নিউরাল নেটওয়ার্ক এবং ডিজিটাল মুদ্রা পরিমাণগত ট্রেডিং সিরিজ (2) - নিবিড় শিক্ষা এবং প্রশিক্ষণ বিটকয়েন ট্রেডিং কৌশল
লেখক:লিডিয়া, সৃষ্টিঃ ২০২৩-০১-১২ ১৬ঃ৪৯ঃ০৯, আপডেটঃ ২০২৩-০৯-২০ ১০ঃ০৭ঃ৩৯
নিউরাল নেটওয়ার্ক এবং ডিজিটাল মুদ্রা পরিমাণগত ট্রেডিং সিরিজ (2) - নিবিড় শিক্ষা এবং প্রশিক্ষণ বিটকয়েন ট্রেডিং কৌশল
১. পরিচিতি
গত নিবন্ধে, আমরা বিটকয়েনের দাম পূর্বাভাস দিতে LSTM নেটওয়ার্ক ব্যবহারের পরিচয় করিয়েছি:https://www.fmz.com/bbs-topic/9879, যেমনটি নিবন্ধে উল্লেখ করা হয়েছে, এটি আরএনএন এবং পাইটর্চের সাথে পরিচিত হওয়ার জন্য কেবল একটি ছোট প্রশিক্ষণ প্রকল্প। এই নিবন্ধটি ট্রেডিং কৌশলগুলি সরাসরি প্রশিক্ষণের জন্য নিবিড় শেখার ব্যবহার পরিচয় করিয়ে দেবে। নিবিড় শেখার মডেলটি ওপেনএআই ওপেন সোর্স পিপিও এবং পরিবেশটি জিমের স্টাইলকে বোঝায়। বোঝার এবং পরীক্ষার সুবিধার্থে, এলএসটিএম এর পিপিও মডেল এবং ব্যাকটেস্টিংয়ের জন্য জিম পরিবেশটি প্রস্তুত প্যাকেজ ব্যবহার না করে সরাসরি লেখা হয়। পিপিও, বা প্রক্সিমাল পলিসি অপ্টিমাইজেশন, পলিসি গ্র্যাডিয়েন্টের একটি অপ্টিমাইজেশান উন্নতি। জিমটি ওপেনএআই দ্বারাও প্রকাশিত হয়েছিল। এটি কৌশল নেটওয়ার্কের সাথে ইন্টারঅ্যাক্ট করতে পারে এবং বর্তমান পরিবেশের অবস্থা এবং পুরষ্কারগুলি ফিডব্যাক করতে পারে। এটি নিবিড় শেখার অনুশীলনের মতো। এটি বিটকয়েনের বাজার তথ্য অনুযায়ী সরাসরি ক্রয়, বিক্রয় বা কোনও অপারেশন না করার মতো নির্দেশাবলী তৈরি করতে এলএসটিএম এর পিপিও মডেল ব্যবহার করে। প্রতিক্রিয়া ব্যাকটেস্ট পরিবেশ দ্বারা দেওয়া হয়। প্রশিক্ষণের মাধ্যমে, কৌশলগত লাভের লক্ষ্য অর্জনের জন্য মডেলটি ক্রমাগত অনুকূলিত করা হয়। এই নিবন্ধটি পড়ার জন্য পাইথন, পাইটর্চ এবং ডিআরএল-এ গভীরতর নিবিড় শিক্ষার একটি নির্দিষ্ট ভিত্তি প্রয়োজন। তবে আপনি যদি না পারেন তবে এটি গুরুত্বপূর্ণ নয়। এই নিবন্ধে দেওয়া কোডটি শিখতে এবং শুরু করা সহজ। এই টিউটোরিয়ালটি এফএমজেড কোয়ান্ট ট্রেডিং প্ল্যাটফর্ম দ্বারা উত্পাদিত হয়েছে (www.fmz.com) । যোগাযোগের জন্য QQ গ্রুপে যোগদানের জন্য স্বাগতমঃ 863946592।
২. তথ্য এবং শিক্ষার রেফারেন্স
বিটকয়েনের মূল্যের তথ্য FMZ Quant Trading প্ল্যাটফর্ম থেকে সংগ্রহ করা হয়েছে:https://www.quantinfo.com/Tools/View/4.html. ট্রেডিং কৌশল প্রশিক্ষণের জন্য ডিআরএল+জিম ব্যবহার করে একটি নিবন্ধঃhttps://towardsdatascience.com/visualizing-stock-trading-agents-using-matplotlib-and-gym-584c992bc6d4. পাইটর্চ দিয়ে শুরু করার কিছু উদাহরণঃhttps://github.com/yunjey/pytorch-tutorial.. এই নিবন্ধটি LSTM-PPO মডেল দ্বারা সরাসরি বাস্তবায়ন করবেঃhttps://github.com/seungeunrho/minimalRL/blob/master/ppo-lstm.py.. পিপিও সম্পর্কে নিবন্ধঃhttps://zhuanlan.zhihu.com/p/38185553. ডিআরএল সম্পর্কে আরও নিবন্ধঃhttps://www.zhihu.com/people/flood-sung/posts.. জিম সম্পর্কে, এই নিবন্ধটি ইনস্টলেশন প্রয়োজন হয় না, কিন্তু এটি নিবিড় শিক্ষার মধ্যে খুব সাধারণঃhttps://gym.openai.com/.
