জন্য একটি বিনিয়োগ মডেল / কৌশল। সাধারণভাবে বলতে গেলে, যে কারণগুলি অবিচ্ছিন্নভাবে অতিরিক্ত মুনাফা তৈরি করতে পারে সেগুলি আলফা নামেও পরিচিত। উদাহরণস্বরূপ, বাজার মূল্য ফ্যাক্টর এবং গতি ফ্যাক্টর একাডেমিক ও বিনিয়োগ সম্প্রদায় দ্বারা একবার কার্যকর কারণ হিসাবে যাচাই করা হয়েছে।
শেয়ার বাজার এবং ডিজিটাল মুদ্রা বাজার উভয়ই জটিল সিস্টেম। এমন কোনও কারণ নেই যা ভবিষ্যতের মুনাফা পুরোপুরি পূর্বাভাস দিতে পারে, তবে তাদের এখনও একটি নির্দিষ্ট পূর্বাভাস রয়েছে। কার্যকর আলফা (বিনিয়োগের মোড) ধীরে ধীরে আরও মূলধন ইনপুটের সাথে অবৈধ হয়ে যাবে। তবে, এই প্রক্রিয়াটি বাজারে অন্যান্য মডেল তৈরি করবে, যার ফলে একটি নতুন আলফা জন্মগ্রহণ করবে। এ-শেয়ার বাজারে বাজার মূল্য ফ্যাক্টরটি একটি খুব কার্যকর কৌশল ছিল। কেবলমাত্র সর্বনিম্ন বাজার মূল্য সহ 10 টি স্টক কিনুন এবং প্রতিদিন একবার সেগুলি সামঞ্জস্য করুন। ২০০৭ সাল থেকে, ১০ বছরের ব্যাকটেস্ট মোট বাজারকে ছাড়িয়ে 400 গুণেরও বেশি মুনাফা দেবে। তবে ২০১৭ সালে হোয়াইট হর্স স্টক মার্কেটটি ছোট বাজার মূল্য ফ্যাক্টরের ব্যর্থতা প্রতিফলিত করেছে এবং এর পরিবর্তে মান ফ্যাক্টর জনপ্রিয় হয়ে উঠেছে। অতএব, আমাদের ক্রমাগত ভারসাম্য বজায় রাখতে হবে এবং আলফা ব্যবহার করার চেষ্টা করতে হবে।
যেসব কারণের খোঁজ করা হয় সেগুলি কৌশল নির্ধারণের ভিত্তি। একাধিক সম্পর্কহীন কার্যকর কারণকে একত্রিত করে একটি ভাল কৌশল তৈরি করা যেতে পারে।
import requests
from datetime import date,datetime
import time
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import requests, zipfile, io
%matplotlib inline
তথ্য উৎস
এখন পর্যন্ত, 2022 সালের শুরু থেকে এখন পর্যন্ত বিন্যান্স ইউএসডিটি চিরস্থায়ী ফিউচারগুলির ঘন্টা-কে লাইন ডেটা 150 টি মুদ্রাকে ছাড়িয়েছে। যেমনটি আমরা আগে উল্লেখ করেছি, ফ্যাক্টর মডেলটি একটি মুদ্রা নির্বাচন মডেল, যা একটি নির্দিষ্ট মুদ্রার পরিবর্তে সমস্ত মুদ্রায় দৃষ্টি নিবদ্ধ করে। কে-লাইন ডেটাতে খোলার উচ্চ এবং বন্ধের নিম্ন দাম, ট্রেডিং ভলিউম, লেনদেনের সংখ্যা, গ্রহণকারীর ক্রয়ের পরিমাণ এবং অন্যান্য ডেটা অন্তর্ভুক্ত রয়েছে। এই ডেটা অবশ্যই মার্কিন স্টক সূচক, সুদের হার বৃদ্ধির প্রত্যাশা, মুনাফা, চেইনের ডেটা, সামাজিক মিডিয়া জনপ্রিয়তা ইত্যাদির মতো সমস্ত কারণের উত্স নয়। অস্বাভাবিক ডেটা উত্সগুলি কার্যকর আলফাও খুঁজে পেতে পারে তবে বেসিক দামের পরিমাণও পর্যাপ্ত।
## Current trading pair
Info = requests.get('https://fapi.binance.com/fapi/v1/exchangeInfo')
symbols = [s['symbol'] for s in Info.json()['symbols']]
symbols = list(filter(lambda x: x[-4:] == 'USDT', [s.split('_')[0] for s in symbols]))
print(symbols)
আউট:
['BTCUSDT', 'ETHUSDT', 'BCHUSDT', 'XRPUSDT', 'EOSUSDT', 'LTCUSDT', 'TRXUSDT', 'ETCUSDT', 'LINKUSDT',
'XLMUSDT', 'ADAUSDT', 'XMRUSDT', 'DASHUSDT', 'ZECUSDT', 'XTZUSDT', 'BNBUSDT', 'ATOMUSDT', 'ONTUSDT',
'IOTAUSDT', 'BATUSDT', 'VETUSDT', 'NEOUSDT', 'QTUMUSDT', 'IOSTUSDT', 'THETAUSDT', 'ALGOUSDT', 'ZILUSDT',
'KNCUSDT', 'ZRXUSDT', 'COMPUSDT', 'OMGUSDT', 'DOGEUSDT', 'SXPUSDT', 'KAVAUSDT', 'BANDUSDT', 'RLCUSDT',
'WAVESUSDT', 'MKRUSDT', 'SNXUSDT', 'DOTUSDT', 'DEFIUSDT', 'YFIUSDT', 'BALUSDT', 'CRVUSDT', 'TRBUSDT',
'RUNEUSDT', 'SUSHIUSDT', 'SRMUSDT', 'EGLDUSDT', 'SOLUSDT', 'ICXUSDT', 'STORJUSDT', 'BLZUSDT', 'UNIUSDT',
'AVAXUSDT', 'FTMUSDT', 'HNTUSDT', 'ENJUSDT', 'FLMUSDT', 'TOMOUSDT', 'RENUSDT', 'KSMUSDT', 'NEARUSDT',
'AAVEUSDT', 'FILUSDT', 'RSRUSDT', 'LRCUSDT', 'MATICUSDT', 'OCEANUSDT', 'CVCUSDT', 'BELUSDT', 'CTKUSDT',
