Modélisation et analyse de la volatilité du Bitcoin basée sur le modèle ARMA-EGARCH
Auteur:Je ne sais pas., Créé: 2022-11-15 15:32:43, Mis à jour: 2023-09-14 20:30:52ED, et le processus a été omis.
Le degré de correspondance de la distribution normale normale n'est pas aussi bon que la distribution t, ce qui montre également que la distribution de rendement a une queue plus épaisse que la distribution normale.
Dans [23]:
am_GARCH = arch_model(training_garch, mean='AR', vol='GARCH',
p=1, q=1, lags=3, dist='ged')
res_GARCH = am_GARCH.fit(disp=False, options={'ftol': 1e-01})
res_GARCH.summary()
Extrait[23]: L'expérience de l'expérience de l'expérience de l'expérience de l'expérience de l'expérience de l'expérience de l'expérience
Résultats du modèle AR-GARCH
Modèle moyen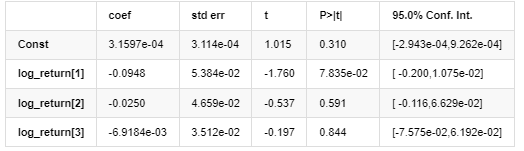
Modèle de volatilité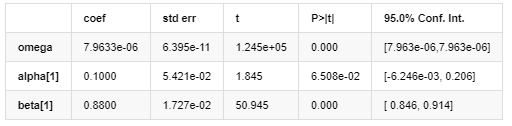
Distribution
Estimateur de covariance: fiable
Description de l'équation de volatilité GARCH selon la base de données ARCH: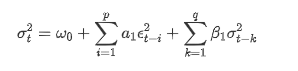
L'équation de régression conditionnelle pour la volatilité peut être obtenue comme suit: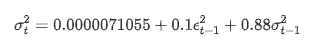
Combiné avec la volatilité prévue correspondante, comparez-le avec la volatilité réelle de l'échantillon pour voir l'effet.
Dans [26]:
def recursive_forecast(pd_dataframe):
window = predict_lag
model = 'GARCH'
index = kline_test[1:].index
end_loc = np.where(index >= kline_test.index[window])[0].min()
forecasts = {}
for i in range(len(kline_test[1:]) - window + 2):
mod = arch_model(pd_dataframe['log_return'][1:], mean='AR', vol=model, dist='ged',p=1, q=1)
res = mod.fit(last_obs=i+end_loc, disp='off', options={'ftol': 1e03})
temp = res.forecast().variance
fcast = temp.iloc[i + end_loc - 1]
forecasts[fcast.name] = fcast
forecasts = pd.DataFrame(forecasts).T
pd_dataframe['recursive_{}'.format(model)] = forecasts['h.1']
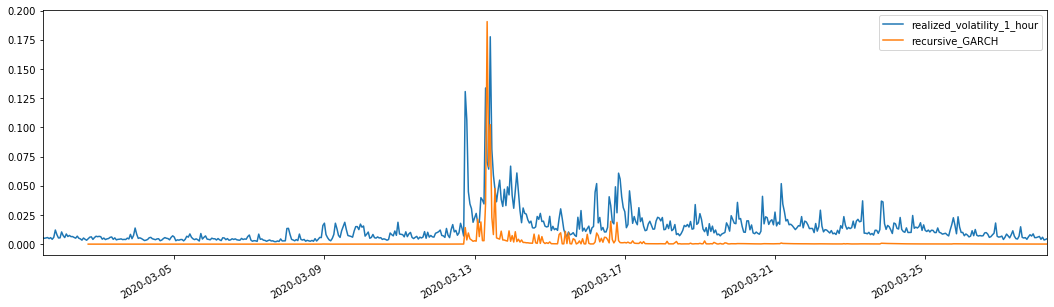
evaluate(pd_dataframe, 'realized_volatility_1_hour', 'recursive_{}'.format(model))
recursive_forecast(kline_test)
Extrait[26]: Faute absolue moyenne (MAE): 0,0128 Erreur moyenne en pourcentage absolu (MAPE): 95,6 Erreur de la racine carrée moyenne (RMSE): 0,018
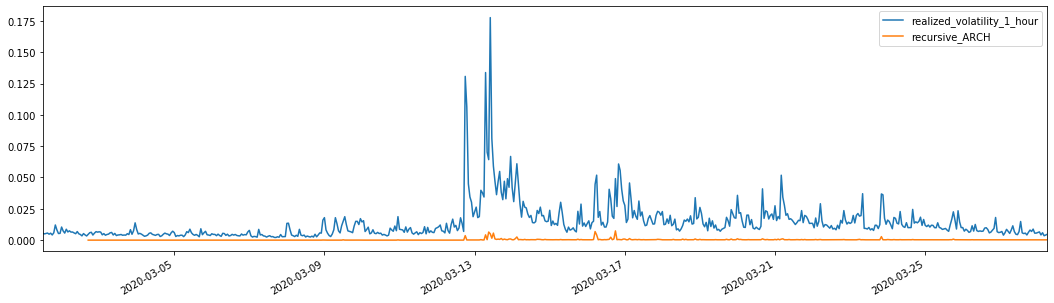
À titre de comparaison, faites une ARCH comme suit:
Dans [27]:
def recursive_forecast(pd_dataframe):
window = predict_lag
model = 'ARCH'