৩. LSTM-PPO
পিপিও সম্পর্কে গভীরতর ব্যাখ্যা পেতে, আপনি পূর্ববর্তী রেফারেন্স উপকরণ থেকে শিখতে পারেন। এখানে ধারণাগুলির একটি সহজ ভূমিকা রয়েছে। এলএসটিএম নেটওয়ার্কের সর্বশেষ ইস্যুতে কেবলমাত্র দামটি পূর্বাভাস দেওয়া হয়েছিল। পূর্বাভাসের দামের ভিত্তিতে কীভাবে কিনতে এবং বিক্রি করতে হবে তা আলাদাভাবে উপলব্ধি করতে হবে। এটি মনে করা স্বাভাবিক যে ট্রেডিং অ্যাকশনের সরাসরি আউটপুট আরও সরাসরি হবে। এটি পলিসি গ্র্যাডিয়েন্টের ক্ষেত্রে, যা ইনপুট পরিবেশের তথ্য এস অনুসারে বিভিন্ন ক্রিয়াকলাপের সম্ভাবনা দিতে পারে। এলএসটিএম এর ক্ষতি পূর্বাভাস মূল্য এবং প্রকৃত মূল্যের মধ্যে পার্থক্য, যখন পিজি এর ক্ষতি - লগ § * Q, যেখানে পি একটি আউটপুট ক্রিয়াকলাপের সম্ভাবনা, এবং কিউ ক্রিয়াকলাপের মান (যেমন পুরষ্কার স্কোর) । ব্যাখ্যাটি হ'ল যদি কোনও ক্রিয়াকলাপের মান বেশি হয় তবে নেটওয়ার্ককে ক্ষতি হ্রাস করার জন্য একটি মূল চাবিকাঠি হওয়া উচিত। যদিও পিপিও এর সাথে আরও জটিল। এর মূলনীতিটি প্রতিটি ক্রিয়াকলাপের
LSTM-PPO এর উৎস কোড নিচে দেওয়া হয়েছে, যা পূর্ববর্তী তথ্যের সাথে সংযুক্ত হতে পারেঃ
import time
import requests
import json
import numpy as np
import pandas as pd
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torch.distributions import Categorical
from itertools import count
# Hyperparameters of the model
learning_rate = 0.0005
gamma = 0.98
lmbda = 0.95
eps_clip = 0.1
K_epoch = 3
device = torch.device('cpu') # It can also be changed to GPU version.
class PPO(nn.Module):
def __init__(self, state_size, action_size):
super(PPO, self).__init__()
self.data = []
self.fc1 = nn.Linear(state_size,10)
self.lstm = nn.LSTM(10,10)
self.fc_pi = nn.Linear(10,action_size)
self.fc_v = nn.Linear(10,1)
self.optimizer = optim.Adam(self.parameters(), lr=learning_rate)
def pi(self, x, hidden):
# Output the probability of each action. Since LSTM network also contains the information of hidden layer, please refer to the previous article.
x = F.relu(self.fc1(x))
x = x.view(-1, 1, 10)
x, lstm_hidden = self.lstm(x, hidden)
x = self.fc_pi(x)
prob = F.softmax(x, dim=2)
return prob, lstm_hidden
def v(self, x, hidden):
# Value function is used to evaluate the current situation, so there is only one output.
x = F.relu(self.fc1(x))
x = x.view(-1, 1, 10)
x, lstm_hidden = self.lstm(x, hidden)
v = self.fc_v(x)
return v
def put_data(self, transition):
self.data.append(transition)
def make_batch(self):
