Opiniones sobre las estrategias de negociación de alta frecuencia (5)
El autor:- ¿ Por qué?, Creado: 2023-08-10 15:57:27, Actualizado: 2023-09-12 15:51:54
Opiniones sobre las estrategias de negociación de alta frecuencia (5)
En el artículo anterior, se introdujeron varios métodos para calcular el precio medio, y se propuso un precio medio revisado.
Datos requeridos
Necesitamos datos de flujo de pedidos y datos de profundidad para los diez niveles superiores de la carpeta de pedidos, recopilados de operaciones en vivo con una frecuencia de actualización de 100 ms. Por razones de simplicidad, no incluiremos actualizaciones en tiempo real para los precios de oferta y demanda. Para reducir el tamaño de los datos, solo hemos mantenido 100,000 filas de datos de profundidad y separado los datos de mercado tick-by-tick en columnas individuales.
En [1]:
from datetime import date,datetime
import time
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import ast
%matplotlib inline
En [2]:
tick_size = 0.0001
En [3]:
trades = pd.read_csv('YGGUSDT_aggTrade.csv',names=['type','event_time', 'agg_trade_id','symbol', 'price', 'quantity', 'first_trade_id', 'last_trade_id',
'transact_time', 'is_buyer_maker'])
En [4]:
trades = trades.groupby(['transact_time','is_buyer_maker']).agg({
'transact_time':'last',
'agg_trade_id': 'last',
'price': 'first',
'quantity': 'sum',
'first_trade_id': 'first',
'last_trade_id': 'last',
'is_buyer_maker': 'last',
})
En [5]:
trades.index = pd.to_datetime(trades['transact_time'], unit='ms')
trades.index.rename('time', inplace=True)
trades['interval'] = trades['transact_time'] - trades['transact_time'].shift()
En [6]:
depths = pd.read_csv('YGGUSDT_depth.csv',names=['type','event_time', 'transact_time','symbol', 'u1', 'u2', 'u3', 'bids','asks'])
En [7]:
depths = depths.iloc[:100000]
En [8]:
depths['bids'] = depths['bids'].apply(ast.literal_eval).copy()
depths['asks'] = depths['asks'].apply(ast.literal_eval).copy()
En [9]:
def expand_bid(bid_data):
expanded = {}
for j, (price, quantity) in enumerate(bid_data):
expanded[f'bid_{j}_price'] = float(price)
expanded[f'bid_{j}_quantity'] = float(quantity)
return pd.Series(expanded)
def expand_ask(ask_data):
expanded = {}
for j, (price, quantity) in enumerate(ask_data):
expanded[f'ask_{j}_price'] = float(price)
expanded[f'ask_{j}_quantity'] = float(quantity)
return pd.Series(expanded)
# Apply to each line to get a new df
expanded_df_bid = depths['bids'].apply(expand_bid)
expanded_df_ask = depths['asks'].apply(expand_ask)
# Expansion on the original df
depths = pd.concat([depths, expanded_df_bid, expanded_df_ask], axis=1)
En el [10]:
depths.index = pd.to_datetime(depths['transact_time'], unit='ms')
depths.index.rename('time', inplace=True);
En [11]:
trades = trades[trades['transact_time'] < depths['transact_time'].iloc[-1]]
Si se observa la distribución del mercado en estos 20 niveles, está en línea con las expectativas, con más órdenes colocadas cuanto más alejadas del precio del mercado.
