Réseaux neuronaux et négociation quantitative de devises numériques série (2) - Apprentissage intensif et formation Stratégie de négociation Bitcoin
Auteur:Je ne sais pas., Créé à: 2023-01-12 16:49:09, Mis à jour à: 2023-09-20 10:07:39
Réseaux neuronaux et négociation quantitative de devises numériques série (2) - Apprentissage intensif et formation Stratégie de négociation Bitcoin
1. Introduction au projet
Dans le dernier article, nous avons présenté l'utilisation du réseau LSTM pour prédire le prix du Bitcoin:https://www.fmz.com/bbs-topic/9879, comme mentionné dans l'article, il ne s'agit que d'un petit projet de formation pour se familiariser avec RNN et pytorch. Cet article présentera l'utilisation de l'apprentissage intensif pour former directement les stratégies de trading. Le modèle d'apprentissage intensif est OpenAI PPO open source, et l'environnement fait référence au style de gym. Afin de faciliter la compréhension et les tests, le modèle PPO de LSTM et l'environnement de gym pour le backtesting sont écrits directement sans utiliser de paquets prêts à l'emploi. PPO, ou Proximal Policy Optimization, est une amélioration de l'optimisation de Policy Gradient. gym a également été publié par OpenAI. Il peut interagir avec le réseau de stratégie et faire des commentaires sur l'état et les récompenses de l'environnement actuel. Il ressemble à la pratique de l'apprentissage intensif. Il utilise le modèle PPO de LSTM pour faire des instructions, telles que l'achat, la vente ou aucune opération directement selon les informations du marché de Bitcoin. Les commentaires sont donnés par l'environnement de backtest. Grâce à la formation, le modèle est continuellement optimisé pour atteindre l'objectif de profit stratégique. Lire cet article nécessite une certaine base d'apprentissage intensif en profondeur en Python, pytorch et DRL. Mais peu importe si vous ne pouvez pas. Il est facile d'apprendre et de commencer avec le code donné dans cet article. Ce tutoriel est produit par la plate-forme de trading FMZ Quant (www.fmz.comBienvenue dans le groupe QQ: 863946592 pour la communication.
2. Données et références d'apprentissage
Les données sur le prix du Bitcoin proviennent de la plateforme de trading FMZ Quant:https://www.quantinfo.com/Tools/View/4.htmlJe suis désolée. Un article qui utilise DRL+gym pour former les stratégies de trading:https://towardsdatascience.com/visualizing-stock-trading-agents-using-matplotlib-and-gym-584c992bc6d4Je suis désolée. Quelques exemples pour commencer avec pytorch:https://github.com/yunjey/pytorch-tutorialJe suis désolée. Le présent article mettra directement en œuvre par le modèle LSTM-PPO:https://github.com/seungeunrho/minimalRL/blob/master/ppo-lstm.pyJe suis désolée. Articles sur le PPO:https://zhuanlan.zhihu.com/p/38185553Je suis désolée. Plus d'articles sur le DRL:https://www.zhihu.com/people/flood-sung/postsJe suis désolée. À propos du gymnase, cet article ne nécessite pas d'installation, mais il est très courant dans l'apprentissage intensif:https://gym.openai.com/.
3. LSTM-PPO
Pour une explication approfondie du PPO, vous pouvez apprendre des documents de référence précédents. Voici juste une introduction simple aux concepts. Le dernier numéro du réseau LSTM n'a prévu que le prix. Comment acheter et vendre en fonction du prix prévu devra être réalisé séparément. Il est naturel de penser que la sortie directe de l'action de trading sera plus directe. C'est le cas de Policy Gradient, qui peut donner la probabilité de diverses actions en fonction des informations de l'environnement d'entrée s. La perte de LSTM est la différence entre le prix prévu et le prix réel, tandis que la perte de PG est - log § * Q, où p est la probabilité d'une action de sortie, et Q est la valeur de l'action (comme le score de récompense intuitive).
