Modelado y análisis de la volatilidad de Bitcoin basado en el modelo ARMA-EGARCH
El autor:- ¿ Por qué?, Creado: 2022-11-15 15:32:43, Actualizado: 2023-09-14 20:30:52ED, y el proceso fue omitido.
El grado de coincidencia de la distribución normal normal no es tan bueno como la distribución t, lo que también muestra que la distribución de rendimiento tiene una cola más gruesa que la distribución normal.
En [23]:
am_GARCH = arch_model(training_garch, mean='AR', vol='GARCH',
p=1, q=1, lags=3, dist='ged')
res_GARCH = am_GARCH.fit(disp=False, options={'ftol': 1e-01})
res_GARCH.summary()
Fuera[23]: Iteración: 1, Cuenta de funciones: 10, Negativo LLF: -1917.4262154917305
Resultados del modelo AR-GARCH
Modelo medio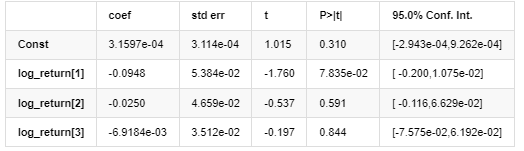
Modelo de volatilidad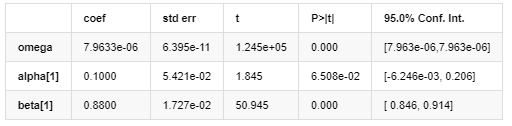
Distribución
Estimador de covarianza: robusto
Descripción de la ecuación de volatilidad de GARCH según la base de datos ARCH: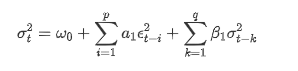
La ecuación de regresión condicional para la volatilidad se puede obtener como: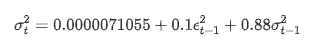
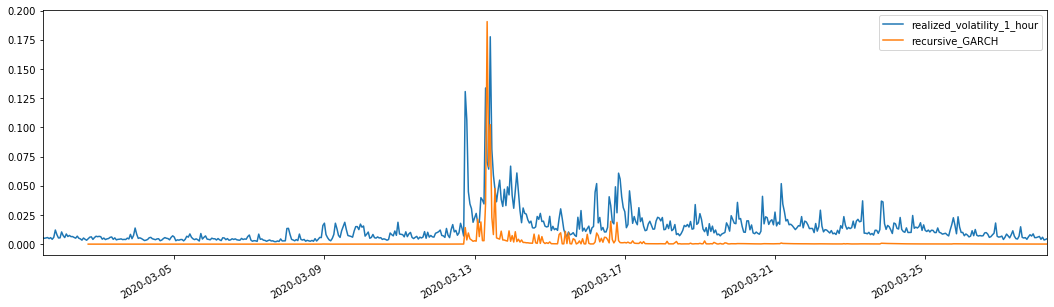
Combinado con la volatilidad prevista emparejada, compararlo con la volatilidad realizada de la muestra para ver el efecto.
