Neuronale Netzwerke und Quantitative Trading in digitaler Währung (2) - Intensives Lernen und Schulen Bitcoin Trading Strategie
Schriftsteller:Lydia., Erstellt: 2023-01-12 16:49:09, Aktualisiert: 2023-09-20 10:07:39
Neuronale Netzwerke und Quantitative Trading in digitaler Währung (2) - Intensives Lernen und Schulen Bitcoin Trading Strategie
1. Einleitung
Im letzten Artikel haben wir die Verwendung des LSTM-Netzwerks zur Vorhersage des Bitcoin-Preises vorgestellt:https://www.fmz.com/bbs-topic/9879, wie im Artikel erwähnt, ist es nur ein kleines Trainingsprojekt, um sich mit RNN und pytorch vertraut zu machen. In diesem Artikel wird die Verwendung von Intensivlernen eingeführt, um die Handelsstrategien direkt zu trainieren. Das Modell des Intensivlernens ist OpenAI Open Source PPO, und die Umgebung bezieht sich auf den Stil von Gym. Um das Verständnis und das Testen zu erleichtern, werden das PPO-Modell von LSTM und die Gym-Umgebung für das Backtesting direkt geschrieben, ohne fertige Pakete zu verwenden. PPO, oder Proximal Policy Optimization, ist eine Optimierungsverbesserung von Policy Gradient. Gym wurde auch von OpenAI veröffentlicht. Es kann mit dem Strategie-Netzwerk interagieren und den Status und die Belohnungen der aktuellen Umgebung zurückgeben. Es ist wie die Praxis des intensiven Lernens. Es verwendet das PPO-Modell von LSTM, um Anweisungen wie Kauf, Verkauf oder keinen Betrieb direkt nach den Marktinformationen von Bitcoin zu machen. Das Feedback wird von der Backtest-Umgebung gegeben. Durch Training wird das Modell kontinuierlich optimiert, um das Ziel des strategischen Gewinns zu erreichen. Das Lesen dieses Artikels erfordert eine gewisse Grundlagen für ein tiefgreifendes intensives Lernen in Python, pytorch und DRL. Aber es spielt keine Rolle, ob Sie es nicht können. Es ist einfach zu lernen und mit dem in diesem Artikel angegebenen Code zu beginnen. Dieses Tutorial wird von der FMZ Quant Trading Plattform erstellt (www.fmz.com) Willkommen zur QQ-Gruppe: 863946592 für Kommunikation.
2. Daten und Lernreferenzen
Bitcoin-Preisdaten stammen von der FMZ Quant Trading Plattform:https://www.quantinfo.com/Tools/View/4.html- Ich weiß. Ein Artikel, in dem DRL+Gym zum Trainieren von Handelsstrategien verwendet wird:https://towardsdatascience.com/visualizing-stock-trading-agents-using-matplotlib-and-gym-584c992bc6d4- Ich weiß. Einige Beispiele, wie man mit pytorch anfängt:https://github.com/yunjey/pytorch-tutorial- Ich weiß. Dieser Artikel wird durch das LSTM-PPO-Modell direkt umsetzen:https://github.com/seungeunrho/minimalRL/blob/master/ppo-lstm.py- Ich weiß. Artikel über PPO:https://zhuanlan.zhihu.com/p/38185553- Ich weiß. Weitere Artikel über DRL:https://www.zhihu.com/people/flood-sung/posts- Ich weiß. Über das Fitnessstudio: Dieser Artikel erfordert keine Installation, ist aber bei Intensivlernen sehr verbreitet:https://gym.openai.com/.