# Prepare the training data.
s_lst, a_lst, r_lst, s_prime_lst, prob_a_lst, hidden_lst, done_lst = [], [], [], [], [], [], []
for transition in self.data:
s, a, r, s_prime, prob_a, hidden, done = transition
s_lst.append(s)
a_lst.append([a])
r_lst.append([r])
s_prime_lst.append(s_prime)
prob_a_lst.append([prob_a])
hidden_lst.append(hidden)
done_mask = 0 if done else 1
done_lst.append([done_mask])
s,a,r,s_prime,done_mask,prob_a = torch.tensor(s_lst, dtype=torch.float), torch.tensor(a_lst), \
torch.tensor(r_lst), torch.tensor(s_prime_lst, dtype=torch.float), \
torch.tensor(done_lst, dtype=torch.float), torch.tensor(prob_a_lst)
self.data = []
return s,a,r,s_prime, done_mask, prob_a, hidden_lst[0]
def train_net(self):
s,a,r,s_prime,done_mask, prob_a, (h1,h2) = self.make_batch()
first_hidden = (h1.detach(), h2.detach())
for i in range(K_epoch):
v_prime = self.v(s_prime, first_hidden).squeeze(1)
td_target = r + gamma * v_prime * done_mask
v_s = self.v(s, first_hidden).squeeze(1)
delta = td_target - v_s
delta = delta.detach().numpy()
advantage_lst = []
advantage = 0.0
for item in delta[::-1]:
advantage = gamma * lmbda * advantage + item[0]
advantage_lst.append([advantage])
advantage_lst.reverse()
advantage = torch.tensor(advantage_lst, dtype=torch.float)
pi, _ = self.pi(s, first_hidden)
pi_a = pi.squeeze(1).gather(1,a)
ratio = torch.exp(torch.log(pi_a) - torch.log(prob_a)) # a/b == log(exp(a)-exp(b))
surr1 = ratio * advantage
surr2 = torch.clamp(ratio, 1-eps_clip, 1+eps_clip) * advantage
loss = -torch.min(surr1, surr2) + F.smooth_l1_loss(v_s, td_target.detach()) # Trained both value and decision networks at the same time.
self.optimizer.zero_grad()
loss.mean().backward(retain_graph=True)
self.optimizer.step()
৪. বিটকয়েন ব্যাকটেস্টিং পরিবেশ
জিমের ফর্ম্যাট অনুসরণ করে, একটি রিসেট প্রারম্ভিকীকরণ পদ্ধতি রয়েছে। ধাপটি ক্রিয়াটি ইনপুট করে এবং ফলাফলটি ফিরে আসে (পরবর্তী অবস্থা, ক্রিয়া আয়, শেষ হবে কিনা, অতিরিক্ত তথ্য) । পুরো ব্যাকটেস্ট পরিবেশটিও 60 টি লাইন। আপনি নিজেরাই আরও জটিল সংস্করণগুলি সংশোধন করতে পারেন। নির্দিষ্ট কোডটি হলঃ
class BitcoinTradingEnv:
def __init__(self, df, commission=0.00075, initial_balance=10000, initial_stocks=1, all_data = False, sample_length= 500):
self.initial_stocks = initial_stocks # Initial number of Bitcoins
self.initial_balance = initial_balance # Initial assets
self.current_time = 0 # Time position of the backtest
self.commission = commission # Trading fees
self.done = False # Is the backtest over?
self.df = df
self.norm_df = 100*(self.df/self.df.shift(1)-1).fillna(0) # Standardized approach, simple yield normalization.
self.mode = all_data # Whether it is a sample backtest mode.
self.sample_length = 500 # Sample length
def reset(self):
self.balance = self.initial_balance
self.stocks = self.initial_stocks
self.last_profit = 0
if self.mode:
self.start = 0
self.end = self.df.shape[0]-1
else:
self.start = np.random.randint(0,self.df.shape[0]-self.sample_length)
self.end = self.start + self.sample_length
self.initial_value = self.initial_balance + self.initial_stocks*self.df.iloc[self.start,4]
self.stocks_value = self.initial_stocks*self.df.iloc[self.start,4]
self.stocks_pct = self.stocks_value/self.initial_value
self.value = self.initial_value
self.current_time = self.start
return np.concatenate([self.norm_df[['o','h','l','c','v']].iloc[self.start].values , [self.balance/10000, self.stocks/1]])
def step(self, action):
# action is the action taken by the strategy, here the account will be updated and the reward will be calculated.
done = False
if action == 0: # Hold
pass
elif action == 1: # Buy
buy_value = self.balance*0.5
if buy_value > 1: # Insufficient balance, no account operation.
self.balance -= buy_value
self.stocks += (1-self.commission)*buy_value/self.df.iloc[self.current_time,4]
elif action == 2: # Sell
sell_amount = self.stocks*0.5
if sell_amount > 0.0001:
self.stocks -= sell_amount
self.balance += (1-self.commission)*sell_amount*self.df.iloc[self.current_time,4]
self.current_time += 1
if self.current_time == self.end:
done = True
self.value = self.balance + self.stocks*self.df.iloc[self.current_time,4]
self.stocks_value = self.stocks*self.df.iloc[self.current_time,4]
self.stocks_pct = self.stocks_value/self.value
if self.value < 0.1*self.initial_value:
done = True
profit = self.value - (self.initial_balance+self.initial_stocks*self.df.iloc[self.current_time,4])
reward = profit - self.last_profit # The reward for each turn is the added revenue.
self.last_profit = profit
next_state = np.concatenate([self.norm_df[['o','h','l','c','v']].iloc[self.current_time].values , [self.balance/10000, self.stocks/1]])
return (next_state, reward, done, profit)
৫. বেশ কিছু উল্লেখযোগ্য বিবরণ
- কেন প্রাথমিক অ্যাকাউন্টে মুদ্রা আছে?