En [26]:
def recursive_forecast(pd_dataframe):
window = predict_lag
model = 'GARCH'
index = kline_test[1:].index
end_loc = np.where(index >= kline_test.index[window])[0].min()
forecasts = {}
for i in range(len(kline_test[1:]) - window + 2):
mod = arch_model(pd_dataframe['log_return'][1:], mean='AR', vol=model, dist='ged',p=1, q=1)
res = mod.fit(last_obs=i+end_loc, disp='off', options={'ftol': 1e03})
temp = res.forecast().variance
fcast = temp.iloc[i + end_loc - 1]
forecasts[fcast.name] = fcast
forecasts = pd.DataFrame(forecasts).T
pd_dataframe['recursive_{}'.format(model)] = forecasts['h.1']
evaluate(pd_dataframe, 'realized_volatility_1_hour', 'recursive_{}'.format(model))
recursive_forecast(kline_test)
Fuera[26]: Error absoluto medio (MAE): 0,0128 Percentaje medio de error absoluto (MAPE): 95,6 Error de la raíz media cuadrada (RMSE): 0,018
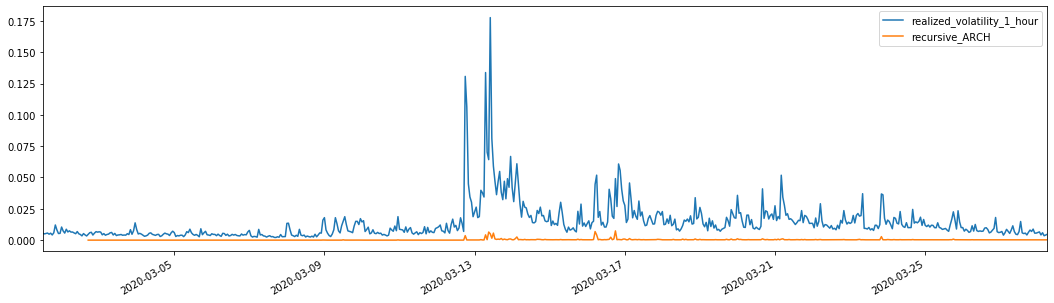
Para la comparación, haga un ARCH como sigue:
En [27]:
def recursive_forecast(pd_dataframe):
window = predict_lag
model = 'ARCH'
index = kline_test[1:].index
end_loc = np.where(index >= kline_test.index[window])[0].min()
forecasts = {}
for i in range(len(kline_test[1:]) - window + 2):
mod = arch_model(pd_dataframe['log_return'][1:], mean='AR', vol=model, dist='ged', p=1)
res = mod.fit(last_obs=i+end_loc, disp='off', options={'ftol': 1e03})
temp = res.forecast().variance
fcast = temp.iloc[i + end_loc - 1]
forecasts[fcast.name] = fcast
forecasts = pd.DataFrame(forecasts).T
pd_dataframe['recursive_{}'.format(model)] = forecasts['h.1']
evaluate(pd_dataframe, 'realized_volatility_1_hour', 'recursive_{}'.format(model))
recursive_forecast(kline_test)
Fuera[27]: Error absoluto medio (MAE): 0,0136 Percentaje de error absoluto medio (MAPE): 98,1 Error de la raíz media cuadrada (RMSE): 0.02
7. Modelado de EGARCH
El siguiente paso es realizar el modelado EGARCH
En [24]:
am_EGARCH = arch_model(training_egarch, mean='AR', vol='EGARCH',
p=1, lags=3, o=1,q=1, dist='ged')
res_EGARCH = am_EGARCH.fit(disp=False, options={'ftol': 1e-01})
res_EGARCH.summary()
Fuera[24]: Iteración: 1, Cuenta de funciones: 11, Negativo LLF: -1966.
Resultados del modelo AR-EGARCH
Modelo medio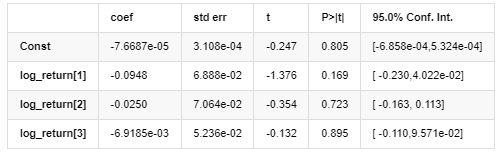
Modelo de volatilidad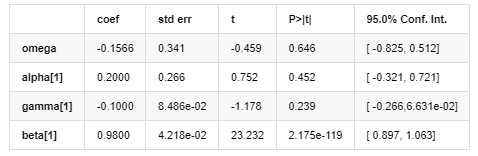
Distribución
Estimador de covarianza: robusto
La ecuación de volatilidad de EGARCH proporcionada por la biblioteca ARCH se describe de la siguiente manera: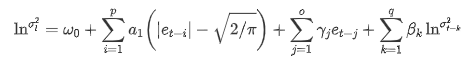
sustitución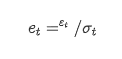