3. LSTM-PPO
Für eine eingehende Erläuterung von PPO können Sie aus den vorherigen Referenzmaterialien lernen. Hier ist nur eine einfache Einführung in Konzepte. Die letzte Ausgabe des LSTM-Netzwerks hat nur den Preis vorhergesagt. Wie man auf der Grundlage des vorhergesagten Preises kauft und verkauft, muss separat realisiert werden. Es ist natürlich zu denken, dass die direkte Ausgabe der Handelsaktion direkter sein wird. Dies ist der Fall mit dem Policy Gradient, der die Wahrscheinlichkeit verschiedener Aktionen nach den Eingabeumgebungsinformationen s geben kann. Der Verlust von LSTM ist die Differenz zwischen dem vorhergesagten Preis und dem tatsächlichen Preis, während der Verlust von PG - log § * Q ist, wobei p die Wahrscheinlichkeit einer Ausgabeaktion ist und Q der intuitive Wert der Aktion ist (z. B. Belohnungsscore). Die Erläuterung ist, dass wenn der Wert einer Aktion höher ist, das Netzwerk einen Schlüssel zur Verringerung der Verluste haben sollte. Obwohl PPO viel komplexer ist, ist sein Prinzi
Der Quellcode von LSTM-PPO ist nachstehend angegeben, der in Kombination mit den vorherigen Daten verstanden werden kann:
import time
import requests
import json
import numpy as np
import pandas as pd
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torch.distributions import Categorical
from itertools import count
# Hyperparameters of the model
learning_rate = 0.0005
gamma = 0.98
lmbda = 0.95
eps_clip = 0.1
K_epoch = 3
device = torch.device('cpu') # It can also be changed to GPU version.
class PPO(nn.Module):
def __init__(self, state_size, action_size):
super(PPO, self).__init__()
self.data = []
self.fc1 = nn.Linear(state_size,10)
self.lstm = nn.LSTM(10,10)
self.fc_pi = nn.Linear(10,action_size)
self.fc_v = nn.Linear(10,1)
self.optimizer = optim.Adam(self.parameters(), lr=learning_rate)
def pi(self, x, hidden):
# Output the probability of each action. Since LSTM network also contains the information of hidden layer, please refer to the previous article.
x = F.relu(self.fc1(x))
x = x.view(-1, 1, 10)
x, lstm_hidden = self.lstm(x, hidden)
x = self.fc_pi(x)
prob = F.softmax(x, dim=2)
return prob, lstm_hidden
def v(self, x, hidden):
# Value function is used to evaluate the current situation, so there is only one output.
x = F.relu(self.fc1(x))
x = x.view(-1, 1, 10)
x, lstm_hidden = self.lstm(x, hidden)
v = self.fc_v(x)
return v
def put_data(self, transition):
self.data.append(transition)
def make_batch(self):
# Prepare the training data.
s_lst, a_lst, r_lst, s_prime_lst, prob_a_lst, hidden_lst, done_lst = [], [], [], [], [], [], []
for transition in self.data:
s, a, r, s_prime, prob_a, hidden, done = transition
s_lst.append(s)
a_lst.append([a])
r_lst.append([r])
s_prime_lst.append(s_prime)
prob_a_lst.append([prob_a])
hidden_lst.append(hidden)
done_mask = 0 if done else 1
done_lst.append([done_mask])
s,a,r,s_prime,done_mask,prob_a = torch.tensor(s_lst, dtype=torch.float), torch.tensor(a_lst), \
torch.tensor(r_lst), torch.tensor(s_prime_lst, dtype=torch.float), \
torch.tensor(done_lst, dtype=torch.float), torch.tensor(prob_a_lst)
self.data = []
return s,a,r,s_prime, done_mask, prob_a, hidden_lst[0]
def train_net(self):
s,a,r,s_prime,done_mask, prob_a, (h1,h2) = self.make_batch()
first_hidden = (h1.detach(), h2.detach())
for i in range(K_epoch):
v_prime = self.v(s_prime, first_hidden).squeeze(1)
td_target = r + gamma * v_prime * done_mask
v_s = self.v(s, first_hidden).squeeze(1)
delta = td_target - v_s
delta = delta.detach().numpy()
advantage_lst = []
advantage = 0.0
for item in delta[::-1]:
advantage = gamma * lmbda * advantage + item[0]
advantage_lst.append([advantage])
advantage_lst.reverse()
advantage = torch.tensor(advantage_lst, dtype=torch.float)
pi, _ = self.pi(s, first_hidden)
pi_a = pi.squeeze(1).gather(1,a)
ratio = torch.exp(torch.log(pi_a) - torch.log(prob_a)) # a/b == log(exp(a)-exp(b))
surr1 = ratio * advantage
surr2 = torch.clamp(ratio, 1-eps_clip, 1+eps_clip) * advantage
loss = -torch.min(surr1, surr2) + F.smooth_l1_loss(v_s, td_target.detach()) # Trained both value and decision networks at the same time.
