Die Waffe von AlphaGo: Der Monte-Carlo-Algorithmus. Nach der Lektüre werden Sie ihn verstehen! (mit Codebeispiel)--Nachdruck
 0
23883
0
23883
Die Alphas: Die Monte-Carlo-Algorithmen, die man verstehen kann!
Am 9. bis 15. März dieses Jahres fand in Seoul, Südkorea, eine große Veranstaltung in der Welt des Go-Games statt, in der insgesamt fünf Runden des Kampfes zwischen Mensch und Maschine ausgetragen wurden. Das Ergebnis des Spiels war eine Niederlage für die Menschheit, als der Go-Weltmeister Lee Hsien Loong von AlphaGo, der künstlichen Intelligenz von Google, mit 1:4 besiegt wurde. Was ist AlphaGo und wo ist der Schlüssel zum Erfolg? Hier geht es um einen Algorithmus: den Monte Carlo Algorithmus.
- ### AlphaGo und der Monte Carlo-Algorithmus
Wie die Nachrichtenagentur Xinhua berichtete, ist AlphaGo ein Programm für das Go-Spiel zwischen Mensch und Maschine, das vom Team DeepMind von Google entwickelt wurde und von chinesischen Chess-Fans als Alpha-Spiel bezeichnet wird.
Im letzten Artikel haben wir über das Neural-Network-Algorithmus, das Google entwickelt, um Maschinen autonomes Lernen zu ermöglichen, berichtet. AlphaGo ist ein ähnliches Produkt.
Der stellvertretende Vorstandsvorsitzende und Generalsekretär der China Automation Association, Wang Fiyun, sagte, dass die Programmierer keine Go-Kenntnisse haben müssen, sondern nur die grundlegenden Regeln des Spiels kennen müssen. Hinter AlphaGo steckt eine Gruppe von herausragenden Computerwissenschaftlern, genau gesagt, Experten im Bereich des maschinellen Lernens.
Der Algorithmus von Monte Carlo ist der Schlüssel, um AlphaGo zu einem selbstlernenden Talent zu machen.
Was ist der Monte Carlo-Algorithmus? Die Algorithmus von Monte Carlo wurde von einem bekannten Algorithmus erklärt: Wenn man 1000 Äpfel in einem Korb hat, so dass man jedes Mal, wenn man die Augen schließt, nach dem größten suchen kann, kann man unbegrenzt wählen. Man kann also mit geschlossenen Augen einen zufällig auswählen, dann noch einen zufällig mit dem ersten vergleichen und den großen belassen, dann noch einen zufällig mit dem vorherigen vergleichen und den großen belassen. Der Kreislauf wird so wiederholt, je öfter man die Äpfel auswählt, desto größer ist die Wahrscheinlichkeit, dass man den größten auswählt, aber es ist nicht sicher, dass man den größten auswählen wird, es sei denn, man wählt alle 1000 Äpfel aus.
Das heißt, die Monte-Carlo-Algorithmus ist, dass je mehr Proben, desto besser die beste Lösung gefunden wird, aber nicht garantiert die beste, denn wenn es 10.000 Äpfel gibt, kann es sein, dass man eine größere finden wird.
Ein Vergleich mit ihm ist der Las Vegas-Algorithmus: Es wird allgemein gesagt, dass, wenn es ein Schloss, 1000 Schlüssel zur Auswahl, aber nur 1 ist richtig. So jedes Mal zufällig nehmen Sie 1 Schlüssel zu versuchen, nicht zu öffnen, und ändern Sie die 1. Je mehr Versuche, desto größer ist die Chance, die beste Lösung zu öffnen, aber vor dem Öffnen, die falschen Schlüssel sind nutzlos.
Der Las Vegas-Algorithmus ist also die bestmögliche Lösung, aber nicht unbedingt die beste. Angenommen, es gibt 1000 Schlüssel, von denen kein einziger das Schloss öffnen kann. Der wahre Schlüssel ist der 1001.
Die Monte Carlo-Algorithmen von AlphaGo Die Schwierigkeit von Go ist besonders groß für eine KI, da es so viele verschiedene Arten gibt, dass es für einen Computer schwierig ist, sie zu erkennen. Zuerst einmal gibt es zu viele Wahrscheinlichkeiten beim Go-Spiel. Jeder Schritt des Go-Spiels hat sehr viele mögliche Entscheidungen, und der Spieler hat 19 x 19 = 361 Möglichkeiten zum Fallen. In einer Partie von 150 Runden gibt es bis zu 10170 mögliche Situationen. Zweitens ist die Regel zu fein, und die Wahl des Fallens hängt zu einem gewissen Grad von der Erfahrung ab, die sich durch die Ansammlung von Intuition entwickelt hat.
AlphaGo ist nicht nur ein Monte-Carlo-Algorithmus, sondern eine erweiterte Version des Monte-Carlo-Algorithmus.
AlphaGo arbeitet mit dem Monte-Carlo-Baum-Such-Algorithmus und zwei tiefen neuronalen Netzwerken zusammen, um das Schachspiel zu erledigen. Bevor es mit Li Shih zu kämpfen hatte, trainierte Google zunächst das neurale Netzwerk des AlphaGo-Hundes mit fast 30 Millionen Bewegungen von menschlichen Paaren, damit es lernen konnte, vorherzusagen, wie ein menschlicher professioneller Schachspieler fallen würde.