ব্যাকটেস্ট পরিবেশের রিটার্ন গণনার সূত্র হলঃ বর্তমান রিটার্ন = বর্তমান অ্যাকাউন্টের মূল্য - প্রাথমিক অ্যাকাউন্টের বর্তমান মূল্য। এর অর্থ হল যে যদি বিটকয়েনের দাম হ্রাস পায় এবং কৌশলটি একটি মুদ্রা বিক্রয় অপারেশন করে, এমনকি যদি মোট অ্যাকাউন্টের মূল্য হ্রাস পায়, তবে কৌশলটি আসলে পুরস্কৃত হওয়া উচিত। যদি ব্যাকটেস্ট দীর্ঘ সময় নেয় তবে প্রাথমিক অ্যাকাউন্টের সামান্য প্রভাব থাকতে পারে তবে এটি শুরুতে একটি বড় প্রভাব ফেলবে। আপেক্ষিক রিটার্ন গণনা নিশ্চিত করে যে প্রতিটি সঠিক অপারেশন ইতিবাচক পুরষ্কার পাবে।
- প্রশিক্ষণের সময় কেন বাজারটি নমুনা করা হয়েছিল?
তথ্যের মোট পরিমাণ 10,000 কে-লাইনেরও বেশি। আপনি যদি প্রতিবার একটি লুপ সম্পূর্ণরূপে চালান তবে এটি দীর্ঘ সময় নেবে এবং কৌশলটি প্রতিবার একই পরিস্থিতির মুখোমুখি হয়, এটি ওভারফিট করা সহজ হতে পারে। ব্যাকটেস্ট হিসাবে একবারে 500 বার নেওয়া। যদিও এখনও ওভারফিট করা সম্ভব, কৌশলটি 10,000 টিরও বেশি সম্ভাব্য স্টার্টের মুখোমুখি।
- যদি কোন মুদ্রা বা টাকা না থাকে?
এই পরিস্থিতি ব্যাকটেস্ট পরিবেশে বিবেচিত হয় না। যদি মুদ্রা বিক্রি হয়ে যায় বা সর্বনিম্ন ট্রেডিং পরিমাণ পৌঁছানো যায় না, তবে বিক্রয় অপারেশনটি প্রকৃতপক্ষে অপারেশনের সমতুল্য। যদি দাম হ্রাস পায়, আপেক্ষিক রিটার্নের গণনার পদ্ধতি অনুসারে, এটি এখনও কৌশলগত ইতিবাচক রিটার্নের উপর ভিত্তি করে। এই পরিস্থিতির প্রভাব হ'ল যখন কৌশলটি বাজার হ্রাস পাচ্ছে এবং অ্যাকাউন্টের অবশিষ্ট মুদ্রা বিক্রি করা যায় না বলে বিচার করে, তখন বিক্রয় ক্রিয়াটি অপারেটিং ক্রিয়া থেকে আলাদা করা অসম্ভব, তবে এটি বাজারে কৌশলটির নিজস্ব বিচারের উপর কোনও প্রভাব ফেলে না।
- কেন আমি অ্যাকাউন্টের তথ্য স্থিতি হিসাবে ফেরত দিতে হবে?
পিপিও মডেলের বর্তমান স্থিতির মান মূল্যায়ন করার জন্য একটি মান নেটওয়ার্ক রয়েছে। স্পষ্টতই, যদি কৌশলটি মূল্যায়ন করে যে দাম বাড়বে, তবে পুরো স্থিতির ইতিবাচক মান কেবল তখনই থাকবে যখন বর্তমান অ্যাকাউন্টে বিটকয়েন রয়েছে এবং বিপরীতভাবে। অতএব, অ্যাকাউন্টের তথ্য মান নেটওয়ার্ক বিচারের জন্য একটি গুরুত্বপূর্ণ ভিত্তি। এটি লক্ষ করা উচিত যে অতীতের ক্রিয়াকলাপের তথ্য স্থিতি হিসাবে ফেরত দেওয়া হয় না। আমি মনে করি মান বিচার করা অকেজো।
- কবে এটা আবার অপারেশন বন্ধ হবে?
