Überlegungen zu Hochfrequenzhandelsstrategien (5)
Schriftsteller:Lydia., Erstellt: 2023-08-10 15:57:27, aktualisiert: 2023-09-12 15:51:54
Überlegungen zu Hochfrequenzhandelsstrategien (5)
In dem vorangegangenen Artikel wurden verschiedene Methoden zur Berechnung des mittleren Preises vorgestellt und ein überarbeiteter mittlerer Preis vorgeschlagen.
Erforderliche Daten
Wir benötigen Bestellflussdaten und Tiefendaten für die zehn obersten Ebenen des Orderbuchs, die aus dem Live-Handel mit einer Aktualisierungsfrequenz von 100 ms gesammelt wurden. Aus Gründen der Einfachheit werden wir keine Echtzeit-Aktualisierungen für die Gebots- und Anfragepreise enthalten. Um die Datengröße zu reduzieren, haben wir nur 100.000 Zeilen mit Tiefendaten aufbewahrt und die Tic-by-Tic-Marktdaten in einzelne Spalten getrennt.
In [1]:
from datetime import date,datetime
import time
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import ast
%matplotlib inline
In [2]:
tick_size = 0.0001
In [3]:
trades = pd.read_csv('YGGUSDT_aggTrade.csv',names=['type','event_time', 'agg_trade_id','symbol', 'price', 'quantity', 'first_trade_id', 'last_trade_id',
'transact_time', 'is_buyer_maker'])
In [4]:
trades = trades.groupby(['transact_time','is_buyer_maker']).agg({
'transact_time':'last',
'agg_trade_id': 'last',
'price': 'first',
'quantity': 'sum',
'first_trade_id': 'first',
'last_trade_id': 'last',
'is_buyer_maker': 'last',
})
In [5]:
trades.index = pd.to_datetime(trades['transact_time'], unit='ms')
trades.index.rename('time', inplace=True)
trades['interval'] = trades['transact_time'] - trades['transact_time'].shift()
In [6]:
depths = pd.read_csv('YGGUSDT_depth.csv',names=['type','event_time', 'transact_time','symbol', 'u1', 'u2', 'u3', 'bids','asks'])
In [7]:
depths = depths.iloc[:100000]
In [8]:
depths['bids'] = depths['bids'].apply(ast.literal_eval).copy()
depths['asks'] = depths['asks'].apply(ast.literal_eval).copy()
In [9]:
def expand_bid(bid_data):
expanded = {}
for j, (price, quantity) in enumerate(bid_data):
expanded[f'bid_{j}_price'] = float(price)
expanded[f'bid_{j}_quantity'] = float(quantity)
return pd.Series(expanded)
def expand_ask(ask_data):
expanded = {}
for j, (price, quantity) in enumerate(ask_data):
expanded[f'ask_{j}_price'] = float(price)
expanded[f'ask_{j}_quantity'] = float(quantity)
return pd.Series(expanded)
# Apply to each line to get a new df
expanded_df_bid = depths['bids'].apply(expand_bid)
expanded_df_ask = depths['asks'].apply(expand_ask)
# Expansion on the original df
depths = pd.concat([depths, expanded_df_bid, expanded_df_ask], axis=1)
In [10]:
depths.index = pd.to_datetime(depths['transact_time'], unit='ms')
depths.index.rename('time', inplace=True);
In [11]:
trades = trades[trades['transact_time'] < depths['transact_time'].iloc[-1]]
Die Verteilung des Marktes in diesen 20 Ebenen entspricht den Erwartungen, je mehr Aufträge vom Marktpreis entfernt platziert werden, desto mehr sind die Kauf- und Verkaufsaufträge nahezu symmetrisch.
