Modellierung und Analyse der Volatilität von Bitcoin auf Basis des ARMA-EGARCH-Modells
Schriftsteller:Lydia., Erstellt: 2022-11-15 15:32:43, Aktualisiert: 2023-09-14 20:30:52ED, und der Prozess wurde weggelassen.
Der Übereinstimmungsgrad der Normalnormalverteilung ist nicht so gut wie die t-Verteilung, was auch zeigt, dass die Ertragsverteilung einen dickeren Schwanz hat als die normale Verteilung.
In [23]:
am_GARCH = arch_model(training_garch, mean='AR', vol='GARCH',
p=1, q=1, lags=3, dist='ged')
res_GARCH = am_GARCH.fit(disp=False, options={'ftol': 1e-01})
res_GARCH.summary()
Außen [1]: Iteration: 1, Funktionszahl: 10, Negativ LLF: -1917.4262154917305
AR - GARCH Modell Ergebnisse
Mittleres Modell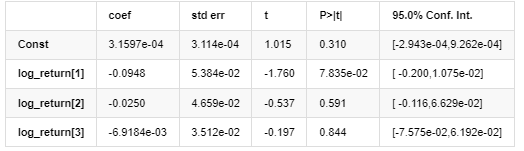
Volatilitätsmodell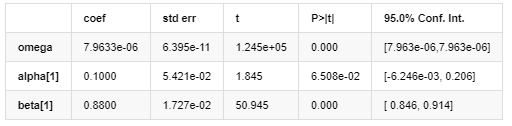
Verteilung
Schätzer der Covarianz: robust
Beschreibung der GARCH-Volatilitätsgleichung gemäß der ARCH-Datenbank: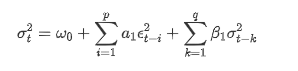
Die bedingte Regressionsgleichung für die Volatilität kann wie folgt ermittelt werden: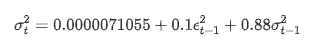
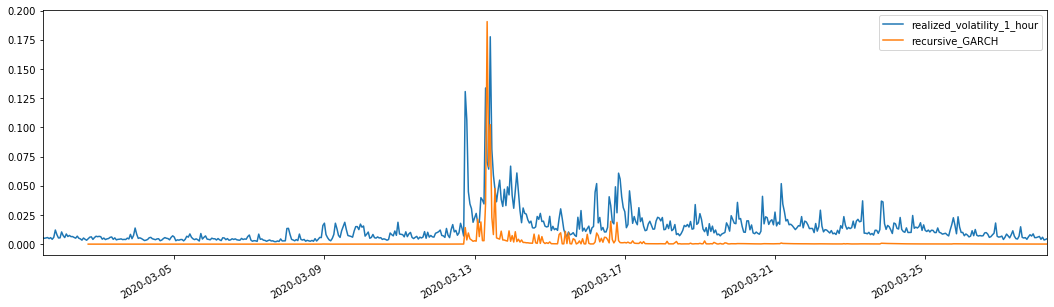
Vergleichen Sie diese Kombination mit der abgeglichenen vorhergesagten Volatilität mit der realisierten Volatilität der Stichprobe, um den Effekt zu ermitteln.
