Réflexions sur les stratégies de négociation à haute fréquence (1)
Auteur:Je ne sais pas., Créé à partir de: 2023-08-04 13:47:39, Mis à jour à partir de: 2023-09-12 15:50:10
Réflexions sur les stratégies de négociation à haute fréquence (1)
J'ai écrit deux articles sur le commerce à haute fréquence des monnaies numériques, à savoir
La source des profits de haute fréquence
Dans mes articles précédents, j'ai mentionné que les stratégies à haute fréquence sont particulièrement appropriées pour les marchés aux fluctuations extrêmement volatiles. Les changements de prix d'un instrument de trading dans un court laps de temps consistent en tendances et oscillations globales. Bien qu'il soit en effet rentable si nous pouvons prédire avec précision les changements de tendance, c'est aussi l'aspect le plus difficile. Dans cet article, je vais principalement me concentrer sur les stratégies de fabricant à haute fréquence et je n'approfondirai pas la prédiction de tendance.
Problèmes à résoudre
-
Le premier problème dans la mise en œuvre d'une stratégie qui place à la fois des ordres d'achat et de vente est de déterminer où placer ces ordres. Plus les ordres sont placés à proximité de la profondeur du marché, plus la probabilité d'exécution est élevée. Cependant, dans des conditions de marché très volatiles, le prix auquel un ordre est instantanément exécuté peut être loin de la profondeur du marché, ce qui entraîne un profit insuffisant. D'autre part, placer des ordres trop loin réduit la probabilité d'exécution. C'est un problème d'optimisation qui doit être résolu.
-
Le contrôle des positions est crucial pour gérer le risque. Une stratégie ne peut accumuler des positions excessives pendant de longues périodes. Cela peut être résolu en contrôlant la distance et la quantité des ordres passés, ainsi qu'en fixant des limites aux positions globales.
Pour atteindre les objectifs ci-dessus, la modélisation et l'estimation sont nécessaires pour divers aspects tels que les probabilités d'exécution, les bénéfices des exécutions et l'estimation du marché. Il existe de nombreux articles et documents disponibles sur ce sujet, en utilisant des mots clés tels que
Données requises
Binance fournitdonnées téléchargeablespour les transactions individuelles et les meilleurs ordres d'achat/achat. Les données de profondeur peuvent être téléchargées via leur API en étant mises sur liste blanche, ou elles peuvent être collectées manuellement. Pour les besoins du backtesting, les données commerciales agrégées sont suffisantes. Dans cet article, nous utiliserons l'exemple des données HOOKUSDT-aggTrades-2023-01-27.
Dans [1]:
from datetime import date,datetime
import time
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
Les données commerciales individuelles comprennent les éléments suivants:
- Agg_trade_id: L'identifiant de la transaction agrégée.
- prix: le prix auquel la transaction a été exécutée.
- quantité: la quantité de la transaction.
- le premier_trade_id: dans les cas où plusieurs transactions sont agrégées, il s'agit de l'ID de la première transaction.
- Last_trade_id: l'identifiant de la dernière transaction dans l'agrégation.
- transact_time: l'horodatage de l'exécution de la transaction.
- is_buyer_maker: Indique la direction de la transaction.
True représente un ordre d'achat exécuté en tant que créateur, tandis qu'un ordre de vente est exécuté en tant que preneur.
On peut voir qu'il y a eu 660 000 transactions exécutées ce jour-là, ce qui indique un marché très actif.
Dans [4]:
trades = pd.read_csv('COMPUSDT-aggTrades-2023-07-02.csv')
trades
Extrait [4]: Je ne veux pas de toi, je veux de toi, je veux de toi, je veux de toi, je veux de toi.