In [14]:
bid_mean_list = []
ask_mean_list = []
for i in range(20):
bid_mean_list.append(round(depths[f'bid_{i}_quantity'].mean(),0))
ask_mean_list.append(round(depths[f'ask_{i}_quantity'].mean(),0))
plt.figure(figsize=(10, 5))
plt.plot(bid_mean_list);
plt.plot(ask_mean_list);
plt.grid(True)
Ausgeschaltet[1]:
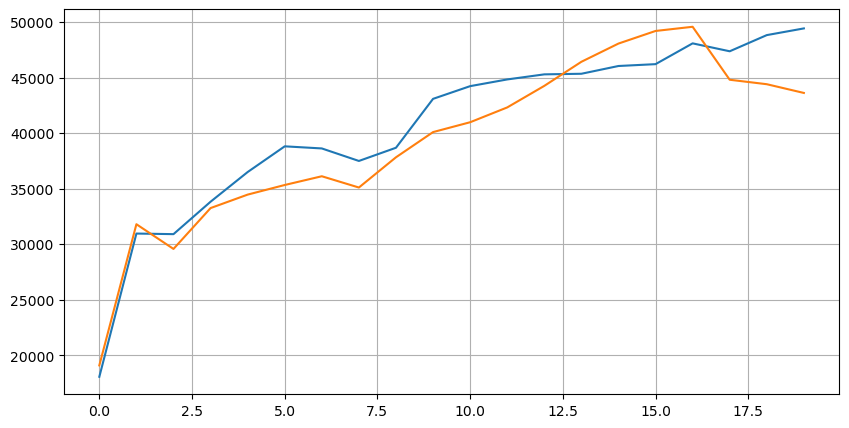
Verknüpfen Sie die Tiefendaten mit den Transaktionsdaten, um die Bewertung der Vorhersagegenauigkeit zu erleichtern. Stellen Sie sicher, dass die Transaktionsdaten später als die Tiefendaten liegen. Berechnen Sie direkt den mittleren Quadratfehler zwischen dem vorhergesagten Wert und dem tatsächlichen Transaktionspreis, ohne die Latenz zu berücksichtigen. Dies wird verwendet, um die Genauigkeit der Vorhersage zu messen.
Aus den Ergebnissen ist der Fehler am höchsten für den durchschnittlichen Wert der Bid- und Ask-Preise (Mid_Price). Wenn der Fehler jedoch auf den gewichteten Mid_Price geändert wird, sinkt er sofort erheblich. Eine weitere Verbesserung wird durch die Verwendung des angepassten gewichteten Mid_Price beobachtet. Nachdem wir Feedback über die Verwendung von nur I ^ 3 / 2 erhalten haben, wurde überprüft und festgestellt, dass die Ergebnisse besser waren. Nach Überlegung ist dies wahrscheinlich auf die unterschiedlichen Ereignisfrequenzen zurückzuführen. Wenn I nahe bei -1 und 1 liegt, stellt es Ereignisse mit geringer Wahrscheinlichkeit dar. Um für diese Ereignisse mit geringer Wahrscheinlichkeit zu korrigieren, wird die Genauigkeit der Vorhersage von Hochfrequenzereignissen beeinträchtigt. Daher wurden einige Anpassungen vorgenommen, um Hochfrequenzereignissen zu priorisieren (diese Parameter waren rein trial-and-error und haben eine begrenzte praktische Bedeutung im Live-Trading).
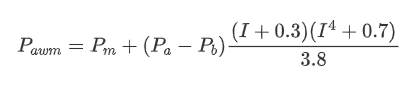
Die Ergebnisse haben sich leicht verbessert. Wie im vorherigen Artikel erwähnt, sollten sich Strategien für die Vorhersage auf mehr Daten stützen. Mit der Verfügbarkeit von mehr Tiefen- und Auftragstransaktionsdaten ist die Verbesserung durch die Fokussierung auf das Auftragsbuch bereits schwach.