'AXSUSDT', 'ALPHAUSDT', 'ZENUSDT', 'SKLUSDT', 'GRTUSDT', '1INCHUSDT', 'CHZUSDT', 'SANDUSDT', 'ANKRUSDT',
'BTSUSDT', 'LITUSDT', 'UNFIUSDT', 'REEFUSDT', 'RVNUSDT', 'SFPUSDT', 'XEMUSDT', 'BTCSTUSDT', 'COTIUSDT',
'CHRUSDT', 'MANAUSDT', 'ALICEUSDT', 'HBARUSDT', 'ONEUSDT', 'LINAUSDT', 'STMXUSDT', 'DENTUSDT', 'CELRUSDT',
'HOTUSDT', 'MTLUSDT', 'OGNUSDT', 'NKNUSDT', 'SCUSDT', 'DGBUSDT', '1000SHIBUSDT', 'ICPUSDT', 'BAKEUSDT',
'GTCUSDT', 'BTCDOMUSDT', 'TLMUSDT', 'IOTXUSDT', 'AUDIOUSDT', 'RAYUSDT', 'C98USDT', 'MASKUSDT', 'ATAUSDT',
'DYDXUSDT', '1000XECUSDT', 'GALAUSDT', 'CELOUSDT', 'ARUSDT', 'KLAYUSDT', 'ARPAUSDT', 'CTSIUSDT', 'LPTUSDT',
'ENSUSDT', 'PEOPLEUSDT', 'ANTUSDT', 'ROSEUSDT', 'DUSKUSDT', 'FLOWUSDT', 'IMXUSDT', 'API3USDT', 'GMTUSDT',
'APEUSDT', 'BNXUSDT', 'WOOUSDT', 'FTTUSDT', 'JASMYUSDT', 'DARUSDT', 'GALUSDT', 'OPUSDT', 'BTCUSDT',
'ETHUSDT', 'INJUSDT', 'STGUSDT', 'FOOTBALLUSDT', 'SPELLUSDT', '1000LUNCUSDT', 'LUNA2USDT', 'LDOUSDT',
'CVXUSDT']
print(len(symbols))
আউট:
153
#Function to obtain any period of K-line
def GetKlines(symbol='BTCUSDT',start='2020-8-10',end='2021-8-10',period='1h',base='fapi',v = 'v1'):
Klines = []
start_time = int(time.mktime(datetime.strptime(start, "%Y-%m-%d").timetuple()))*1000 + 8*60*60*1000
end_time = min(int(time.mktime(datetime.strptime(end, "%Y-%m-%d").timetuple()))*1000 + 8*60*60*1000,time.time()*1000)
intervel_map = {'m':60*1000,'h':60*60*1000,'d':24*60*60*1000}
while start_time < end_time:
mid_time = start_time+1000*int(period[:-1])*intervel_map[period[-1]]
url = 'https://'+base+'.binance.com/'+base+'/'+v+'/klines?symbol=%s&interval=%s&startTime=%s&endTime=%s&limit=1000'%(symbol,period,start_time,mid_time)
res = requests.get(url)
res_list = res.json()
if type(res_list) == list and len(res_list) > 0:
start_time = res_list[-1][0]+int(period[:-1])*intervel_map[period[-1]]
Klines += res_list
if type(res_list) == list and len(res_list) == 0:
start_time = start_time+1000*int(period[:-1])*intervel_map[period[-1]]
if mid_time >= end_time:
break
df = pd.DataFrame(Klines,columns=['time','open','high','low','close','amount','end_time','volume','count','buy_amount','buy_volume','null']).astype('float')
df.index = pd.to_datetime(df.time,unit='ms')
return df
start_date = '2022-1-1'
end_date = '2022-09-14'
period = '1h'
df_dict = {}
for symbol in symbols:
df_s = GetKlines(symbol=symbol,start=start_date,end=end_date,period=period,base='fapi',v='v1')
if not df_s.empty:
df_dict[symbol] = df_s
symbols = list(df_dict.keys())
print(df_s.columns)
আউট:
Index(['time', 'open', 'high', 'low', 'close', 'amount', 'end_time', 'volume',
'count', 'buy_amount', 'buy_volume', 'null'],
dtype='object')
আমাদের আগ্রহের তথ্যগুলিঃ বন্ধের মূল্য, খোলার মূল্য, ট্রেডিংয়ের পরিমাণ, লেনদেনের সংখ্যা এবং গ্রহণকারীর ক্রয়ের অনুপাত প্রথমে কে-লাইন ডেটা থেকে বের করা হয়। এই তথ্যগুলির ভিত্তিতে, প্রয়োজনীয় ফ্যাক্টরগুলি প্রক্রিয়াজাত করা হয়।
df_close = pd.DataFrame(index=pd.date_range(start=start_date, end=end_date, freq=period),columns=df_dict.keys())