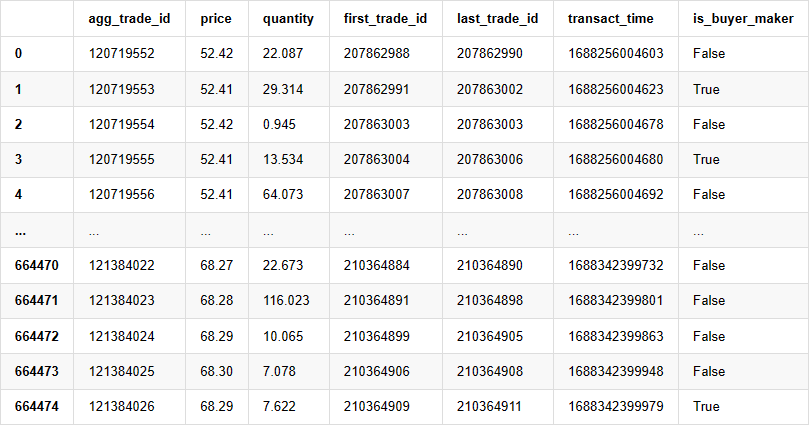
664475 lignes × 7 colonnes
Modélisation du montant des échanges individuels
Premièrement, les données sont traitées en divisant les ordres d'achat d'origine en deux groupes: les ordres d'achat exécutés en tant que créateurs et les ordres de vente exécutés en tant que preneurs. En outre, les données d'achat d'origine agrégées combinent les ordres d'achat exécutés en même temps, au même prix et dans la même direction en un seul point de données. Par exemple, s'il y a un seul ordre d'achat avec un volume de 100, il peut être divisé en deux ordres avec des volumes de 60 et 40, respectivement, si les prix sont différents. Cela peut affecter l'estimation des volumes d'ordre d'achat. Par conséquent, il est nécessaire d'agréger à nouveau les données en fonction du transaction_time. Après cette deuxième agrégation, le volume de données est réduit de 140 000 enregistrements.
Dans [6]:
trades['date'] = pd.to_datetime(trades['transact_time'], unit='ms')
trades.index = trades['date']
buy_trades = trades[trades['is_buyer_maker']==False].copy()
sell_trades = trades[trades['is_buyer_maker']==True].copy()
buy_trades = buy_trades.groupby('transact_time').agg({
'agg_trade_id': 'last',
'price': 'last',
'quantity': 'sum',
'first_trade_id': 'first',
'last_trade_id': 'last',
'is_buyer_maker': 'last',
'date': 'last',
'transact_time':'last'
})
sell_trades = sell_trades.groupby('transact_time').agg({
'agg_trade_id': 'last',
'price': 'last',
'quantity': 'sum',
'first_trade_id': 'first',
'last_trade_id': 'last',
'is_buyer_maker': 'last',
'date': 'last',
'transact_time':'last'
})
buy_trades['interval']=buy_trades['transact_time'] - buy_trades['transact_time'].shift()
sell_trades['interval']=sell_trades['transact_time'] - sell_trades['transact_time'].shift()
Dans [10]:
print(trades.shape[0] - (buy_trades.shape[0]+sell_trades.shape[0]))
En dehors [10]: Les produits suivants
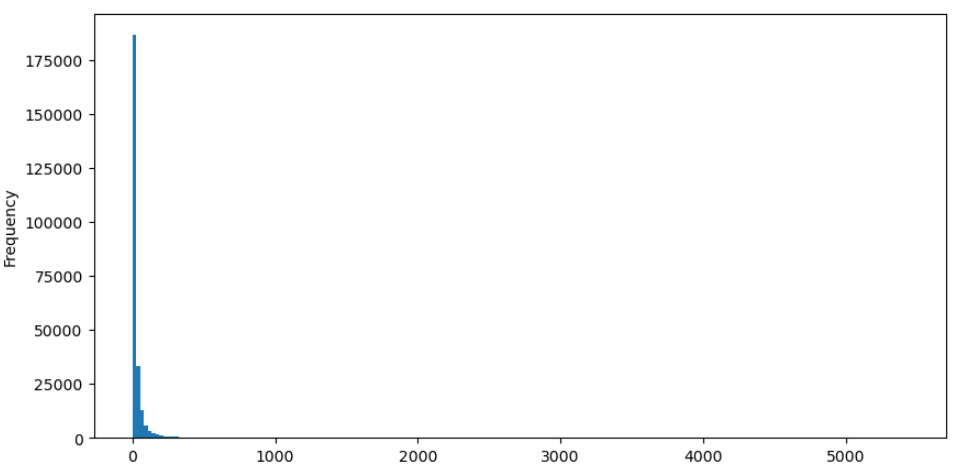
Prenons l'exemple des ordres d'achat, nous allons d'abord tracer un histogramme. On peut observer qu'il y a un effet longue queue significatif, la majorité des données étant concentrées vers la partie la plus à gauche de l'histogramme.