self.optimizer.zero_grad()
loss.mean().backward(retain_graph=True)
self.optimizer.step()
4. Bitcoin-Backtestumgebung
Nach dem Format von Gym gibt es eine Reset-Initialisierungsmethode. Step gibt die Aktion ein und das zurückgegebene Ergebnis ist (nächster Status, Aktionsertrag, ob zu Ende gehen soll, zusätzliche Informationen). Die gesamte Backtest-Umgebung besteht ebenfalls aus 60 Zeilen. Sie können selbst komplexere Versionen ändern. Der spezifische Code lautet:
class BitcoinTradingEnv:
def __init__(self, df, commission=0.00075, initial_balance=10000, initial_stocks=1, all_data = False, sample_length= 500):
self.initial_stocks = initial_stocks # Initial number of Bitcoins
self.initial_balance = initial_balance # Initial assets
self.current_time = 0 # Time position of the backtest
self.commission = commission # Trading fees
self.done = False # Is the backtest over?
self.df = df
self.norm_df = 100*(self.df/self.df.shift(1)-1).fillna(0) # Standardized approach, simple yield normalization.
self.mode = all_data # Whether it is a sample backtest mode.
self.sample_length = 500 # Sample length
def reset(self):
self.balance = self.initial_balance
self.stocks = self.initial_stocks
self.last_profit = 0
if self.mode:
self.start = 0
self.end = self.df.shape[0]-1
else:
self.start = np.random.randint(0,self.df.shape[0]-self.sample_length)
self.end = self.start + self.sample_length
self.initial_value = self.initial_balance + self.initial_stocks*self.df.iloc[self.start,4]
self.stocks_value = self.initial_stocks*self.df.iloc[self.start,4]
self.stocks_pct = self.stocks_value/self.initial_value
self.value = self.initial_value
self.current_time = self.start
return np.concatenate([self.norm_df[['o','h','l','c','v']].iloc[self.start].values , [self.balance/10000, self.stocks/1]])
def step(self, action):
# action is the action taken by the strategy, here the account will be updated and the reward will be calculated.
done = False
if action == 0: # Hold
pass
elif action == 1: # Buy
buy_value = self.balance*0.5
if buy_value > 1: # Insufficient balance, no account operation.
self.balance -= buy_value
self.stocks += (1-self.commission)*buy_value/self.df.iloc[self.current_time,4]
elif action == 2: # Sell
sell_amount = self.stocks*0.5
if sell_amount > 0.0001:
self.stocks -= sell_amount
self.balance += (1-self.commission)*sell_amount*self.df.iloc[self.current_time,4]
self.current_time += 1
if self.current_time == self.end:
done = True
self.value = self.balance + self.stocks*self.df.iloc[self.current_time,4]
self.stocks_value = self.stocks*self.df.iloc[self.current_time,4]
self.stocks_pct = self.stocks_value/self.value
if self.value < 0.1*self.initial_value:
done = True
profit = self.value - (self.initial_balance+self.initial_stocks*self.df.iloc[self.current_time,4])
reward = profit - self.last_profit # The reward for each turn is the added revenue.
self.last_profit = profit
next_state = np.concatenate([self.norm_df[['o','h','l','c','v']].iloc[self.current_time].values , [self.balance/10000, self.stocks/1]])
return (next_state, reward, done, profit)
5. Mehrere bemerkenswerte Einzelheiten
- Warum hat das Konto eine Währung?
Die Formel zur Berechnung der Rendite der Backtestumgebung lautet: aktuelle Rendite = Leistungsbilanzwert - Leistungsbilanzwert des Anfangskontos. Dies bedeutet, dass, wenn der Preis von Bitcoin sinkt und die Strategie eine Münzverkaufsaktion durchführt, auch wenn der Gesamtkontowert sinkt, die Strategie tatsächlich belohnt werden sollte. Wenn der Backtest lange dauert, kann der Anfangskonto wenig Auswirkungen haben, aber er wird am Anfang eine große Wirkung haben. Die Berechnung der relativen Rendite stellt sicher, dass jede richtige Operation eine positive Belohnung erzielt.
- Warum wurde der Markt während der Ausbildung ausgewählt?
Die Gesamtmenge der Daten beträgt mehr als 10.000 K-Linien. Wenn Sie jedes Mal eine Schleife vollständig ausführen, dauert es lange, und die Strategie wird jedes Mal mit der gleichen Situation konfrontiert, kann es einfacher sein, sich zu überanpassen.