df_open = pd.DataFrame(index=pd.date_range(start=start_date, end=end_date, freq=period),columns=df_dict.keys())
df_volume = pd.DataFrame(index=pd.date_range(start=start_date, end=end_date, freq=period),columns=df_dict.keys())
df_buy_ratio = pd.DataFrame(index=pd.date_range(start=start_date, end=end_date, freq=period),columns=df_dict.keys())
df_count = pd.DataFrame(index=pd.date_range(start=start_date, end=end_date, freq=period),columns=df_dict.keys())
for symbol in df_dict.keys():
df_s = df_dict[symbol]
df_close[symbol] = df_s.close
df_open[symbol] = df_s.open
df_volume[symbol] = df_s.volume
df_count[symbol] = df_s['count']
df_buy_ratio[symbol] = df_s.buy_amount/df_s.amount
df_close = df_close.dropna(how='all')
df_open = df_open.dropna(how='all')
df_volume = df_volume.dropna(how='all')
df_count = df_count.dropna(how='all')
df_buy_ratio = df_buy_ratio.dropna(how='all')
বছরের শুরু থেকে সাম্প্রতিক দিনগুলোতে বাজারের সূচকের সামগ্রিক পারফরম্যান্স হতাশাব্যঞ্জক।
df_norm = df_close/df_close.fillna(method='bfill').iloc[0] #normalization
df_norm.mean(axis=1).plot(figsize=(15,6),grid=True);
#Final index profit chart
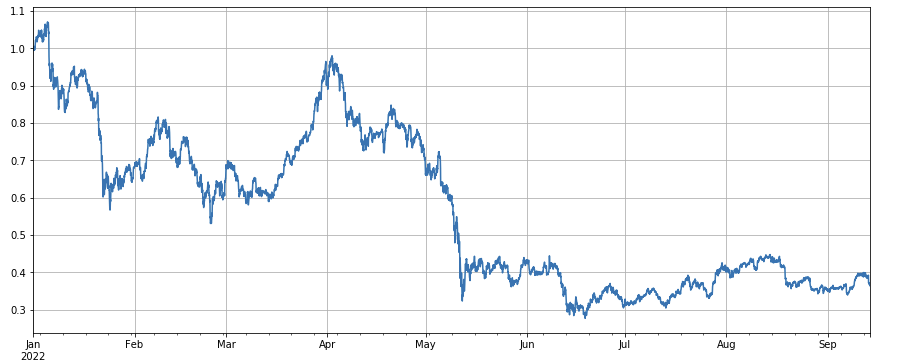
ফ্যাক্টর বৈধতা রায়
-
রিগ্রেশন পদ্ধতি নিম্নলিখিত সময়ের ফলন নির্ভরশীল পরিবর্তনশীল, এবং পরীক্ষার জন্য ফ্যাক্টরটি স্বাধীন পরিবর্তনশীল। রিগ্রেশন দ্বারা প্রাপ্ত সহগটিও ফ্যাক্টরের ফলন। রিগ্রেশন সমীকরণটি নির্মিত হওয়ার পরে, ফ্যাক্টরগুলির বৈধতা এবং অস্থিরতা সাধারণত সহগ t মানের পরম গড় মান, সহগ t মানের পরম মানের অনুক্রমের অনুপাত 2 এর চেয়ে বেশি, বার্ষিক ফ্যাক্টর রিটার্ন, বার্ষিক ফ্যাক্টর লাভের অস্থিরতা এবং ফ্যাক্টর লাভের শার্প অনুপাতের রেফারেন্স দ্বারা দেখা হয়। একাধিক ফ্যাক্টর একসাথে রিগ্রেশন করা যেতে পারে। বিস্তারিত জানার জন্য দয়া করে বার ডকুমেন্টটি দেখুন।
-
আইসি, আইআর এবং অন্যান্য সূচক তথাকথিত আইসি হ'ল ফ্যাক্টর এবং পরবর্তী সময়ের রিটার্ন রেটের মধ্যে সম্পর্ক সহগ। এখন, র্যাঙ্ক_আইসি সাধারণভাবেও ব্যবহৃত হয়, এটি ফ্যাক্টর র্যাঙ্কিং এবং পরবর্তী স্টক রিটার্ন রেটের মধ্যে সম্পর্ক সহগ। আইআর সাধারণত আইসি ক্রমের গড় মান / আইসি ক্রমের স্ট্যান্ডার্ড বিচ্যুতি।
-
স্তরিত রিগ্রেশন পদ্ধতি এই প্রবন্ধে, আমরা এই পদ্ধতিটি ব্যবহার করব, যা পরীক্ষার জন্য ফ্যাক্টর অনুযায়ী মুদ্রাগুলি বাছাই করা, গ্রুপ ব্যাকটেস্টিংয়ের জন্য তাদের এন গ্রুপে বিভক্ত করা এবং অবস্থান সমন্বয় করার জন্য একটি নির্দিষ্ট সময়কাল ব্যবহার করা। যদি পরিস্থিতি আদর্শ হয় তবে গ্রুপ এন মুদ্রার রিটার্ন রেট একটি ভাল এককতা প্রদর্শন করবে, এককভাবে বৃদ্ধি বা হ্রাস পাবে এবং প্রতিটি গ্রুপের আয়ের ফাঁক বড়। এই জাতীয় কারণগুলি ভাল বৈষম্যে প্রতিফলিত হয়। যদি প্রথম গ্রুপের সর্বোচ্চ মুনাফা থাকে এবং শেষ গ্রুপের সর্বনিম্ন মুনাফা থাকে তবে প্রথম গ্রুপে দীর্ঘ যান এবং শেষ গ্রুপে শেষ ফলন পেতে শর্ট যান, যা শার্প অনুপাতের রেফারেন্স সূচক।
প্রকৃত ব্যাকটেস্ট অপারেশন
মুদ্রা নির্বাচন করার জন্য 3 টি গ্রুপে বিভক্ত করা হয় কারণগুলির র্যাঙ্কিংয়ের উপর ভিত্তি করে সবচেয়ে ছোট থেকে বৃহত্তম পর্যন্ত। মুদ্রার প্রতিটি গ্রুপ মোটের প্রায় 1/3 এর জন্য দায়ী। যদি একটি ফ্যাক্টর কার্যকর হয় তবে প্রতিটি গ্রুপে পয়েন্টের সংখ্যা যত কম হবে, রিটার্নের হার তত বেশি হবে, তবে এর অর্থ হ'ল প্রতিটি মুদ্রায় অপেক্ষাকৃত বেশি তহবিল বরাদ্দ করা হবে। যদি লং এবং শর্ট পজিশনগুলি যথাক্রমে ডাবল লিভারেজ হয় এবং প্রথম গ্রুপ এবং শেষ গ্রুপটি যথাক্রমে 10 মুদ্রা হয় তবে একটি মুদ্রা মোটের 10% এর জন্য দায়ী। যদি একটি মুদ্রা শর্ট হয় তবে দ্বিগুণ হয়, তবে 20% প্রত্যাহার করা হয়; যদি গ্রুপের সংখ্যা 50 হয় তবে 4% প্রত্যাহার করা হবে। বৈচিত্র্যময় মুদ্রাগুলি কালো সোয়ানগুলির ঝুঁকি হ্রাস করতে পারে। প্রথম গ্রুপ (সর্বনিম্ন মানের ফ্যাক্টর) দীর্ঘ যান, তৃতীয় গ্রুপে যান। যত বড় ফ্যাক্টর, এবং সংখ্যাটি বেশি হবে, আপনি কেবল ফ্যাক্টরটি বিপরীত