La ecuación de regresión condicional de la volatilidad se puede obtener de la siguiente manera: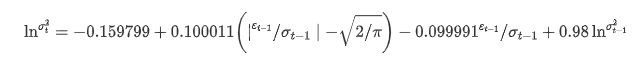
Entre ellos, el coeficiente estimado del término simétrico γ es menor que el intervalo de confianza, lo que indica que existe una
Combinados con la volatilidad prevista combinada, los resultados se comparan con la volatilidad real de la muestra de la siguiente manera:
En el [28]:
def recursive_forecast(pd_dataframe):
window = 280
model = 'EGARCH'
index = kline_test[1:].index
end_loc = np.where(index >= kline_test.index[window])[0].min()
forecasts = {}
for i in range(len(kline_test[1:]) - window + 2):
mod = arch_model(pd_dataframe['log_return'][1:], mean='AR', vol=model,
lags=3, p=2, o=0, q=1, dist='ged')
res = mod.fit(last_obs=i+end_loc, disp='off', options={'ftol': 1e03})
temp = res.forecast().variance
fcast = temp.iloc[i + end_loc - 1]
forecasts[fcast.name] = fcast
forecasts = pd.DataFrame(forecasts).T
pd_dataframe['recursive_{}'.format(model)] = forecasts['h.1']
evaluate(pd_dataframe, 'realized_volatility_1_hour', 'recursive_{}'.format(model))
pd_dataframe['recursive_{}'.format(model)]
recursive_forecast(kline_test)
Fuera de juego[28]: El error absoluto medio (MAE): 0,0201 Error promedio en porcentaje absoluto (MAPE): 122 Error de la raíz media cuadrada (RMSE): 0,0279
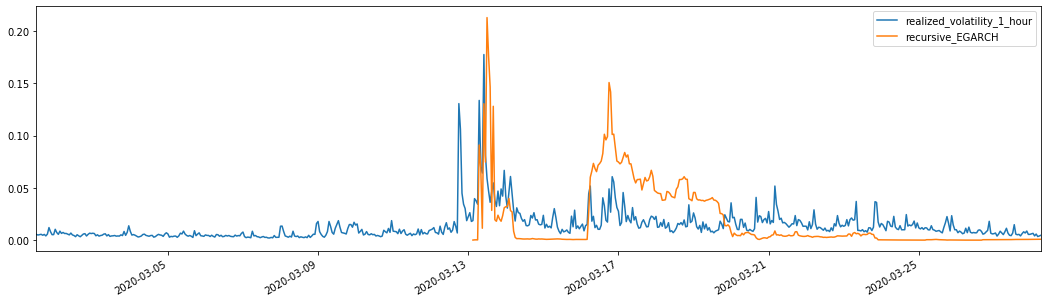
Se puede ver que EGARCH es más sensible a la volatilidad y coincide mejor con la volatilidad que ARCH y GARCH.
8. Evaluación de las predicciones de volatilidad
Los datos por hora se seleccionan en función de la muestra, y el siguiente paso es predecir una hora por delante. Seleccionamos la volatilidad prevista de las primeras 10 horas de los tres modelos, con RV como la volatilidad de referencia. El valor de error comparativo es el siguiente:
En [29]:
compare_ARCH_X = pd.DataFrame()
compare_ARCH_X['original']=kline_test['realized_volatility_1_hour']
compare_ARCH_X['arch']=kline_test['recursive_ARCH']
compare_ARCH_X['arch_diff']=compare_ARCH_X['original']-np.abs(compare_ARCH_X['arch'])
compare_ARCH_X['garch']=kline_test['recursive_GARCH']
compare_ARCH_X['garch_diff']=compare_ARCH_X['original']-np.abs(compare_ARCH_X['garch'])
compare_ARCH_X['egarch']=kline_test['recursive_EGARCH']
compare_ARCH_X['egarch_diff']=compare_ARCH_X['original']-np.abs(compare_ARCH_X['egarch'])
compare_ARCH_X = compare_ARCH_X[280:]
compare_ARCH_X.head(10)
Fuera de juego[29]: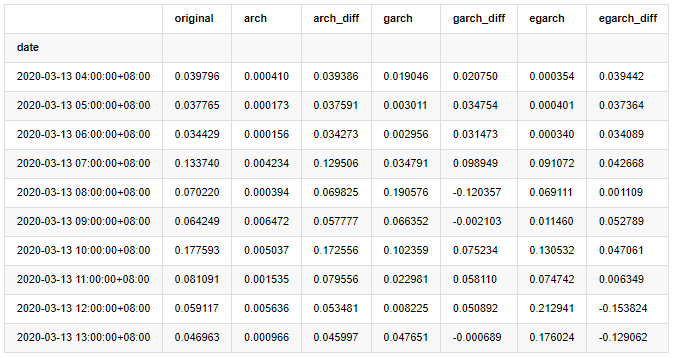
En el [30]:
compare_ARCH_X_diff = pd.DataFrame(index=['ARCH','GARCH','EGARCH'], columns=['head 1 step', 'head 10 steps', 'head 100 steps'])