Le code source de LSTM-PPO est indiqué ci-dessous, qui peut être compris en combinaison avec les données précédentes:
import time
import requests
import json
import numpy as np
import pandas as pd
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torch.distributions import Categorical
from itertools import count
# Hyperparameters of the model
learning_rate = 0.0005
gamma = 0.98
lmbda = 0.95
eps_clip = 0.1
K_epoch = 3
device = torch.device('cpu') # It can also be changed to GPU version.
class PPO(nn.Module):
def __init__(self, state_size, action_size):
super(PPO, self).__init__()
self.data = []
self.fc1 = nn.Linear(state_size,10)
self.lstm = nn.LSTM(10,10)
self.fc_pi = nn.Linear(10,action_size)
self.fc_v = nn.Linear(10,1)
self.optimizer = optim.Adam(self.parameters(), lr=learning_rate)
def pi(self, x, hidden):
# Output the probability of each action. Since LSTM network also contains the information of hidden layer, please refer to the previous article.
x = F.relu(self.fc1(x))
x = x.view(-1, 1, 10)
x, lstm_hidden = self.lstm(x, hidden)
x = self.fc_pi(x)
prob = F.softmax(x, dim=2)
return prob, lstm_hidden
def v(self, x, hidden):
# Value function is used to evaluate the current situation, so there is only one output.
x = F.relu(self.fc1(x))
x = x.view(-1, 1, 10)
x, lstm_hidden = self.lstm(x, hidden)
v = self.fc_v(x)
return v
def put_data(self, transition):
self.data.append(transition)
def make_batch(self):
# Prepare the training data.
s_lst, a_lst, r_lst, s_prime_lst, prob_a_lst, hidden_lst, done_lst = [], [], [], [], [], [], []
for transition in self.data:
s, a, r, s_prime, prob_a, hidden, done = transition
s_lst.append(s)
a_lst.append([a])
r_lst.append([r])
s_prime_lst.append(s_prime)
prob_a_lst.append([prob_a])
hidden_lst.append(hidden)
done_mask = 0 if done else 1
done_lst.append([done_mask])
s,a,r,s_prime,done_mask,prob_a = torch.tensor(s_lst, dtype=torch.float), torch.tensor(a_lst), \
torch.tensor(r_lst), torch.tensor(s_prime_lst, dtype=torch.float), \
torch.tensor(done_lst, dtype=torch.float), torch.tensor(prob_a_lst)
self.data = []
return s,a,r,s_prime, done_mask, prob_a, hidden_lst[0]
def train_net(self):
s,a,r,s_prime,done_mask, prob_a, (h1,h2) = self.make_batch()
first_hidden = (h1.detach(), h2.detach())
for i in range(K_epoch):
v_prime = self.v(s_prime, first_hidden).squeeze(1)
td_target = r + gamma * v_prime * done_mask
v_s = self.v(s, first_hidden).squeeze(1)
delta = td_target - v_s
delta = delta.detach().numpy()
advantage_lst = []
advantage = 0.0
for item in delta[::-1]:
advantage = gamma * lmbda * advantage + item[0]
advantage_lst.append([advantage])
advantage_lst.reverse()
advantage = torch.tensor(advantage_lst, dtype=torch.float)
pi, _ = self.pi(s, first_hidden)
pi_a = pi.squeeze(1).gather(1,a)
ratio = torch.exp(torch.log(pi_a) - torch.log(prob_a)) # a/b == log(exp(a)-exp(b))
surr1 = ratio * advantage
surr2 = torch.clamp(ratio, 1-eps_clip, 1+eps_clip) * advantage
loss = -torch.min(surr1, surr2) + F.smooth_l1_loss(v_s, td_target.detach()) # Trained both value and decision networks at the same time.