সাধারণভাবে, ফ্যাক্টর পূর্বাভাস ক্ষমতাটি চূড়ান্ত ব্যাকটেস্টের রিটার্ন রেট এবং শার্প অনুপাত অনুযায়ী মোটামুটি মূল্যায়ন করা যেতে পারে। এছাড়াও, এটি ফ্যাক্টর এক্সপ্রেশনটি সহজ, গোষ্ঠীটির আকারের প্রতি সংবেদনশীল, অবস্থান সমন্বয় ব্যবধানের প্রতি সংবেদনশীল এবং ব্যাকটেস্টের প্রাথমিক সময়ের প্রতি সংবেদনশীল কিনা তা উল্লেখ করতে হবে।
পজিশন অ্যাডজাস্টমেন্টের ফ্রিকোয়েন্সি সম্পর্কে, স্টক মার্কেটে সাধারণত 5 দিন, 10 দিন এবং এক মাসের সময় থাকে। তবে, ডিজিটাল মুদ্রা বাজারের জন্য, এই ধরনের সময়কাল নিঃসন্দেহে খুব দীর্ঘ, এবং বাস্তব বটে বাজারটি রিয়েল টাইমে পর্যবেক্ষণ করা হয়। আবার পজিশনগুলি সামঞ্জস্য করার জন্য নির্দিষ্ট সময়ের সাথে লেগে থাকা প্রয়োজন হয় না। অতএব, বাস্তব বটে, আমরা রিয়েল টাইমে বা অল্প সময়ের মধ্যে অবস্থানগুলি সামঞ্জস্য করি।
পজিশন বন্ধ করার পদ্ধতি সম্পর্কে, ঐতিহ্যগত পদ্ধতি অনুসারে, পরবর্তী সময় বাছাই করার সময় পজিশনটি যদি গ্রুপে না থাকে তবে পজিশনটি বন্ধ করা যেতে পারে। তবে, রিয়েল-টাইম পজিশন সমন্বয়ের ক্ষেত্রে, কিছু মুদ্রা কেবল সীমানায় থাকতে পারে, যা পিছনে এবং সামনের পজিশন বন্ধের দিকে পরিচালিত করতে পারে। অতএব, এই কৌশলটি গোষ্ঠী পরিবর্তনগুলির জন্য অপেক্ষা করার পদ্ধতি গ্রহণ করে এবং তারপরে বিপরীত দিকের অবস্থানটি খোলার প্রয়োজন হলে অবস্থানটি বন্ধ করে দেয়। উদাহরণস্বরূপ, প্রথম গ্রুপটি দীর্ঘ হয়। যখন দীর্ঘ পজিশন স্থিতিতে থাকা মুদ্রাগুলি তৃতীয় গ্রুপে বিভক্ত হয়, তখন অবস্থানটি বন্ধ করুন এবং শর্ট যান। যদি অবস্থানটি একটি নির্দিষ্ট সময়ের মধ্যে বন্ধ হয়, যেমন প্রতিদিন বা প্রতি 8 ঘন্টা, আপনি একটি গ্রুপে না থাকার পরেও অবস্থানটি বন্ধ করতে পারেন। যতটা সম্ভব চেষ্টা করুন।
#Backtest engine
class Exchange:
def __init__(self, trade_symbols, fee=0.0004, initial_balance=10000):
self.initial_balance = initial_balance #Initial assets
self.fee = fee
self.trade_symbols = trade_symbols
self.account = {'USDT':{'realised_profit':0, 'unrealised_profit':0, 'total':initial_balance, 'fee':0, 'leverage':0, 'hold':0}}
for symbol in trade_symbols:
self.account[symbol] = {'amount':0, 'hold_price':0, 'value':0, 'price':0, 'realised_profit':0,'unrealised_profit':0,'fee':0}
def Trade(self, symbol, direction, price, amount):
cover_amount = 0 if direction*self.account[symbol]['amount'] >=0 else min(abs(self.account[symbol]['amount']), amount)
open_amount = amount - cover_amount
self.account['USDT']['realised_profit'] -= price*amount*self.fee #Net of fees
self.account['USDT']['fee'] += price*amount*self.fee
self.account[symbol]['fee'] += price*amount*self.fee
if cover_amount > 0: #Close position first
self.account['USDT']['realised_profit'] += -direction*(price - self.account[symbol]['hold_price'])*cover_amount #Profits
self.account[symbol]['realised_profit'] += -direction*(price - self.account[symbol]['hold_price'])*cover_amount
self.account[symbol]['amount'] -= -direction*cover_amount