In [26]:
def recursive_forecast(pd_dataframe):
window = predict_lag
model = 'GARCH'
index = kline_test[1:].index
end_loc = np.where(index >= kline_test.index[window])[0].min()
forecasts = {}
for i in range(len(kline_test[1:]) - window + 2):
mod = arch_model(pd_dataframe['log_return'][1:], mean='AR', vol=model, dist='ged',p=1, q=1)
res = mod.fit(last_obs=i+end_loc, disp='off', options={'ftol': 1e03})
temp = res.forecast().variance
fcast = temp.iloc[i + end_loc - 1]
forecasts[fcast.name] = fcast
forecasts = pd.DataFrame(forecasts).T
pd_dataframe['recursive_{}'.format(model)] = forecasts['h.1']
evaluate(pd_dataframe, 'realized_volatility_1_hour', 'recursive_{}'.format(model))
recursive_forecast(kline_test)
Ausgeschaltet[1]: Durchschnittlicher absoluter Fehler (MAE): 0,0128 Durchschnittlicher absoluter Fehleranteil (MAPE): 95,6 Wurzeldurchschnittlicher Quadratfehler (RMSE): 0,018
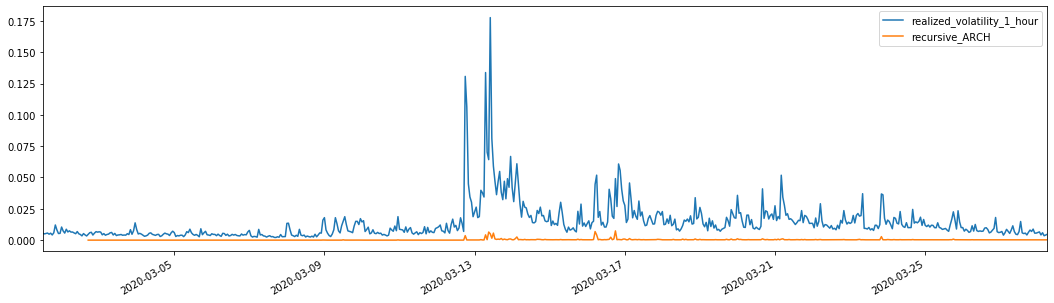
Zum Vergleich: Erstellen Sie folgende ARCH:
In [27]:
def recursive_forecast(pd_dataframe):
window = predict_lag
model = 'ARCH'
index = kline_test[1:].index
end_loc = np.where(index >= kline_test.index[window])[0].min()
forecasts = {}
for i in range(len(kline_test[1:]) - window + 2):
mod = arch_model(pd_dataframe['log_return'][1:], mean='AR', vol=model, dist='ged', p=1)
res = mod.fit(last_obs=i+end_loc, disp='off', options={'ftol': 1e03})
temp = res.forecast().variance
fcast = temp.iloc[i + end_loc - 1]
forecasts[fcast.name] = fcast
forecasts = pd.DataFrame(forecasts).T
pd_dataframe['recursive_{}'.format(model)] = forecasts['h.1']
evaluate(pd_dataframe, 'realized_volatility_1_hour', 'recursive_{}'.format(model))
recursive_forecast(kline_test)
Ausgeschaltet[1]: Durchschnittlicher absoluter Fehler (MAE): 0,0136 Durchschnittlicher absoluter Fehleranteil (MAPE): 98,1 Wurzeldurchschnittlicher Quadratfehler (RMSE): 0,02
7. EGARCH-Modellierung
Der nächste Schritt besteht darin, EGARCH-Modellierung durchzuführen
In [24]:
am_EGARCH = arch_model(training_egarch, mean='AR', vol='EGARCH',
p=1, lags=3, o=1,q=1, dist='ged')
res_EGARCH = am_EGARCH.fit(disp=False, options={'ftol': 1e-01})
res_EGARCH.summary()
Außen [1]: Ich habe das Gefühl, dass ich das nicht kann.
AR - EGARCH Modell Ergebnisse
Mittleres Modell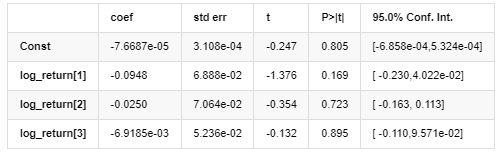
Volatilitätsmodell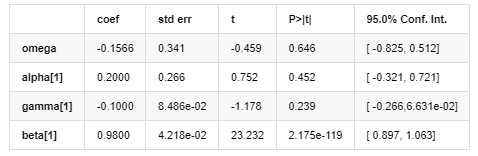
Verteilung
Schätzer der Covarianz: robust
Die von der ARCH-Bibliothek bereitgestellte EGARCH-Volatilitätsgleichung ist wie folgt beschrieben: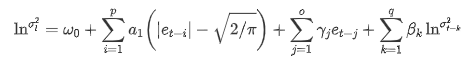
Ersatz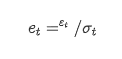