self.optimizer.zero_grad()
loss.mean().backward(retain_graph=True)
self.optimizer.step()
4. Environnement de backtesting Bitcoin
En suivant le format de gym, il existe une méthode d'initialisation de réinitialisation. Step entre l'action et le résultat retourné est (état suivant, revenu de l'action, si elle doit se terminer, informations supplémentaires). L'ensemble de l'environnement de backtest est également de 60 lignes. Vous pouvez modifier vous-même des versions plus complexes. Le code spécifique est:
class BitcoinTradingEnv:
def __init__(self, df, commission=0.00075, initial_balance=10000, initial_stocks=1, all_data = False, sample_length= 500):
self.initial_stocks = initial_stocks # Initial number of Bitcoins
self.initial_balance = initial_balance # Initial assets
self.current_time = 0 # Time position of the backtest
self.commission = commission # Trading fees
self.done = False # Is the backtest over?
self.df = df
self.norm_df = 100*(self.df/self.df.shift(1)-1).fillna(0) # Standardized approach, simple yield normalization.
self.mode = all_data # Whether it is a sample backtest mode.
self.sample_length = 500 # Sample length
def reset(self):
self.balance = self.initial_balance
self.stocks = self.initial_stocks
self.last_profit = 0
if self.mode:
self.start = 0
self.end = self.df.shape[0]-1
else:
self.start = np.random.randint(0,self.df.shape[0]-self.sample_length)
self.end = self.start + self.sample_length
self.initial_value = self.initial_balance + self.initial_stocks*self.df.iloc[self.start,4]
self.stocks_value = self.initial_stocks*self.df.iloc[self.start,4]
self.stocks_pct = self.stocks_value/self.initial_value
self.value = self.initial_value
self.current_time = self.start
return np.concatenate([self.norm_df[['o','h','l','c','v']].iloc[self.start].values , [self.balance/10000, self.stocks/1]])
def step(self, action):
# action is the action taken by the strategy, here the account will be updated and the reward will be calculated.
done = False
if action == 0: # Hold
pass
elif action == 1: # Buy
buy_value = self.balance*0.5
if buy_value > 1: # Insufficient balance, no account operation.
self.balance -= buy_value
self.stocks += (1-self.commission)*buy_value/self.df.iloc[self.current_time,4]
elif action == 2: # Sell
sell_amount = self.stocks*0.5
if sell_amount > 0.0001:
self.stocks -= sell_amount
self.balance += (1-self.commission)*sell_amount*self.df.iloc[self.current_time,4]
self.current_time += 1
if self.current_time == self.end:
done = True
self.value = self.balance + self.stocks*self.df.iloc[self.current_time,4]
self.stocks_value = self.stocks*self.df.iloc[self.current_time,4]
self.stocks_pct = self.stocks_value/self.value
if self.value < 0.1*self.initial_value:
done = True
profit = self.value - (self.initial_balance+self.initial_stocks*self.df.iloc[self.current_time,4])
reward = profit - self.last_profit # The reward for each turn is the added revenue.
self.last_profit = profit
next_state = np.concatenate([self.norm_df[['o','h','l','c','v']].iloc[self.current_time].values , [self.balance/10000, self.stocks/1]])
return (next_state, reward, done, profit)
5. Plusieurs détails dignes d'intérêt
- Pourquoi le compte initial a-t-il de la monnaie?
La formule pour calculer le rendement de l'environnement de backtest est: rendement courant = valeur du compte courant - valeur actuelle du compte initial. Cela signifie que si le prix du Bitcoin diminue et que la stratégie effectue une opération de vente de pièces, même si la valeur totale du compte diminue, la stratégie devrait en fait être récompensée. Si le backtest prend beaucoup de temps, le compte initial peut avoir peu d'impact, mais il aura un grand impact au début. Le calcul du rendement relatif garantit que chaque opération correcte obtiendra une récompense positive.
- Pourquoi l'échantillonnage du marché a-t-il été effectué au cours de la formation?
La quantité totale de données est supérieure à 10 000 lignes K. Si vous exécutez une boucle en entier à chaque fois, cela prendra beaucoup de temps, et la stratégie fait face à la même situation à chaque fois, il peut être plus facile de se suradapter. En prenant 500 barres à la fois comme backtest. Bien qu'il soit toujours possible de se suradapter, la stratégie fait face à plus de 10 000 départs possibles.
