Modelo de factor de moneda digital
El autor:- ¿ Por qué?, Creado: 2022-10-24 17:37:50, Actualizado: 2023-09-15 20:59:38
Marco del modelo de factores
Los informes de investigación sobre el modelo multifactor del mercado de valores son voluminosos, con ricas teorías y prácticas. No importa el número de monedas, el valor total de mercado, el volumen de operaciones, el mercado de derivados, etc. en el mercado de divisas digitales, es suficiente con realizar investigación por factores. Este documento es principalmente para principiantes en estrategias cuantitativas, y no involucrará principios matemáticos complejos y análisis estadístico.
El factor puede ser considerado como un indicador y una expresión puede ser escrita. El factor cambia constantemente, reflejando la información de ingresos futuros.
Por ejemplo, la suposición detrás del factor de precio de cierre es que el precio de las acciones puede predecir las ganancias futuras, y cuanto mayor sea el precio de las acciones, mayores serán (o pueden ser) las ganancias futuras. De hecho, construir una cartera basada en este factor es un modelo/estrategia de inversión para comprar acciones de alto precio en una ronda regular. En términos generales, los factores que pueden generar continuamente ganancias excedentes también se llaman Alpha. Por ejemplo, el factor de valor de mercado y el factor de impulso han sido verificados como factores una vez efectivos por la academia y la comunidad de inversión.
Tanto el mercado de valores como el mercado de divisas digitales son sistemas complejos. No hay ningún factor que pueda predecir completamente las ganancias futuras, pero aún tienen cierta previsibilidad. El alfa efectivo (modo de inversión) gradualmente se invalidará con más entrada de capital. Sin embargo, este proceso producirá otros modelos en el mercado, dando a luz a un nuevo alfa. El factor de valor de mercado solía ser una estrategia muy efectiva en el mercado de acciones A. Simplemente compre 10 acciones con el valor de mercado más bajo y ajustelas una vez al día. Desde 2007, el retraso de 10 años producirá más de 400 veces las ganancias, superando con creces el mercado general. Sin embargo, el mercado de acciones de caballo blanco en 2017 reflejó el fracaso del factor de valor de mercado pequeño, y el factor de valor se hizo popular en su lugar. Por lo tanto, necesitamos verificar constantemente el equilibrio y tratar de usar el alfa.
Los factores buscados son la base para establecer estrategias. Una mejor estrategia puede construirse combinando múltiples factores efectivos no relacionados.
import requests
from datetime import date,datetime
import time
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import requests, zipfile, io
%matplotlib inline
Recursos de datos
Hasta ahora, los datos de línea K por hora de los futuros perpetuos de Binance USDT desde principios de 2022 hasta ahora han superado 150 monedas. Como mencionamos anteriormente, el modelo de factor es un modelo de selección de divisas, que está orientado a todas las monedas en lugar de a una determinada moneda. Los datos de línea K incluyen precios altos y bajos de apertura y cierre, volumen de operaciones, número de transacciones, volumen de compra de tomadores y otros datos. Estos datos ciertamente no son la fuente de todos los factores, como el índice de valores de los Estados Unidos, la expectativa de aumento de la tasa de interés, la rentabilidad, los datos de la cadena, la popularidad de las redes sociales, etc. Las fuentes de datos inusuales también pueden encontrar alfa efectivo, pero el volumen de precios básicos también es suficiente.
## Current trading pair
Info = requests.get('https://fapi.binance.com/fapi/v1/exchangeInfo')
symbols = [s['symbol'] for s in Info.json()['symbols']]
symbols = list(filter(lambda x: x[-4:] == 'USDT', [s.split('_')[0] for s in symbols]))
print(symbols)
- ¿ Qué?
['BTCUSDT', 'ETHUSDT', 'BCHUSDT', 'XRPUSDT', 'EOSUSDT', 'LTCUSDT', 'TRXUSDT', 'ETCUSDT', 'LINKUSDT',
'XLMUSDT', 'ADAUSDT', 'XMRUSDT', 'DASHUSDT', 'ZECUSDT', 'XTZUSDT', 'BNBUSDT', 'ATOMUSDT', 'ONTUSDT',
'IOTAUSDT', 'BATUSDT', 'VETUSDT', 'NEOUSDT', 'QTUMUSDT', 'IOSTUSDT', 'THETAUSDT', 'ALGOUSDT', 'ZILUSDT',
'KNCUSDT', 'ZRXUSDT', 'COMPUSDT', 'OMGUSDT', 'DOGEUSDT', 'SXPUSDT', 'KAVAUSDT', 'BANDUSDT', 'RLCUSDT',
'WAVESUSDT', 'MKRUSDT', 'SNXUSDT', 'DOTUSDT', 'DEFIUSDT', 'YFIUSDT', 'BALUSDT', 'CRVUSDT', 'TRBUSDT',