যখন কৌশলটি বিচার করে যে লেনদেনের দ্বারা আনা রিটার্নগুলি হ্যান্ডলিং ফি কভার করতে পারে না, তখন এটি অপারেশনে ফিরে আসতে হবে। যদিও পূর্ববর্তী বিবরণটি মূল্যের প্রবণতা বিচার করতে বারবার কৌশলগুলি ব্যবহার করে, এটি কেবল বোঝার সুবিধার জন্য। আসলে, এই পিপিও মডেলটি বাজারটি পূর্বাভাস দেয় না, তবে কেবল তিনটি ক্রিয়াকলাপের সম্ভাবনা আউটপুট করে।
৬. তথ্য সংগ্রহ ও প্রশিক্ষণ
পূর্ববর্তী নিবন্ধের মতো, তথ্য সংগ্রহের পদ্ধতি এবং বিন্যাস নিম্নরূপঃ বিটফাইনেক্স এক্সচেঞ্জ বিটিসি_ইউএসডি ট্রেডিং জোড়ার এক ঘন্টার সময়কালের কে-লাইন 7 মে, 2018 থেকে 27 জুন, 2019 পর্যন্তঃ
resp = requests.get('https://www.quantinfo.com/API/m/chart/history?symbol=BTC_USD_BITFINEX&resolution=60&from=1525622626&to=1561607596')
data = resp.json()
df = pd.DataFrame(data,columns = ['t','o','h','l','c','v'])
df.index = df['t']
df = df.dropna()
df = df.astype(np.float32)
এলএসটিএম নেটওয়ার্কের ব্যবহারের কারণে, প্রশিক্ষণের সময়টি খুব দীর্ঘ। আমি একটি জিপিইউ সংস্করণে স্যুইচ করেছি, যা প্রায় তিনগুণ দ্রুত।
env = BitcoinTradingEnv(df)
model = PPO()
total_profit = 0 # Record total profit
profit_list = [] # Record the profits of each training session
for n_epi in range(10000):
hidden = (torch.zeros([1, 1, 32], dtype=torch.float).to(device), torch.zeros([1, 1, 32], dtype=torch.float).to(device))
s = env.reset()
done = False
buy_action = 0
sell_action = 0
while not done:
h_input = hidden
prob, hidden = model.pi(torch.from_numpy(s).float().to(device), h_input)
prob = prob.view(-1)
m = Categorical(prob)
a = m.sample().item()