self.account[symbol]['hold_price'] = 0 if self.account[symbol]['amount'] == 0 else self.account[symbol]['hold_price']
if open_amount > 0:
total_cost = self.account[symbol]['hold_price']*direction*self.account[symbol]['amount'] + price*open_amount
total_amount = direction*self.account[symbol]['amount']+open_amount
self.account[symbol]['hold_price'] = total_cost/total_amount
self.account[symbol]['amount'] += direction*open_amount
def Buy(self, symbol, price, amount):
self.Trade(symbol, 1, price, amount)
def Sell(self, symbol, price, amount):
self.Trade(symbol, -1, price, amount)
def Update(self, close_price): #Update assets
self.account['USDT']['unrealised_profit'] = 0
self.account['USDT']['hold'] = 0
for symbol in self.trade_symbols:
if not np.isnan(close_price[symbol]):
self.account[symbol]['unrealised_profit'] = (close_price[symbol] - self.account[symbol]['hold_price'])*self.account[symbol]['amount']
self.account[symbol]['price'] = close_price[symbol]
self.account[symbol]['value'] = abs(self.account[symbol]['amount'])*close_price[symbol]
self.account['USDT']['hold'] += self.account[symbol]['value']
self.account['USDT']['unrealised_profit'] += self.account[symbol]['unrealised_profit']
self.account['USDT']['total'] = round(self.account['USDT']['realised_profit'] + self.initial_balance + self.account['USDT']['unrealised_profit'],6)
self.account['USDT']['leverage'] = round(self.account['USDT']['hold']/self.account['USDT']['total'],3)
#Function of test factor
def Test(factor, symbols, period=1, N=40, value=300):
e = Exchange(symbols, fee=0.0002, initial_balance=10000)
res_list = []
index_list = []
factor = factor.dropna(how='all')
for idx, row in factor.iterrows():
if idx.hour % period == 0:
buy_symbols = row.sort_values().dropna()[0:N].index
sell_symbols = row.sort_values().dropna()[-N:].index
prices = df_close.loc[idx,]
index_list.append(idx)
for symbol in symbols:
if symbol in buy_symbols and e.account[symbol]['amount'] <= 0:
e.Buy(symbol,prices[symbol],value/prices[symbol]-e.account[symbol]['amount'])
if symbol in sell_symbols and e.account[symbol]['amount'] >= 0:
e.Sell(symbol,prices[symbol], value/prices[symbol]+e.account[symbol]['amount'])
e.Update(prices)
res_list.append([e.account['USDT']['total'],e.account['USDT']['hold']])
return pd.DataFrame(data=res_list, columns=['total','hold'],index = index_list)
সহজ ফ্যাক্টর টেস্ট
ট্রেডিং ভলিউম ফ্যাক্টরঃ কম ট্রেডিং ভলিউম সহ সহজ লং মুদ্রা এবং উচ্চ ট্রেডিং ভলিউম সহ সংক্ষিপ্ত মুদ্রা, যা খুব ভাল পারফর্ম করে, যা জনপ্রিয় মুদ্রাগুলি হ্রাসের প্রবণতা দেখায়।
ট্রেডিং মূল্য ফ্যাক্টরঃ কম দামের মুদ্রা এবং উচ্চ দামের মুদ্রা উভয়ই সাধারণ।
লেনদেনের সংখ্যা ফ্যাক্টরঃ পারফরম্যান্স লেনদেনের পরিমাণের সাথে খুব অনুরূপ। এটি স্পষ্ট যে লেনদেনের পরিমাণ ফ্যাক্টর এবং লেনদেনের সংখ্যা ফ্যাক্টরের মধ্যে সম্পর্ক খুব বেশি। আসলে, বিভিন্ন মুদ্রায় তাদের মধ্যে গড় সম্পর্ক 0.97 এ পৌঁছেছে, যা নির্দেশ করে যে দুটি কারণ খুব অনুরূপ। একাধিক কারণকে সংশ্লেষণ করার সময় এই কারণটি বিবেচনা করা দরকার।
3h গতির ফ্যাক্টরঃ (df_close - df_close. shift (3)) /df_ close. shift ((3)) । অর্থাৎ, ফ্যাক্টরের 3-ঘন্টা বৃদ্ধি। ব্যাকটেস্টের ফলাফলগুলি দেখায় যে 3-ঘন্টা বৃদ্ধিতে সুস্পষ্ট রিগ্রেশন বৈশিষ্ট্য রয়েছে, অর্থাৎ, উত্থানটি পরে পড়া সহজ। সামগ্রিক কর্মক্ষমতা ঠিক আছে, তবে প্রত্যাহার এবং দোলনার দীর্ঘ সময়ও রয়েছে।