index = kline_test[1:].index
end_loc = np.where(index >= kline_test.index[window])[0].min()
forecasts = {}
for i in range(len(kline_test[1:]) - window + 2):
mod = arch_model(pd_dataframe['log_return'][1:], mean='AR', vol=model, dist='ged', p=1)
res = mod.fit(last_obs=i+end_loc, disp='off', options={'ftol': 1e03})
temp = res.forecast().variance
fcast = temp.iloc[i + end_loc - 1]
forecasts[fcast.name] = fcast
forecasts = pd.DataFrame(forecasts).T
pd_dataframe['recursive_{}'.format(model)] = forecasts['h.1']
evaluate(pd_dataframe, 'realized_volatility_1_hour', 'recursive_{}'.format(model))
recursive_forecast(kline_test)
Extrait[27]: Faux absolu moyen (MAE): 0,0136 Percentage moyen d'erreur absolue (MAPE): 98,1 Erreur de la racine carrée moyenne (RMSE): 0,02
7. modélisation EGARCH
L'étape suivante consiste à effectuer la modélisation EGARCH
Dans [24]:
am_EGARCH = arch_model(training_egarch, mean='AR', vol='EGARCH',
p=1, lags=3, o=1,q=1, dist='ged')
res_EGARCH = am_EGARCH.fit(disp=False, options={'ftol': 1e-01})
res_EGARCH.summary()
Extrait[24]: L'expérience de l'équipe de l'équipe de l'équipe de l'équipe de l'équipe de l'équipe de l'équipe de l'équipe de l'équipe de l'équipe de l'équipe de l'équipe de l'équipe de l'équipe de l'équipe de l'équipe de l'équipe de l'équipe de l'équipe de l'équipe de l'équipe de l'équipe de l'équipe de l'équipe de l'équipe de l'équipe de l'équipe de l'équipe de l'équipe de l'équipe de l'équipe de l'équipe de l'équipe de l'équipe de l'équipe de l'équipe de l'équipe de l'équipe de l'équipe de l'équipe de l'équipe de l'équipe de l'équipe de l'équipe de l'équipe de l'équipe de l'équipe de l'équipe de l'équipe de l'é
Résultats du modèle AR-EGARCH
Modèle moyen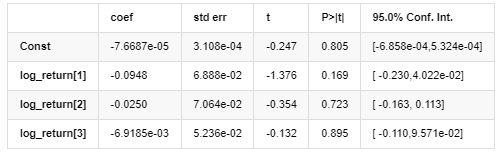
Modèle de volatilité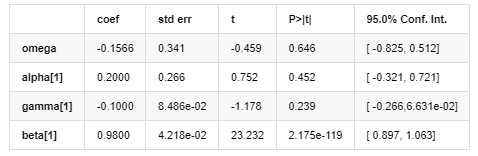
Distribution
Estimateur de covariance: fiable
L'équation de volatilité EGARCH fournie par la bibliothèque ARCH est décrite comme suit: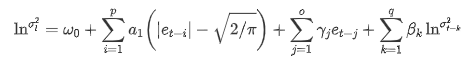
remplaçant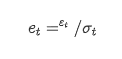
L'équation de régression conditionnelle de la volatilité peut être obtenue comme suit: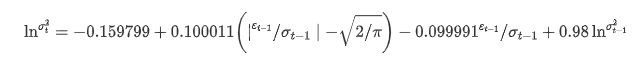
Parmi eux, le coefficient estimatif du terme symétrique γ est inférieur à l'intervalle de confiance, ce qui indique qu'il existe une asymétrie significative dans la volatilité des taux de rendement du Bitcoin.
