Support Vector Machines im Gehirn
 0
2106
0
2106
Support Vector Machines im Gehirn
Die SWM scheint ein mathematisches Kunststück zu sein, aber es passt zufällig zur Mechanik der Gehirnkodierung. Wir können aus einem Nature-Papier aus dem Jahr 2013 lesen, um die tiefe Verbindung zwischen der Funktionsweise von Maschinelles Lernen und dem Gehirn zu verstehen. Titel: Die Bedeutung von Mixed Selectivity in Complex Cognitive Tasks (by Omri Barak al.)
- #### SVM
Zuerst sprechen wir über die Natur der Neurokodierung: Tiere empfangen ein bestimmtes Signal und verhalten sich danach, indem sie das äußere Signal in ein elektrisches Signal umwandeln, das andere in ein Entscheidungssignal umwandeln. Der erste Prozess wird als Encoding bezeichnet, der zweite als Decoding. Der eigentliche Zweck der Neurokodierung ist es, den Code zu entschlüsseln, um dann eine Entscheidung zu treffen.
Und wenn wir über das Codieren sprechen, dann ist es oft eine Abweichung der Zeit, dass in einem kleinen Zeitrahmen die Abgabe konstant ist, so dass ein neuronales Netzwerk in diesem Zeitrahmen die Abgabe von Zellen in einer Reihe betrachten kann in einer n-dimensionalen Richtung, in der n die Anzahl der Neuronen ist, und diese n-dimensionalen Menge, die wir nennen die codierte Menge, die die Bilder darstellt, die ein Tier sehen oder hören kann, die das entsprechende Nervennetzwerk in der Haut auslösen - das entsprechende Signal in der äußeren Umgebung. Wir haben zuvor keine tiefgehende Aufmerksamkeit auf dieses Netzwerk gelegt.
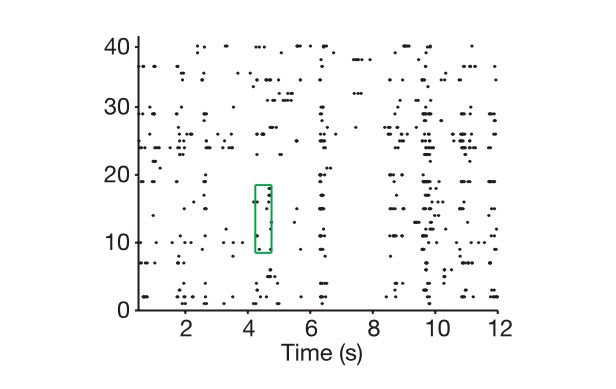
Grafik: Die Vertikale ist die Zelle, die Laterale ist die Zeit, und die Grafik zeigt, wie wir die neuronalen Codes extrahieren.
Natürlich gibt es einen Unterschied zwischen den realen Dimensionen eines n-dimensionalen Vektors und der realen Dimension einer neuronalen Codierung. Zuerst betreten wir diesen n-dimensionalen Raum, der von einem n-dimensionalen Vektor markiert ist, und dann geben wir Ihnen alle möglichen Aufgabenkombinationen, z. B. zeigen wir Ihnen tausend Bilder, nehmen Sie an, dass diese Bilder die ganze Welt repräsentieren, und markieren Sie jede neuronale Codierung, die wir erhalten, als einen Punkt in diesem Raum.
Wir haben ein Konzept, das wir neben der realen Dimension der Codierung auch haben, die realen Dimensionen der äußeren Signale, also der äußeren Signale, die von einem neuronalen Netzwerk ausgedrückt werden. Natürlich müssen wir alle Details der äußeren Signale wiederholen. Das ist ein unendliches Problem, aber unsere Klassifizierung und Entscheidungsgrundlage sind immer die entscheidenden Eigenschaften, ein Dimensionierungsprozess, das ist auch die Idee der PCA.
Und dann stellt sich die zentrale Frage: Warum sollte man mit einer so hohen Anzahl von Neuronen und einer so hohen Anzahl von Code-Dimensionen versuchen, dieses Problem zu lösen?