In [15]:
df = pd.merge_asof(trades, depths, on='transact_time', direction='backward')
In [17]:
df['spread'] = round(df['ask_0_price'] - df['bid_0_price'],4)
df['mid_price'] = (df['bid_0_price']+ df['ask_0_price']) / 2
df['I'] = (df['bid_0_quantity'] - df['ask_0_quantity']) / (df['bid_0_quantity'] + df['ask_0_quantity'])
df['weight_mid_price'] = df['mid_price'] + df['spread']*df['I']/2
df['adjust_mid_price'] = df['mid_price'] + df['spread']*(df['I'])*(df['I']**8+1)/4
df['adjust_mid_price_2'] = df['mid_price'] + df['spread']*df['I']*(df['I']**2+1)/4
df['adjust_mid_price_3'] = df['mid_price'] + df['spread']*df['I']**3/2
df['adjust_mid_price_4'] = df['mid_price'] + df['spread']*(df['I']+0.3)*(df['I']**4+0.7)/3.8
In [18]:
print('Mean value Error in mid_price:', ((df['price']-df['mid_price'])**2).sum())
print('Error of pending order volume weighted mid_price:', ((df['price']-df['weight_mid_price'])**2).sum())
print('The error of the adjusted mid_price:', ((df['price']-df['adjust_mid_price'])**2).sum())
print('The error of the adjusted mid_price_2:', ((df['price']-df['adjust_mid_price_2'])**2).sum())
print('The error of the adjusted mid_price_3:', ((df['price']-df['adjust_mid_price_3'])**2).sum())
print('The error of the adjusted mid_price_4:', ((df['price']-df['adjust_mid_price_4'])**2).sum())
Ausgeschaltet[1]:
Durchschnittlicher Wert Fehler im mittleren Preis: 0,0048751924999999845 Fehler des ausstehenden Auftragsvolumens gewichtet mittelpreis: 0,0048373440193987035 Der Fehler des angepassten mittleren Preises: 0,004803654771638586 Der Fehler des angepassten mittleren_Preises_2: 0,004808216498329721 Der Fehler des angepassten mittleren_Preises_3: 0,004794984755260528 Der Fehler des angepassten mittleren_Preises_4: 0,0047909595497071375
Betrachten wir die zweite Stufe der Tiefe
Wir können dem Ansatz aus dem vorherigen Artikel folgen, um verschiedene Bereiche eines Parameters zu untersuchen und seinen Beitrag zum mittleren Preis anhand der Veränderungen des Transaktionspreises zu messen. Ähnlich wie bei der ersten Tiefenstufe steigt der Transaktionspreis mit zunehmender Wahrscheinlichkeit, was auf einen positiven Beitrag von I hindeutet.
Bei der zweiten Tiefenstufe ergab sich, dass der Effekt zwar etwas kleiner ist als die erste, aber dennoch signifikant ist und nicht ignoriert werden sollte.
Auf der Grundlage der verschiedenen Beiträge werden diesen drei Ebenen der Ungleichgewichtsparameter unterschiedliche Gewichte zugewiesen.
In [19]:
bins = np.linspace(-1, 1, 50)
df['change'] = (df['price'].pct_change().shift(-1))/tick_size
df['I_bins'] = pd.cut(df['I'], bins, labels=bins[1:])
df['I_2'] = (df['bid_1_quantity'] - df['ask_1_quantity']) / (df['bid_1_quantity'] + df['ask_1_quantity'])
df['I_2_bins'] = pd.cut(df['I_2'], bins, labels=bins[1:])
df['I_3'] = (df['bid_2_quantity'] - df['ask_2_quantity']) / (df['bid_2_quantity'] + df['ask_2_quantity'])
