El arma de AlphaGo: el algoritmo de Monte Carlo. ¡Lo entenderás después de leer esto! (con código de ejemplo)--Reimpresión
 0
23882
0
23882
El algoritmo de Montecarlo, ¡ya lo sabes!
Entre el 9 y el 15 de marzo de este año, un evento importante en el mundo del Go se llevó a cabo en Seúl, Corea del Sur, con una batalla de cinco rondas entre humanos y máquinas. El resultado de la competencia fue una derrota para los humanos, con el campeón mundial de Go, Lee Hsien Loong, derrotado por 1 a 4 por el programa de inteligencia artificial AlphaGo de Google. Entonces, ¿qué es AlphaGo y cuál es la clave para ganar?
- ### AlphaGo y el algoritmo de Monte Carlo
Según Xinhua, AlphaGo es un programa de juego de Go desarrollado por el equipo DeepMind de la compañía estadounidense Google, y es conocido por los fanáticos chinos como “El perro de Alpha”.
En el artículo anterior, mencionamos que Google está desarrollando una red neuronal para que las máquinas aprendan de forma autónoma, y AlphaGo es un producto similar.
El vicepresidente y secretario general de la Asociación de Automatización de China, Wang Fiyun, dijo que los programadores no necesitan ser expertos en el juego de go, solo necesitan conocer las reglas básicas del juego. Detrás de AlphaGo hay un grupo de destacados científicos informáticos, específicamente expertos en el campo del aprendizaje automático.
Entonces, ¿cuál es la clave para que AlphaGo se auto-aprendizaje y se convierta en un genio?
¿Qué es el algoritmo de Monte Carlo? El algoritmo de Montecarlo es un método muy popular que se utiliza para explicar el problema de las monedas. Si hay 1000 manzanas en una canasta, para que encuentres la más grande cada vez que cierres los ojos, no hay límite en la cantidad de veces que puedes elegir. Así que puedes elegir una al azar con los ojos cerrados, y luego comparar otra al azar con la primera, dejando la más grande, y otra al azar, comparándola con la anterior, dejando la más grande.
Es decir, el algoritmo de Montecarlo es que cuantas más muestras hay, más soluciones se encuentran, pero no garantiza que sea la mejor, porque si hay 10.000 manzanas, es probable que se encuentre una más grande.
El algoritmo de Las Vegas, por su parte, es una comparación: Se suele decir que si hay una cerradura, hay 1000 llaves para elegir, pero sólo una es la correcta. Así que cada vez que se toma una llave al azar para intentar abrirla y no se abre, se cambia una.
Por lo tanto, el algoritmo de Las Vegas es la mejor solución posible, pero no necesariamente se puede encontrar. Supongamos que de 1000 llaves, no se puede abrir ninguna llave, la verdadera llave es la llave 1001, pero en la muestra no hay el algoritmo 1001, el algoritmo de Las Vegas no puede encontrar la llave para abrir la cerradura.
El algoritmo Monte Carlo de AlphaGo La dificultad del juego de Go es especialmente grande para la inteligencia artificial, ya que el juego de Go tiene demasiadas formas de jugar que es difícil para las computadoras distinguir. Wang Leung dijo: En primer lugar, el juego de go es muy probable Cada paso del juego de go es muy probable, el jugador tiene 19 × 19 = 361 opciones de caídas cuando comienza En una partida de 150 vueltas de go pueden aparecer hasta 10170 situaciones En segundo lugar, la regla es demasiado delicada, en cierta medida la elección de caídas depende de la intuición que se forma a partir de la acumulación de experiencia Además, en la partida de go, es difícil para la computadora distinguir las ventajas y las debilidades de la partida de go Por lo tanto, el desafío de go se llama el plan de Apolo de la inteligencia artificial
AlphaGo no es solo un algoritmo de Monte Carlo, sino que es una versión mejorada de él.
AlphaGo trabaja con un algoritmo de búsqueda de árboles de Monte Carlo y dos redes neuronales de profundidad para completar el juego de ajedrez. Antes de enfrentarse a Lee Hsien Loong, Google primero entrenó a la red neuronal de AlphaGo Dog con casi 30 millones de pasos de pares humanos para que aprendiera a predecir cómo fallarían los jugadores profesionales humanos. Más adelante, AlphaGo jugó a su propio juego de ajedrez, lo que generó una nueva carta de ajedrez de gran escala.
Su tarea consiste en seleccionar las jugadas más prometedoras y dejar de lado las jugadas evidentemente deficientes, para así limitar el cálculo al alcance de la computadora. En esencia, esto es lo mismo que hacen los jugadores de ajedrez humanos, dijo Zhang Gaoqi, doctorado en el Instituto de Automatización de la Academia de Ciencias de China.