En [14]:
bid_mean_list = []
ask_mean_list = []
for i in range(20):
bid_mean_list.append(round(depths[f'bid_{i}_quantity'].mean(),0))
ask_mean_list.append(round(depths[f'ask_{i}_quantity'].mean(),0))
plt.figure(figsize=(10, 5))
plt.plot(bid_mean_list);
plt.plot(ask_mean_list);
plt.grid(True)
Fuera [1]:
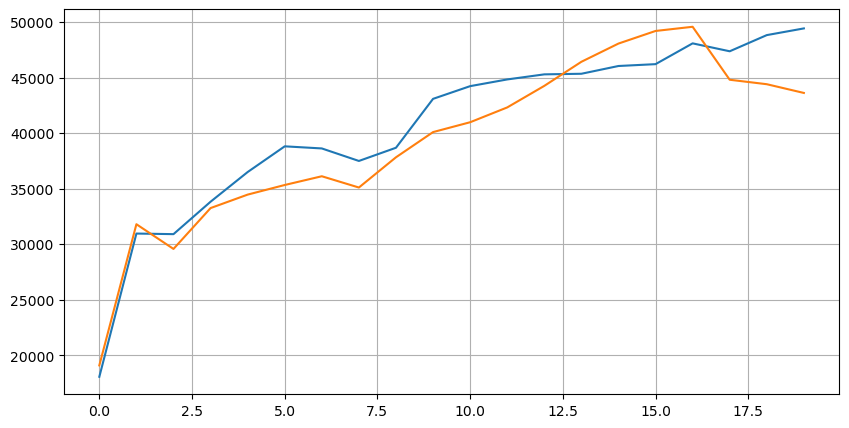
Combinar los datos de profundidad con los datos de transacción para facilitar la evaluación de la precisión de la predicción. Asegúrese de que los datos de transacción sean posteriores a los datos de profundidad. Sin tener en cuenta la latencia, calcule directamente el error cuadrado medio entre el valor predicho y el precio real de la transacción. Esto se utiliza para medir la precisión de la predicción.
De los resultados, el error es más alto para el valor promedio de los precios de oferta y demanda (mid_price). Sin embargo, cuando se cambia al precio medio ponderado, el error disminuye inmediatamente significativamente. Se observa una mejora adicional mediante el uso del precio medio ponderado ajustado. Después de recibir comentarios sobre el uso de I^3/2 solo, se comprobó y se encontró que los resultados eran mejores. Tras la reflexión, esto es probable debido a las diferentes frecuencias de eventos. Cuando I está cerca de -1 y 1, representa eventos de baja probabilidad. Para corregir estos eventos de baja probabilidad, la precisión de predecir eventos de alta frecuencia se ve comprometida. Por lo tanto, para priorizar los eventos de alta frecuencia, se realizaron algunos ajustes (estos parámetros fueron puramente de prueba y error y tienen un significado práctico limitado en el comercio en vivo).
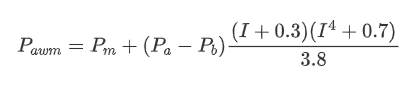
Los resultados han mejorado ligeramente. Como se mencionó en el artículo anterior, las estrategias deben basarse en más datos para la predicción. Con la disponibilidad de más datos de profundidad y transacción de pedidos, la mejora obtenida al centrarse en el libro de pedidos ya es débil.
En [15]:
df = pd.merge_asof(trades, depths, on='transact_time', direction='backward')
En [17]:
df['spread'] = round(df['ask_0_price'] - df['bid_0_price'],4)
df['mid_price'] = (df['bid_0_price']+ df['ask_0_price']) / 2
df['I'] = (df['bid_0_quantity'] - df['ask_0_quantity']) / (df['bid_0_quantity'] + df['ask_0_quantity'])
df['weight_mid_price'] = df['mid_price'] + df['spread']*df['I']/2
df['adjust_mid_price'] = df['mid_price'] + df['spread']*(df['I'])*(df['I']**8+1)/4
df['adjust_mid_price_2'] = df['mid_price'] + df['spread']*df['I']*(df['I']**2+1)/4
df['adjust_mid_price_3'] = df['mid_price'] + df['spread']*df['I']**3/2
df['adjust_mid_price_4'] = df['mid_price'] + df['spread']*(df['I']+0.3)*(df['I']**4+0.7)/3.8
En el [18]:
print('Mean value Error in mid_price:', ((df['price']-df['mid_price'])**2).sum())
print('Error of pending order volume weighted mid_price:', ((df['price']-df['weight_mid_price'])**2).sum())
print('The error of the adjusted mid_price:', ((df['price']-df['adjust_mid_price'])**2).sum())
print('The error of the adjusted mid_price_2:', ((df['price']-df['adjust_mid_price_2'])**2).sum())
print('The error of the adjusted mid_price_3:', ((df['price']-df['adjust_mid_price_3'])**2).sum())
print('The error of the adjusted mid_price_4:', ((df['price']-df['adjust_mid_price_4'])**2).sum())
Fuera [1]:
Valor medio Error en el precio medio: 0.0048751924999999845 Error del volumen de orden pendiente ponderado en el precio medio: 0,0048373440193987035 El error del precio medio ajustado: 0,004803654771638586 Error del precio medio ajustado: 0,004808216498329721 Error del precio medio ajustado: 0,004794984755260528 Error del precio medio ajustado: 0,0047909595497071375
Consideremos el segundo nivel de profundidad
Podemos seguir el enfoque del artículo anterior para examinar diferentes rangos de un parámetro y medir su contribución al precio medio basado en los cambios en el precio de la transacción.