Dans [36]:
buy_trades['quantity'].plot.hist(bins=200,figsize=(10, 5));
En dehors [36]:
Pour faciliter l'observation, nous allons couper la queue et analyser les données. On peut observer qu'au fur et à mesure que le montant des transactions augmente, la fréquence d'apparition diminue et le taux de diminution devient plus rapide.
Dans [37]:
buy_trades['quantity'][buy_trades['quantity']<200].plot.hist(bins=200,figsize=(10, 5));
En dehors [37]:
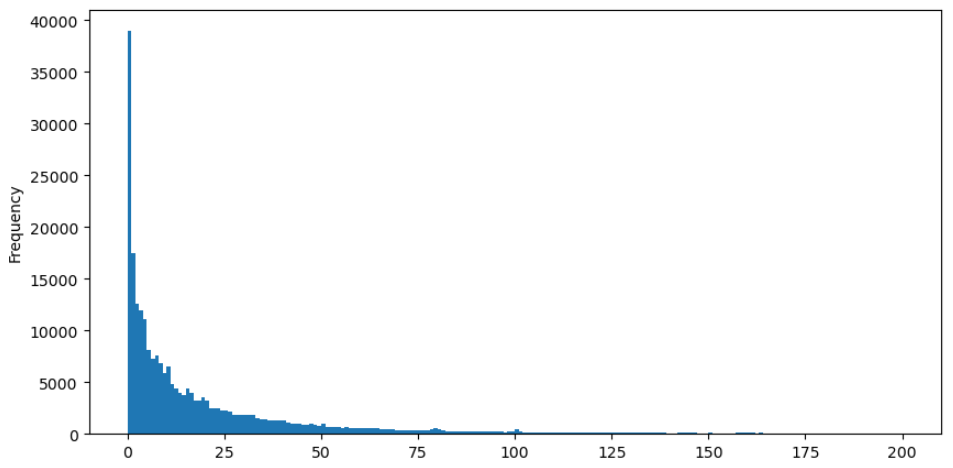
Il y a eu de nombreuses études sur la distribution des quantités de transactions. Il a été constaté que les quantités de transactions suivent une distribution de la loi de puissance, également connue sous le nom de distribution de Pareto, qui est une distribution de probabilité commune en physique statistique et en sciences sociales. Dans une distribution de loi de puissance, la probabilité d'un événement de la taille (ou de la fréquence) est proportionnelle à un exponent négatif de la taille de cet événement.
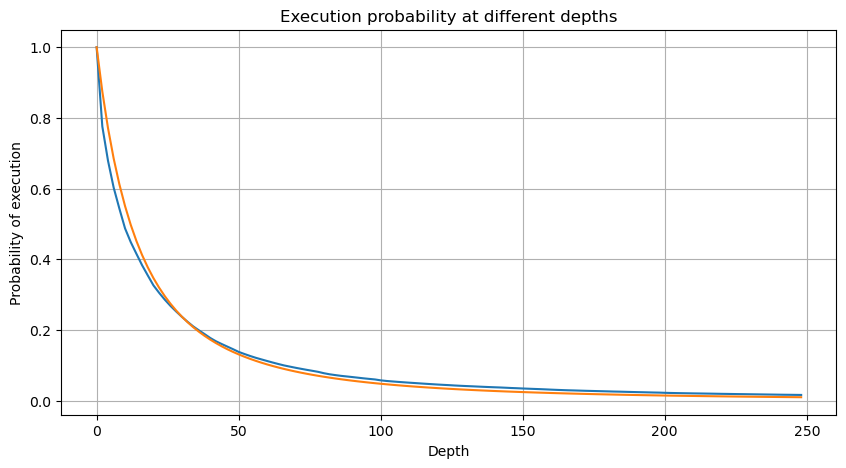
Le graphique suivant représente la probabilité que les montants des transactions dépassent une certaine valeur. La ligne bleue représente la probabilité réelle, tandis que la ligne orange représente la probabilité simulée. Veuillez noter que nous n'entrerons pas dans les paramètres spécifiques à ce stade.