if a==1:
buy_action += 1
if a==2:
sell_action += 1
s_prime, r, done, profit = env.step(a)
model.put_data((s, a, r/10.0, s_prime, prob[a].item(), h_input, done))
s = s_prime
model.train_net()
profit_list.append(profit)
total_profit += profit
if n_epi%10==0:
print("# of episode :{:<5}, profit : {:<8.1f}, buy :{:<3}, sell :{:<3}, total profit: {:<20.1f}".format(n_epi, profit, buy_action, sell_action, total_profit))
৭. প্রশিক্ষণের ফলাফল এবং বিশ্লেষণ
দীর্ঘ অপেক্ষার পর:

প্রথমত, প্রশিক্ষণের তথ্যের বাজারে দেখুন। সাধারণভাবে, প্রথম অর্ধেক একটি দীর্ঘমেয়াদী পতন, এবং দ্বিতীয় অর্ধেক একটি শক্তিশালী রিবাউন্ড।
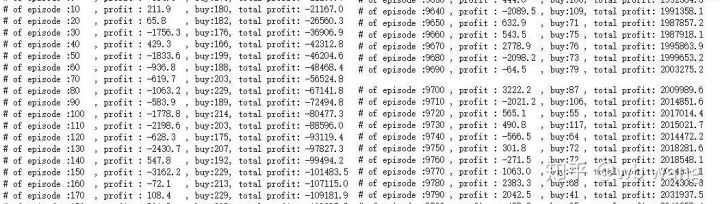
প্রশিক্ষণের প্রাথমিক পর্যায়ে অনেকগুলি ক্রয় অপারেশন রয়েছে এবং মূলত কোনও লাভজনক রাউন্ড নেই। প্রশিক্ষণের মাঝামাঝি সময়ে ক্রয় অপারেশন ধীরে ধীরে হ্রাস পেয়েছে এবং লাভের সম্ভাবনাও বাড়ছে, তবে এখনও ক্ষতির সম্ভাবনা রয়েছে।
প্রতিটি রাউন্ডের মুনাফা সমতল করুন, এবং ফলাফল নিম্নরূপঃ
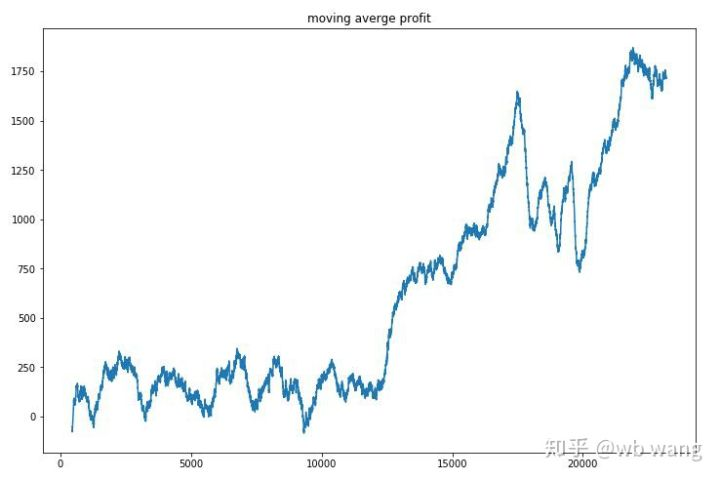
কৌশলটি দ্রুত পরিস্থিতি থেকে মুক্তি পেয়েছিল যে প্রাথমিক রিটার্ন নেতিবাচক ছিল, তবে ওঠানামা বড় ছিল। 10,000 রাউন্ডের পরে পর্যন্ত রিটার্ন দ্রুত বৃদ্ধি পায়নি। সাধারণভাবে, মডেল প্রশিক্ষণ খুব কঠিন ছিল।
চূড়ান্ত প্রশিক্ষণের পরে, মডেলটি কীভাবে সম্পাদন করে তা দেখতে সমস্ত ডেটা আবার চালিয়ে যাক। এই সময়ের মধ্যে, অ্যাকাউন্টের মোট বাজার মূল্য, রাখা বিটকয়েনের সংখ্যা, বিটকয়েনের মূল্যের অনুপাত এবং মোট রিটার্ন রেকর্ড করুন। প্রথমটি হল মোট বাজারমূল্য, এবং মোট রিটার্ন এর অনুরূপ, তারা পোস্ট করা হবে নাঃ
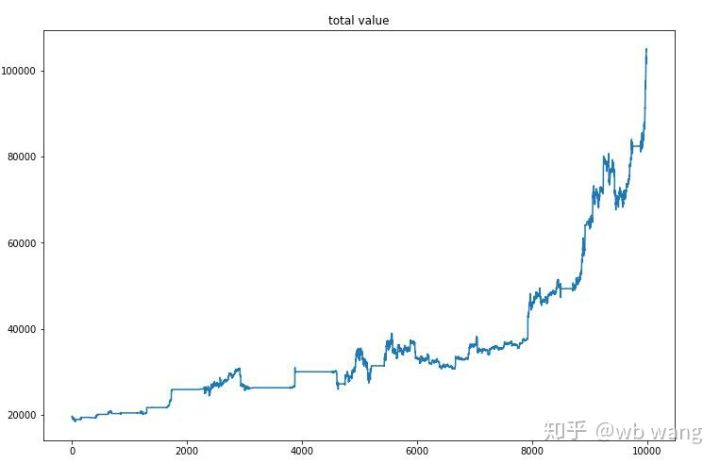