- Was ist, wenn es keine Währung oder Geld gibt?
Diese Situation wird im Backtest-Umfeld nicht berücksichtigt. Wenn die Währung ausverkauft wurde oder die Mindesthandelsmenge nicht erreicht werden kann, dann entspricht die Verkaufsaktion der tatsächlichen Nichtoperation. Wenn der Preis nach der Berechnungsmethode der relativen Rendite sinkt, basiert er immer noch auf der strategischen positiven Rendite. Die Auswirkungen dieser Situation sind, dass, wenn die Strategie beurteilt, dass der Markt sinkt und die verbleibende Währung des Kontos nicht verkauft werden kann, es unmöglich ist, die Verkaufsaktion von der nicht-operativen Aktion zu unterscheiden, aber es hat keinen Einfluss auf das Urteil der Strategie selbst auf dem Markt.
- Warum sollte ich Kontoinformationen als Status zurückgeben?
Das PPO-Modell verfügt über ein Wertnetzwerk, um den Wert des aktuellen Status zu bewerten. Offensichtlich, wenn die Strategie beurteilt, dass der Preis steigen wird, wird der gesamte Status nur dann einen positiven Wert haben, wenn das Girokonto Bitcoin hält, und umgekehrt. Daher ist Kontoinformationen eine wichtige Grundlage für das Wertnetzwerk-Urteil. Es ist zu beachten, dass die vergangenen Aktionsinformationen nicht als Status zurückgegeben werden. Ich halte es für sinnlos, den Wert zu beurteilen.
- Wann wird es wieder nicht funktionieren?
Wenn die Strategie beurteilt, dass die durch die Transaktion erzielten Renditen die Handlinggebühr nicht decken können, sollte sie zur Nichtoperation zurückkehren. Obwohl die vorherige Beschreibung wiederholt Strategien verwendet, um den Preistrend zu beurteilen, ist dies nur zur Verständniserleichterung. In der Tat prognostiziert dieses PPO-Modell den Markt nicht, sondern liefert nur die Wahrscheinlichkeit von drei Aktionen.
6. Datenerfassung und Ausbildung
Wie im vorherigen Artikel sind die Methode und das Format der Datenerfassung wie folgt: einstündige Periode K-Linie des Bitfinex Exchange BTC_USD Handelspaares vom 7. Mai 2018 bis 27. Juni 2019:
resp = requests.get('https://www.quantinfo.com/API/m/chart/history?symbol=BTC_USD_BITFINEX&resolution=60&from=1525622626&to=1561607596')
data = resp.json()
df = pd.DataFrame(data,columns = ['t','o','h','l','c','v'])
df.index = df['t']
df = df.dropna()
df = df.astype(np.float32)
Aufgrund der Verwendung des LSTM-Netzwerks ist die Trainingszeit sehr lang. Ich wechselte zu einer GPU-Version, die etwa dreimal schneller ist.
env = BitcoinTradingEnv(df)
model = PPO()
total_profit = 0 # Record total profit
profit_list = [] # Record the profits of each training session
for n_epi in range(10000):
hidden = (torch.zeros([1, 1, 32], dtype=torch.float).to(device), torch.zeros([1, 1, 32], dtype=torch.float).to(device))
s = env.reset()
done = False
buy_action = 0
sell_action = 0
while not done:
h_input = hidden
prob, hidden = model.pi(torch.from_numpy(s).float().to(device), h_input)
prob = prob.view(-1)
m = Categorical(prob)
a = m.sample().item()
if a==1:
buy_action += 1
if a==2:
sell_action += 1
s_prime, r, done, profit = env.step(a)
model.put_data((s, a, r/10.0, s_prime, prob[a].item(), h_input, done))
s = s_prime
model.train_net()
profit_list.append(profit)
total_profit += profit
if n_epi%10==0:
print("# of episode :{:<5}, profit : {:<8.1f}, buy :{:<3}, sell :{:<3}, total profit: {:<20.1f}".format(n_epi, profit, buy_action, sell_action, total_profit))
7. Ausbildungsergebnisse und Analyse
Nach langer Wartezeit:

Zunächst einmal betrachten wir den Markt für Ausbildungsdaten. Im Allgemeinen ist die erste Hälfte ein langfristiger Rückgang, und die zweite Hälfte ist ein starker Aufschwung.