Combinés à la volatilité prévue correspondante, les résultats sont comparés à la volatilité réelle de l'échantillon comme suit:
Dans [28]:
def recursive_forecast(pd_dataframe):
window = 280
model = 'EGARCH'
index = kline_test[1:].index
end_loc = np.where(index >= kline_test.index[window])[0].min()
forecasts = {}
for i in range(len(kline_test[1:]) - window + 2):
mod = arch_model(pd_dataframe['log_return'][1:], mean='AR', vol=model,
lags=3, p=2, o=0, q=1, dist='ged')
res = mod.fit(last_obs=i+end_loc, disp='off', options={'ftol': 1e03})
temp = res.forecast().variance
fcast = temp.iloc[i + end_loc - 1]
forecasts[fcast.name] = fcast
forecasts = pd.DataFrame(forecasts).T
pd_dataframe['recursive_{}'.format(model)] = forecasts['h.1']
evaluate(pd_dataframe, 'realized_volatility_1_hour', 'recursive_{}'.format(model))
pd_dataframe['recursive_{}'.format(model)]
recursive_forecast(kline_test)
Extrait[28]: L'erreur absolue moyenne (EAM): 0,0201 Erreur moyenne en pourcentage absolu (MAPE): 122 Erreur de la racine carrée moyenne (RMSE): 0,0279
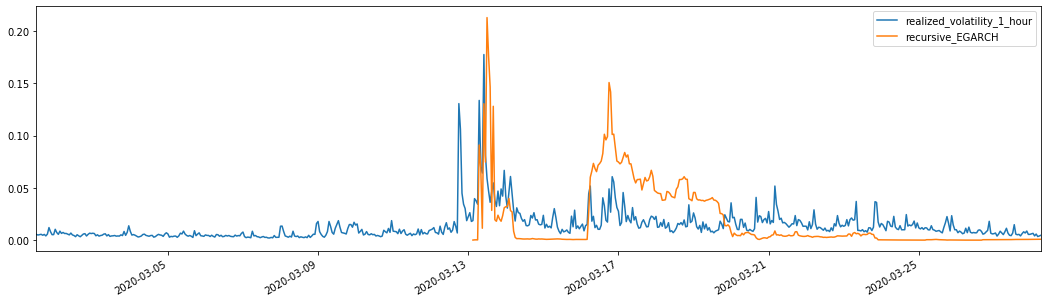
Il apparaît que l'EGARCH est plus sensible à la volatilité et correspond mieux à la volatilité qu'ARCH et GARCH.
8. Évaluation des prévisions de volatilité
Les données horaires sont sélectionnées sur la base de l'échantillon, et l'étape suivante consiste à prédire une heure à l'avance.