df['I_3_bins'] = pd.cut(df['I_3'], bins, labels=bins[1:])
df['I_4'] = (df['bid_3_quantity'] - df['ask_3_quantity']) / (df['bid_3_quantity'] + df['ask_3_quantity'])
df['I_4_bins'] = pd.cut(df['I_4'], bins, labels=bins[1:])
fig, axes = plt.subplots(nrows=2, ncols=2, figsize=(8, 5))
axes[0][0].plot(df.groupby('I_bins')['change'].mean())
axes[0][0].set_title('I')
axes[0][0].grid(True)
axes[0][1].plot(df.groupby('I_2_bins')['change'].mean())
axes[0][1].set_title('I 2')
axes[0][1].grid(True)
axes[1][0].plot(df.groupby('I_3_bins')['change'].mean())
axes[1][0].set_title('I 3')
axes[1][0].grid(True)
axes[1][1].plot(df.groupby('I_4_bins')['change'].mean())
axes[1][1].set_title('I 4')
axes[1][1].grid(True)
plt.tight_layout();
Ausgeschaltet[1]:
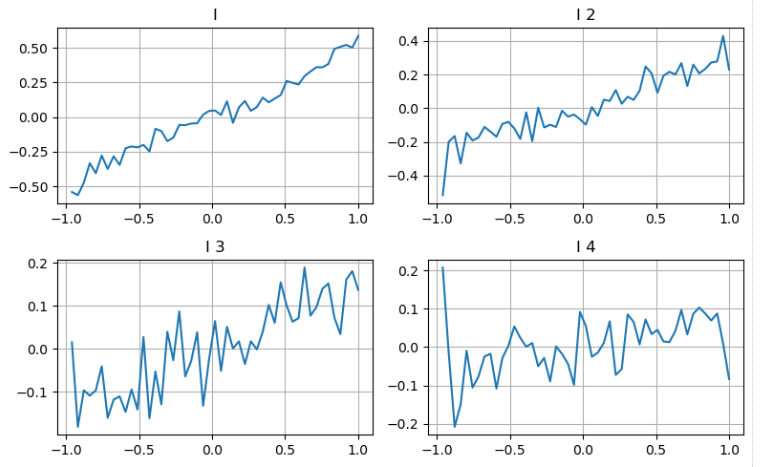
In [20]:
df['adjust_mid_price_4'] = df['mid_price'] + df['spread']*(df['I']+0.3)*(df['I']**4+0.7)/3.8
df['adjust_mid_price_5'] = df['mid_price'] + df['spread']*(0.7*df['I']+0.3*df['I_2'])/2
df['adjust_mid_price_6'] = df['mid_price'] + df['spread']*(0.7*df['I']+0.3*df['I_2'])**3/2
df['adjust_mid_price_7'] = df['mid_price'] + df['spread']*(0.7*df['I']+0.3*df['I_2']+0.3)*((0.7*df['I']+0.3*df['I_2'])**4+0.7)/3.8
df['adjust_mid_price_8'] = df['mid_price'] + df['spread']*(0.7*df['I']+0.2*df['I_2']+0.1*df['I_3']+0.3)*((0.7*df['I']+0.3*df['I_2']+0.1*df['I_3'])**4+0.7)/3.8
In [21]:
print('The error of the adjusted mid_price_4:', ((df['price']-df['adjust_mid_price_4'])**2).sum())
print('The error of the adjusted mid_price_5:', ((df['price']-df['adjust_mid_price_5'])**2).sum())
print('The error of the adjusted mid_price_6:', ((df['price']-df['adjust_mid_price_6'])**2).sum())
print('The error of the adjusted mid_price_7:', ((df['price']-df['adjust_mid_price_7'])**2).sum())
print('The error of the adjusted mid_price_8:', ((df['price']-df['adjust_mid_price_8'])**2).sum())
Außen [1]:
Der Fehler des angepassten mittleren_Preises_4: 0,0047909595497071375 Der Fehler des angepassten mittleren_Preises_5: 0,0047884350488318714 Der Fehler des angepassten mittleren_Preises_6: 0,0047778319053133735 Der Fehler des angepassten mittleren_Preises_7: 0,004773578540592192 Der Fehler des angepassten mittleren_Preises_8: 0,004771415189297518
Berücksichtigung der Transaktionsdaten
Transaktionsdaten spiegeln direkt das Ausmaß von Long- und Short-Positionen wider. Schließlich beinhalten Transaktionen echtes Geld, während die Auftragserteilung viel geringere Kosten hat und sogar absichtliche Täuschung beinhalten kann. Daher sollten sich Strategien bei der Vorhersage des mittleren Preises auf die Transaktionsdaten konzentrieren.
In Form können wir das Ungleichgewicht der durchschnittlichen Auftragsmenge als VI definieren, wobei Vb und Vs die durchschnittliche Menge der Kauf- und Verkaufsbestellungen innerhalb eines Zeitintervalls darstellen.