Aplicando el mismo enfoque al segundo nivel de profundidad, encontramos que aunque el efecto es ligeramente menor que el primer nivel, sigue siendo significativo y no debe ignorarse.
En base a las diferentes contribuciones, asignamos diferentes pesos a estos tres niveles de parámetros de desequilibrio.
En [19]:
bins = np.linspace(-1, 1, 50)
df['change'] = (df['price'].pct_change().shift(-1))/tick_size
df['I_bins'] = pd.cut(df['I'], bins, labels=bins[1:])
df['I_2'] = (df['bid_1_quantity'] - df['ask_1_quantity']) / (df['bid_1_quantity'] + df['ask_1_quantity'])
df['I_2_bins'] = pd.cut(df['I_2'], bins, labels=bins[1:])
df['I_3'] = (df['bid_2_quantity'] - df['ask_2_quantity']) / (df['bid_2_quantity'] + df['ask_2_quantity'])
df['I_3_bins'] = pd.cut(df['I_3'], bins, labels=bins[1:])
df['I_4'] = (df['bid_3_quantity'] - df['ask_3_quantity']) / (df['bid_3_quantity'] + df['ask_3_quantity'])
df['I_4_bins'] = pd.cut(df['I_4'], bins, labels=bins[1:])
fig, axes = plt.subplots(nrows=2, ncols=2, figsize=(8, 5))
axes[0][0].plot(df.groupby('I_bins')['change'].mean())
axes[0][0].set_title('I')
axes[0][0].grid(True)
axes[0][1].plot(df.groupby('I_2_bins')['change'].mean())
axes[0][1].set_title('I 2')
axes[0][1].grid(True)
axes[1][0].plot(df.groupby('I_3_bins')['change'].mean())
axes[1][0].set_title('I 3')
axes[1][0].grid(True)
axes[1][1].plot(df.groupby('I_4_bins')['change'].mean())
axes[1][1].set_title('I 4')
axes[1][1].grid(True)
plt.tight_layout();
Fuera [1]:
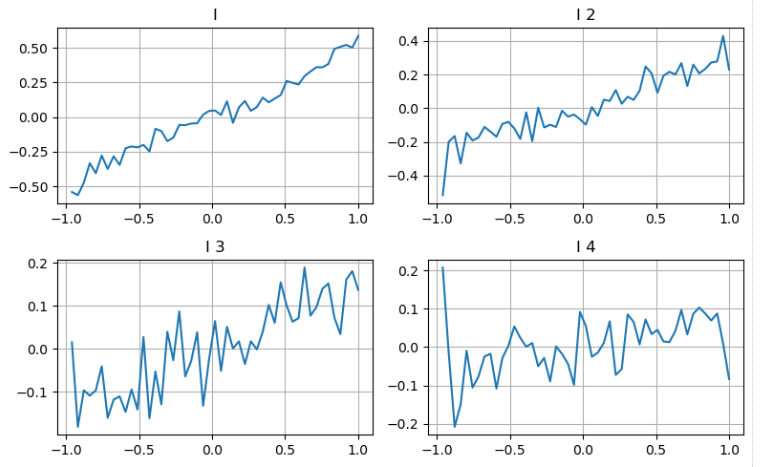
En [20]:
df['adjust_mid_price_4'] = df['mid_price'] + df['spread']*(df['I']+0.3)*(df['I']**4+0.7)/3.8
df['adjust_mid_price_5'] = df['mid_price'] + df['spread']*(0.7*df['I']+0.3*df['I_2'])/2
df['adjust_mid_price_6'] = df['mid_price'] + df['spread']*(0.7*df['I']+0.3*df['I_2'])**3/2
df['adjust_mid_price_7'] = df['mid_price'] + df['spread']*(0.7*df['I']+0.3*df['I_2']+0.3)*((0.7*df['I']+0.3*df['I_2'])**4+0.7)/3.8
df['adjust_mid_price_8'] = df['mid_price'] + df['spread']*(0.7*df['I']+0.2*df['I_2']+0.1*df['I_3']+0.3)*((0.7*df['I']+0.3*df['I_2']+0.1*df['I_3'])**4+0.7)/3.8
En [21]:
print('The error of the adjusted mid_price_4:', ((df['price']-df['adjust_mid_price_4'])**2).sum())
print('The error of the adjusted mid_price_5:', ((df['price']-df['adjust_mid_price_5'])**2).sum())
print('The error of the adjusted mid_price_6:', ((df['price']-df['adjust_mid_price_6'])**2).sum())
print('The error of the adjusted mid_price_7:', ((df['price']-df['adjust_mid_price_7'])**2).sum())
print('The error of the adjusted mid_price_8:', ((df['price']-df['adjust_mid_price_8'])**2).sum())
Fuera[21]:
Error del precio medio ajustado: 0,0047909595497071375 Error del precio medio ajustado: 0,0047884350488318714 Error del precio medio ajustado: 0,0047778319053133735 El error del precio medio ajustado_7: 0,004773578540592192 Error del precio medio ajustado: 0,004771415189297518
Considerando los datos de las transacciones
Los datos de transacción reflejan directamente el alcance de las posiciones largas y cortas. Después de todo, las transacciones involucran dinero real, mientras que la colocación de órdenes tiene costos mucho más bajos e incluso puede implicar engaño intencional. Por lo tanto, al predecir el precio medio, las estrategias deben centrarse en los datos de transacción.
