Réflexions sur les stratégies de négociation à haute fréquence (5)
Auteur:Je ne sais pas., Créé à: 2023-08-10 15:57:27, Mis à jour à: 2023-09-12 15:51:54
Réflexions sur les stratégies de négociation à haute fréquence (5)
Dans l'article précédent, diverses méthodes de calcul du prix moyen ont été introduites, et un prix moyen révisé a été proposé.
Données requises
Nous avons besoin de données de flux de commandes et de données de profondeur pour les dix premiers niveaux du carnet de commandes, collectées à partir de la négociation en direct avec une fréquence de mise à jour de 100 ms. Pour des raisons de simplicité, nous n'inclurons pas de mises à jour en temps réel pour les prix d'enchères et de demande. Pour réduire la taille des données, nous n'avons conservé que 100 000 lignes de données de profondeur et séparé les données de marché tick-by-tick en colonnes individuelles.
Dans [1]:
from datetime import date,datetime
import time
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import ast
%matplotlib inline
Dans [2]:
tick_size = 0.0001
Dans [3]:
trades = pd.read_csv('YGGUSDT_aggTrade.csv',names=['type','event_time', 'agg_trade_id','symbol', 'price', 'quantity', 'first_trade_id', 'last_trade_id',
'transact_time', 'is_buyer_maker'])
Dans [4]:
trades = trades.groupby(['transact_time','is_buyer_maker']).agg({
'transact_time':'last',
'agg_trade_id': 'last',
'price': 'first',
'quantity': 'sum',
'first_trade_id': 'first',
'last_trade_id': 'last',
'is_buyer_maker': 'last',
})
Dans [5]:
trades.index = pd.to_datetime(trades['transact_time'], unit='ms')
trades.index.rename('time', inplace=True)
trades['interval'] = trades['transact_time'] - trades['transact_time'].shift()
Dans [6]:
depths = pd.read_csv('YGGUSDT_depth.csv',names=['type','event_time', 'transact_time','symbol', 'u1', 'u2', 'u3', 'bids','asks'])
Dans [7]:
depths = depths.iloc[:100000]
Dans [8]:
depths['bids'] = depths['bids'].apply(ast.literal_eval).copy()
depths['asks'] = depths['asks'].apply(ast.literal_eval).copy()
Dans [9]:
def expand_bid(bid_data):
expanded = {}
for j, (price, quantity) in enumerate(bid_data):
expanded[f'bid_{j}_price'] = float(price)
expanded[f'bid_{j}_quantity'] = float(quantity)
return pd.Series(expanded)
def expand_ask(ask_data):
expanded = {}
for j, (price, quantity) in enumerate(ask_data):
expanded[f'ask_{j}_price'] = float(price)
expanded[f'ask_{j}_quantity'] = float(quantity)
return pd.Series(expanded)
# Apply to each line to get a new df
expanded_df_bid = depths['bids'].apply(expand_bid)
expanded_df_ask = depths['asks'].apply(expand_ask)
# Expansion on the original df
depths = pd.concat([depths, expanded_df_bid, expanded_df_ask], axis=1)
Dans [10]:
depths.index = pd.to_datetime(depths['transact_time'], unit='ms')
depths.index.rename('time', inplace=True);
Dans [11]:
trades = trades[trades['transact_time'] < depths['transact_time'].iloc[-1]]
Il s'agit d'un système de négociation des prix de l'échange, qui est un système de négociation des prix de l'échange, qui est un système de négociation des prix.
Dans [14]:
bid_mean_list = []
ask_mean_list = []
for i in range(20):
bid_mean_list.append(round(depths[f'bid_{i}_quantity'].mean(),0))
ask_mean_list.append(round(depths[f'ask_{i}_quantity'].mean(),0))
plt.figure(figsize=(10, 5))
plt.plot(bid_mean_list);
plt.plot(ask_mean_list);
plt.grid(True)
Extrait [1]:
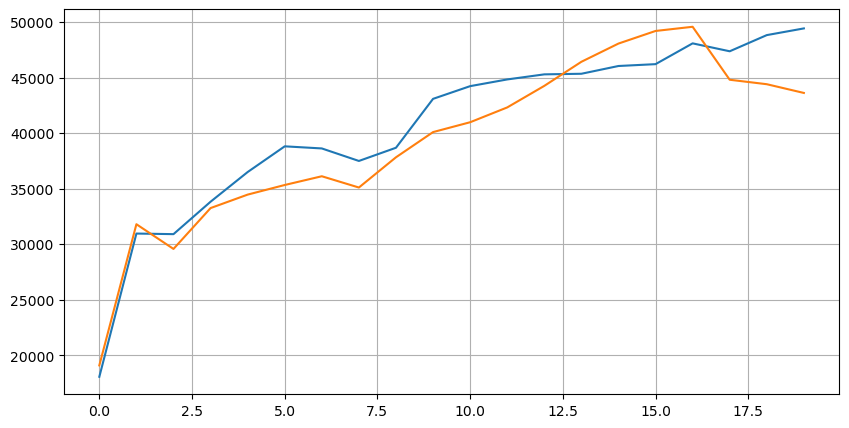
Combinez les données de profondeur avec les données de transaction pour faciliter l'évaluation de l'exactitude de la prédiction. Assurez-vous que les données de transaction sont plus tardives que les données de profondeur. Sans tenir compte de la latence, calculez directement l'erreur au carré moyenne entre la valeur prévue et le prix réel de la transaction. Ceci est utilisé pour mesurer l'exactitude de la prédiction.