Die bedingte Regressionsgleichung der Volatilität kann wie folgt ermittelt werden: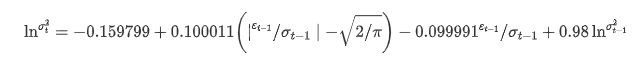
Unter ihnen ist der geschätzte Koeffizient des symmetrischen Begriffs γ kleiner als der Konfidenzintervall, was darauf hindeutet, dass es eine signifikante
In Kombination mit der abgeglichenen prognostizierten Volatilität werden die Ergebnisse wie folgt mit der realisierten Volatilität der Stichprobe verglichen:
In [28]:
def recursive_forecast(pd_dataframe):
window = 280
model = 'EGARCH'
index = kline_test[1:].index
end_loc = np.where(index >= kline_test.index[window])[0].min()
forecasts = {}
for i in range(len(kline_test[1:]) - window + 2):
mod = arch_model(pd_dataframe['log_return'][1:], mean='AR', vol=model,
lags=3, p=2, o=0, q=1, dist='ged')
res = mod.fit(last_obs=i+end_loc, disp='off', options={'ftol': 1e03})
temp = res.forecast().variance
fcast = temp.iloc[i + end_loc - 1]
forecasts[fcast.name] = fcast
forecasts = pd.DataFrame(forecasts).T
pd_dataframe['recursive_{}'.format(model)] = forecasts['h.1']
evaluate(pd_dataframe, 'realized_volatility_1_hour', 'recursive_{}'.format(model))
pd_dataframe['recursive_{}'.format(model)]
recursive_forecast(kline_test)
Ausgeschaltet[28]: Durchschnittlicher absoluter Fehler (MAE): 0,0201 Durchschnittlicher absoluter Fehleranteil (MAPE): 122 Wurzeldurchschnittlicher Quadratfehler (RMSE): 0,0279
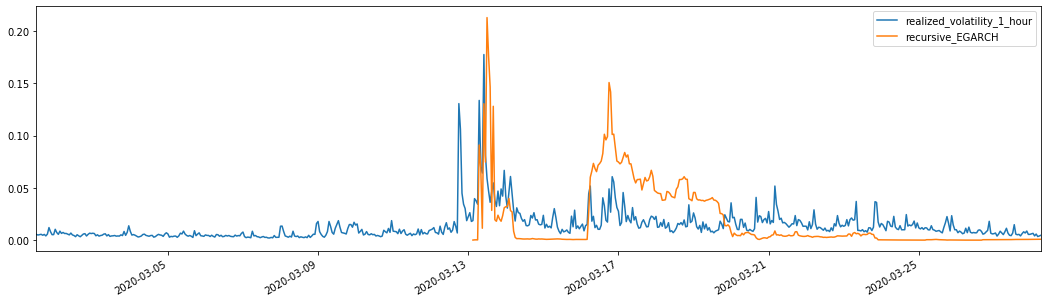
Es kann festgestellt werden, dass EGARCH empfindlicher auf Volatilität reagiert und besser mit Volatilität übereinstimmt als ARCH und GARCH.
8. Bewertung der Volatilitätsprognose
Die Stundendaten werden auf der Grundlage der Stichprobe ausgewählt, und der nächste Schritt besteht darin, eine Stunde vorauszusagen. Wir wählen die vorhergesagte Volatilität der ersten 10 Stunden der drei Modelle aus, wobei RV die Benchmark-Volatilität ist. Der vergleichende Fehlerwert ist wie folgt:
In [29]:
compare_ARCH_X = pd.DataFrame()
compare_ARCH_X['original']=kline_test['realized_volatility_1_hour']
compare_ARCH_X['arch']=kline_test['recursive_ARCH']
compare_ARCH_X['arch_diff']=compare_ARCH_X['original']-np.abs(compare_ARCH_X['arch'])
compare_ARCH_X['garch']=kline_test['recursive_GARCH']
compare_ARCH_X['garch_diff']=compare_ARCH_X['original']-np.abs(compare_ARCH_X['garch'])
compare_ARCH_X['egarch']=kline_test['recursive_EGARCH']
compare_ARCH_X['egarch_diff']=compare_ARCH_X['original']-np.abs(compare_ARCH_X['egarch'])
compare_ARCH_X = compare_ARCH_X[280:]
compare_ARCH_X.head(10)
Ausgeschaltet[29]: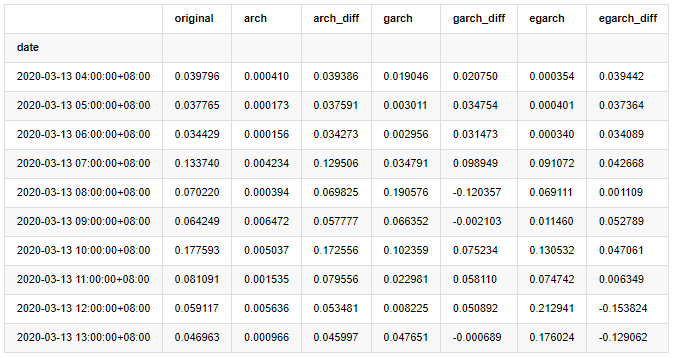
In [30]:
compare_ARCH_X_diff = pd.DataFrame(index=['ARCH','GARCH','EGARCH'], columns=['head 1 step', 'head 10 steps', 'head 100 steps'])
