The Alpha Dog's Tricks: Monte Carlo algorithm, read it and you'll understand!
Author: The Little Dream, Created: 2016-11-02 13:03:03, Updated: 2016-11-02 13:11:30The Alpha Dog's Trick: The Monte Carlo Algorithm, you can read it!
On March 9-15, a major event in the Go world took place, with a five-round battle between humans and machines taking place in Seoul, South Korea. The result of the match was a human defeat, with world champion Lee Hsien Loong defeating Google's AI program AlphaGo by a final score of 1 to 4. So what is AlphaGo and where is the key to winning? Here we will learn about an algorithm: the Monte Carlo algorithm.
-
AlphaGo and the Monte Carlo algorithm
According to Xinhua, the AlphaGo program is a human-robot go-to-go game developed by the DeepMind team of Google Inc. in the United States, jokingly referred to by Chinese chess fans as the Alpha Go-to game.
In a previous article, we talked about the neural network algorithms Google is developing to allow machines to learn autonomously, and AlphaGo is a similar product.
Wang Feiyu, vice-president and secretary-general of the China Association of Automation, said that programmers do not need to be proficient in Go, they just need to know the basic rules of Go. Behind AlphaGo is a group of outstanding computer scientists, more precisely, experts in the field of machine learning. Scientists use neural network algorithms to input the chess expert's game records into the computer and let the computer play against itself, continuously learning in the process.
So where's the key to making AlphaGo a self-learning genius?
What is the Monte Carlo algorithm?The most common explanation for the Monte Carlo algorithm is: If there are 1000 apples in the basket, and you close your eyes every time to find the biggest one, you can choose the number of times without limit. So you can close your eyes and pick one at random, then pick one at random again with the first one, leave it big, then pick one at random again with the previous one, and you can leave it big again. The cycle repeats itself, the more times you pick, the more likely you are to pick the biggest apple, but unless you pick one of the 1,000 apples, you can't be sure that the final pick is the biggest one.
In other words, the Monte Carlo algorithm is that the more samples, the better the solution, but it is not guaranteed to be the best, because if there are 10,000 apples, the bigger the solution will probably be.
He is also the founder of the Las Vegas algorithm, which can be compared to him: It is commonly said that if there is a lock, there are 1000 keys to choose from, but only one is correct. So every time you try to open one key at random, you can't open it. The more times you try, the greater the chance of opening the best, but until you open it, the wrong keys are useless.
So the Las Vegas algorithm is the best possible solution, but not necessarily found. Suppose that out of 1000 keys, none of them can open the lock. The real key is the 1001st key, but the Las Vegas algorithm cannot find the key to open the lock in the sample without the 1001st algorithm.
The Monte Carlo algorithm from AlphaGoThe difficulty of Go is particularly great for AI, because there are so many ways to play Go that it is difficult for the computer to distinguish. First, there are too many possibilities for Go. There are 19 x 19 = 361 different dice to choose from at the start of each step. There are as many as 10,170 possible situations for 150 rounds of Go. Second, the rules are too subtle, and to some extent, the choice of dice depends on the intuition formed by the accumulation of experience.
AlphaGo is not just a Monte Carlo algorithm, it is an upgrade of the Monte Carlo algorithm.
AlphaGo is a collaboration between a Monte Carlo tree search algorithm and two deep neural networks. Prior to the match against Lichtenstein, Google first trained AlphaGo's neural network to predict how a human chess player will play, using nearly 30 million human-to-animal moves.
Their task is to cooperatively pick out the more promising moves, discard the obvious ones, and thus control the computation to the extent that the computer can do. This is essentially the same as what human players do.
According to Yi Jianqiang, a researcher at the Institute of Automation of the Chinese Academy of Sciences, traditional chess software, generally using violent search, including deep blue computers, builds a search tree for all possible results (each result is a fruit on the tree) and performs a search through as needed. This method is also feasible in chess, jumping chess, etc., but not for Go, because the probability of falling is so high that the computer cannot construct the tree fruit (too many lines) to perform a search through. Alpha Go uses a very clever method that solves this problem perfectly.