Und Computational Neuroscience und Machine Learning zusammen zeigen uns, dass die hohe Dimension der Neuroexpression die Grundlage für ihre hohe Lernfähigkeit ist. Je höher die Coding-Dimension, desto stärker ist die Lernfähigkeit.
Beachten Sie, dass die hier diskutierte Neurokodierung sich hauptsächlich auf die Neurokodierung der höheren Nervenzentren bezieht, wie z. B. der in diesem Artikel diskutierten präfrontalen Kortex (PFC), da die Kodierungsregeln der unteren Nervenzentren nicht so sehr mit Klassifizierung und Entscheidungsfindung zu tun haben.
Hochentwickelte Hirnregionen, die von PFC repräsentiert werden
Zunächst einmal nehmen wir an, dass wir mit einem linearen Klassifikator nicht in der Lage sind, mit einem nicht-linearen Klassifizierungsproblem umzugehen, wenn unsere codierte Dimension der Dimension einer wichtigen Variable in der realen Aufgabe entspricht (sagen wir, Sie möchten eine Zucchini aus einer Zucchini trennen, aber Sie können sie nicht mit einer linearen Grenze aus der Zucchini trennen). Dies ist auch eine typische Aufgabe, die wir ohne Deep Learning und SVM in das Maschinelle Lernen nicht lösen können.
SVM (unterstützt Vektor):
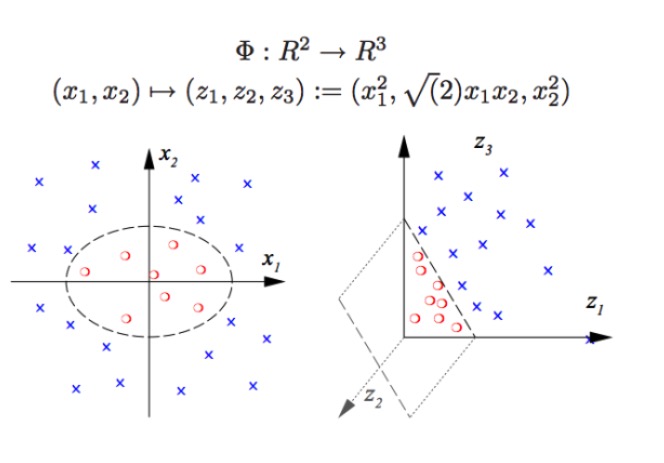
SVM kann eine nichtlineare Klassifizierung durchführen, z. B. die Trennung von roten und blauen Punkten in der Grafik, die wir mit einer linearen Grenze nicht von roten und blauen Punkten trennen können (siehe Abbildung links), so dass die SVM-Methode genau die Erhöhung der Dimension ist. Die einfache Erhöhung der Zahl der Variablen ist nicht möglich, z. B. die Zuordnung von (x1, x2) zu (x1, x2, x1 + x2) System ist in der Tat ein zweidimensionaler linearer Raum (wenn man die roten Punkte und die blauen Punkte in einer Ebene darstellt), nur mit einer nichtlinearen Funktion (x1 ^ 2, x1)*x2, x2^2) Wir haben also einen wesentlichen Übergang von der niedrigen zur höheren Dimension, wenn man die blauen Punkte in die Luft wirft und dann eine Fläche in die Luft zeichnet, die die blauen Punkte von den roten Punkten trennt, wie in der rechten Abbildung.
Tatsächlich ist es genau das, was echte neuronale Netze tun. Die Art der Klassifizierung, die ein solcher linearer Klassifikator (Decoder) durchführen kann, ist stark erhöht, was bedeutet, dass wir viel bessere Mustererkennungskapazitäten haben als zuvor. Hier ist hohe Dimension hohe Energie, und hohe Dimension ist die Wahrheit.