En términos de forma, podemos definir el desequilibrio de la cantidad media de llegada de órdenes como VI, con Vb y Vs representando la cantidad media de órdenes de compra y venta dentro de un intervalo de tiempo unitario, respectivamente.
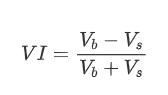
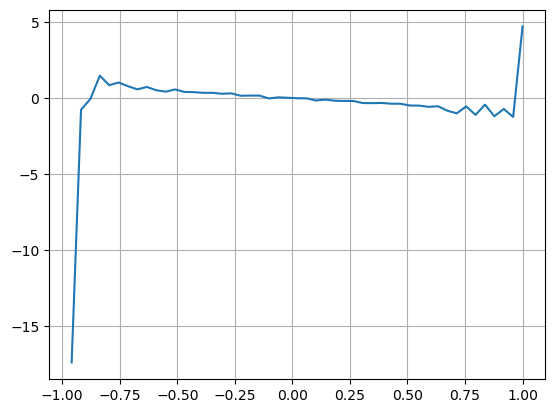
Los resultados muestran que la cantidad de llegada en un corto período de tiempo tiene el impacto más significativo en la predicción del cambio de precio. Cuando VI está entre 0.1 y 0.9, está correlacionada negativamente con el precio, mientras que fuera de este rango, está correlacionada positivamente con el precio. Esto sugiere que cuando el mercado no es extremo y principalmente oscila, el precio tiende a volver a la media. Sin embargo, en condiciones extremas del mercado, como cuando hay un gran número de órdenes de compra abrumadoras órdenes de venta, surge una tendencia. Incluso sin considerar estos escenarios de baja probabilidad, asumiendo una relación lineal negativa entre la tendencia y VI reduce significativamente la predicción del error del precio medio. El coeficiente
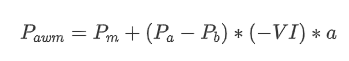
En [22]:
alpha=0.1
En [23]:
df['avg_buy_interval'] = None
df['avg_sell_interval'] = None
df.loc[df['is_buyer_maker'] == True, 'avg_buy_interval'] = df[df['is_buyer_maker'] == True]['transact_time'].diff().ewm(alpha=alpha).mean()
df.loc[df['is_buyer_maker'] == False, 'avg_sell_interval'] = df[df['is_buyer_maker'] == False]['transact_time'].diff().ewm(alpha=alpha).mean()
En [24]:
df['avg_buy_quantity'] = None
df['avg_sell_quantity'] = None
df.loc[df['is_buyer_maker'] == True, 'avg_buy_quantity'] = df[df['is_buyer_maker'] == True]['quantity'].ewm(alpha=alpha).mean()
df.loc[df['is_buyer_maker'] == False, 'avg_sell_quantity'] = df[df['is_buyer_maker'] == False]['quantity'].ewm(alpha=alpha).mean()
En el [25]:
df['avg_buy_quantity'] = df['avg_buy_quantity'].fillna(method='ffill')
df['avg_sell_quantity'] = df['avg_sell_quantity'].fillna(method='ffill')
df['avg_buy_interval'] = df['avg_buy_interval'].fillna(method='ffill')
df['avg_sell_interval'] = df['avg_sell_interval'].fillna(method='ffill')
df['avg_buy_rate'] = 1000 / df['avg_buy_interval']
df['avg_sell_rate'] =1000 / df['avg_sell_interval']
df['avg_buy_volume'] = df['avg_buy_rate']*df['avg_buy_quantity']
df['avg_sell_volume'] = df['avg_sell_rate']*df['avg_sell_quantity']
En [26]:
df['I'] = (df['bid_0_quantity']- df['ask_0_quantity']) / (df['bid_0_quantity'] + df['ask_0_quantity'])
df['OI'] = (df['avg_buy_rate']-df['avg_sell_rate']) / (df['avg_buy_rate'] + df['avg_sell_rate'])
df['QI'] = (df['avg_buy_quantity']-df['avg_sell_quantity']) / (df['avg_buy_quantity'] + df['avg_sell_quantity'])
df['VI'] = (df['avg_buy_volume']-df['avg_sell_volume']) / (df['avg_buy_volume'] + df['avg_sell_volume'])
En [27]:
bins = np.linspace(-1, 1, 50)
df['VI_bins'] = pd.cut(df['VI'], bins, labels=bins[1:])
plt.plot(df.groupby('VI_bins')['change'].mean());
plt.grid(True)