প্রথম ধীরে ধীরে বাজারে মোট বাজারমূল্য বৃদ্ধি পায় এবং পরে ষাঁড়ের বাজারে বৃদ্ধি পায়, কিন্তু এখনও পর্যায়ক্রমিক ক্ষতি হয়।
অবশেষে, অবস্থানের অনুপাতটি দেখুন। চার্টের বাম অক্ষটি অবস্থানের অনুপাত এবং ডান অক্ষটি বাজার। এটি প্রাথমিকভাবে বিচার করা যেতে পারে যে মডেলটি ওভারফিট। অবস্থানের ফ্রিকোয়েন্সি প্রাথমিক ভালুকের বাজারে কম এবং বাজারের নীচে উচ্চ। এটিও দেখা যায় যে মডেলটি দীর্ঘমেয়াদী অবস্থানগুলি ধরে রাখতে শিখেনি এবং সর্বদা দ্রুত বিক্রি করে।
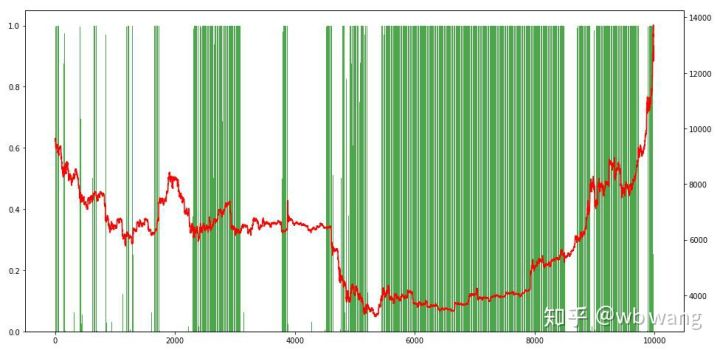
৮. পরীক্ষার তথ্য বিশ্লেষণ
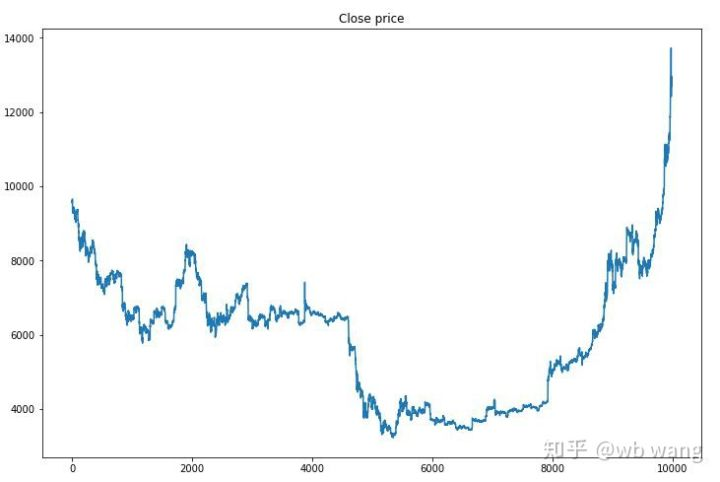
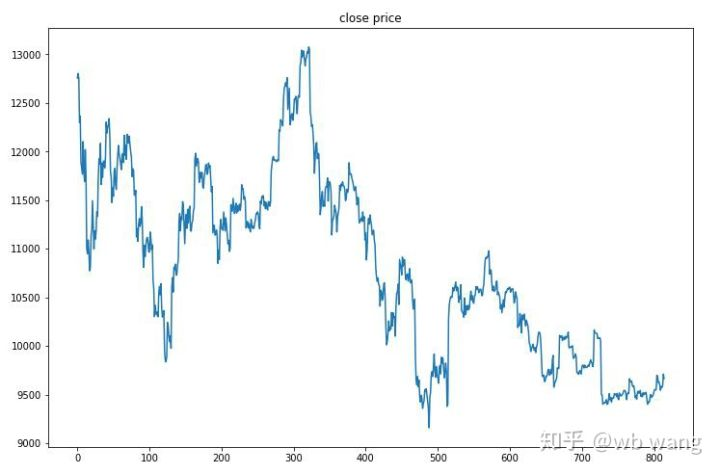
২৭ জুন, ২০১৯ থেকে এখন পর্যন্ত বিটকয়েনের এক ঘণ্টার বাজার পরীক্ষার তথ্য থেকে প্রাপ্ত হয়েছিল। চার্ট থেকে দেখা যায় যে দাম ১৩,০০০ ডলার থেকে কমে ৯,০০০ ডলারেরও বেশি হয়েছে, যা মডেলের জন্য একটি দুর্দান্ত পরীক্ষা।
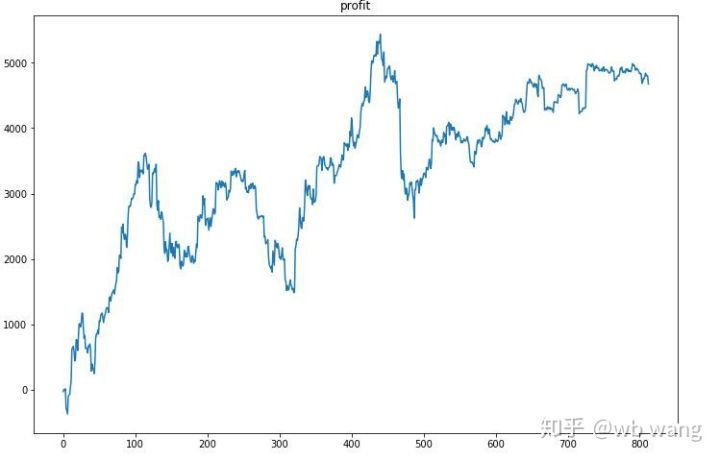
প্রথমত, চূড়ান্ত আপেক্ষিক রিটার্ন কাজ করেছে, কিন্তু কোন ক্ষতি হয়নি।
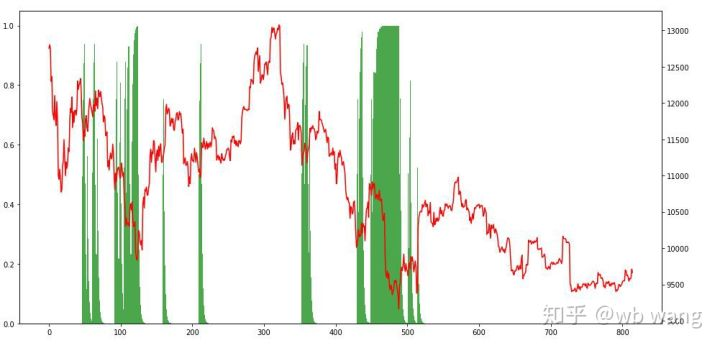
পজিশন পরিস্থিতি দেখে আমরা অনুমান করতে পারি যে মডেলটি তীব্র পতনের পরে কিনতে এবং রিবাউন্ডের পরে বিক্রি করতে থাকে। বিটকয়েনের বাজার সাম্প্রতিক সময়ে সামান্য ওঠানামা করেছে, এবং মডেলটি শর্ট পজিশনে রয়েছে।
৯. সারসংক্ষেপ
এই প্রবন্ধে, একটি বিটকয়েন স্বয়ংক্রিয় ট্রেডিং রোবট পিপিও এর সাহায্যে প্রশিক্ষিত হয়, একটি গভীর নিবিড় শেখার পদ্ধতি, এবং কিছু উপসংহার পাওয়া যায়। সীমিত সময়ের কারণে, মডেলটিতে এখনও কিছু দিক উন্নত করা যায়। আলোচনাকে স্বাগত জানাই। সবচেয়ে বড় পাঠ হল যে ডেটা স্ট্যান্ডার্ডাইজেশন পদ্ধতির জন্য, স্কেলিং