compare_ARCH_X_diff['head 1 step']['ARCH'] = compare_ARCH_X['arch_diff']['2020-03-13 04:00:00+08:00']
compare_ARCH_X_diff['head 10 steps']['ARCH'] = np.mean(compare_ARCH_X['arch_diff'][:10])
compare_ARCH_X_diff['head 100 steps']['ARCH'] = np.mean(compare_ARCH_X['arch_diff'][:100])
compare_ARCH_X_diff['head 1 step']['GARCH'] = compare_ARCH_X['garch_diff']['2020-03-13 04:00:00+08:00']
compare_ARCH_X_diff['head 10 steps']['GARCH'] = np.mean(compare_ARCH_X['garch_diff'][:10])
compare_ARCH_X_diff['head 100 steps']['GARCH'] = np.mean(compare_ARCH_X['garch_diff'][:100])
compare_ARCH_X_diff['head 1 step']['EGARCH'] = compare_ARCH_X['egarch_diff']['2020-03-13 04:00:00+08:00']
compare_ARCH_X_diff['head 10 steps']['EGARCH'] = np.mean(compare_ARCH_X['egarch_diff'][:10])
compare_ARCH_X_diff['head 100 steps']['EGARCH'] = np.abs(np.mean(compare_ARCH_X['egarch_diff'][:100]))
compare_ARCH_X_diff
Ausgeschaltet[30]: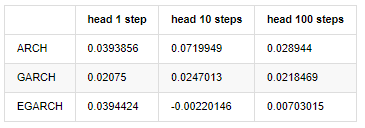
Es wurden mehrere Tests durchgeführt, in den Vorhersageergebnissen der ersten Stunde ist die Wahrscheinlichkeit des kleinsten Fehlers von EGARCH relativ groß, aber der Gesamtunterschied ist nicht besonders offensichtlich; Es gibt einige offensichtliche Unterschiede in den kurzfristigen Vorhersageeffekten; EGARCH hat die herausragendste Vorhersagefähigkeit in der Langzeitvorhersage
In [31]:
compare_ARCH_X = pd.DataFrame()
compare_ARCH_X['Model'] = ['ARCH','GARCH','EGARCH']
compare_ARCH_X['RMSE'] = [get_rmse(kline_test['realized_volatility_1_hour'][280:320],kline_test['recursive_ARCH'][280:320]),
get_rmse(kline_test['realized_volatility_1_hour'][280:320],kline_test['recursive_GARCH'][280:320]),
get_rmse(kline_test['realized_volatility_1_hour'][280:320],kline_test['recursive_EGARCH'][280:320])]
compare_ARCH_X['MAPE'] = [get_mape(kline_test['realized_volatility_1_hour'][280:320],kline_test['recursive_ARCH'][280:320]),
get_mape(kline_test['realized_volatility_1_hour'][280:320],kline_test['recursive_GARCH'][280:320]),
get_mape(kline_test['realized_volatility_1_hour'][280:320],kline_test['recursive_EGARCH'][280:320])]
compare_ARCH_X['MASE'] = [get_mape(kline_test['realized_volatility_1_hour'][280:320],kline_test['recursive_ARCH'][280:320]),
get_mape(kline_test['realized_volatility_1_hour'][280:320],kline_test['recursive_GARCH'][280:320]),
get_mape(kline_test['realized_volatility_1_hour'][280:320],kline_test['recursive_EGARCH'][280:320])]
compare_ARCH_X
Außen [1]: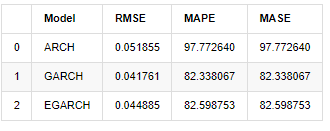
In Bezug auf die Indikatoren haben GARCH und EGARCH eine gewisse Verbesserung im Vergleich zu ARCH, aber der Unterschied ist nicht besonders offensichtlich.