'RUNEUSDT', 'SUSHIUSDT', 'SRMUSDT', 'EGLDUSDT', 'SOLUSDT', 'ICXUSDT', 'STORJUSDT', 'BLZUSDT', 'UNIUSDT',
'AVAXUSDT', 'FTMUSDT', 'HNTUSDT', 'ENJUSDT', 'FLMUSDT', 'TOMOUSDT', 'RENUSDT', 'KSMUSDT', 'NEARUSDT',
'AAVEUSDT', 'FILUSDT', 'RSRUSDT', 'LRCUSDT', 'MATICUSDT', 'OCEANUSDT', 'CVCUSDT', 'BELUSDT', 'CTKUSDT',
'AXSUSDT', 'ALPHAUSDT', 'ZENUSDT', 'SKLUSDT', 'GRTUSDT', '1INCHUSDT', 'CHZUSDT', 'SANDUSDT', 'ANKRUSDT',
'BTSUSDT', 'LITUSDT', 'UNFIUSDT', 'REEFUSDT', 'RVNUSDT', 'SFPUSDT', 'XEMUSDT', 'BTCSTUSDT', 'COTIUSDT',
'CHRUSDT', 'MANAUSDT', 'ALICEUSDT', 'HBARUSDT', 'ONEUSDT', 'LINAUSDT', 'STMXUSDT', 'DENTUSDT', 'CELRUSDT',
'HOTUSDT', 'MTLUSDT', 'OGNUSDT', 'NKNUSDT', 'SCUSDT', 'DGBUSDT', '1000SHIBUSDT', 'ICPUSDT', 'BAKEUSDT',
'GTCUSDT', 'BTCDOMUSDT', 'TLMUSDT', 'IOTXUSDT', 'AUDIOUSDT', 'RAYUSDT', 'C98USDT', 'MASKUSDT', 'ATAUSDT',
'DYDXUSDT', '1000XECUSDT', 'GALAUSDT', 'CELOUSDT', 'ARUSDT', 'KLAYUSDT', 'ARPAUSDT', 'CTSIUSDT', 'LPTUSDT',
'ENSUSDT', 'PEOPLEUSDT', 'ANTUSDT', 'ROSEUSDT', 'DUSKUSDT', 'FLOWUSDT', 'IMXUSDT', 'API3USDT', 'GMTUSDT',
'APEUSDT', 'BNXUSDT', 'WOOUSDT', 'FTTUSDT', 'JASMYUSDT', 'DARUSDT', 'GALUSDT', 'OPUSDT', 'BTCUSDT',
'ETHUSDT', 'INJUSDT', 'STGUSDT', 'FOOTBALLUSDT', 'SPELLUSDT', '1000LUNCUSDT', 'LUNA2USDT', 'LDOUSDT',
'CVXUSDT']
print(len(symbols))
- ¿ Qué?
153
#Function to obtain any period of K-line
def GetKlines(symbol='BTCUSDT',start='2020-8-10',end='2021-8-10',period='1h',base='fapi',v = 'v1'):
Klines = []
start_time = int(time.mktime(datetime.strptime(start, "%Y-%m-%d").timetuple()))*1000 + 8*60*60*1000
end_time = min(int(time.mktime(datetime.strptime(end, "%Y-%m-%d").timetuple()))*1000 + 8*60*60*1000,time.time()*1000)
intervel_map = {'m':60*1000,'h':60*60*1000,'d':24*60*60*1000}
while start_time < end_time:
mid_time = start_time+1000*int(period[:-1])*intervel_map[period[-1]]
url = 'https://'+base+'.binance.com/'+base+'/'+v+'/klines?symbol=%s&interval=%s&startTime=%s&endTime=%s&limit=1000'%(symbol,period,start_time,mid_time)
res = requests.get(url)
res_list = res.json()
if type(res_list) == list and len(res_list) > 0:
start_time = res_list[-1][0]+int(period[:-1])*intervel_map[period[-1]]
Klines += res_list
if type(res_list) == list and len(res_list) == 0:
start_time = start_time+1000*int(period[:-1])*intervel_map[period[-1]]
if mid_time >= end_time:
break
df = pd.DataFrame(Klines,columns=['time','open','high','low','close','amount','end_time','volume','count','buy_amount','buy_volume','null']).astype('float')
df.index = pd.to_datetime(df.time,unit='ms')
return df
start_date = '2022-1-1'
end_date = '2022-09-14'
period = '1h'
df_dict = {}
for symbol in symbols:
df_s = GetKlines(symbol=symbol,start=start_date,end=end_date,period=period,base='fapi',v='v1')
if not df_s.empty:
df_dict[symbol] = df_s
symbols = list(df_dict.keys())
print(df_s.columns)
- ¿ Qué?
Index(['time', 'open', 'high', 'low', 'close', 'amount', 'end_time', 'volume',
'count', 'buy_amount', 'buy_volume', 'null'],
dtype='object')
Los datos que nos interesan: precio de cierre, precio de apertura, volumen de operaciones, número de transacciones y proporción de compra de tomadores se extraen primero de los datos de la línea K. Sobre la base de estos datos, se procesan los factores requeridos.
df_close = pd.DataFrame(index=pd.date_range(start=start_date, end=end_date, freq=period),columns=df_dict.keys())
df_open = pd.DataFrame(index=pd.date_range(start=start_date, end=end_date, freq=period),columns=df_dict.keys())
df_volume = pd.DataFrame(index=pd.date_range(start=start_date, end=end_date, freq=period),columns=df_dict.keys())
df_buy_ratio = pd.DataFrame(index=pd.date_range(start=start_date, end=end_date, freq=period),columns=df_dict.keys())
df_count = pd.DataFrame(index=pd.date_range(start=start_date, end=end_date, freq=period),columns=df_dict.keys())
for symbol in df_dict.keys():
df_s = df_dict[symbol]
df_close[symbol] = df_s.close
df_open[symbol] = df_s.open
df_volume[symbol] = df_s.volume
df_count[symbol] = df_s['count']
df_buy_ratio[symbol] = df_s.buy_amount/df_s.amount
df_close = df_close.dropna(how='all')
df_open = df_open.dropna(how='all')
df_volume = df_volume.dropna(how='all')
df_count = df_count.dropna(how='all')
df_buy_ratio = df_buy_ratio.dropna(how='all')
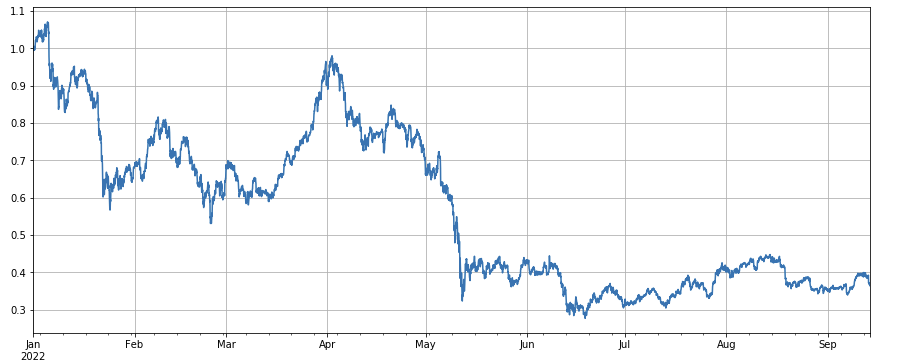
El rendimiento general del índice de mercado es sombrío, cayendo un 60% desde el comienzo del año hasta los últimos días.