Wie kommt man zu einer hohen Dimension der neuronalen Codierung? Eine hohe Anzahl von Lichtneuronen ist nutzlos. Denn wir wissen aus der linearen Algebra, dass, wenn wir eine große Anzahl von N Neuronen haben, und die Entladungsrate jedes Neurons nur linear mit K Schlüsselmerkmalen verbunden ist, dann ist die Dimension, die wir am Ende darstellen, nur die Dimension der Frage selbst, und Ihre N Neuronen sind unbedeutend (die Mehrzahl der Neuronen ist eine lineare Kombination von K Neuronen).
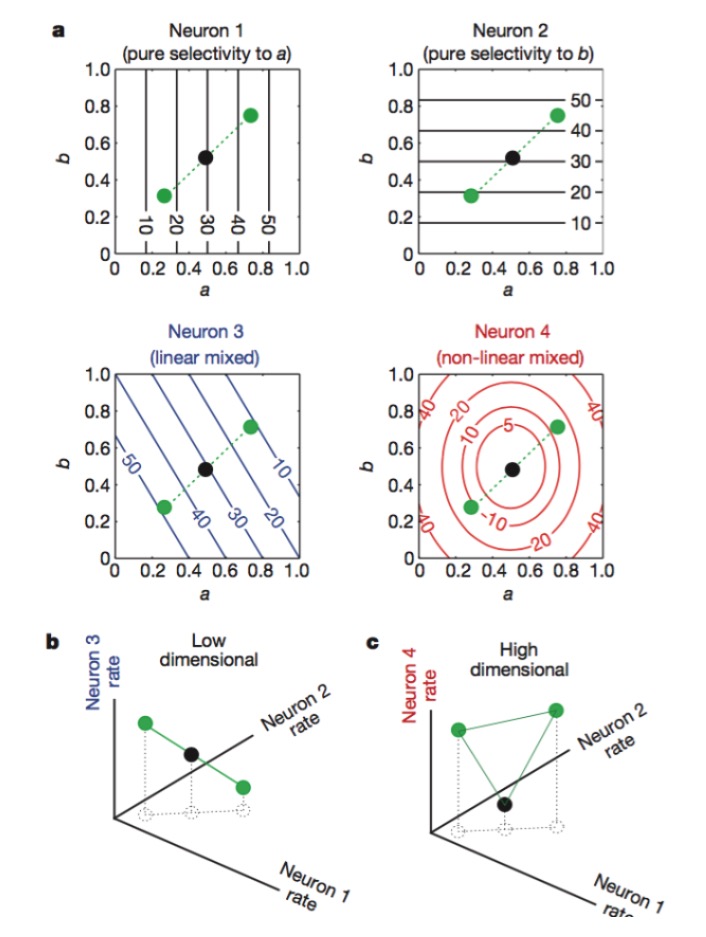
Abbildung: Neuronen 1 und 2 sind nur für Merkmale a und b empfindlich, 3 für die lineare Mischung von Merkmalen a und b und 4 für die nichtlineare Mischung von Merkmalen. Letztendlich erhöht nur die Kombination von Neuronen 1, 2 und 4 die neurokodierte Dimension (siehe Abbildung unten).
Die offizielle Bezeichnung für diese Art der Kodierung lautet “gemischte Selektivität” (mixed selectivity), was uns unbegreiflich erschien, als man diese Art der Kodierung nicht entdeckte, denn es handelt sich um ein nervöses Netzwerk, das auf eine bestimmte Art von Signal schlecht reagiert. Im umgebenden Nervensystem wirken Neuronen wie Sensoren, um verschiedene Merkmale der Signale zu extrahieren und zu erkennen. Die Funktion jeder einzelnen Nervenzelle ist ziemlich spezifisch, wie die Roden und Kegel der Retina, die für die Aufnahme von Photonen verantwortlich sind, und dann die Gangelion-Zelle weiter kodiert, so dass jede Nervenzelle wie ein individueller, professionell ausgebildeter Wachmann ist.
