5.4 Pourquoi nous avons besoin d'un test hors échantillon
Auteur:La bonté, Créé: 2019-05-10 09:13:53, mis à jour:Résumé
Dans la section précédente, nous vous avons montré comment lire le rapport de performance de backtesting de stratégie en se concentrant sur plusieurs indicateurs de performance importants. En fait, il n'est pas difficile d'écrire une stratégie qui fait des profits dans le rapport de performance de backtesting. Il est difficile d'évaluer si cette stratégie continuera à être efficace sur le marché réel à l'avenir.
Le backtesting n'est pas équivalent au marché réel
Il est vrai que ce résultat de backtesting correspond parfaitement à l'état d'un marché qu'ils ont observé, mais une fois que la stratégie de trading est mise dans une bataille à long terme, ils constateront que la stratégie n'est en fait pas efficace.
J'ai vu de nombreuses stratégies de trading, et le taux de réussite peut atteindre jusqu'à 50% lors du backtesting. Sous la prémisse d'un taux de gain aussi élevé, il y a toujours un ratio de profit et de perte plus élevé de 1: 1. Cependant, une fois que ces stratégies sont mises en pratique, elles perdent toutes de l'argent. Il y a de nombreuses raisons à cela. Parmi ces raisons, l'échantillon de données est trop petit est le principal, ce qui conduit à l'écart des données.
Cependant, la négociation est une chose tellement enchevêtrée, et c'est très clair par la suite, mais si nous revenons à l'original, nous nous sentons toujours dépassés. Cela implique la cause fondamentale de la quantification - les limites des données historiques. donc, si nous n'utilisons que des données historiques limitées pour tester la stratégie de négociation, il est difficile d'éviter le problème de
Qu'est-ce qu'un test hors échantillon?
Comment utiliser pleinement les données limitées pour tester scientifiquement la stratégie de trading lorsque les données sont limitées? La réponse est la méthode de test hors échantillon. Pendant le backtesting, les données historiques sont divisées en deux segments en fonction de la séquence temporelle. Le segment précédent de données est utilisé pour l'optimisation de la stratégie, appelé ensemble de formation, et le dernier segment de données est utilisé pour le test hors échantillon, appelé ensemble de test.
Si votre stratégie est toujours valide, puis optimiser plusieurs ensembles de meilleurs paramètres dans les données de l'ensemble de formation, et appliquer ces ensembles de paramètres aux données de l'ensemble de test pour backtest à nouveau. Idéalement, les résultats de backtest devraient être presque les mêmes que les ensembles de formation, ou la différence est dans une plage raisonnable. Alors on peut dire que cette stratégie est relativement efficace.
Mais si une stratégie fonctionne bien dans l'ensemble de formation, mais que l'ensemble de test fonctionne mal, ou change beaucoup, et que les autres paramètres utilisés restent les mêmes, alors la stratégie peut avoir un biais de migration de données.
Par exemple, supposons que vous souhaitiez tester en arrière la barre d'armature des contrats à terme sur matières premières. Maintenant que cette barre d'armature a des données pour environ 10 ans (2009 ~ 2019), vous pouvez utiliser les données de 2009 à 2015 comme ensemble de formation, de 2015 à 2019, utilisées comme ensemble de test. Si le meilleur paramètre défini dans l'ensemble de formation est (15, 90), (5, 50), (10, 100)... alors nous mettons ces ensembles de paramètres dans l'ensemble de test. En comparant ces deux rapports de performance de backtest et les courbes de fonds, nous déterminons si leur différence est dans une plage raisonnable.
Si vous n'utilisez pas le test hors échantillon, utilisez simplement directement les données de 2009 à 2019 pour tester la stratégie.
Essai avancé hors échantillon
Comme mentionné ci-dessus, en raison du manque de données historiques, il est judicieux de diviser les données en deux parties pour former des données à l'intérieur et à l'extérieur de l'échantillon.
Le principe de base du test récursif: utiliser les données historiques longues précédentes pour former le modèle, puis utiliser les données relativement courtes pour tester le modèle, puis déplacer continuellement la fenêtre de temps pour récupérer les données, répéter les étapes de formation et de test.