df_norm = df_close/df_close.fillna(method='bfill').iloc[0] #normalization
df_norm.mean(axis=1).plot(figsize=(15,6),grid=True);
#Final index profit chart
En el caso de las empresas de servicios de telecomunicaciones:
-
Método de regresión El rendimiento del período siguiente es la variable dependiente, y el factor a probar es la variable independiente. El coeficiente obtenido por regresión es también el rendimiento del factor. Después de que se construye la ecuación de regresión, la validez y volatilidad de los factores generalmente se ven en referencia al valor medio absoluto del valor del coeficiente t, la proporción de la secuencia de valor absoluto del valor del coeficiente t mayor de 2, el rendimiento del factor anualizado, la volatilidad del beneficio del factor anualizado y la relación Sharpe del factor de beneficio. Se pueden regredir múltiples factores a la vez. Consulte el documento barra para obtener detalles.
-
IC, IR y otros indicadores El denominado IC es el coeficiente de correlación entre el factor y la tasa de rendimiento del siguiente período. Ahora, RANK_ IC también se usa generalmente, es el coeficiente de correlación entre la clasificación de factores y la tasa de rendimiento de la próxima acción. IR es generalmente el valor medio de la secuencia IC / la desviación estándar de la secuencia IC.
-
Método de regresión estratificada En este trabajo, utilizaremos este método, que es ordenar las monedas de acuerdo con los factores a probar, dividirlas en N grupos para backtesting de grupos, y utilizar un período fijo para el ajuste de posición. Si la situación es ideal, la tasa de rendimiento de las monedas del Grupo N mostrará una buena monotonía, aumentando o disminuyendo monótona, y la brecha de ingresos de cada grupo es grande. Tales factores se reflejan en una buena discriminación. Si el primer grupo tiene las ganancias más altas y el último grupo tiene las ganancias más bajas, entonces vaya largo en el primer grupo y vaya corto en el último grupo para obtener el rendimiento final, que es el indicador de referencia de la relación Sharp.
Operación de prueba posterior real
Las monedas a seleccionar se dividen en 3 grupos basados en la clasificación de los factores desde el más pequeño hasta el más grande. Cada grupo de monedas representa aproximadamente 1/3 del total. Si un factor es efectivo, cuanto menor sea el número de puntos en cada grupo, mayor será la tasa de retorno, pero también significa que cada moneda tiene relativamente más fondos asignados. Si las posiciones largas y cortas son doble apalancamiento respectivamente, y el primer grupo y el último grupo son 10 monedas respectivamente, entonces una moneda representa el 10% del total. Si una moneda que se corta se duplica, entonces se retira el 20%; Si el número de grupos es 50, entonces se retirará el 4%.
En general, la capacidad de predicción de factores se puede evaluar aproximadamente de acuerdo con la tasa de retorno y la relación Sharpe del backtest final. Además, también necesita referirse a si la expresión de factores es simple, sensible al tamaño de la agrupación, sensible al intervalo de ajuste de posición y sensible al tiempo inicial del backtest.
En cuanto a la frecuencia de ajuste de posición, el mercado de valores generalmente tiene un período de 5 días, 10 días y un mes. Sin embargo, para el mercado de divisas digitales, dicho período es sin duda demasiado largo, y el mercado en el bot real se monitoriza en tiempo real. No es necesario apegarse a un período específico para ajustar posiciones nuevamente. Por lo tanto, en el bot real, ajustamos posiciones en tiempo real o en un corto período de tiempo.
En cuanto a cómo cerrar la posición, de acuerdo con el método tradicional, la posición puede cerrarse si no está en el grupo al ordenar la próxima vez. Sin embargo, en el caso del ajuste de posición en tiempo real, algunas monedas pueden estar justo en el límite, lo que puede llevar al cierre de posición de ida y vuelta. Por lo tanto, esta estrategia adopta el método de esperar cambios de agrupación, y luego cerrar la posición cuando la posición en la dirección opuesta necesita ser abierta. Por ejemplo, el primer grupo va largo. Cuando las monedas en el estado de posición larga se dividen en el tercer grupo, luego cierre la posición y vaya corto. Si la posición se cierra en un período fijo, como todos los días o cada 8 horas, también puede cerrar la posición sin estar en un grupo. Pruebe lo más que pueda.