এবং অন্যান্য পদ্ধতি ব্যবহার করবেন না, অন্যথায় মডেলটি দ্রুত মূল্য এবং বাজারের মধ্যে সম্পর্কটি মনে রাখবে এবং ওভারফিট হয়ে পড়বে। স্ট্যান্ডার্ডাইজড পরিবর্তন হারটি আপেক্ষিক ডেটা, যা মডেলের জন্য বাজারের সাথে সম্পর্কটি মনে রাখা কঠিন করে তোলে এবং পরিবর্তন হার এবং বৃদ্ধি এবং হ্রাসের মধ্যে সম্পর্ক খুঁজে পেতে বাধ্য হয়।
পূর্ববর্তী নিবন্ধের ভূমিকা: একটি উচ্চ-ফ্রিকোয়েন্সি কৌশল আমি প্রকাশ করেছি যা একসময় খুবই লাভজনক ছিল:https://www.fmz.com/bbs-topic/9886.
- ক্রিপ্টোকারেন্সি মার্কেটে মৌলিক বিশ্লেষণের পরিমাণ নির্ধারণঃ তথ্য নিজের জন্য কথা বলতে দিন!
- মুদ্রাচক্রের মৌলিক পরিমাণগত গবেষণা - এখন আর সব ধরনের ধাঁধাবাদী শিক্ষকদের বিশ্বাস করা বন্ধ করুন, তথ্য অবজেক্টিভভাবে কথা বলছে!
- কোয়ালিফাইড লেনদেনের জন্য একটি অপরিহার্য সরঞ্জাম - উদ্ভাবক কোয়ালিফাইড ডেটা এক্সপ্লোরার মডিউল
- সবকিছু আয়ত্ত করা - এফএমজেড ট্রেডিং টার্মিনালের নতুন সংস্করণে ভূমিকা (টিআরবি আর্বিট্রেজ সোর্স কোড সহ)
- এফএমজেডের নতুন ট্রেডিং টার্মিনালের সাথে পরিচিত হোন (ট্র্যাফিক কোড সহ)
- FMZ Quant: ক্রিপ্টোকারেন্সি মার্কেটে সাধারণ প্রয়োজনীয়তা ডিজাইন উদাহরণগুলির বিশ্লেষণ (II)
- কিভাবে 80 লাইন কোডে একটি উচ্চ ফ্রিকোয়েন্সি কৌশল সঙ্গে মস্তিষ্কহীন বিক্রয় বট শোষণ
- এফএমজেড পরিমাণঃ ক্রিপ্টোকারেন্সি বাজারের সাধারণ চাহিদা ডিজাইন উদাহরণ বিশ্লেষণ (২)
- ৮০ লাইন কোডের উচ্চ-প্রবাহের কৌশল ব্যবহার করে মস্তিষ্কবিহীন রোবটকে কীভাবে বিক্রি করা যায়
- FMZ Quant: ক্রিপ্টোকারেন্সি মার্কেটে সাধারণ প্রয়োজনীয়তা ডিজাইন উদাহরণগুলির বিশ্লেষণ (I)
- এফএমজেড কোয়াটিফিকেশনঃ ক্রিপ্টোকারেন্সি মার্কেটের সাধারণ চাহিদা ডিজাইন উদাহরণ বিশ্লেষণ