Fuera[27]:
En el [28]:
df['adjust_mid_price'] = df['mid_price'] + df['spread']*df['I']/2
df['adjust_mid_price_9'] = df['mid_price'] + df['spread']*(-df['OI'])*2
df['adjust_mid_price_10'] = df['mid_price'] + df['spread']*(-df['VI'])*1.4
En [29]:
print('The error of the adjusted mid_price:', ((df['price']-df['adjust_mid_price'])**2).sum())
print('The error of the adjusted mid_price_9:', ((df['price']-df['adjust_mid_price_9'])**2).sum())
print('The error of the adjusted mid_price_10:', ((df['price']-df['adjust_mid_price_10'])**2).sum())
Fuera de juego[29]:
El error del precio medio ajustado: 0,0048373440193987035 Error del precio medio ajustado: 0,004629586542840461 El error del precio medio ajustado_10: 0,004401790287167206
El precio medio global
Considerando que tanto el desequilibrio del libro de pedidos como los datos de transacción son útiles para predecir el precio medio, podemos combinar estos dos parámetros juntos. La asignación de pesos en este caso es arbitraria y no tiene en cuenta las condiciones límite. En casos extremos, el precio medio predicho puede no caer entre los precios de oferta y demanda. Sin embargo, siempre que se pueda reducir el error de predicción, estos detalles no son de gran preocupación.
Al final, el error de predicción se reduce de 0.00487 a 0.0043. En este punto, no profundizaremos más en el tema. Todavía hay muchos aspectos que explorar cuando se trata de predecir el precio medio, ya que es esencialmente predecir el precio en sí.
En el [30]:
#Note that the VI needs to be delayed by one to use
df['CI'] = -1.5*df['VI'].shift()+0.7*(0.7*df['I']+0.2*df['I_2']+0.1*df['I_3'])**3
En [31]:
df['adjust_mid_price_11'] = df['mid_price'] + df['spread']*(df['CI'])
print('The error of the adjusted mid_price_11:', ((df['price']-df['adjust_mid_price_11'])**2).sum())
Fuera[31]:
El error del precio medio ajustado_11: 0,0043001941412563575
Resumen de las actividades
El artículo combina datos de profundidad y datos de transacción para mejorar aún más el método de cálculo del precio medio. Proporciona un método para medir la precisión y mejora la precisión de la predicción del cambio de precio. En general, los parámetros no son rigurosos y son solo para referencia.
- Hacer una cobertura delta con una curva de sonrisas para opciones de Bitcoin
- Opiniones sobre las estrategias de negociación de alta frecuencia (4)
- Pensamiento sobre estrategias de trading de alta frecuencia (5)
- Pensamiento sobre estrategias de trading de alta frecuencia (4)
- Opiniones sobre las estrategias de negociación de alta frecuencia (3)
- Pensamiento sobre estrategias de trading de alta frecuencia (3)
- Opiniones sobre las estrategias de negociación de alta frecuencia (2)
- Pensamiento sobre estrategias de trading de alta frecuencia (2)
- Opiniones sobre las estrategias de negociación de alta frecuencia (1)
- Pensamiento sobre estrategias de trading de alta frecuencia (1)
- Documento de descripción de la configuración de Futu Securities