#Backtest engine
class Exchange:
def __init__(self, trade_symbols, fee=0.0004, initial_balance=10000):
self.initial_balance = initial_balance #Initial assets
self.fee = fee
self.trade_symbols = trade_symbols
self.account = {'USDT':{'realised_profit':0, 'unrealised_profit':0, 'total':initial_balance, 'fee':0, 'leverage':0, 'hold':0}}
for symbol in trade_symbols:
self.account[symbol] = {'amount':0, 'hold_price':0, 'value':0, 'price':0, 'realised_profit':0,'unrealised_profit':0,'fee':0}
def Trade(self, symbol, direction, price, amount):
cover_amount = 0 if direction*self.account[symbol]['amount'] >=0 else min(abs(self.account[symbol]['amount']), amount)
open_amount = amount - cover_amount
self.account['USDT']['realised_profit'] -= price*amount*self.fee #Net of fees
self.account['USDT']['fee'] += price*amount*self.fee
self.account[symbol]['fee'] += price*amount*self.fee
if cover_amount > 0: #Close position first
self.account['USDT']['realised_profit'] += -direction*(price - self.account[symbol]['hold_price'])*cover_amount #Profits
self.account[symbol]['realised_profit'] += -direction*(price - self.account[symbol]['hold_price'])*cover_amount
self.account[symbol]['amount'] -= -direction*cover_amount
self.account[symbol]['hold_price'] = 0 if self.account[symbol]['amount'] == 0 else self.account[symbol]['hold_price']
if open_amount > 0:
total_cost = self.account[symbol]['hold_price']*direction*self.account[symbol]['amount'] + price*open_amount
total_amount = direction*self.account[symbol]['amount']+open_amount
self.account[symbol]['hold_price'] = total_cost/total_amount
self.account[symbol]['amount'] += direction*open_amount
def Buy(self, symbol, price, amount):
self.Trade(symbol, 1, price, amount)
def Sell(self, symbol, price, amount):
self.Trade(symbol, -1, price, amount)
def Update(self, close_price): #Update assets
self.account['USDT']['unrealised_profit'] = 0
self.account['USDT']['hold'] = 0
for symbol in self.trade_symbols:
if not np.isnan(close_price[symbol]):
self.account[symbol]['unrealised_profit'] = (close_price[symbol] - self.account[symbol]['hold_price'])*self.account[symbol]['amount']
self.account[symbol]['price'] = close_price[symbol]
self.account[symbol]['value'] = abs(self.account[symbol]['amount'])*close_price[symbol]
self.account['USDT']['hold'] += self.account[symbol]['value']
self.account['USDT']['unrealised_profit'] += self.account[symbol]['unrealised_profit']
self.account['USDT']['total'] = round(self.account['USDT']['realised_profit'] + self.initial_balance + self.account['USDT']['unrealised_profit'],6)
self.account['USDT']['leverage'] = round(self.account['USDT']['hold']/self.account['USDT']['total'],3)
#Function of test factor
def Test(factor, symbols, period=1, N=40, value=300):
e = Exchange(symbols, fee=0.0002, initial_balance=10000)
res_list = []
index_list = []
factor = factor.dropna(how='all')
for idx, row in factor.iterrows():
if idx.hour % period == 0:
buy_symbols = row.sort_values().dropna()[0:N].index
sell_symbols = row.sort_values().dropna()[-N:].index
prices = df_close.loc[idx,]
index_list.append(idx)
for symbol in symbols:
if symbol in buy_symbols and e.account[symbol]['amount'] <= 0:
e.Buy(symbol,prices[symbol],value/prices[symbol]-e.account[symbol]['amount'])
if symbol in sell_symbols and e.account[symbol]['amount'] >= 0:
e.Sell(symbol,prices[symbol], value/prices[symbol]+e.account[symbol]['amount'])
e.Update(prices)
res_list.append([e.account['USDT']['total'],e.account['USDT']['hold']])
return pd.DataFrame(data=res_list, columns=['total','hold'],index = index_list)
Prueba de factores sencilla
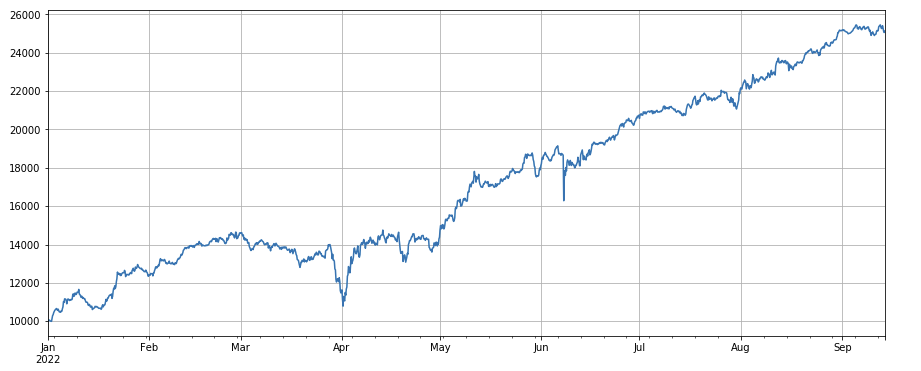
Factor de volumen de negociación: monedas largas simples con bajo volumen de negociación y monedas cortas con alto volumen de negociación, que se desempeñan muy bien, lo que indica que las monedas populares tienden a disminuir.
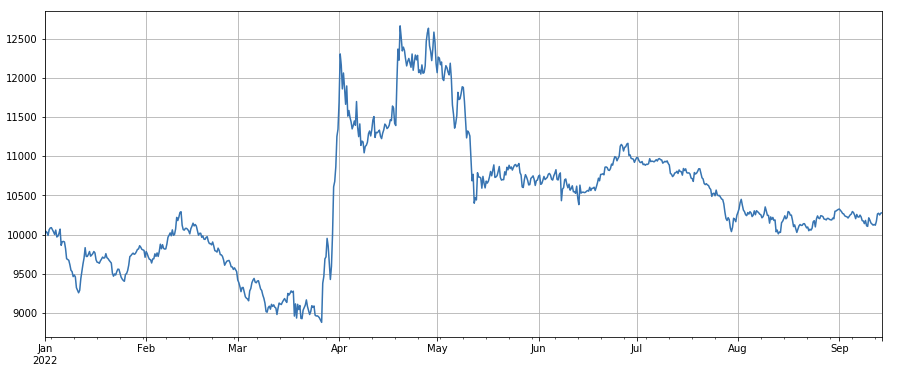
Factor de precio de negociación: el efecto de las monedas largas con precios bajos y las monedas cortas con precios altos son comunes.