Dans [29]:
compare_ARCH_X = pd.DataFrame()
compare_ARCH_X['original']=kline_test['realized_volatility_1_hour']
compare_ARCH_X['arch']=kline_test['recursive_ARCH']
compare_ARCH_X['arch_diff']=compare_ARCH_X['original']-np.abs(compare_ARCH_X['arch'])
compare_ARCH_X['garch']=kline_test['recursive_GARCH']
compare_ARCH_X['garch_diff']=compare_ARCH_X['original']-np.abs(compare_ARCH_X['garch'])
compare_ARCH_X['egarch']=kline_test['recursive_EGARCH']
compare_ARCH_X['egarch_diff']=compare_ARCH_X['original']-np.abs(compare_ARCH_X['egarch'])
compare_ARCH_X = compare_ARCH_X[280:]
compare_ARCH_X.head(10)
Extrait[29]: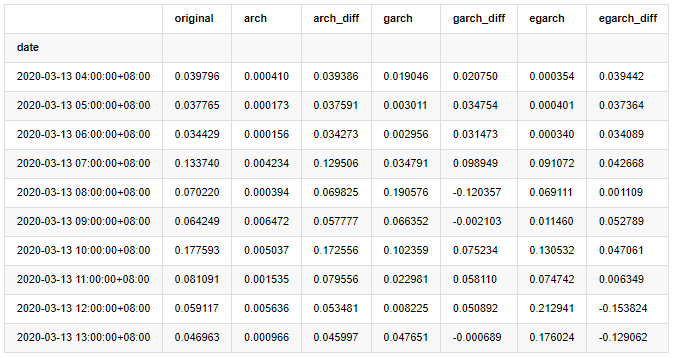
Dans [30]:
compare_ARCH_X_diff = pd.DataFrame(index=['ARCH','GARCH','EGARCH'], columns=['head 1 step', 'head 10 steps', 'head 100 steps'])
compare_ARCH_X_diff['head 1 step']['ARCH'] = compare_ARCH_X['arch_diff']['2020-03-13 04:00:00+08:00']
compare_ARCH_X_diff['head 10 steps']['ARCH'] = np.mean(compare_ARCH_X['arch_diff'][:10])
compare_ARCH_X_diff['head 100 steps']['ARCH'] = np.mean(compare_ARCH_X['arch_diff'][:100])
compare_ARCH_X_diff['head 1 step']['GARCH'] = compare_ARCH_X['garch_diff']['2020-03-13 04:00:00+08:00']
compare_ARCH_X_diff['head 10 steps']['GARCH'] = np.mean(compare_ARCH_X['garch_diff'][:10])
compare_ARCH_X_diff['head 100 steps']['GARCH'] = np.mean(compare_ARCH_X['garch_diff'][:100])
compare_ARCH_X_diff['head 1 step']['EGARCH'] = compare_ARCH_X['egarch_diff']['2020-03-13 04:00:00+08:00']
compare_ARCH_X_diff['head 10 steps']['EGARCH'] = np.mean(compare_ARCH_X['egarch_diff'][:10])
compare_ARCH_X_diff['head 100 steps']['EGARCH'] = np.abs(np.mean(compare_ARCH_X['egarch_diff'][:100]))
compare_ARCH_X_diff
Extrait[30]: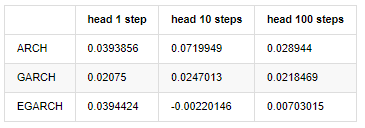
Plusieurs tests ont été effectués, dans les résultats de prédiction de la première heure, la probabilité de la plus petite erreur d'EGARCH est relativement grande, mais la différence globale n'est pas particulièrement évidente; Il y a quelques différences évidentes dans les effets de prédiction à court terme; EGARCH a la capacité de prédiction la plus remarquable dans la prédiction à long terme
Dans [31]:
compare_ARCH_X = pd.DataFrame()
compare_ARCH_X['Model'] = ['ARCH','GARCH','EGARCH']
compare_ARCH_X['RMSE'] = [get_rmse(kline_test['realized_volatility_1_hour'][280:320],kline_test['recursive_ARCH'][280:320]),
get_rmse(kline_test['realized_volatility_1_hour'][280:320],kline_test['recursive_GARCH'][280:320]),
get_rmse(kline_test['realized_volatility_1_hour'][280:320],kline_test['recursive_EGARCH'][280:320])]
compare_ARCH_X['MAPE'] = [get_mape(kline_test['realized_volatility_1_hour'][280:320],kline_test['recursive_ARCH'][280:320]),
get_mape(kline_test['realized_volatility_1_hour'][280:320],kline_test['recursive_GARCH'][280:320]),
get_mape(kline_test['realized_volatility_1_hour'][280:320],kline_test['recursive_EGARCH'][280:320])]
compare_ARCH_X['MASE'] = [get_mape(kline_test['realized_volatility_1_hour'][280:320],kline_test['recursive_ARCH'][280:320]),
get_mape(kline_test['realized_volatility_1_hour'][280:320],kline_test['recursive_GARCH'][280:320]),
get_mape(kline_test['realized_volatility_1_hour'][280:320],kline_test['recursive_EGARCH'][280:320])]
compare_ARCH_X
À l'extérieur [1]: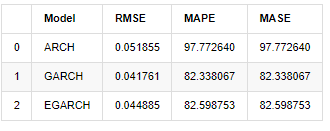
En termes d'indicateurs, GARCH et EGARCH présentent une certaine amélioration par rapport à ARCH, mais la différence n'est pas particulièrement évidente.