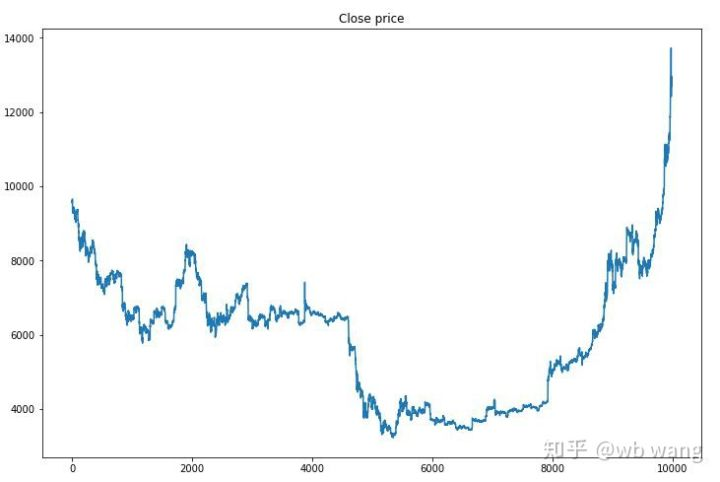
In der Anfangsphase der Ausbildung gibt es viele Kaufoperationen, und es gibt im Grunde keine profitable Runde.
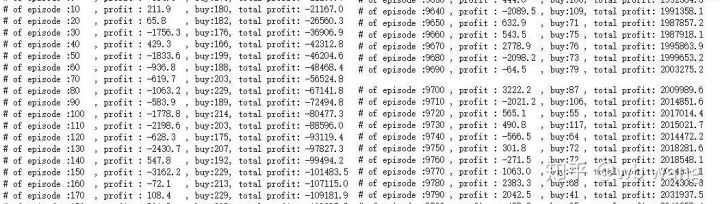
Glatte den Gewinn jeder Runde aus, und das Ergebnis ist wie folgt:
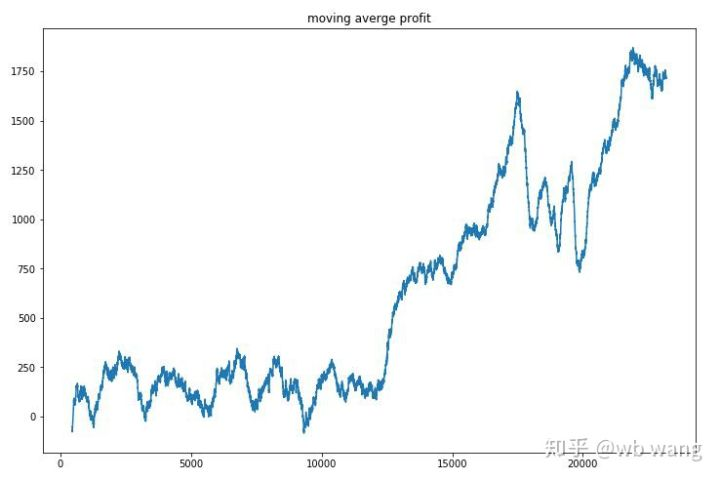
Die Strategie löste schnell die Situation, dass die frühe Rückkehr negativ war, aber die Schwankung war groß. Die Rückkehr wuchs erst nach 10.000 Runden schnell. Im Allgemeinen war das Modelltraining sehr schwierig.