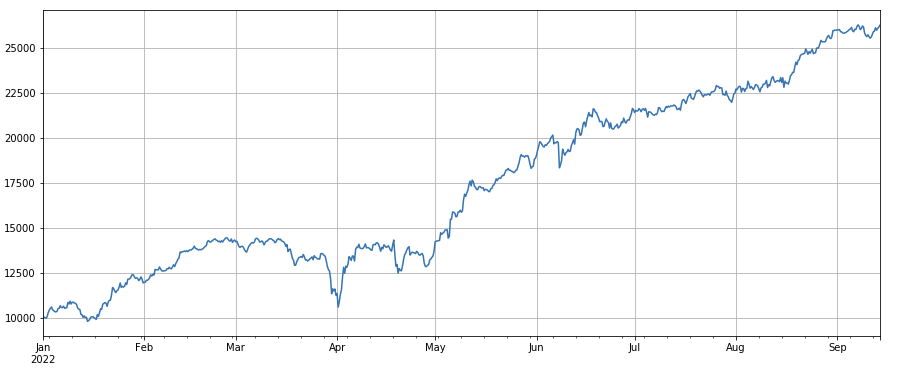
Factor de número de transacciones: El rendimiento es muy similar al volumen de transacciones. Es obvio que la correlación entre el factor de volumen de transacciones y el factor de número de transacciones es muy alta. De hecho, la correlación promedio entre ellos en diferentes monedas ha alcanzado 0.97, lo que indica que los dos factores son muy similares. Este factor debe tenerse en cuenta al sintetizar múltiples factores.
3h factor de impulso: (df_close - df_close. shift (3)) /df_ close. shift(3). Es decir, el aumento de 3 horas del factor. Los resultados de las pruebas de retroceso muestran que el aumento de 3 horas tiene características de regresión obvias, es decir, el aumento es más fácil de caer más tarde. El rendimiento general está bien, pero también hay un largo período de retirada y oscilación.
Factor de impulso de 24 horas: el resultado del período de ajuste de posición de 24 horas es bueno, el rendimiento es similar al impulso de 3 horas y la retirada es menor.
Fator de cambio del volumen de transacciones: df_ volume.rolling(24).mean() /df_ volume. rolling (96). mean(), es decir, la relación entre el volumen de transacciones del último día y el volumen de transacciones de los últimos tres días. La posición se ajusta cada 8 horas. Los resultados de la backtesting fueron buenos y el retiro también fue relativamente bajo, lo que indica que los que tenían un volumen de transacciones activo tenían más tendencia a disminuir.
El factor de cambio del número de transacciones: df_ count.rolling ((24).mean() /df_ count.rolling ((96). mean (), es decir, la relación entre el número de transacciones en el último día y el número de transacciones en los últimos tres días. La posición se ajusta cada 8 horas. Los resultados de las pruebas de retroceso fueron buenos y el retiro también es relativamente bajo, lo que indica que los que tienen un volumen de transacciones activo tendieron más a disminuir.
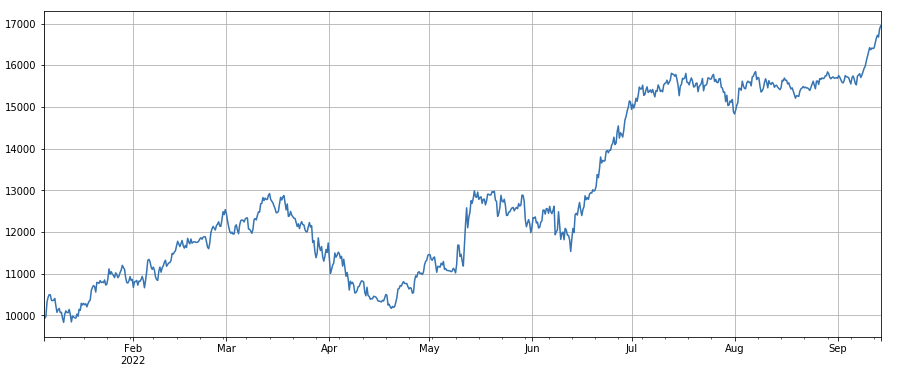
Factor de cambio del valor de una sola transacción: - ((df_volume.rolling(24).medio() /df_count.rolling(24.medio()) /(df_volume.rolling(24.medio() /df_count.rolling(96.medio()) , es decir, la relación entre el valor de la transacción del último día y el valor de la transacción de los últimos tres días, y la posición se ajustará cada 8 horas.
Fator de cambio del tomador por proporción de transacción: df_buy_ratio.rolling(24).mean() /df_buy_ratio.rolling(96).mean(), es decir, la relación del tomador por volumen al volumen total de transacciones en el último día al valor de transacciones en los últimos tres días, y la posición se ajustará cada 8 horas. Este factor funciona bastante bien y tiene poca correlación con el factor de volumen de transacciones.