Tanguchi further explains that one of the most basic units of the deep neural network is similar to neurons in our human brain, with many layers connected as if it were a human neural network. The two neural networks in AlphaGo are the Strategy Network and the Valuation Network.
The strategy network is mainly used to generate a strategy of falling. In the process of chess, it does not think about what it should do, but what a human master would do. That is, it will predict where the next human move will be based on the current state of the board, suggesting several viable solutions that are most consistent with human thinking.
However, the strategic network does not know if the move is good or bad, it only knows if the move is the same as the human one, and then it needs to evaluate the network to play a role.
The network evaluates the entire board for each feasible scenario and then gives a winning margin. These values are then fed back to the Monte Carlo tree search algorithm to infer the highest winning margin by repeating the process. The Monte Carlo tree search algorithm determines that the strategy network will continue to infer only where the winning margin is higher, so that certain routes can be abandoned without a single path to black.
AlphaGo uses these two tools to analyze the situation and judge the merits and demerits of each strategy, just as a human chess player would judge the current situation and infer the future situation. Using the Monte Carlo tree search algorithm to analyze, for example, the next 20 steps, it is possible to determine where the probability of winning is higher.
There is no doubt, however, that the Monte Carlo algorithm is one of the core elements of AlphaGo.
Two small experiments Finally, let's look at two small experiments with Monte Carlo algorithms.
-
1.计算圆周率pi。
Principle: first draw a square, draw its inner circle, then draw a random point inside the square, set the point to fall within the circle to approximately P, so P = area of the circle / area of the square. P is equal to Pi.RR) / ((2R*2R) = Pi/4, which is Pi = 4P
The steps: 1. Place the center of the circle at the origin, and make a circle with R as the radius, and the area of the first quadrant is Pi.RR/4 2. Make the outer square of the 1/4 circle, the coordinates are ((0,0) ((0,R) ((R,0) ((R,R), then the area of the square is RR 3. Take the point ((X,Y) at random, so that 0 <= X <= R and 0 <= Y <= R, i.e. the point is inside the square 4. through the formula xX+YY<RDetermine if R is within 1/4 circle. 5. Set all points (i.e. number of experiments) to N, and the number of points (i.e. points that satisfy step 4) that fall within 1/4 circle to M.
P is equal to M/N, so Pi is 4 times N/M. This is a picture.
This is a picture.
M_C ((10000) runs the result as 3.1424
-
2.蒙特卡洛模拟求函数极值,可避免陷入局部极值
# Randomly generate a number on the interval [-2,2], find its corresponding y, and find the largest value considered to be the greatest value of the function on [-2,2]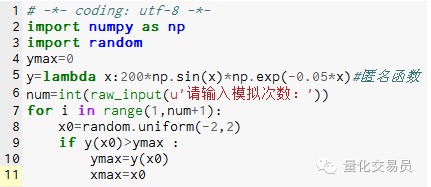 This is the second picture.
This is the second picture.
After 1000 simulations, the extreme value was found to be 185.12292832389875 ((very accurate))
See, guys, you get it. The code can be written by hand. Translated from WeChat
- 2.2 Lower price lists
- 2.1 Use the API to access account information, market data, K-line data, and market depth
- Other functions
- 1.3.4 Robots and strategies
- 1.3.3 The exchange
- 1.3.2 Getting to Know the Trustee
- 1.3.1 Overview and architecture of the main interface
- 1.1 Understand what is a quantitative transaction, a programmatic transaction
- Quantified must read: What exactly is Tick data and why is it so hard to find reliable transaction data?
- Why is there no poloniiex option???
- Can you run over a gorilla with an SVM vector machine?
- Simple SVM classification algorithms
- This is what high-frequency trading used to look like.
- Some of the content of the API documentation (python version) is outdated and needs to be adjusted to avoid misinterpretation.
- There is a problem with the real disk tick.
- Interfaces for trading software
- The data center
- Modifications of Python 2.x.x with Python 3.x.x & Methods of converting Python 2.x.x to Python 3.x.x
- Ice and Fire: Live and retest
- Dry goods - how is high-frequency trading making money?