24 ঘন্টা গতির ফ্যাক্টরঃ 24 ঘন্টা অবস্থানের সমন্বয় সময়ের ফলাফল ভাল, ফলন 3 ঘন্টা গতির অনুরূপ, এবং প্রত্যাহার ছোট।
লেনদেনের ভলিউমের পরিবর্তন ফ্যাক্টরঃ df_ volume.rolling(24).mean() /df_ volume.rolling (96). mean(), অর্থাৎ, গত দিনের লেনদেনের ভলিউম এবং গত তিন দিনের লেনদেনের ভলিউমের অনুপাত। অবস্থানটি প্রতি 8 ঘন্টা অন্তর সামঞ্জস্য করা হয়। ব্যাকটেস্টিংয়ের ফলাফল ভাল ছিল এবং প্রত্যাহারও তুলনামূলকভাবে কম ছিল, যা নির্দেশ করে যে সক্রিয় লেনদেনের ভলিউমযুক্তরা হ্রাসের প্রবণতা বেশি ছিল।
লেনদেনের সংখ্যার পরিবর্তন ফ্যাক্টরঃ df_ count.rolling ((24).mean() /df_ count.rolling ((96). mean (), অর্থাৎ, গত দিনের লেনদেনের সংখ্যা এবং গত তিন দিনের লেনদেনের সংখ্যার অনুপাত। অবস্থানটি প্রতি 8 ঘন্টা পরপর সামঞ্জস্য করা হয়। ব্যাকটেস্টিংয়ের ফলাফল ভাল ছিল এবং প্রত্যাহারও তুলনামূলকভাবে কম, যা নির্দেশ করে যে সক্রিয় লেনদেনের পরিমাণের সাথে যারা হ্রাস পেতে বেশি প্রবণ ছিল।
একক লেনদেনের মূল্যের পরিবর্তন ফ্যাক্টরঃ - ((df_volume.rolling(24).mean() /df_count.rolling(24.mean()) /(df_volume.rolling(24.mean() /df_count.rolling(96.mean()) , অর্থাৎ, গত দিনের লেনদেনের মূল্যের অনুপাত গত তিন দিনের লেনদেনের মূল্যের তুলনায়, এবং অবস্থানটি প্রতি 8 ঘন্টার মধ্যে সংশোধন করা হবে। এই ফ্যাক্টরটি লেনদেনের ভলিউম ফ্যাক্টরের সাথেও অত্যন্ত সম্পর্কিত।
লেনদেন অনুপাত দ্বারা গ্রহণকারীর পরিবর্তন ফ্যাক্টরঃ df_buy_ratio.rolling(24).mean() /df_buy_ratio.rolling(96).mean(), অর্থাৎ, লেনদেনের ভলিউমের সাথে লেনদেনের পরিমাণের সাথে লেনদেনকারীর পরিমাণের অনুপাত গত তিন দিনের লেনদেনের মানের সাথে, এবং অবস্থানটি প্রতি 8 ঘন্টা অন্তর সামঞ্জস্য করা হবে। এই ফ্যাক্টরটি বেশ ভাল সম্পাদন করে এবং এটি লেনদেনের ভলিউম ফ্যাক্টরের সাথে সামান্য সম্পর্কযুক্ত।
অস্থিরতা ফ্যাক্টরঃ (df_close/df_open).rolling ((24).std ((), কম অস্থিরতার সাথে দীর্ঘ মুদ্রা যান, এটি একটি নির্দিষ্ট প্রভাব আছে।
লেনদেনের পরিমাণ এবং বন্ধের মূল্যের মধ্যে সম্পর্কঃ df_close.rolling ((96).corr ((df_volume), গত চার দিনের বন্ধের মূল্যে লেনদেনের পরিমাণের একটি সম্পর্ক রয়েছে, যা সামগ্রিকভাবে ভাল করেছে।
এখানে তালিকাভুক্ত ফ্যাক্টরগুলি দামের পরিমাণের উপর ভিত্তি করে। প্রকৃতপক্ষে ফ্যাক্টর সূত্রগুলির সংমিশ্রণটি সুস্পষ্ট যুক্তি ছাড়াই খুব জটিল হতে পারে। আপনি বিখ্যাত ALPHA101 ফ্যাক্টর নির্মাণ পদ্ধতিটি উল্লেখ করতে পারেনঃhttps://github.com/STHSF/alpha101.
#transaction volume
factor_volume = df_volume
factor_volume_res = Test(factor_volume, symbols, period=4)
factor_volume_res.total.plot(figsize=(15,6),grid=True);
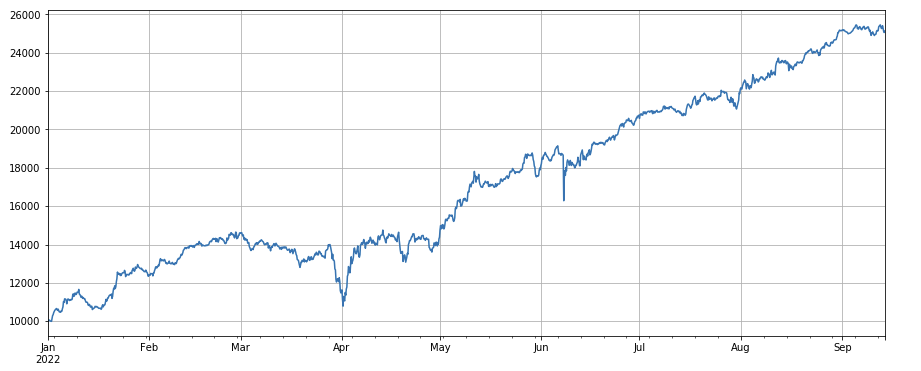
#transaction price
factor_close = df_close
factor_close_res = Test(factor_close, symbols, period=8)
factor_close_res.total.plot(figsize=(15,6),grid=True);
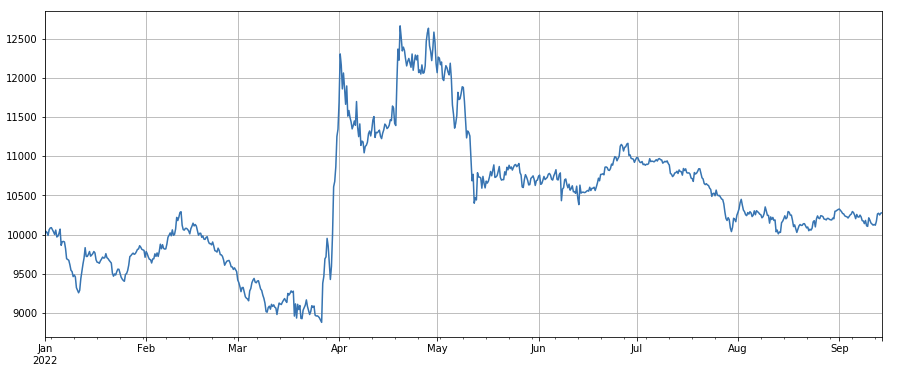
#transaction count
factor_count = df_count
factor_count_res = Test(factor_count, symbols, period=8)
factor_count_res.total.plot(figsize=(15,6),grid=True);
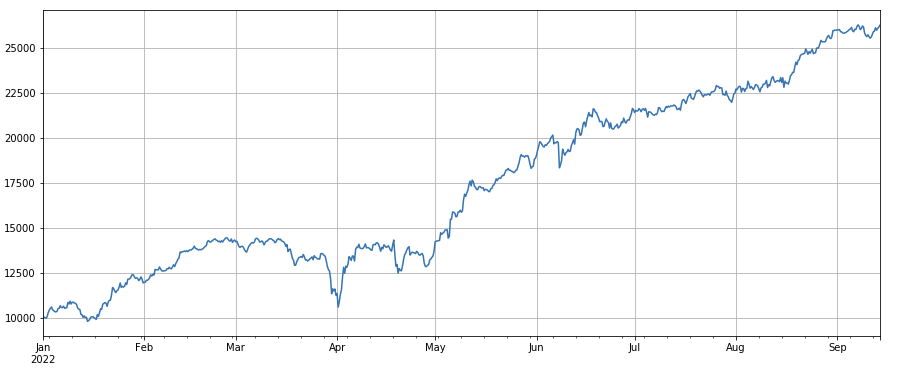
print(df_count.corrwith(df_volume).mean())
0.9671246744996017
#3h momentum factor
factor_1 = (df_close - df_close.shift(3))/df_close.shift(3)
factor_1_res = Test(factor_1,symbols,period=1)