D'après les résultats, l'erreur est la plus élevée pour la valeur moyenne des prix d'offre et de demande (mid_price). Cependant, lorsque l'erreur est changée au prix moyen pondéré, elle diminue immédiatement de manière significative. Une amélioration supplémentaire est observée en utilisant le prix moyen pondéré ajusté. Après avoir reçu des commentaires sur l'utilisation de I^3/2 seulement, il a été vérifié et constaté que les résultats étaient meilleurs. Après réflexion, cela est probablement dû aux différentes fréquences d'événements. Lorsque je suis proche de -1 et 1, cela représente des événements à faible probabilité. Afin de corriger ces événements à faible probabilité, l'exactitude de la prédiction des événements à haute fréquence est compromise. Par conséquent, pour hiérarchiser les événements à haute fréquence, certains ajustements ont été apportés (ces paramètres étaient purement d'essai et d'erreur et ont une signification pratique limitée dans le trading en direct).
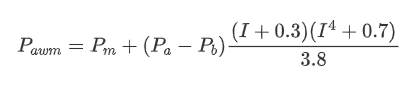
Les résultats se sont légèrement améliorés. Comme mentionné dans l'article précédent, les stratégies devraient s'appuyer sur plus de données pour la prédiction. Avec la disponibilité de plus de profondeur et de données sur les transactions d'ordres, l'amélioration obtenue en se concentrant sur le carnet de commandes est déjà faible.
Dans [15]:
df = pd.merge_asof(trades, depths, on='transact_time', direction='backward')
Dans [17]:
df['spread'] = round(df['ask_0_price'] - df['bid_0_price'],4)
df['mid_price'] = (df['bid_0_price']+ df['ask_0_price']) / 2
df['I'] = (df['bid_0_quantity'] - df['ask_0_quantity']) / (df['bid_0_quantity'] + df['ask_0_quantity'])
df['weight_mid_price'] = df['mid_price'] + df['spread']*df['I']/2
df['adjust_mid_price'] = df['mid_price'] + df['spread']*(df['I'])*(df['I']**8+1)/4
df['adjust_mid_price_2'] = df['mid_price'] + df['spread']*df['I']*(df['I']**2+1)/4
df['adjust_mid_price_3'] = df['mid_price'] + df['spread']*df['I']**3/2
df['adjust_mid_price_4'] = df['mid_price'] + df['spread']*(df['I']+0.3)*(df['I']**4+0.7)/3.8
Dans [18]:
print('Mean value Error in mid_price:', ((df['price']-df['mid_price'])**2).sum())
print('Error of pending order volume weighted mid_price:', ((df['price']-df['weight_mid_price'])**2).sum())
print('The error of the adjusted mid_price:', ((df['price']-df['adjust_mid_price'])**2).sum())
print('The error of the adjusted mid_price_2:', ((df['price']-df['adjust_mid_price_2'])**2).sum())
print('The error of the adjusted mid_price_3:', ((df['price']-df['adjust_mid_price_3'])**2).sum())
print('The error of the adjusted mid_price_4:', ((df['price']-df['adjust_mid_price_4'])**2).sum())
À l'extérieur [1]:
Valeur moyenne Erreur dans le prix moyen: 0,0048751924999999845 Erreur du volume des ordres en attente pondéré au prix moyen: 0,0048373440193987035 L'erreur du prix moyen ajusté: 0,004803654771638586 L'erreur du prix moyen ajusté est de 0,004808216498329721 L'erreur du prix moyen ajusté est de 0,004794984755260528 L'erreur du prix moyen ajusté est de 0,0047909595497071375
Considérons le deuxième degré de profondeur
Nous pouvons suivre l'approche de l'article précédent pour examiner les différentes plages d'un paramètre et mesurer sa contribution au prix moyen en fonction des changements du prix de la transaction.