9. Conclusion
D'après l'analyse simple ci-dessus, il peut être constaté que le taux de rendement logarithmique du Bitcoin ne se conforme pas à la distribution normale, qui se caractérise par des queues épaisses, et la volatilité a un effet d'agrégation et d'effet de levier, tout en montrant une hétérogénéité conditionnelle évidente.
Dans la prédiction et l'évaluation du taux de rendement logarithmique, la capacité de prédiction statique intra-échantillon du modèle ARMA est nettement meilleure que celle dynamique, ce qui montre que la méthode de laminage est évidemment meilleure que la méthode itérative, et peut éviter les problèmes de surmatch et d'amplification d'erreur.
En outre, lorsqu'il s'agit du phénomène de la queue épaisse de Bitcoin, c'est-à-dire la distribution épaisse de rendements, il est constaté que la distribution GED (erreur généralisée) est meilleure que la distribution t et la distribution normale de manière significative, ce qui peut améliorer la précision de mesure du risque de queue.
Le processus de modélisation entier est plein de diverses hypothèses audacieuses, et il n'y a pas d'identification de cohérence en fonction de la validité, nous ne pouvons donc vérifier que certains phénomènes avec soin.
Comparé aux marchés traditionnels, la disponibilité des données à haute fréquence de Bitcoin est plus facile. La mesure
Cependant, ce qui précède est limité à la théorie. Les données à fréquence plus élevée peuvent en effet fournir une analyse plus précise du comportement des traders. Elles peuvent non seulement fournir des tests plus fiables pour les modèles théoriques financiers, mais également fournir des informations de prise de décision plus abondantes pour les traders, même soutenir la prédiction du flux d'informations et du flux de capital, et aider à concevoir des stratégies de trading quantitatives plus précises. Cependant, le marché du Bitcoin est si volatil que les données historiques trop longues ne peuvent pas correspondre aux informations de prise de décision efficaces, de sorte que les données à haute fréquence apporteront certainement de plus grands avantages sur le marché aux investisseurs de monnaie numérique.
Enfin, si vous pensez que le contenu ci-dessus est utile, vous pouvez également offrir un peu de BTC pour m'acheter une tasse de Cola.
- Quantifier l'analyse fondamentale sur le marché des crypto-monnaies: laissez les données parler d'elles-mêmes!
- Les fondements de la recherche quantifiée dans le cercle monétaire - ne croyez plus à tous les professeurs de mathématiques, les données sont objectives!
- Un outil indispensable dans le domaine de la quantification des transactions - l'inventeur du module de recherche de données quantifiées
- Maîtriser tout - Introduction à FMZ Nouvelle version du terminal de négociation (avec le code source TRB Arbitrage)
- Tout savoir sur la nouvelle version du terminal de trading FMZ (source code TRB)
- FMZ Quant: Une analyse des exemples de conception des exigences communes sur le marché des crypto-monnaies (II)
- Comment exploiter les robots de vente sans cerveau avec une stratégie de haute fréquence en 80 lignes de code
- Quantification FMZ: analyse de l'exemple de conception des besoins courants sur le marché des crypto-monnaies (II)
- Comment exploiter les robots sans cerveau pour les vendre avec une stratégie de haute fréquence de 80 lignes de code
- FMZ Quant: Une analyse des exemples de conception des exigences communes sur le marché des crypto-monnaies (I)
- Quantification FMZ: analyse de l'exemple de conception des besoins courants sur le marché des crypto-monnaies (1)