factor_1_res.total.plot(figsize=(15,6),grid=True);
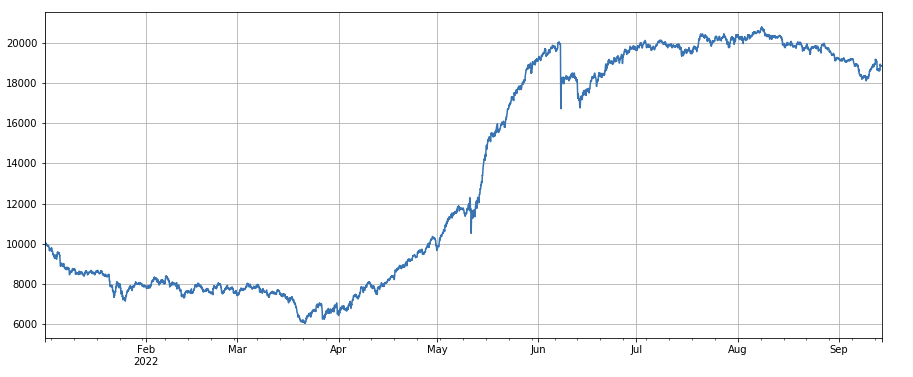
#24h momentum factor
factor_2 = (df_close - df_close.shift(24))/df_close.shift(24)
factor_2_res = Test(factor_2,symbols,period=24)
tamenxuanfactor_2_res.total.plot(figsize=(15,6),grid=True);
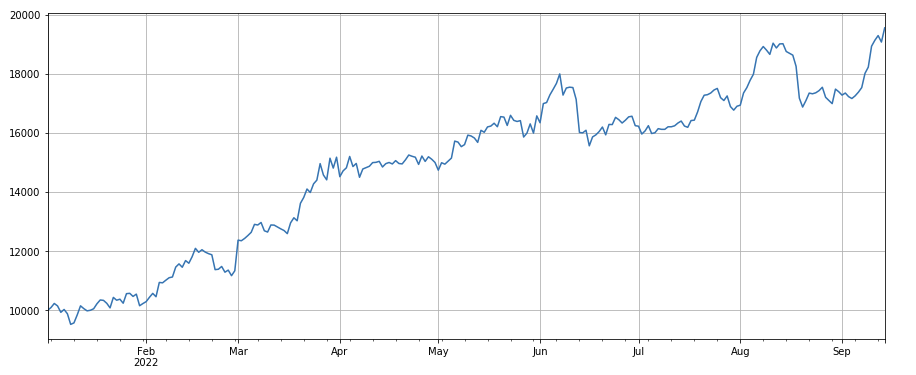
#factor of transaction volume
factor_3 = df_volume.rolling(24).mean()/df_volume.rolling(96).mean()
factor_3_res = Test(factor_3, symbols, period=8)
factor_3_res.total.plot(figsize=(15,6),grid=True);
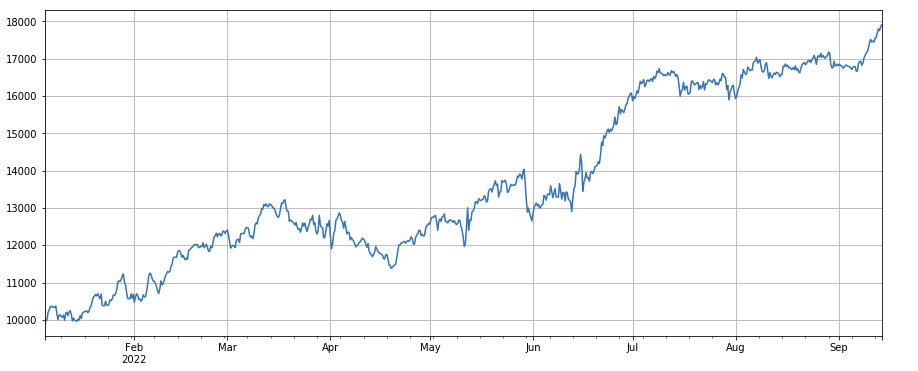
#factor of transaction number
factor_4 = df_count.rolling(24).mean()/df_count.rolling(96).mean()
factor_4_res = Test(factor_4, symbols, period=8)
factor_4_res.total.plot(figsize=(15,6),grid=True);
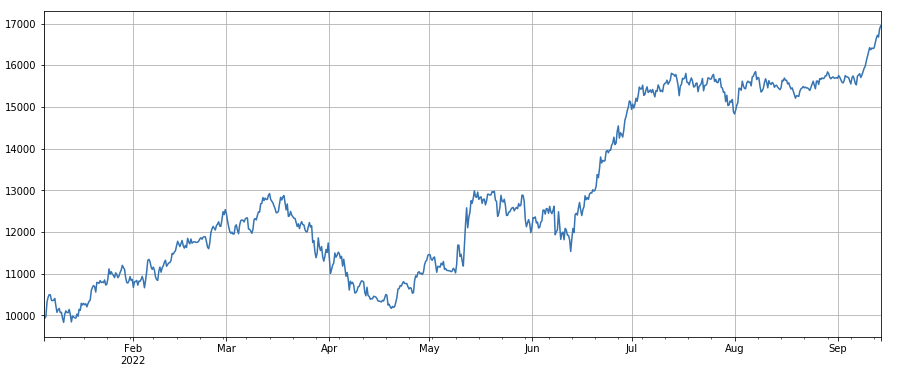
#factor correlation
print(factor_4.corrwith(factor_3).mean())
0.9707239580854841
#single transaction value factor
factor_5 = -(df_volume.rolling(24).mean()/df_count.rolling(24).mean())/(df_volume.rolling(24).mean()/df_count.rolling(96).mean())
factor_5_res = Test(factor_5, symbols, period=8)
factor_5_res.total.plot(figsize=(15,6),grid=True);
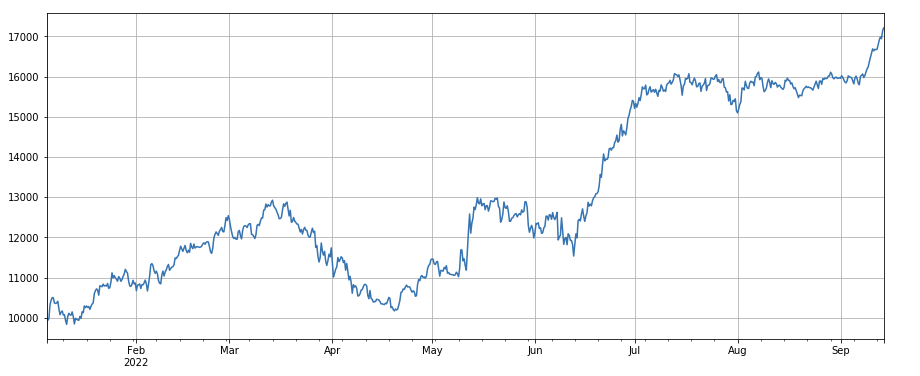
print(factor_4.corrwith(factor_5).mean())
0.861206620552479
#proportion factor of taker by transaction
factor_6 = df_buy_ratio.rolling(24).mean()/df_buy_ratio.rolling(96).mean()
factor_6_res = Test(factor_6, symbols, period=4)
factor_6_res.total.plot(figsize=(15,6),grid=True);
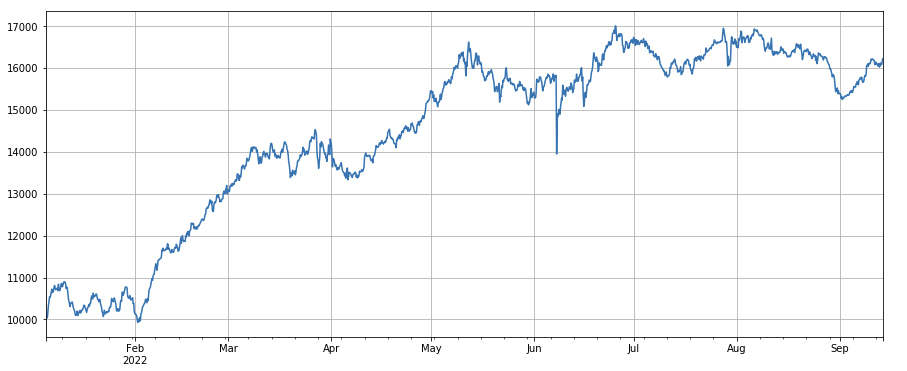
print(factor_3.corrwith(factor_6).mean())
0.1534572192503726
#volatility factor
factor_7 = (df_close/df_open).rolling(24).std()
factor_7_res = Test(factor_7, symbols, period=2)
factor_7_res.total.plot(figsize=(15,6),grid=True);
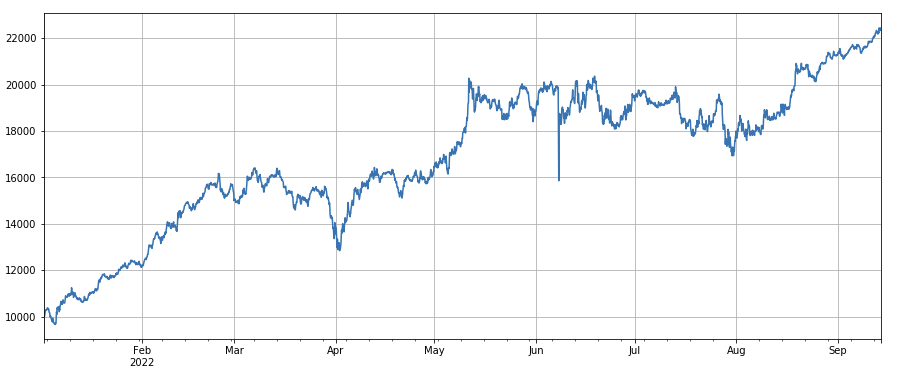
#correlation factor between transaction volume and closing price
factor_8 = df_close.rolling(96).corr(df_volume)
factor_8_res = Test(factor_8, symbols, period=4)
factor_8_res.total.plot(figsize=(15,6),grid=True);
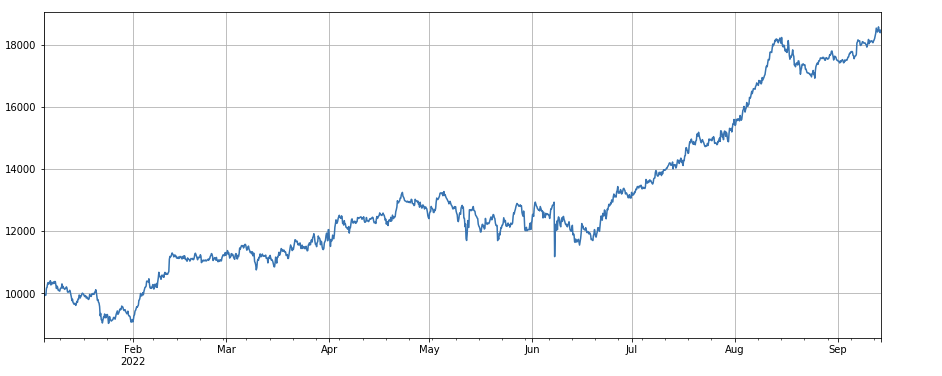
মাল্টিফ্যাক্টর সংশ্লেষণ
নতুন কার্যকর কারণগুলি ক্রমাগত আবিষ্কার করা অবশ্যই কৌশল গঠনের প্রক্রিয়াটির সবচেয়ে গুরুত্বপূর্ণ অংশ, তবে একটি ভাল ফ্যাক্টর সংশ্লেষণ পদ্ধতি ছাড়া একটি দুর্দান্ত একক আলফা ফ্যাক্টর তার সর্বোচ্চ ভূমিকা পালন করতে পারে না। সাধারণ মাল্টি ফ্যাক্টর সংশ্লেষণ পদ্ধতিগুলির মধ্যে রয়েছেঃ
সমান ওজনের পদ্ধতিঃ সংশ্লেষণের পরে নতুন ফ্যাক্টর পাওয়ার জন্য সংশ্লেষণ করা সমস্ত ফ্যাক্টর সমান ওজনের সাথে যোগ করা হয়।
ঐতিহাসিক ফ্যাক্টর রিটার্ন রেটের ওজন পদ্ধতিঃ সংমিশ্রণের পরে একটি নতুন ফ্যাক্টর পাওয়ার জন্য ওজন হিসাবে সর্বশেষ সময়ের ঐতিহাসিক ফ্যাক্টর রিটার্ন রেটের গাণিতিক গড় অনুসারে একত্রিত করা সমস্ত ফ্যাক্টর যোগ করা হয়। এই পদ্ধতিতে ভাল পারফর্মকারী ফ্যাক্টরগুলির উচ্চতর ওজন রয়েছে।
সর্বাধিক আইসি_আইআর ওজন পদ্ধতিঃ ইতিহাসের একটি সময়ের মধ্যে যৌগিক ফ্যাক্টরের গড় আইসি মানটি পরবর্তী সময়ের যৌগিক ফ্যাক্টরের আইসি মানের অনুমান হিসাবে ব্যবহৃত হয় এবং পরবর্তী সময়ের যৌগিক ফ্যাক্টরের অস্থিরতার অনুমান হিসাবে historicalতিহাসিক আইসি মানের কোভ্যারিয়েন্স ম্যাট্রিক্স ব্যবহার করা হয়। আইসি_আইআর অনুসারে আইসির প্রত্যাশিত মানটি আইসির স্ট্যান্ডার্ড বিচ্যুতি দ্বারা বিভক্ত হয় সর্বোচ্চ যৌগিক ফ্যাক্টর আইসি_আইআর এর অনুকূল ওজন সমাধান পেতে।