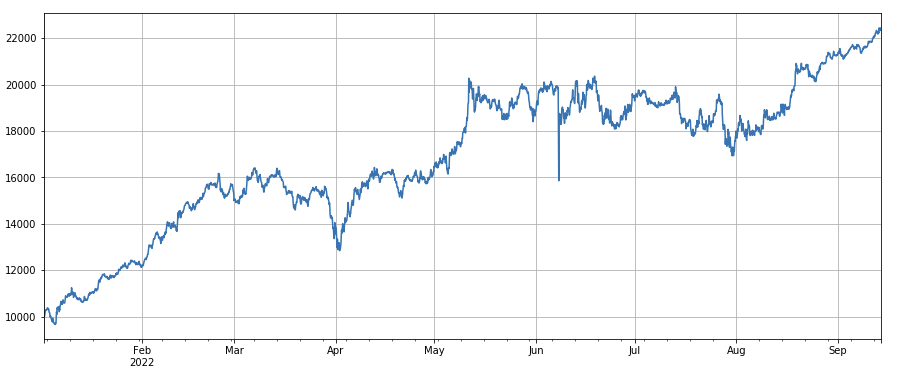
Factor de volatilidad: (df_close/df_open).rolling(24).std(), ir largo monedas con baja volatilidad, tiene un cierto efecto.
Factor de correlación entre el volumen de transacciones y el precio de cierre: df_close.rolling ((96).corr ((df_volume), el precio de cierre en los últimos cuatro días tiene un factor de correlación del volumen de transacciones, que ha tenido un buen desempeño en general.
Los factores enumerados aquí se basan en el volumen del precio. De hecho, la combinación de fórmulas de factores puede ser muy compleja sin lógica obvia. Puede referirse al famoso método de construcción de factores ALPHA101:https://github.com/STHSF/alpha101.
#transaction volume
factor_volume = df_volume
factor_volume_res = Test(factor_volume, symbols, period=4)
factor_volume_res.total.plot(figsize=(15,6),grid=True);
#transaction price
factor_close = df_close
factor_close_res = Test(factor_close, symbols, period=8)
factor_close_res.total.plot(figsize=(15,6),grid=True);
#transaction count
factor_count = df_count
factor_count_res = Test(factor_count, symbols, period=8)
factor_count_res.total.plot(figsize=(15,6),grid=True);
print(df_count.corrwith(df_volume).mean())
0.9671246744996017
#3h momentum factor
factor_1 = (df_close - df_close.shift(3))/df_close.shift(3)
factor_1_res = Test(factor_1,symbols,period=1)
factor_1_res.total.plot(figsize=(15,6),grid=True);
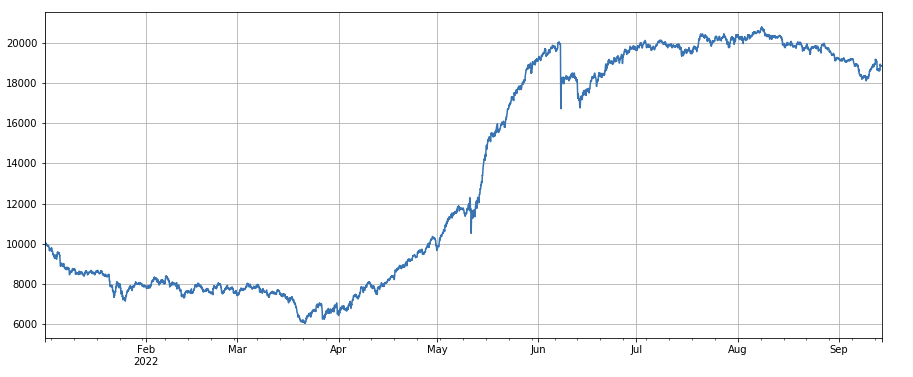
#24h momentum factor
factor_2 = (df_close - df_close.shift(24))/df_close.shift(24)
factor_2_res = Test(factor_2,symbols,period=24)
tamenxuanfactor_2_res.total.plot(figsize=(15,6),grid=True);
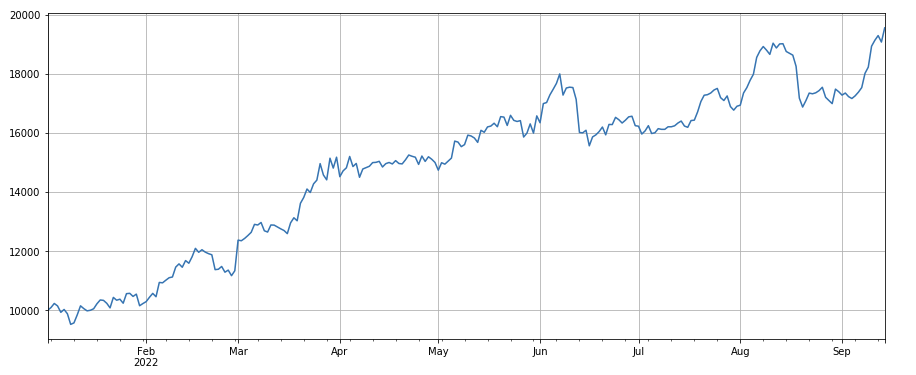
#factor of transaction volume
factor_3 = df_volume.rolling(24).mean()/df_volume.rolling(96).mean()