En appliquant la même approche au deuxième niveau de profondeur, nous constatons que, bien que l'effet soit légèrement inférieur au premier niveau, il est toujours significatif et ne doit pas être ignoré.
En examinant les différentes méthodes de calcul, nous observons une réduction supplémentaire des erreurs de prédiction.
Dans [19]:
bins = np.linspace(-1, 1, 50)
df['change'] = (df['price'].pct_change().shift(-1))/tick_size
df['I_bins'] = pd.cut(df['I'], bins, labels=bins[1:])
df['I_2'] = (df['bid_1_quantity'] - df['ask_1_quantity']) / (df['bid_1_quantity'] + df['ask_1_quantity'])
df['I_2_bins'] = pd.cut(df['I_2'], bins, labels=bins[1:])
df['I_3'] = (df['bid_2_quantity'] - df['ask_2_quantity']) / (df['bid_2_quantity'] + df['ask_2_quantity'])
df['I_3_bins'] = pd.cut(df['I_3'], bins, labels=bins[1:])
df['I_4'] = (df['bid_3_quantity'] - df['ask_3_quantity']) / (df['bid_3_quantity'] + df['ask_3_quantity'])
df['I_4_bins'] = pd.cut(df['I_4'], bins, labels=bins[1:])
fig, axes = plt.subplots(nrows=2, ncols=2, figsize=(8, 5))
axes[0][0].plot(df.groupby('I_bins')['change'].mean())
axes[0][0].set_title('I')
axes[0][0].grid(True)
axes[0][1].plot(df.groupby('I_2_bins')['change'].mean())
axes[0][1].set_title('I 2')
axes[0][1].grid(True)
axes[1][0].plot(df.groupby('I_3_bins')['change'].mean())
axes[1][0].set_title('I 3')
axes[1][0].grid(True)
axes[1][1].plot(df.groupby('I_4_bins')['change'].mean())
axes[1][1].set_title('I 4')
axes[1][1].grid(True)
plt.tight_layout();
Extrait [1]:
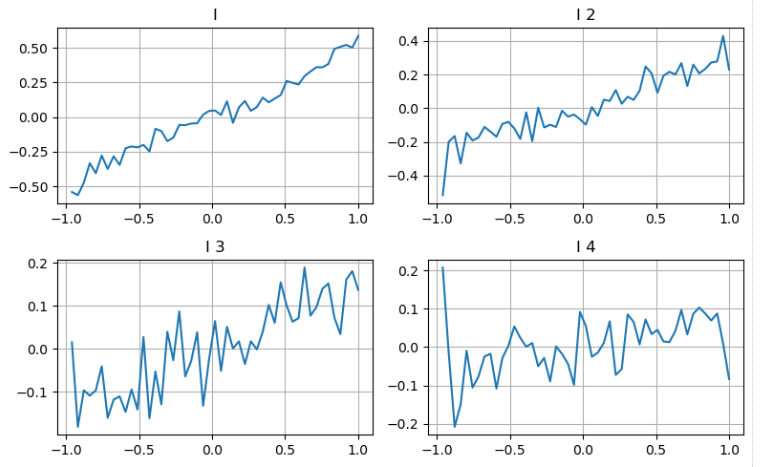
Dans [20]:
df['adjust_mid_price_4'] = df['mid_price'] + df['spread']*(df['I']+0.3)*(df['I']**4+0.7)/3.8
df['adjust_mid_price_5'] = df['mid_price'] + df['spread']*(0.7*df['I']+0.3*df['I_2'])/2
df['adjust_mid_price_6'] = df['mid_price'] + df['spread']*(0.7*df['I']+0.3*df['I_2'])**3/2
df['adjust_mid_price_7'] = df['mid_price'] + df['spread']*(0.7*df['I']+0.3*df['I_2']+0.3)*((0.7*df['I']+0.3*df['I_2'])**4+0.7)/3.8
df['adjust_mid_price_8'] = df['mid_price'] + df['spread']*(0.7*df['I']+0.2*df['I_2']+0.1*df['I_3']+0.3)*((0.7*df['I']+0.3*df['I_2']+0.1*df['I_3'])**4+0.7)/3.8
Dans [21]:
print('The error of the adjusted mid_price_4:', ((df['price']-df['adjust_mid_price_4'])**2).sum())
print('The error of the adjusted mid_price_5:', ((df['price']-df['adjust_mid_price_5'])**2).sum())
print('The error of the adjusted mid_price_6:', ((df['price']-df['adjust_mid_price_6'])**2).sum())
print('The error of the adjusted mid_price_7:', ((df['price']-df['adjust_mid_price_7'])**2).sum())
print('The error of the adjusted mid_price_8:', ((df['price']-df['adjust_mid_price_8'])**2).sum())
Extrait[21]:
L'erreur du prix moyen ajusté est de 0,0047909595497071375 L'erreur du prix moyen ajusté est de 0,0047884350488318714 L'erreur du prix moyen ajusté: 0,0047778319053133735 L'erreur du prix moyen ajusté est de 0,004773578540592192 L'erreur du prix moyen ajusté: 0,004771415189297518
Considérant les données de transaction
Les données de transaction reflètent directement l'étendue des positions longues et courtes. Après tout, les transactions impliquent de l'argent réel, tandis que la passation d'ordres a des coûts beaucoup plus faibles et peut même impliquer une tromperie intentionnelle. Par conséquent, lors de la prédiction du prix moyen, les stratégies doivent se concentrer sur les données de transaction.