-
données de formation: 2000 à 2001, données d'essais: 2002;
-
Les données relatives à la formation: 2001 à 2002, les données relatives aux essais: 2003;
-
données de formation: de 2002 à 2003, données d'essais: de 2004;
-
données de formation: de 2003 à 2004, données d'essais: de 2005;
-
données de formation: 2004 à 2005, données d'essais: 2006;
...et ainsi de suite...
Enfin, les résultats des essais (2002, 2003, 2004, 2005, 2006...) ont été analysés statistiquement afin d'évaluer de manière exhaustive le rendement de la stratégie.
Le schéma suivant peut expliquer le principe du test récursif de manière intuitive:
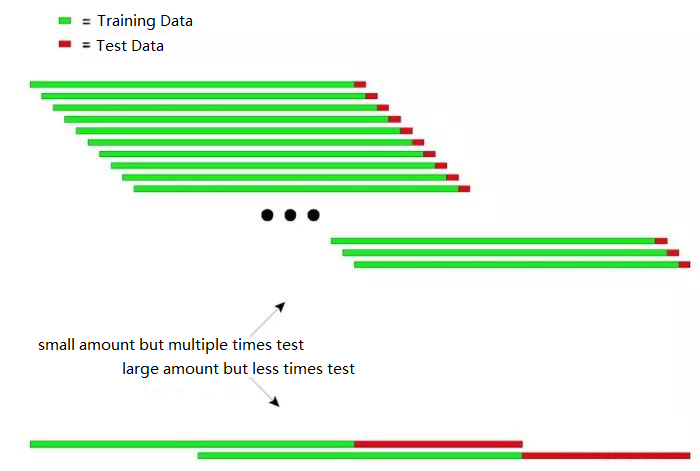
La figure ci-dessus montre deux méthodes de test récursif.
Le premier type: petite quantité mais test répété
Le deuxième type: grande quantité mais moins de fois d'essai
Dans les applications pratiques, plusieurs essais peuvent être effectués en modifiant la longueur des données d'essai pour déterminer la stabilité du modèle en réponse aux données non stationnaires.
Le principe de base de l'essai de vérification croisée est de diviser toutes les données en N parties, d'utiliser les parties N-1 pour l'entraînement à chaque fois et d'utiliser la partie restante pour l'essai.
De 2000 à 2003, il est divisé en quatre parties selon la répartition annuelle.
-
données de formation: 2001-2003, données d'essais: 2000;
-
Données de formation: 2000-2002, données d'essais: 2003;
-
Les données relatives à la formation: 2000, 2001, 2003, les données relatives aux essais: 2002;
-
Les données relatives à la formation: 2000, 2002, 2003, les données relatives aux essais: 2001;
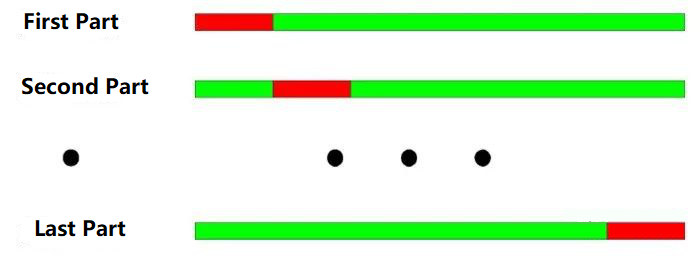
Comme le montre la figure ci-dessus: le plus grand avantage du test de vérification croisée est de tirer pleinement parti des données limitées, et chaque donnée de formation est également les données du test.
-
Lorsque les données sur les prix ne sont pas stables, les résultats des tests du modèle sont souvent peu fiables. Par exemple, utilisez les données de 2008 pour la formation et les données de 2005 pour les tests. Il est très probable que l'environnement du marché en 2008 ait beaucoup changé par rapport à 2005, de sorte que les résultats des tests du modèle ne sont pas crédibles.
-
Comme pour le premier, dans le test de vérification croisée, si le modèle est formé avec les données les plus récentes et que le modèle est testé avec des données plus anciennes, cela n'est pas très logique en soi.