Ihre Aufgabe besteht darin, gemeinsam die vielversprechendsten Schritte auszuwählen und die offensichtlich schlechten Schritte zu verdrängen, um die Berechnungen so zu begrenzen, dass sie von einem Computer erledigt werden können.
Die traditionellen Schachspielsoftware, die in der Regel mit gewaltsamen Suchen arbeitet, einschließlich des Deep Blue Computers, der eine Suchtbaum für alle möglichen Ergebnisse erstellt (jedes Ergebnis ist eine Frucht auf dem Baum), um nach Bedarf eine Durchsuchung durchzuführen. Diese Methode ist auch in Schach, Tennis und anderen Bereichen möglich, aber nicht für Go, da das Go 19 Linien überspannt und die Wahrscheinlichkeit, dass ein Computer einen Baum bauen kann, so groß ist (zu viele Früchte), um eine Durchsuchung durchzuführen.
Der Grundsatz des Deep Neural Networks ist, so erklärt Dr. Yugachi weiter, dass eine der grundlegendsten Zellen eines Deep Neural Networks eine Neurone in unserem menschlichen Gehirn ähnelt, die mit vielen Ebenen verbunden ist, so dass es sich um ein neuronales Netzwerk im menschlichen Gehirn handelt. Die beiden neuronalen Netzwerke von AlphaGo sind das Strategie-Netzwerk und das Bewertungsnetzwerk.
Das Schachstrategie-Netzwerk wird hauptsächlich zur Erzeugung von Fallstrategien verwendet. Während des Spiels wird nicht darüber nachgedacht, wie man selbst abschneiden sollte, sondern wie der menschliche Vorteil abschneiden würde. Das heißt, es wird anhand des aktuellen Zustands des eingegebenen Spielfeldes vorhersagen, wo der nächste Schachschritt des Menschen stattfinden wird, und einige praktikable Schritte vorschlagen, die am besten dem menschlichen Denken entsprechen.
Das Strategie-Netzwerk weiß jedoch nicht, ob das Schachspiel, das es herausbringt, gut oder schlecht ist, es weiß nur, ob es das gleiche Schachspiel wie das menschliche ist, und das Bewertungs-Netzwerk ist dann notwendig.
Der Monte Carlo-Algorithmus entscheidet, dass das Strategie-Netzwerk nur dort weitergeführt wird, wo die Gewinnrate höher ist, so dass bestimmte Routen abgeschafft werden können, ohne einen Weg zum Schwarzen zu berechnen.
AlphaGo nutzt diese beiden Werkzeuge, um die Situation zu analysieren und die Vor- und Nachteile jeder unteren Strategie zu beurteilen, so wie ein menschlicher Schachspieler die gegenwärtige Situation beurteilt und zukünftige Situationen abschätzt.
Aber es gibt keinen Zweifel, dass der Monte Carlo-Algorithmus einer der Kernpunkte von AlphaGo ist.
Zwei kleine Experimente Zum Schluss noch zwei kleine Experimente mit dem Monte-Carlo-Algorithmus:
- ### 1. Berechnen Sie die Kreislänge Pi.
Prinzip: Zeichne zuerst ein Quadrat, zeichne den Kreis, der in ihm geschnitten ist, und dann einen zufälligen Punkt in dem Quadrat, wobei der Punkt in der Kreislinie P liegt, wobei P = Fläche des Kreises / Fläche des Quadrats. P=(Pi*R*R)/(2R*2R) = Pi/4, also Pi = 4P
Schritte: 1. Setzen Sie den Mittelpunkt des Kreises an den Ursprungspunkt und machen Sie einen Kreis mit R als Radius, dann ist die Fläche des Kreises Pi 1⁄4 des ersten Quadrats*R*R/4 2. Machen Sie ein Quadrat mit der Koordinaten: 0, 0, R, R, R, R, R, R, R, R, R, R, R, R, R, R, R, R, R, R, R, R, R, R, R, R, R, R, R, R, R, R, R, R, und R.*R 3. Nehmen Sie sofort die Punkte ((X, Y), so dass 0 <= X <= R und 0 <= Y <= R, also der Punkt im Quadrat 4. Durch die Formel X*X+Y*Y*R ist in 1⁄4 der Umkreis. 5. Angenommen, alle Punkte (d. h. die Anzahl der Experimente) sind N und die Punkte innerhalb des Viertelkreises (d. h. die Punkte, die Schritt 4 erfüllen) sind M.
P = M/N, also Pi = 4.*N/M
 Bild 1
Bild 1
M_C ((10000) läuft auf 3.1424
- ### 2. Montecarlo simuliert Extreme der Suchfunktion, um lokale Extreme zu vermeiden
# In der Zwischenzeit[-2,2] erzeugt eine Zahl zufällig und sucht die entsprechende y heraus, um herauszufinden, ob die größte davon die Funktion ist, die in[-2,2] auf der äußersten
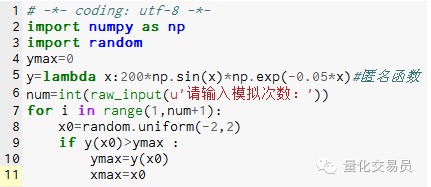 Bild 2
Bild 2
Nach 1000 Simulationen wurde ein Maximalwert von 185.12292832389875 gefunden (sehr genau)
Das ist ja auch interessant, wenn man sieht, dass man Code handschriftlich schreiben kann. Übertragung von WeChat Public