factor_3_res = Test(factor_3, symbols, period=8)
factor_3_res.total.plot(figsize=(15,6),grid=True);
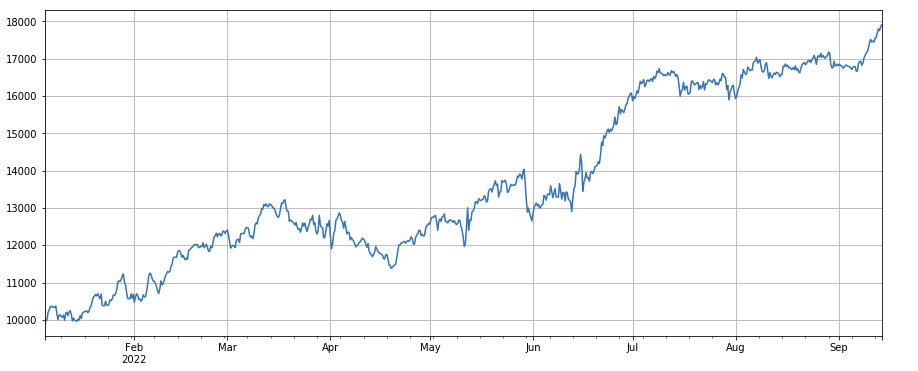
#factor of transaction number
factor_4 = df_count.rolling(24).mean()/df_count.rolling(96).mean()
factor_4_res = Test(factor_4, symbols, period=8)
factor_4_res.total.plot(figsize=(15,6),grid=True);
#factor correlation
print(factor_4.corrwith(factor_3).mean())
0.9707239580854841
#single transaction value factor
factor_5 = -(df_volume.rolling(24).mean()/df_count.rolling(24).mean())/(df_volume.rolling(24).mean()/df_count.rolling(96).mean())
factor_5_res = Test(factor_5, symbols, period=8)
factor_5_res.total.plot(figsize=(15,6),grid=True);
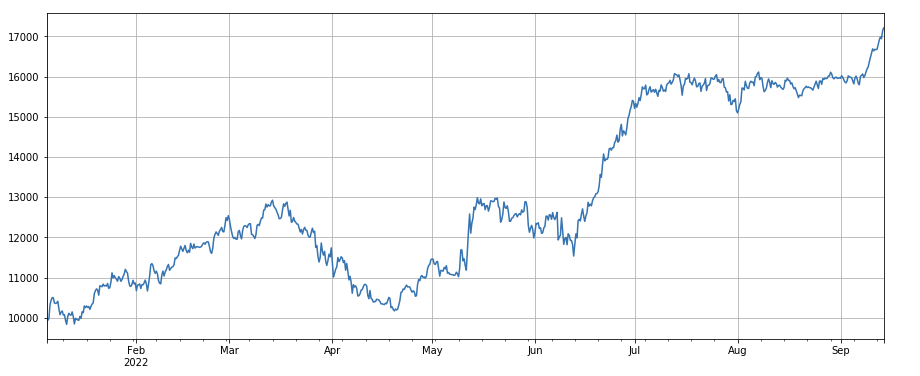
print(factor_4.corrwith(factor_5).mean())
0.861206620552479
#proportion factor of taker by transaction
factor_6 = df_buy_ratio.rolling(24).mean()/df_buy_ratio.rolling(96).mean()
factor_6_res = Test(factor_6, symbols, period=4)
factor_6_res.total.plot(figsize=(15,6),grid=True);
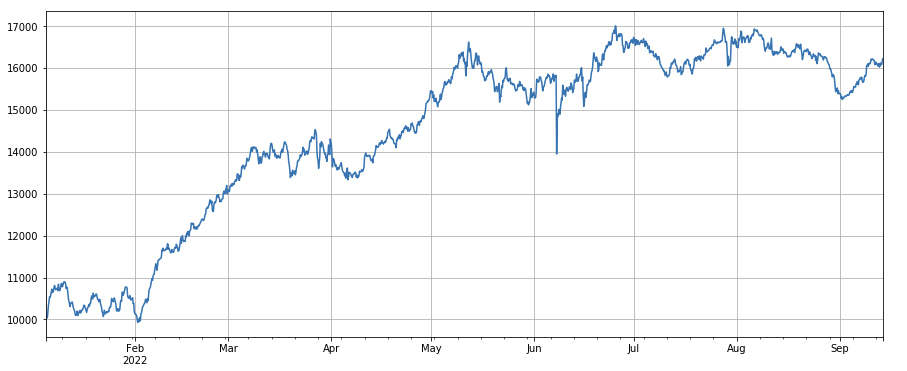
print(factor_3.corrwith(factor_6).mean())
0.1534572192503726
#volatility factor
factor_7 = (df_close/df_open).rolling(24).std()
factor_7_res = Test(factor_7, symbols, period=2)
factor_7_res.total.plot(figsize=(15,6),grid=True);
#correlation factor between transaction volume and closing price
factor_8 = df_close.rolling(96).corr(df_volume)
factor_8_res = Test(factor_8, symbols, period=4)
factor_8_res.total.plot(figsize=(15,6),grid=True);
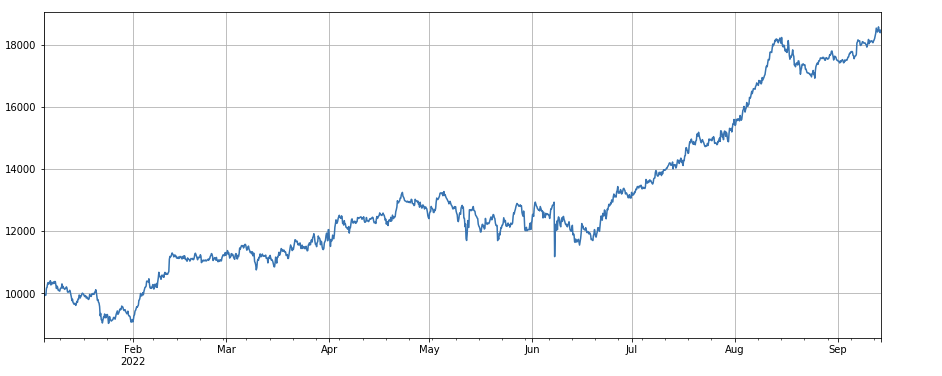
Síntesis de múltiples factores
Sin duda, la parte más importante del proceso de construcción de estrategias es descubrir constantemente nuevos factores efectivos, pero sin un buen método de síntesis de factores, un excelente factor alfa único no puede desempeñar su papel máximo.