Nach dem letzten Training lassen Sie das Modell alle Daten erneut ausführen, um zu sehen, wie es funktioniert. Während des Zeitraums erfassen Sie den Gesamtmarktwert des Kontos, die Anzahl der gehaltenen Bitcoins, den Anteil des Bitcoin-Wertes und die Gesamtrendite. Erstens ist der Gesamtmarktwert, und die Gesamtrendite sind ähnlich, sie werden nicht veröffentlicht:
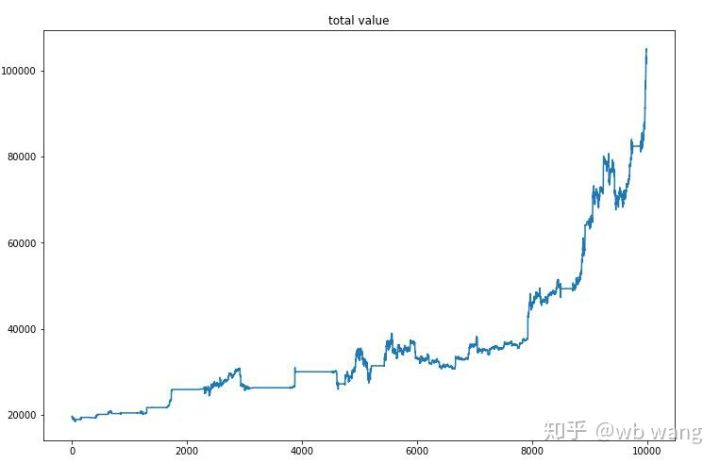
Der Gesamtmarktwert stieg im frühen Bärenmarkt langsam an und hielt mit dem Anstieg des späteren Bullenmarktes Schritt, aber es gab immer noch periodische Verluste.
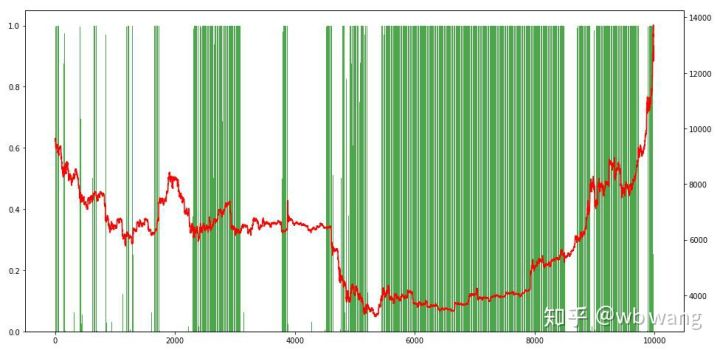
Schließlich schauen wir uns den Anteil der Positionen an. Die linke Achse des Diagramms ist der Anteil der Positionen und die rechte Achse ist der Markt. Es kann vorläufig beurteilt werden, dass das Modell übermäßig passt. Die Häufigkeit der Positionen ist in den frühen Bärenmärkten niedrig und an der Unterseite des Marktes hoch. Es kann auch gesehen werden, dass das Modell nicht gelernt hat, langfristige Positionen zu halten und immer schnell verkauft.
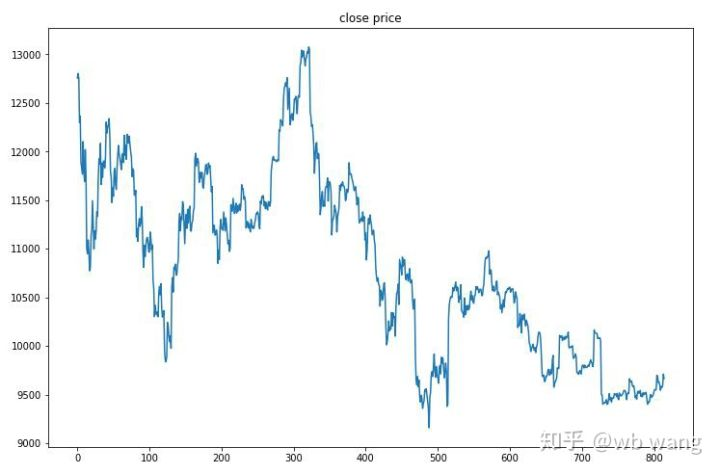
8. Analyse der Prüfdaten
Der einstündige Markt für Bitcoin vom 27. Juni 2019 bis jetzt wurde aus den Testdaten gewonnen. Aus dem Diagramm kann gesehen werden, dass der Preis von 13.000 USD auf mehr als 9.000 USD gefallen ist, was ein großartiger Test für das Modell ist.