compare_ARCH_X_diff['head 1 step']['ARCH'] = compare_ARCH_X['arch_diff']['2020-03-13 04:00:00+08:00']
compare_ARCH_X_diff['head 10 steps']['ARCH'] = np.mean(compare_ARCH_X['arch_diff'][:10])
compare_ARCH_X_diff['head 100 steps']['ARCH'] = np.mean(compare_ARCH_X['arch_diff'][:100])
compare_ARCH_X_diff['head 1 step']['GARCH'] = compare_ARCH_X['garch_diff']['2020-03-13 04:00:00+08:00']
compare_ARCH_X_diff['head 10 steps']['GARCH'] = np.mean(compare_ARCH_X['garch_diff'][:10])
compare_ARCH_X_diff['head 100 steps']['GARCH'] = np.mean(compare_ARCH_X['garch_diff'][:100])
compare_ARCH_X_diff['head 1 step']['EGARCH'] = compare_ARCH_X['egarch_diff']['2020-03-13 04:00:00+08:00']
compare_ARCH_X_diff['head 10 steps']['EGARCH'] = np.mean(compare_ARCH_X['egarch_diff'][:10])
compare_ARCH_X_diff['head 100 steps']['EGARCH'] = np.abs(np.mean(compare_ARCH_X['egarch_diff'][:100]))
compare_ARCH_X_diff
Fuera de juego[30]: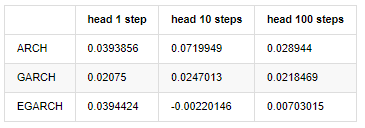
Se han realizado varias pruebas, en los resultados de predicción de la primera hora, la probabilidad del error más pequeño de EGARCH es relativamente grande, pero la diferencia general no es particularmente obvia; Hay algunas diferencias obvias en los efectos de predicción a corto plazo; EGARCH tiene la capacidad de predicción más destacada en la predicción a largo plazo
En [31]:
compare_ARCH_X = pd.DataFrame()
compare_ARCH_X['Model'] = ['ARCH','GARCH','EGARCH']
compare_ARCH_X['RMSE'] = [get_rmse(kline_test['realized_volatility_1_hour'][280:320],kline_test['recursive_ARCH'][280:320]),
get_rmse(kline_test['realized_volatility_1_hour'][280:320],kline_test['recursive_GARCH'][280:320]),
get_rmse(kline_test['realized_volatility_1_hour'][280:320],kline_test['recursive_EGARCH'][280:320])]
compare_ARCH_X['MAPE'] = [get_mape(kline_test['realized_volatility_1_hour'][280:320],kline_test['recursive_ARCH'][280:320]),
get_mape(kline_test['realized_volatility_1_hour'][280:320],kline_test['recursive_GARCH'][280:320]),
get_mape(kline_test['realized_volatility_1_hour'][280:320],kline_test['recursive_EGARCH'][280:320])]
compare_ARCH_X['MASE'] = [get_mape(kline_test['realized_volatility_1_hour'][280:320],kline_test['recursive_ARCH'][280:320]),
get_mape(kline_test['realized_volatility_1_hour'][280:320],kline_test['recursive_GARCH'][280:320]),
get_mape(kline_test['realized_volatility_1_hour'][280:320],kline_test['recursive_EGARCH'][280:320])]
compare_ARCH_X
Fuera[31]: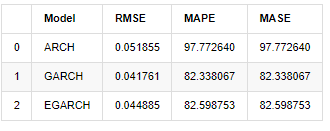
En términos de indicadores, GARCH y EGARCH presentan cierta mejora en comparación con ARCH, pero la diferencia no es particularmente obvia.