En termes de forme, nous pouvons définir le déséquilibre de la quantité moyenne d'arrivée d'ordres comme VI, avec Vb et Vs représentant respectivement la quantité moyenne d'ordres d'achat et de vente dans un intervalle de temps unitaire.
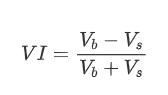
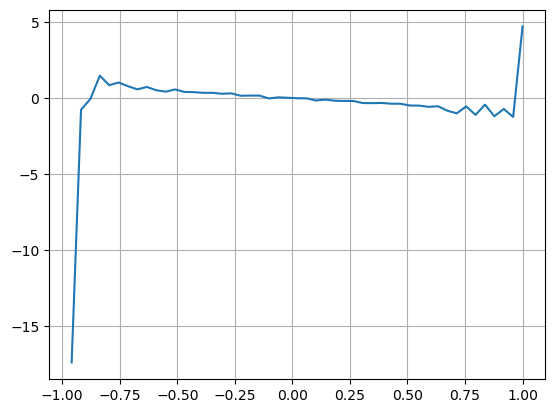
Les résultats montrent que la quantité d'arrivée dans un court laps de temps a l'impact le plus significatif sur la prédiction du changement de prix. Lorsque VI est comprise entre 0,1 et 0,9, elle est corrélée négativement au prix, tandis qu'en dehors de cette plage, elle est corrélée positivement au prix. Cela suggère que lorsque le marché n'est pas extrême et oscille principalement, le prix a tendance à revenir à la moyenne. Cependant, dans des conditions de marché extrêmes, comme lorsqu'il y a un grand nombre d'ordres d'achat écrasant les ordres de vente, une tendance émerge. Même sans tenir compte de ces scénarios à faible probabilité, en supposant une relation linéaire négative entre la tendance et VI, la prédiction de l'erreur du prix moyen est considérablement réduite.
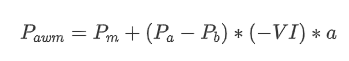
Dans [22]:
alpha=0.1
Dans [23]:
df['avg_buy_interval'] = None
df['avg_sell_interval'] = None
df.loc[df['is_buyer_maker'] == True, 'avg_buy_interval'] = df[df['is_buyer_maker'] == True]['transact_time'].diff().ewm(alpha=alpha).mean()
df.loc[df['is_buyer_maker'] == False, 'avg_sell_interval'] = df[df['is_buyer_maker'] == False]['transact_time'].diff().ewm(alpha=alpha).mean()
Dans [24]:
df['avg_buy_quantity'] = None
df['avg_sell_quantity'] = None
df.loc[df['is_buyer_maker'] == True, 'avg_buy_quantity'] = df[df['is_buyer_maker'] == True]['quantity'].ewm(alpha=alpha).mean()
df.loc[df['is_buyer_maker'] == False, 'avg_sell_quantity'] = df[df['is_buyer_maker'] == False]['quantity'].ewm(alpha=alpha).mean()
Dans [25]:
df['avg_buy_quantity'] = df['avg_buy_quantity'].fillna(method='ffill')
df['avg_sell_quantity'] = df['avg_sell_quantity'].fillna(method='ffill')
df['avg_buy_interval'] = df['avg_buy_interval'].fillna(method='ffill')
df['avg_sell_interval'] = df['avg_sell_interval'].fillna(method='ffill')
df['avg_buy_rate'] = 1000 / df['avg_buy_interval']
df['avg_sell_rate'] =1000 / df['avg_sell_interval']
df['avg_buy_volume'] = df['avg_buy_rate']*df['avg_buy_quantity']
df['avg_sell_volume'] = df['avg_sell_rate']*df['avg_sell_quantity']
Dans [26]:
df['I'] = (df['bid_0_quantity']- df['ask_0_quantity']) / (df['bid_0_quantity'] + df['ask_0_quantity'])
df['OI'] = (df['avg_buy_rate']-df['avg_sell_rate']) / (df['avg_buy_rate'] + df['avg_sell_rate'])
df['QI'] = (df['avg_buy_quantity']-df['avg_sell_quantity']) / (df['avg_buy_quantity'] + df['avg_sell_quantity'])
df['VI'] = (df['avg_buy_volume']-df['avg_sell_volume']) / (df['avg_buy_volume'] + df['avg_sell_volume'])
Dans [27]:
bins = np.linspace(-1, 1, 50)
df['VI_bins'] = pd.cut(df['VI'], bins, labels=bins[1:])
plt.plot(df.groupby('VI_bins')['change'].mean());
plt.grid(True)
Extrait[27]:
Dans [28]:
df['adjust_mid_price'] = df['mid_price'] + df['spread']*df['I']/2
df['adjust_mid_price_9'] = df['mid_price'] + df['spread']*(-df['OI'])*2
df['adjust_mid_price_10'] = df['mid_price'] + df['spread']*(-df['VI'])*1.4
Dans [29]:
print('The error of the adjusted mid_price:', ((df['price']-df['adjust_mid_price'])**2).sum())
print('The error of the adjusted mid_price_9:', ((df['price']-df['adjust_mid_price_9'])**2).sum())
print('The error of the adjusted mid_price_10:', ((df['price']-df['adjust_mid_price_10'])**2).sum())
Extrait[29]:
L'erreur du prix moyen ajusté: 0,0048373440193987035 L'erreur du prix moyen ajusté: 0,004629586542840461 L'erreur du prix moyen ajusté_10: 0,004401790287167206
Le prix moyen global
Considérant que les données de déséquilibre du carnet de commandes et de transaction sont utiles pour prédire le prix moyen, nous pouvons combiner ces deux paramètres. L'attribution des pondérations dans ce cas est arbitraire et ne prend pas en compte les conditions limites. Dans les cas extrêmes, le prix moyen prévu peut ne pas tomber entre les prix d'offre et de demande. Cependant, tant que l'erreur de prédiction peut être réduite, ces détails ne sont pas très préoccupants.
En fin de compte, l'erreur de prédiction est réduite de 0,00487 à 0,0043. À ce stade, nous n'approfondirons pas le sujet. Il reste encore de nombreux aspects à explorer en ce qui concerne la prédiction du prix moyen, car il s'agit essentiellement de prédire le prix lui-même. Tout le monde est encouragé à essayer ses propres approches et techniques.
Dans [30]:
#Note that the VI needs to be delayed by one to use
df['CI'] = -1.5*df['VI'].shift()+0.7*(0.7*df['I']+0.2*df['I_2']+0.1*df['I_3'])**3
Dans [31]:
df['adjust_mid_price_11'] = df['mid_price'] + df['spread']*(df['CI'])
print('The error of the adjusted mid_price_11:', ((df['price']-df['adjust_mid_price_11'])**2).sum())
À l'extérieur [1]:
L'erreur du prix moyen ajusté_11: 0,0043001941412563575
Résumé
L'article combine des données de profondeur et des données de transaction pour améliorer davantage la méthode de calcul du prix moyen. Il fournit une méthode pour mesurer l'exactitude et améliore l'exactitude de la prédiction du changement de prix. Dans l'ensemble, les paramètres ne sont pas rigoureux et sont uniquement à titre de référence.
- Delta contre les options Bitcoin avec une courbe souriante
- Réflexions sur les stratégies de négociation à haute fréquence (4)
- Réflexion sur la stratégie de trading à haute fréquence (5)
- Réflexion sur les stratégies de trading à haute fréquence (4)
- Réflexions sur les stratégies de négociation à haute fréquence (3)
- Réflexion sur les stratégies de trading à haute fréquence (3)
- Réflexions sur les stratégies de négociation à haute fréquence (2)
- Réflexion sur la stratégie de trading à haute fréquence (2)
- Réflexions sur les stratégies de négociation à haute fréquence (1)
- Réflexion sur les stratégies de trading à haute fréquence (1)
- Document de description de la configuration des titres Futu