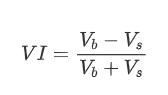
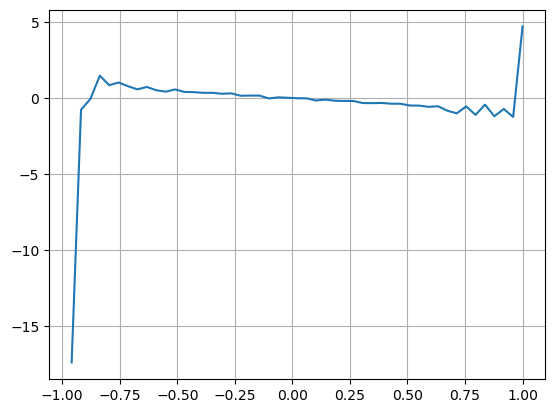
Die Ergebnisse zeigen, dass die Ankunftsmenge in einem kurzen Zeitraum den größten Einfluss auf die Preisänderungsvorhersage hat. Wenn VI zwischen 0,1 und 0,9 liegt, ist sie negativ mit dem Preis korreliert, während sie außerhalb dieses Bereichs positiv mit dem Preis korreliert. Dies deutet darauf hin, dass der Preis, wenn der Markt nicht extrem ist und hauptsächlich oszilliert, dazu neigt, zum Durchschnitt zurückzukehren. In extremen Marktbedingungen jedoch tritt ein Trend auf, wenn es eine große Anzahl von Kaufordern gibt, die Verkaufsordern überwältigen. Selbst ohne Berücksichtigung dieser Szenarien mit geringer Wahrscheinlichkeit reduziert die Annahme einer negativen linearen Beziehung zwischen dem Trend und VI das Vorhersagungsfehler des mittleren Preises erheblich. Der Koeffizient
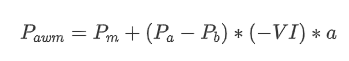
In [22]:
alpha=0.1
In [23]:
df['avg_buy_interval'] = None
df['avg_sell_interval'] = None
df.loc[df['is_buyer_maker'] == True, 'avg_buy_interval'] = df[df['is_buyer_maker'] == True]['transact_time'].diff().ewm(alpha=alpha).mean()
df.loc[df['is_buyer_maker'] == False, 'avg_sell_interval'] = df[df['is_buyer_maker'] == False]['transact_time'].diff().ewm(alpha=alpha).mean()
In [24]:
df['avg_buy_quantity'] = None
df['avg_sell_quantity'] = None
df.loc[df['is_buyer_maker'] == True, 'avg_buy_quantity'] = df[df['is_buyer_maker'] == True]['quantity'].ewm(alpha=alpha).mean()
df.loc[df['is_buyer_maker'] == False, 'avg_sell_quantity'] = df[df['is_buyer_maker'] == False]['quantity'].ewm(alpha=alpha).mean()
In [25]:
df['avg_buy_quantity'] = df['avg_buy_quantity'].fillna(method='ffill')
df['avg_sell_quantity'] = df['avg_sell_quantity'].fillna(method='ffill')
df['avg_buy_interval'] = df['avg_buy_interval'].fillna(method='ffill')
df['avg_sell_interval'] = df['avg_sell_interval'].fillna(method='ffill')
df['avg_buy_rate'] = 1000 / df['avg_buy_interval']
df['avg_sell_rate'] =1000 / df['avg_sell_interval']
df['avg_buy_volume'] = df['avg_buy_rate']*df['avg_buy_quantity']
df['avg_sell_volume'] = df['avg_sell_rate']*df['avg_sell_quantity']
In [26]:
df['I'] = (df['bid_0_quantity']- df['ask_0_quantity']) / (df['bid_0_quantity'] + df['ask_0_quantity'])
df['OI'] = (df['avg_buy_rate']-df['avg_sell_rate']) / (df['avg_buy_rate'] + df['avg_sell_rate'])
df['QI'] = (df['avg_buy_quantity']-df['avg_sell_quantity']) / (df['avg_buy_quantity'] + df['avg_sell_quantity'])
df['VI'] = (df['avg_buy_volume']-df['avg_sell_volume']) / (df['avg_buy_volume'] + df['avg_sell_volume'])
In [27]:
bins = np.linspace(-1, 1, 50)
df['VI_bins'] = pd.cut(df['VI'], bins, labels=bins[1:])
plt.plot(df.groupby('VI_bins')['change'].mean());
plt.grid(True)
Ausgeschaltet[1]:
In [28]:
df['adjust_mid_price'] = df['mid_price'] + df['spread']*df['I']/2
df['adjust_mid_price_9'] = df['mid_price'] + df['spread']*(-df['OI'])*2