El investigador de la Academia de Ciencias de China, Yi Jianqiang, dijo que el software tradicional de juegos de azar de Liu, generalmente usa búsquedas violentas, incluida la computadora azul profunda, que crea un árbol de búsqueda para todos los resultados posibles (cada resultado es una fruta del árbol), y realiza búsquedas de recorrido según sea necesario. Este método también es factible en el ajedrez, el salto y otros juegos, pero no para el go, ya que el go tiene 19 líneas y la posibilidad de caídas es tan grande que la computadora no puede construir el árbol (hay demasiadas frutas) para realizar una búsqueda de recorrido.
Yugachi explica además que la unidad más básica de la red neuronal profunda es similar a las neuronas de nuestro cerebro humano, con muchas capas conectadas como si fuera una red neuronal en el cerebro humano. Las dos redes neuronales de AlphaGo son la red de estrategia y la red de valoración.
La red de estrategias de juego de cartas se utiliza principalmente para generar estrategias de caída. En el proceso de jugar al ajedrez, no considera cómo debería salir, sino qué pasaría con la mano alta de los humanos. Es decir, predicirá dónde jugará el próximo ajedrez de los humanos según el estado actual del tablero de entrada y propondrá varias soluciones viables que mejor se ajusten a la mentalidad humana.
Sin embargo, la red estratégica no sabe si el movimiento que está haciendo es bueno o malo, solo sabe si es el mismo que el movimiento humano, y es entonces cuando la red de valoración funciona.
La red de valoración de las cartas evalúa el conjunto de la tabla para cada opción viable, y luego da una tabla de ganancias. Estos valores se reflejan en el algoritmo de búsqueda de árboles de Monte Carlo, que presenta el camino con la mayor cantidad de ganancias por el proceso repetido. El algoritmo de búsqueda de árboles de Monte Carlo determina que la red de estrategias solo continuará con la mayor cantidad de ganancias, de modo que se pueden descartar ciertas rutas y no se necesita un camino para llegar a las negras.
AlphaGo utiliza estas dos herramientas para analizar la situación y determinar las ventajas y desventajas de cada estrategia subyacente, al igual que un jugador de ajedrez humano puede evaluar la situación actual y inferir la situación futura. Utilizando el algoritmo de búsqueda de árboles de Monte Carlo para analizar, por ejemplo, los próximos 20 pasos, se puede determinar dónde la probabilidad de ganar la subyacente es alta.
Sin embargo, no hay duda de que el algoritmo de Monte Carlo es uno de los pilares de AlphaGo.
Dos pequeñas experiencias Por último, veamos dos pequeños experimentos con el algoritmo de Montecarlo:
- ### 1. Calcular el promedio de circunferencia de pi.
Principio: Dibuja un cuadrado, dibuja el círculo de corte, y luego el punto de dibujo aleatorio dentro del cuadrado, el punto de ajuste se encuentra dentro del círculo como P, entonces P = área del círculo / área del cuadrado. P=(Pi*R*R)/(2R*2R) = Pi/4, es decir Pi = 4P
Qué hacer: 1. Coloque el centro de la circunferencia en el punto de partida y haga una circunferencia con R como radio, entonces el área de 1⁄4 de la circunferencia en el primer cuadrante es Pi*R*R/4 2. Hacer el cuadrado exterior de este 1 / 4 círculo, las coordenadas son ((0,0) ((0,R) ((R,0) ((R,R), el área del cuadrado es R*R 3. tomando el punto ((X, Y), de modo que 0 <= X <= R y 0 <= Y <= R, es decir, el punto está dentro del cuadrado 4. Por la fórmula X*X+Y*Y*R determina si el punto está dentro de 1⁄4 de la circunferencia. 5. Si el número de todos los puntos (es decir, el número de experimentos) es N y el número de los puntos que caen dentro del círculo de 1 / 4 (es decir, los puntos que satisfacen el paso 4) es M, entonces
P es igual a M/N y Pi es igual a 4.*N/M
 Imagen 1 de las imágenes
Imagen 1 de las imágenes
El resultado de la operación M_C(10000) es 3.1424
- ### 2. La simulación de Montecarlo busca los extremos de la función para evitar caer en los extremos locales
# En el espacio[-2,2] generar un número al azar, encontrar su correspondiente y, encontrar el más grande dentro de que se considera la función en[El valor máximo de -2,2]
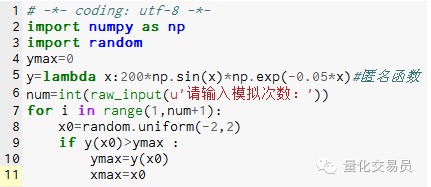 La imagen 2
La imagen 2
Después de 1000 simulaciones, se encontró un valor máximo de 185.12292832389875 (muy preciso)
¡Qué divertido, el código se puede escribir a mano! Se publicó en el sitio web de WeChat.