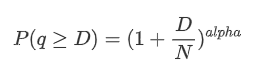
Ici, N est le paramètre de normalisation. Nous choisirons le montant moyen du commerce, M, et définirons alpha à -2.06. L'estimation spécifique d'alpha peut être obtenue en calculant la valeur P lorsque D=N. Plus précisément, alpha = log (((P(d>M)) /log ((2). Le choix de différents points peut entraîner de légères différences dans la valeur d'alpha.
Dans [55]:
depths = range(0, 250, 2)
probabilities = np.array([np.mean(buy_trades['quantity'] > depth) for depth in depths])
alpha = np.log(np.mean(buy_trades['quantity'] > mean_quantity))/np.log(2)
mean_quantity = buy_trades['quantity'].mean()
probabilities_s = np.array([(1+depth/mean_quantity)**alpha for depth in depths])
plt.figure(figsize=(10, 5))
plt.plot(depths, probabilities)
plt.plot(depths, probabilities_s)
plt.xlabel('Depth')
plt.ylabel('Probability of execution')
plt.title('Execution probability at different depths')
plt.grid(True)
À l'extérieur[55]:
Dans [56]:
plt.figure(figsize=(10, 5))
plt.grid(True)
plt.title('Diff')
plt.plot(depths, probabilities_s-probabilities);
À l'extérieur[56]:
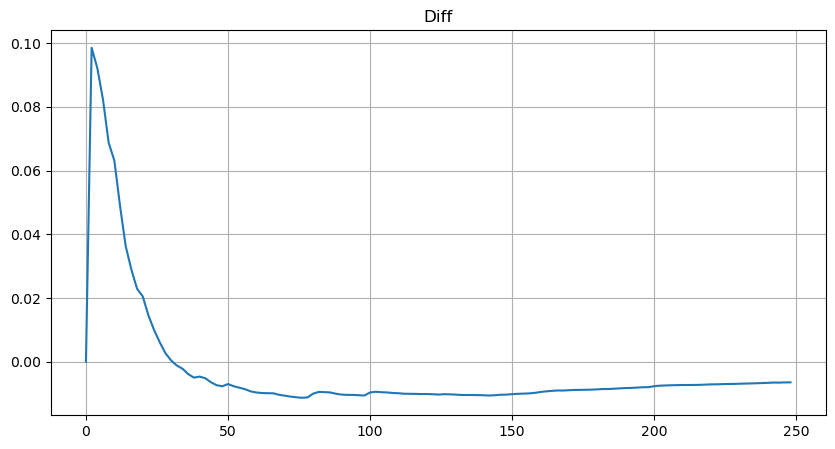
Cependant, cette estimation n'est qu'approximative, comme le montre le graphique où nous traçons la différence entre les valeurs simulées et réelles. Lorsque le montant du commerce est faible, l'écart est significatif, même approchant 10%. Bien que la sélection de différents points lors de l'estimation des paramètres puisse améliorer la précision de la probabilité de ce point spécifique, elle ne résout pas le problème d'écart dans son ensemble. Cette divergence découle de la différence entre la distribution de la loi de puissance et la distribution réelle. Pour obtenir des résultats plus précis, l'équation de la distribution de la loi de puissance doit être modifiée. Le processus spécifique n'est pas élaboré ici, mais en résumé, après un moment de réflexion, on constate que l'équation réelle devrait être la suivante:
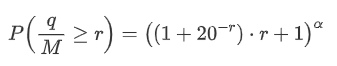
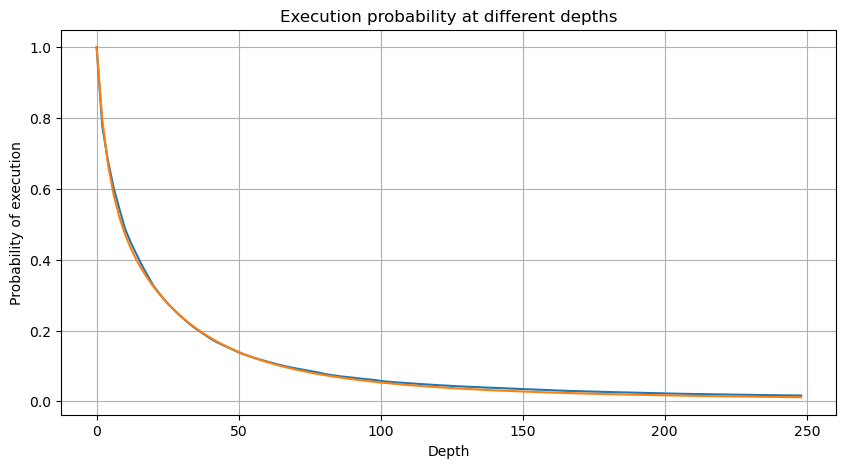
Pour simplifier, utilisons r = q / M pour représenter le montant du commerce normalisé. Nous pouvons estimer les paramètres en utilisant la même méthode qu'avant. Le graphique suivant montre qu'après la modification, l'écart maximum n'est pas supérieur à 2%. En théorie, d'autres ajustements peuvent être effectués, mais ce niveau de précision est déjà suffisant.