Mit jedem Detail der Natur, der in der Vorlage steckt, einer Menge von Redundanz und Mischcodierung, das scheinbar unprofessionelle Vorgehen, das scheinbar chaotische Signal, endet eine bessere Rechenleistung. Mit diesem Prinzip können wir leicht mit einigen Aufgaben wie:
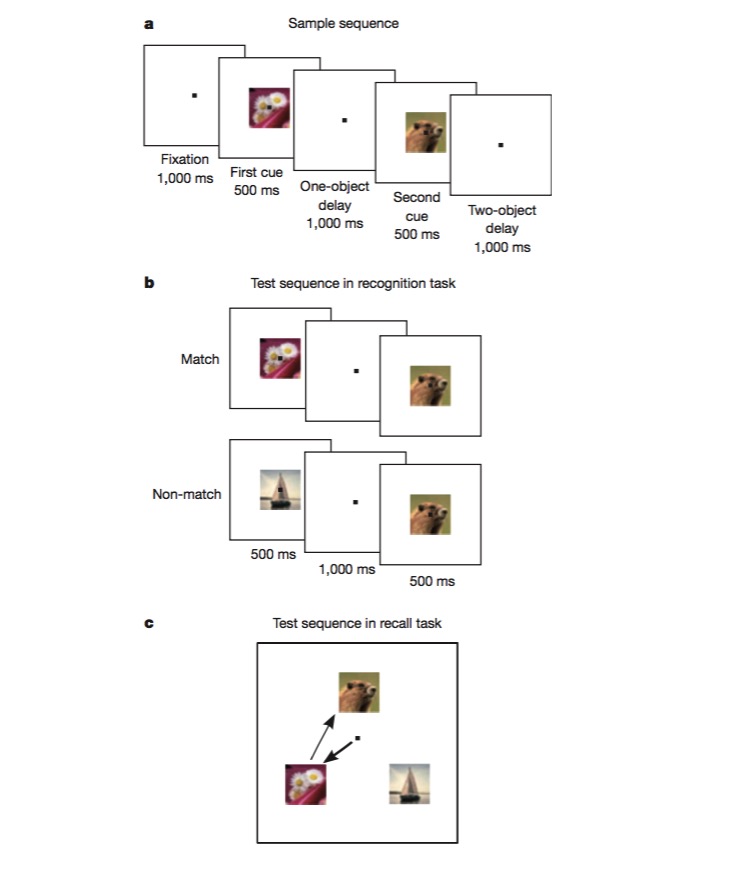
In dieser Aufgabe wird der Affe erst trainiert, zu unterscheiden, ob ein Bild mit dem vorherigen identisch ist, und dann zu beurteilen, in welcher Reihenfolge zwei verschiedene Bilder erscheinen. Um diese Aufgabe zu erfüllen, muss der Affe in der Lage sein, verschiedene Aspekte der Aufgabe zu kodieren, wie z. B. die Art des Auftrags, die Art des Bildes usw., und dies ist der beste Test, um zu prüfen, ob ein hybridisierter nichtlinearer Codierungsmechanismus vorhanden ist.
In diesem Artikel haben wir gelernt, dass das Entwerfen von neuronalen Netzwerken die Fähigkeit zur Mustererkennung erheblich verbessern kann, wenn man einige nichtlineare Einheiten einführt, und dass die SVM dies anwendet, um nichtlineare Klassifizierungsprobleme zu lösen.
Wir untersuchen die Funktionen der Gehirnregionen, zuerst verarbeiten wir die Daten mit Methoden des maschinellen Lernens, z. B. finden wir die entscheidenden Dimensionen des Problems mit PCA, dann verstehen wir die Neurokodierung und -code mit den Gedanken, die das Lernmodell erkennt, und schließlich können wir die Methode des maschinellen Lernens verbessern, wenn wir neue Inspirationen bekommen. Für das Gehirn oder die Maschinellehrungsalgorithmen ist es am wichtigsten, die richtige Art und Weise zu erhalten, wie die Informationen am besten dargestellt werden, und mit einer guten Darstellung ist alles einfacher.
Übertragung von Weiß-Hü-Jei-Kreuzfahrt-Technologie