9. Conclusión
A partir del análisis simple anterior, se puede encontrar que la tasa de retorno logarítmico de Bitcoin no se ajusta a la distribución normal, que se caracteriza por colas gruesas, y la volatilidad tiene un efecto de agregación y apalancamiento, al tiempo que muestra una obvia heterogeneidad condicional.
En la predicción y evaluación de la tasa de retorno logarítmico, la capacidad de predicción estática intra muestra del modelo ARMA es significativamente mejor que la dinámica, lo que muestra que el método de rodamiento es obviamente mejor que el método iterativo, y puede evitar los problemas de sobreajuste y amplificación de error.
Además, cuando se trata del fenómeno de cola gruesa de Bitcoin, es decir, la distribución de cola gruesa de los rendimientos, se encuentra que la distribución GED (error generalizado) es mejor que la distribución t y la distribución normal significativamente, lo que puede mejorar la precisión de medición del riesgo de cola. Al mismo tiempo, EGARCH tiene más ventajas en la predicción de la volatilidad a largo plazo, lo que explica bien la heteroscedasticidad de la muestra.
Todo el proceso de modelado está lleno de diversas suposiciones audaces, y no hay identificación de consistencia dependiendo de la validez, por lo que solo podemos verificar cuidadosamente algunos fenómenos.
En comparación con los mercados tradicionales, la disponibilidad de datos de alta frecuencia de Bitcoin es más fácil. La medición
Sin embargo, lo anterior se limita a la teoría. Los datos de mayor frecuencia pueden proporcionar un análisis más preciso del comportamiento de los comerciantes. No solo pueden proporcionar pruebas más confiables para modelos teóricos financieros, sino también proporcionar información más abundante para la toma de decisiones para los comerciantes, incluso apoyar la predicción del flujo de información y el flujo de capital, y ayudar a diseñar estrategias comerciales cuantitativas más precisas. Sin embargo, el mercado de Bitcoin es tan volátil que los datos históricos demasiado largos no pueden coincidir con la información efectiva para la toma de decisiones, por lo que los datos de alta frecuencia sin duda traerán mayores ventajas de mercado a los inversores de moneda digital.
Por último, si crees que el contenido anterior es útil, también puedes ofrecerme un poco de BTC para comprarme una taza de Coca-Cola.
- Cuantificar el análisis fundamental en el mercado de criptomonedas: ¡Deja que los datos hablen por sí mismos!
- La investigación cuantitativa básica del círculo monetario - ¡No confíes más en los profesores de idiomas, los datos hablan objetivamente!
- Una herramienta esencial en el campo de la transacción cuantitativa - inventor de módulos de exploración de datos cuantitativos
- Dominarlo todo - Introducción a FMZ Nueva versión de la terminal de negociación (con el código fuente de TRB Arbitrage)
- Conozca todo acerca de la nueva versión del terminal de operaciones de FMZ (con código de código de TRB)
- FMZ Quant: Análisis de ejemplos de diseño de requisitos comunes en el mercado de criptomonedas (II)
- Cómo explotar robots de venta sin cerebro con una estrategia de alta frecuencia en 80 líneas de código
- Cuantificación FMZ: Desarrollo de casos de diseño de necesidades comunes en el mercado de criptomonedas (II)
- Cómo utilizar una estrategia de alta frecuencia de 80 líneas de código para explotar y vender robots sin cerebro
- FMZ Quant: Análisis de ejemplos de diseño de requisitos comunes en el mercado de criptomonedas (I)
- Cuantificación FMZ: Desarrollo de casos de diseño de necesidades comunes en el mercado de criptomonedas (1)