En outre, lors du test du modèle de stratégie quantitative, le test récursif et le test de vérification croisée ont rencontré des problèmes de chevauchement des données.
Lors du développement d'un modèle de stratégie de trading, la plupart des indicateurs techniques sont basés sur des données historiques d'une certaine période. Par exemple, en utilisant des indicateurs de tendance pour calculer les données historiques des 50 derniers jours, mais pour le jour de trading suivant, qui est à nouveau calculé à partir des données des 50 premiers jours de la journée de trading, les données pour calculer les deux indicateurs sont les mêmes pendant 49 jours.
Le chevauchement des données peut avoir les effets suivants:
-
Le changement lent des résultats prédits par le modèle conduit à un changement lent des positions, qui est l'hystérésis des indicateurs que nous disons souvent.
-
En raison de la corrélation séquentielle causée par des données répétées, les résultats de certains tests statistiques ne sont pas fiables.
Une bonne stratégie de trading devrait être rentable à l'avenir. les tests hors échantillon, en plus de détecter objectivement les stratégies de trading, sont plus efficaces pour gagner du temps pour les traders quantitatifs.
Si toutes les données historiques avant le point de temps pour l'optimisation des paramètres sont distinguées, et les données sont divisées en données dans l'échantillon et les données à l'extérieur de l'échantillon, le paramètre est optimisé en utilisant les données de l'échantillon, puis l'échantillon à l'extérieur de l'échantillon est utilisé pour le test hors échantillon.
Pour résumer
Tout comme le trading lui-même, nous ne pouvons jamais revenir en arrière dans le temps et prendre une décision correcte pour nous-mêmes.
Cependant, même avec les énormes données historiques, face à un avenir sans fin et imprévisible, l'histoire est extrêmement rare. Par conséquent, le système de trading basé sur l'histoire finira par couler avec le temps. Parce que l'histoire ne peut pas épuiser l'avenir. Par conséquent, un système de trading complet d'attentes positives doit être soutenu par ses principes et sa logique inhérents.
Faites confiance, mais vérifiez.
Exercices après l'école
-
Quels sont les phénomènes de la vie réelle qui sont les préjugés des survivants?
-
Utilisez la plateforme FMZ Quant pour comparer le backtest à l'entrée et à l'extérieur des échantillons.
- Quand ajouter un échange de maté?
- Pourquoi le dernier appel de bad system peut-il apparaître lorsque vous installez un hôte linux sur votre téléphone via un simulateur de terminal?
- Pourriez-vous modifier le nombre de profondeurs que GetDepth renvoie?
- Comment déployer un robot sur local, win ou mac
- Une erreur lors de l'ajout d'un échange de jetons futurs.
- L'administrateur peut-il fournir le code de connexion WSS de Deribit?
- BitMax utilise l'agrégation
- S'il vous plaît demander à la programmation visuelle comment enregistrer le prix le plus élevé
- Est-il possible d'obtenir des offres pour plusieurs paires de devises numériques en même temps?
- 5.5 Optimisation de la stratégie de négociation
- 5.3 Comment lire le rapport de performance de la stratégie
- Questions fréquemment posées
- Dans le cas d'une crypto-monnaie, si le cycle de base d'une simulation de ticks est d'une minute, combien de ticks par minute peut-on simuler?
- Quelques stratégies de quantification des bitcoins et des monnaies numériques qui valent la peine d'être apprises
- 5.2 Comment effectuer un backtesting quantitatif du trading
- Dans la revue de stratégie de crypto-monnaie, la façon de prendre la photo est-elle de fermer la barre actuelle ou d'ouvrir la barre suivante?
- Demandez-vous si le volume des transactions en liquidation est faible dans la révision de la stratégie de crypto-monnaie, pourquoi les transactions ne sont souvent pas conclues, les positions sont geléesAmount > 0
- 5.1 Le sens et le piège du backtesting
- 4.6 Comment mettre en œuvre des stratégies dans le langage C++
- Il y a aussi une question sur Emma.