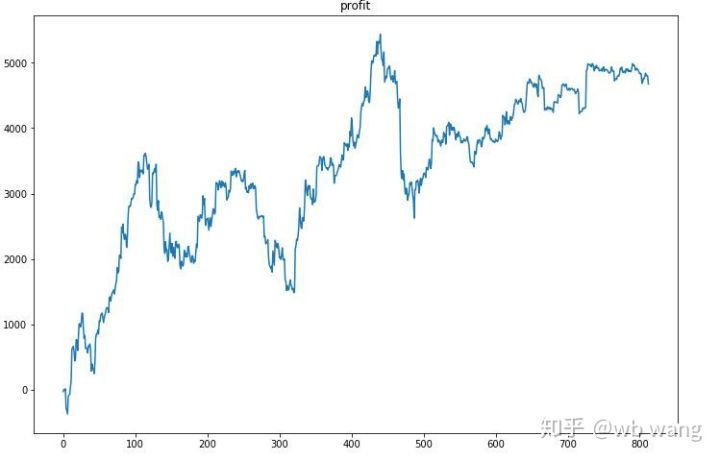
Zunächst einmal lief die relative Rückkehr so, aber es gab keinen Verlust.
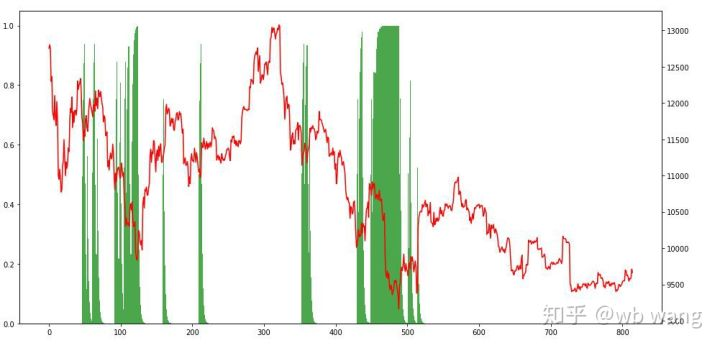
Wenn man sich die Positionssituation ansieht, kann man vermuten, dass das Modell nach einem starken Fall zu kaufen und nach einem Rebound zu verkaufen neigt.
9. Zusammenfassung
In diesem Papier wird ein Bitcoin automatischer Handelsroboter mit Hilfe von PPO, einer tiefen intensiven Lernmethode, trainiert und einige Schlussfolgerungen gezogen. Aufgrund der begrenzten Zeit gibt es noch einige Aspekte im Modell zu verbessern. Willkommen bei der Diskussion. Die größte Lektion ist, dass für die Datenstandardisierungsmethode nicht skalieren und andere Methoden verwenden, sonst wird das Modell schnell die Beziehung zwischen Preis und Markt merken und in Überanpassung geraten. Die standardisierte Wechselrate ist die relative Datenrate, die es dem Modell erschwert, sich an die Beziehung zum Markt zu erinnern, und ist gezwungen, die Beziehung zwischen der Veränderungsrate und dem Anstieg und Abfall zu finden.
Einleitung zu früheren Artikeln: Eine hochfrequente Strategie, die ich enthüllte, war einst sehr profitabel:https://www.fmz.com/bbs-topic/9886.
- Quantifizierung der Fundamentalanalyse auf dem Kryptowährungsmarkt: Die Daten sprechen für sich!
- Die Quantifizierung der Kernforschung der Münzkreise - nicht mehr auf alle Arten von Lehrern zu vertrauen, die überzeugt sind, dass die Daten objektiv sind!
- Ein wichtiges Werkzeug im Bereich der Quantitative Transaktionen - der Erfinder der Quantitative Data Exploration Module
- Mastering Everything - Einführung in FMZ Neue Version des Handelsterminals (mit TRB Arbitrage Source Code)
- Die neue Version des FMZ-Trading-Terminals ist verfügbar.
- FMZ Quant: Eine Analyse von gemeinsamen Anforderungen Designbeispielen auf dem Kryptowährungsmarkt (II)
- Wie man Hirnlose Verkaufs-Bots mit einer Hochfrequenz-Strategie in 80 Codezeilen ausnutzt
- FMZ-Quantifizierung: Analyse von Designbeispielen für häufige Bedürfnisse im Kryptowährungsmarkt (II)
- Wie man Hirnlose Roboter ausbeuten und verkaufen kann mit einer 80-Zeilen-code-Hochfrequenz-Strategie
- FMZ Quant: Eine Analyse von gemeinsamen Anforderungen Designbeispielen auf dem Kryptowährungsmarkt (I)
- FMZ-Quantifizierung: Analyse von Designbeispielen für häufige Bedürfnisse im Kryptowährungsmarkt