প্রধান উপাদান বিশ্লেষণ (পিসিএ): পিসিএ ডেটা মাত্রা হ্রাসের জন্য একটি সাধারণ পদ্ধতি এবং কারণগুলির মধ্যে সম্পর্ক উচ্চ হতে পারে। মাত্রা হ্রাসের পরে প্রধান উপাদানগুলি সিন্থেটিক ফ্যাক্টর হিসাবে ব্যবহৃত হয়।
এই কাগজটি ম্যানুয়ালি ফ্যাক্টর বৈধতা বরাদ্দকে উল্লেখ করবে। উপরে বর্ণিত পদ্ধতিগুলি উল্লেখ করা যেতে পারেঃae933a8c-5a94-4d92-8f33-d92b70c36119.pdf
একক ফ্যাক্টর পরীক্ষা করার সময়, বাছাই স্থির করা হয়, কিন্তু মাল্টি ফ্যাক্টর সংশ্লেষণ সম্পূর্ণ ভিন্ন তথ্য একত্রিত করতে হবে, তাই সমস্ত ফ্যাক্টর মানসম্মত করা প্রয়োজন, এবং চরম মান এবং অনুপস্থিত মান সাধারণত অপসারণ করা প্রয়োজন। এখানে আমরা সংশ্লেষণের জন্য df_ ভলিউম\ ফ্যাক্টর_ 1\ ফ্যাক্টর_ 7\ ফ্যাক্টর_ 6\ ফ্যাক্টর_ 8 ব্যবহার করি।
#standardize functions, remove missing values and extreme values, and standardize
def norm_factor(factor):
factor = factor.dropna(how='all')
factor_clip = factor.apply(lambda x:x.clip(x.quantile(0.2), x.quantile(0.8)),axis=1)
factor_norm = factor_clip.add(-factor_clip.mean(axis=1),axis ='index').div(factor_clip.std(axis=1),axis ='index')
return factor_norm
df_volume_norm = norm_factor(df_volume)
factor_1_norm = norm_factor(factor_1)
factor_6_norm = norm_factor(factor_6)
factor_7_norm = norm_factor(factor_7)
factor_8_norm = norm_factor(factor_8)
factor_total = 0.6*df_volume_norm + 0.4*factor_1_norm + 0.2*factor_6_norm + 0.3*factor_7_norm + 0.4*factor_8_norm
factor_total_res = Test(factor_total, symbols, period=8)
factor_total_res.total.plot(figsize=(15,6),grid=True);
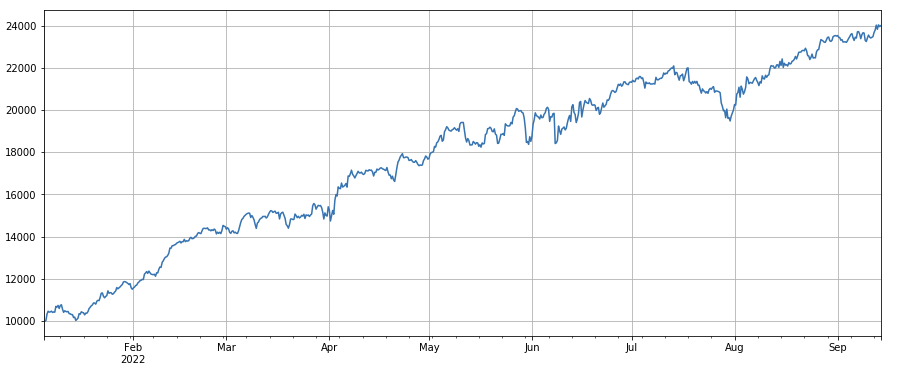
সংক্ষিপ্তসার
এই কাগজটি একক ফ্যাক্টর পরীক্ষার পদ্ধতি এবং সাধারণ একক ফ্যাক্টর পরীক্ষা করে এবং প্রাথমিকভাবে মাল্টি ফ্যাক্টর সংশ্লেষণের পদ্ধতিটি প্রবর্তন করে। তবে, মাল্টি ফ্যাক্টরের অনেকগুলি গবেষণা সামগ্রী রয়েছে। কাগজে উল্লিখিত প্রতিটি পয়েন্ট আরও বিকাশ করা যেতে পারে। এটি আলফা ফ্যাক্টর অন্বেষণে বিভিন্ন কৌশল নিয়ে গবেষণা করার একটি কার্যকর উপায়। ফ্যাক্টর পদ্ধতির ব্যবহার ট্রেডিং আইডিয়াগুলির যাচাইকরণকে ব্যাপকভাবে ত্বরান্বিত করতে পারে এবং রেফারেন্সের জন্য অনেকগুলি উপকরণ রয়েছে।
আসল বটটা:https://www.fmz.com/robot/486605
- ক্রিপ্টোকারেন্সি মার্কেটে মৌলিক বিশ্লেষণের পরিমাণ নির্ধারণঃ তথ্য নিজের জন্য কথা বলতে দিন!
- মুদ্রাচক্রের মৌলিক পরিমাণগত গবেষণা - এখন আর সব ধরনের ধাঁধাবাদী শিক্ষকদের বিশ্বাস করা বন্ধ করুন, তথ্য অবজেক্টিভভাবে কথা বলছে!
- কোয়ালিফাইড লেনদেনের জন্য একটি অপরিহার্য সরঞ্জাম - উদ্ভাবক কোয়ালিফাইড ডেটা এক্সপ্লোরার মডিউল
- সবকিছু আয়ত্ত করা - এফএমজেড ট্রেডিং টার্মিনালের নতুন সংস্করণে ভূমিকা (টিআরবি আর্বিট্রেজ সোর্স কোড সহ)
- এফএমজেডের নতুন ট্রেডিং টার্মিনালের সাথে পরিচিত হোন (ট্র্যাফিক কোড সহ)
- FMZ Quant: ক্রিপ্টোকারেন্সি মার্কেটে সাধারণ প্রয়োজনীয়তা ডিজাইন উদাহরণগুলির বিশ্লেষণ (II)
- কিভাবে 80 লাইন কোডে একটি উচ্চ ফ্রিকোয়েন্সি কৌশল সঙ্গে মস্তিষ্কহীন বিক্রয় বট শোষণ
- এফএমজেড পরিমাণঃ ক্রিপ্টোকারেন্সি বাজারের সাধারণ চাহিদা ডিজাইন উদাহরণ বিশ্লেষণ (২)
- ৮০ লাইন কোডের উচ্চ-প্রবাহের কৌশল ব্যবহার করে মস্তিষ্কবিহীন রোবটকে কীভাবে বিক্রি করা যায়
- FMZ Quant: ক্রিপ্টোকারেন্সি মার্কেটে সাধারণ প্রয়োজনীয়তা ডিজাইন উদাহরণগুলির বিশ্লেষণ (I)
- এফএমজেড কোয়াটিফিকেশনঃ ক্রিপ্টোকারেন্সি মার্কেটের সাধারণ চাহিদা ডিজাইন উদাহরণ বিশ্লেষণ