df['adjust_mid_price_10'] = df['mid_price'] + df['spread']*(-df['VI'])*1.4
In [29]:
print('The error of the adjusted mid_price:', ((df['price']-df['adjust_mid_price'])**2).sum())
print('The error of the adjusted mid_price_9:', ((df['price']-df['adjust_mid_price_9'])**2).sum())
print('The error of the adjusted mid_price_10:', ((df['price']-df['adjust_mid_price_10'])**2).sum())
Ausgeschaltet[29]:
Der Fehler des angepassten mittleren Preises: 0,0048373440193987035 Der Fehler des angepassten mittleren_Preises_9: 0,004629586542840461 Fehler des angepassten mittleren_Preises_10: 0,004401790287167206
Der umfassende Mittelpreis
In Anbetracht der Tatsache, dass sowohl das Ungleichgewicht des Auftragsbuchs als auch die Transaktionsdaten hilfreich sind, um den mittleren Preis vorherzusagen, können wir diese beiden Parameter miteinander kombinieren. Die Zuweisung von Gewichten ist in diesem Fall willkürlich und berücksichtigt keine Grenzbedingungen. In extremen Fällen fällt der vorhergesagte mittlere Preis möglicherweise nicht zwischen den Gebots- und Verkaufspreisen. Solange der Vorhersagefehler jedoch reduziert werden kann, sind diese Details nicht von großem Interesse.
Am Ende wird der Vorhersagefehler von 0,00487 auf 0,0043 reduziert. An dieser Stelle werden wir nicht weiter in das Thema eintauchen. Es gibt noch viele Aspekte zu erforschen, wenn es um die Vorhersage des mittleren Preises geht, da es sich im Wesentlichen um die Vorhersage des Preises selbst handelt. Jeder wird ermutigt, seine eigenen Ansätze und Techniken auszuprobieren.
In [30]:
#Note that the VI needs to be delayed by one to use
df['CI'] = -1.5*df['VI'].shift()+0.7*(0.7*df['I']+0.2*df['I_2']+0.1*df['I_3'])**3
In [31]:
df['adjust_mid_price_11'] = df['mid_price'] + df['spread']*(df['CI'])
print('The error of the adjusted mid_price_11:', ((df['price']-df['adjust_mid_price_11'])**2).sum())
Außen [1]:
Fehler des angepassten mittleren_Preises_11: 0,0043001941412563575
Zusammenfassung
Der Artikel kombiniert Tiefendaten und Transaktionsdaten, um die Berechnungsmethode des mittleren Preises weiter zu verbessern. Es bietet eine Methode zur Messung der Genauigkeit und verbessert die Genauigkeit der Preisänderungsvorhersage. Insgesamt sind die Parameter nicht streng und dienen nur zur Referenz.
- Delta-Hedging für Bitcoin-Optionen mit einer Lächeln-Kurve
- Überlegungen zu Hochfrequenz-Handelsstrategien (4)
- Überlegungen zur Hochfrequenz-Handelstrategie (5)
- Denken Sie über die Strategie des Hochfrequenz-Handels nach (4)
- Überlegungen zu Hochfrequenzhandelsstrategien (3)
- Überlegungen zur Hochfrequenz-Handelsstrategie (3)
- Überlegungen zu Hochfrequenzhandelsstrategien (2)
- Denken Sie über die Strategie des Hochfrequenz-Handels nach.
- Überlegungen zu Hochfrequenzhandelsstrategien (1)
- Denken Sie über die Strategie des Hochfrequenz-Handels nach (1)
- Dokument zur Beschreibung der Konfiguration von Futu Securities