Dans [52]:
depths = range(0, 250, 2)
probabilities = np.array([np.mean(buy_trades['quantity'] > depth) for depth in depths])
mean = buy_trades['quantity'].mean()
alpha = np.log(np.mean(buy_trades['quantity'] > mean))/np.log(2.05)
probabilities_s = np.array([(((1+20**(-depth/mean))*depth+mean)/mean)**alpha for depth in depths])
plt.figure(figsize=(10, 5))
plt.plot(depths, probabilities)
plt.plot(depths, probabilities_s)
plt.xlabel('Depth')
plt.ylabel('Probability of execution')
plt.title('Execution probability at different depths')
plt.grid(True)
À l'extérieur[52]:
Dans [53]:
plt.figure(figsize=(10, 5))
plt.grid(True)
plt.title('Diff')
plt.plot(depths, probabilities_s-probabilities);
À l'extérieur[53]:
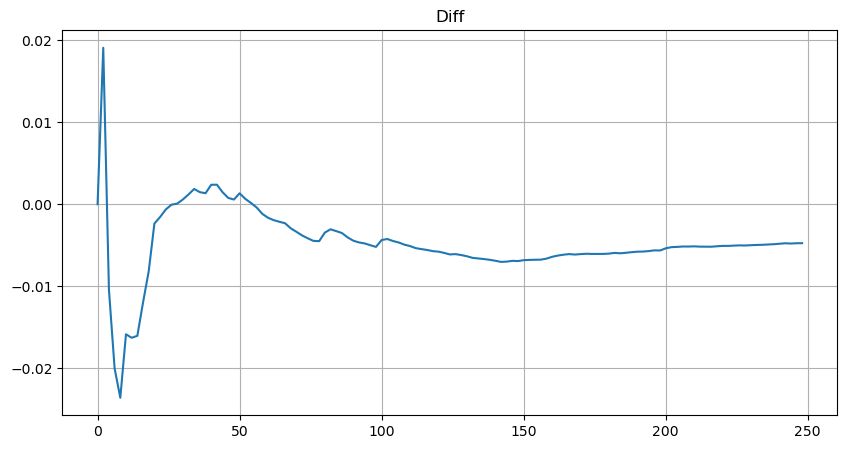
Avec l'équation estimée pour la distribution du montant du commerce, il est important de noter que les probabilités dans l'équation ne sont pas les probabilités réelles, mais les probabilités conditionnelles. À ce stade, nous pouvons répondre à la question: quelle est la probabilité que le prochain ordre soit supérieur à une certaine valeur?
À ce stade, la longueur du texte est déjà assez longue, et il reste encore beaucoup de questions auxquelles il faut répondre.
- Delta contre les options Bitcoin avec une courbe souriante
- Réflexions sur les stratégies de négociation à haute fréquence (5)
- Réflexions sur les stratégies de négociation à haute fréquence (4)
- Réflexion sur la stratégie de trading à haute fréquence (5)
- Réflexion sur les stratégies de trading à haute fréquence (4)
- Réflexions sur les stratégies de négociation à haute fréquence (3)
- Réflexion sur les stratégies de trading à haute fréquence (3)
- Réflexions sur les stratégies de négociation à haute fréquence (2)
- Réflexion sur la stratégie de trading à haute fréquence (2)
- Réflexion sur les stratégies de trading à haute fréquence (1)
- Document de description de la configuration des titres Futu
- FMZ Quant Uniswap V3 Guide des opérations liées à la liquidité des fonds communs de change (partie 1)
- FMZ quantifier Uniswap V3 pour les opérations liées à la fluidité des bassins de change (part 1)