9. Schlussfolgerung
Aus der obigen einfachen Analyse kann festgestellt werden, dass die logarithmische Rendite von Bitcoin nicht mit der normalen Verteilung übereinstimmt, die durch dicke Fettschwänze gekennzeichnet ist, und die Volatilität Aggregation und Hebelwirkung hat, während sie eine offensichtliche bedingte Heterogenität aufweist.
Bei der Vorhersage und Bewertung der logarithmischen Rendite ist die statische Vorhersagekraft des ARMA-Modells innerhalb der Stichprobe deutlich besser als die dynamischen, was zeigt, dass die Rollmethode offensichtlich besser ist als die iterative Methode und die Probleme der Überschneidung und Fehlerverstärkung vermeiden kann.
Darüber hinaus ist bei der Bewältigung des Phänomens des dicken Schwanzes von Bitcoin, d.h. der dicken Schwankverteilung der Renditen, festgestellt, dass die GED-Verteilung (generalisierter Fehler) besser ist als die t-Verteilung und die normale Verteilung, was die Messgenauigkeit des Schwankrisikos erheblich verbessern kann. Gleichzeitig hat EGARCH mehr Vorteile bei der Vorhersage langfristiger Volatilität, was die Heteroscedastik der Stichprobe gut erklärt. Der symmetrische Schätzkoeffizient in der Modellmatching ist kleiner als der Konfidenzintervall, was darauf hindeutet, dass es eine signifikante
Der gesamte Modellierungsprozess ist voll von verschiedenen kühnen Annahmen, und es gibt keine Konsistenz-Identifizierung abhängig von der Gültigkeit, so dass wir nur einige Phänomene sorgfältig überprüfen können.
Im Vergleich zu traditionellen Märkten ist die Verfügbarkeit von Hochfrequenzdaten von Bitcoin einfacher. Die
Allerdings beschränkt sich das oben genannte auf die Theorie. Höhere Frequenzdaten können tatsächlich eine genauere Analyse des Verhaltens von Händlern liefern. Sie können nicht nur zuverlässigere Tests für finanzielle theoretische Modelle liefern, sondern auch reichhaltigere Entscheidungsinformationen für Händler liefern, sogar die Vorhersage von Informationsfluss und Kapitalfluss unterstützen und bei der Gestaltung präziserer quantitativer Handelsstrategien helfen. Der Bitcoin-Markt ist jedoch so volatil, dass zu lange historische Daten nicht mit effektiven Entscheidungsinformationen übereinstimmen können, so dass hochfrequente Daten Investoren von digitaler Währung sicherlich größere Marktvorteile bringen werden.
Schließlich, wenn Sie den obigen Inhalt hilfreich finden, können Sie mir auch ein wenig BTC anbieten, um mir eine Tasse Cola zu kaufen.
- Quantifizierung der Fundamentalanalyse auf dem Kryptowährungsmarkt: Die Daten sprechen für sich!
- Die Quantifizierung der Kernforschung der Münzkreise - nicht mehr auf alle Arten von Lehrern zu vertrauen, die überzeugt sind, dass die Daten objektiv sind!
- Ein wichtiges Werkzeug im Bereich der Quantitative Transaktionen - der Erfinder der Quantitative Data Exploration Module
- Mastering Everything - Einführung in FMZ Neue Version des Handelsterminals (mit TRB Arbitrage Source Code)
- Die neue Version des FMZ-Trading-Terminals ist verfügbar.
- FMZ Quant: Eine Analyse von gemeinsamen Anforderungen Designbeispielen auf dem Kryptowährungsmarkt (II)
- Wie man Hirnlose Verkaufs-Bots mit einer Hochfrequenz-Strategie in 80 Codezeilen ausnutzt
- FMZ-Quantifizierung: Analyse von Designbeispielen für häufige Bedürfnisse im Kryptowährungsmarkt (II)
- Wie man Hirnlose Roboter ausbeuten und verkaufen kann mit einer 80-Zeilen-code-Hochfrequenz-Strategie
- FMZ Quant: Eine Analyse von gemeinsamen Anforderungen Designbeispielen auf dem Kryptowährungsmarkt (I)
- FMZ-Quantifizierung: Analyse von Designbeispielen für häufige Bedürfnisse im Kryptowährungsmarkt