Método de peso igual: todos los factores a sintetizar se suman con pesos iguales para obtener nuevos factores después de la síntesis.
Método de ponderación de la tasa de retorno de factores históricos: todos los factores a combinar se suman de acuerdo con la media aritmética de la tasa de retorno de factores históricos en el último período como el peso para obtener un nuevo factor después de la síntesis.
Método de ponderación de IC_IR maximizado: el valor promedio de IC del factor compuesto durante un período de la historia se utiliza como la estimación del valor de IC del factor compuesto en el siguiente período, y la matriz de covarianza del valor histórico de IC se utiliza como la estimación de la volatilidad del factor compuesto en el siguiente período.
Análisis de componentes principales (PCA): PCA es un método común para la reducción de dimensionalidad de los datos, y la correlación entre los factores puede ser alta.
En este documento se hará referencia a la asignación de validez de factores manualmente. Los métodos descritos anteriormente se pueden referir:ae933a8c-5a94-4d92-8f33-d92b70c36119.pdf
Al probar factores únicos, la clasificación es fija, pero la síntesis de múltiples factores necesita combinar datos completamente diferentes, por lo que todos los factores deben estandarizarse y el valor extremo y el valor faltante deben eliminarse en general. Aquí usamos df_ volumen\factor_ 1\factor_ 7\factor_ 6\factor_ 8 para la síntesis.
#standardize functions, remove missing values and extreme values, and standardize
def norm_factor(factor):
factor = factor.dropna(how='all')
factor_clip = factor.apply(lambda x:x.clip(x.quantile(0.2), x.quantile(0.8)),axis=1)
factor_norm = factor_clip.add(-factor_clip.mean(axis=1),axis ='index').div(factor_clip.std(axis=1),axis ='index')
return factor_norm
df_volume_norm = norm_factor(df_volume)
factor_1_norm = norm_factor(factor_1)
factor_6_norm = norm_factor(factor_6)
factor_7_norm = norm_factor(factor_7)
factor_8_norm = norm_factor(factor_8)
factor_total = 0.6*df_volume_norm + 0.4*factor_1_norm + 0.2*factor_6_norm + 0.3*factor_7_norm + 0.4*factor_8_norm
factor_total_res = Test(factor_total, symbols, period=8)
factor_total_res.total.plot(figsize=(15,6),grid=True);
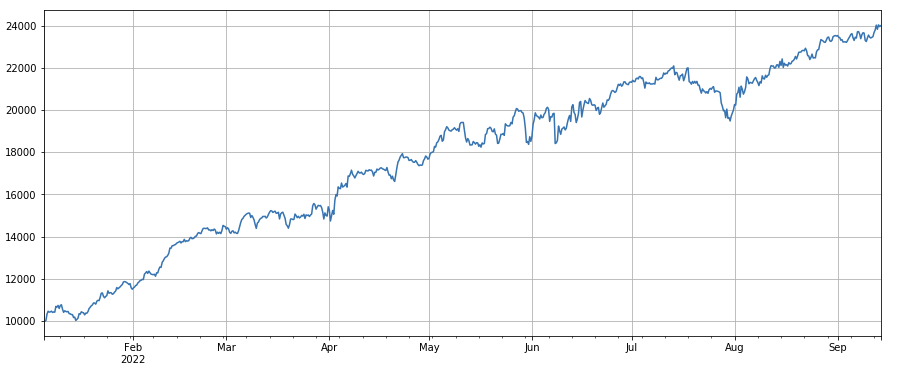
Resumen de las actividades
Este artículo introduce el método de prueba de un solo factor y prueba los factores comunes, y inicialmente introduce el método de síntesis de múltiples factores. Sin embargo, hay muchos contenidos de investigación de múltiples factores. Cada punto mencionado en el artículo puede desarrollarse aún más. Es una forma factible de convertir la investigación sobre varias estrategias en la exploración del factor alfa. El uso de la metodología de factores puede acelerar enormemente la verificación de las ideas comerciales, y hay muchos materiales para referencia.
El verdadero robot de:https://www.fmz.com/robot/486605
- Cuantificar el análisis fundamental en el mercado de criptomonedas: ¡Deja que los datos hablen por sí mismos!
- La investigación cuantitativa básica del círculo monetario - ¡No confíes más en los profesores de idiomas, los datos hablan objetivamente!
- Una herramienta esencial en el campo de la transacción cuantitativa - inventor de módulos de exploración de datos cuantitativos
- Dominarlo todo - Introducción a FMZ Nueva versión de la terminal de negociación (con el código fuente de TRB Arbitrage)
- Conozca todo acerca de la nueva versión del terminal de operaciones de FMZ (con código de código de TRB)
- FMZ Quant: Análisis de ejemplos de diseño de requisitos comunes en el mercado de criptomonedas (II)
- Cómo explotar robots de venta sin cerebro con una estrategia de alta frecuencia en 80 líneas de código
- Cuantificación FMZ: Desarrollo de casos de diseño de necesidades comunes en el mercado de criptomonedas (II)
- Cómo utilizar una estrategia de alta frecuencia de 80 líneas de código para explotar y vender robots sin cerebro
- FMZ Quant: Análisis de ejemplos de diseño de requisitos comunes en el mercado de criptomonedas (I)
- Cuantificación FMZ: Desarrollo de casos de diseño de necesidades comunes en el mercado de criptomonedas (1)