- Et s'il n'y avait pas de monnaie ou d'argent?
Cette situation n'est pas prise en compte dans l'environnement de backtest. Si la monnaie a été épuisée ou la quantité minimale de négociation ne peut pas être atteinte, alors l'opération de vente est équivalente à la non-opération réelle. Si le prix diminue, selon la méthode de calcul du rendement relatif, il est toujours basé sur le rendement stratégique positif. L'impact de cette situation est que lorsque la stratégie juge que le marché diminue et que la monnaie restante du compte ne peut pas être vendue, il est impossible de distinguer l'action de vente de l'action non opérationnelle, mais cela n'a aucun impact sur le jugement de la stratégie elle-même sur le marché.
- Pourquoi dois-je retourner les informations du compte comme statut?
Le modèle PPO dispose d'un réseau de valeur pour évaluer la valeur de l'état actuel. Évidemment, si la stratégie juge que le prix augmentera, l'ensemble du statut n'aura une valeur positive que lorsque le compte courant détient Bitcoin, et vice versa. Par conséquent, les informations du compte sont une base importante pour le jugement du réseau de valeur. Il est à noter que les informations d'action passées ne sont pas renvoyées comme un statut. Je considère qu'il est inutile de juger la valeur.
- Quand sera-t-il de retour à la non-opération?
Lorsque la stratégie juge que les rendements apportés par la transaction ne peuvent pas couvrir les frais de traitement, elle devrait revenir à la non-opération. Bien que la description précédente utilise des stratégies à plusieurs reprises pour juger de la tendance des prix, il est seulement pour la commodité de la compréhension. En fait, ce modèle PPO ne prédit pas le marché, mais ne produit que la probabilité de trois actions.
6. acquisition et formation des données
Comme dans l'article précédent, la méthode et le format d'acquisition des données sont les suivants: période d'une heure K-line de la paire de trading Bitfinex Exchange BTC_USD du 7 mai 2018 au 27 juin 2019:
resp = requests.get('https://www.quantinfo.com/API/m/chart/history?symbol=BTC_USD_BITFINEX&resolution=60&from=1525622626&to=1561607596')
data = resp.json()
df = pd.DataFrame(data,columns = ['t','o','h','l','c','v'])
df.index = df['t']
df = df.dropna()
df = df.astype(np.float32)
En raison de l'utilisation du réseau LSTM, le temps de formation est très long. J'ai changé à une version GPU, qui est environ trois fois plus rapide.
env = BitcoinTradingEnv(df)
model = PPO()
total_profit = 0 # Record total profit
profit_list = [] # Record the profits of each training session
for n_epi in range(10000):
hidden = (torch.zeros([1, 1, 32], dtype=torch.float).to(device), torch.zeros([1, 1, 32], dtype=torch.float).to(device))
s = env.reset()
done = False
buy_action = 0
sell_action = 0
while not done:
h_input = hidden
prob, hidden = model.pi(torch.from_numpy(s).float().to(device), h_input)
prob = prob.view(-1)
m = Categorical(prob)
a = m.sample().item()
if a==1:
buy_action += 1
if a==2:
sell_action += 1
s_prime, r, done, profit = env.step(a)
model.put_data((s, a, r/10.0, s_prime, prob[a].item(), h_input, done))
s = s_prime
model.train_net()
profit_list.append(profit)
total_profit += profit
if n_epi%10==0:
print("# of episode :{:<5}, profit : {:<8.1f}, buy :{:<3}, sell :{:<3}, total profit: {:<20.1f}".format(n_epi, profit, buy_action, sell_action, total_profit))
7. Résultats et analyse de la formation
Après une longue attente:

Tout d'abord, jetons un coup d'œil sur le marché des données de formation. En général, la première moitié est un déclin de longue durée, et la seconde moitié est un rebond fort.
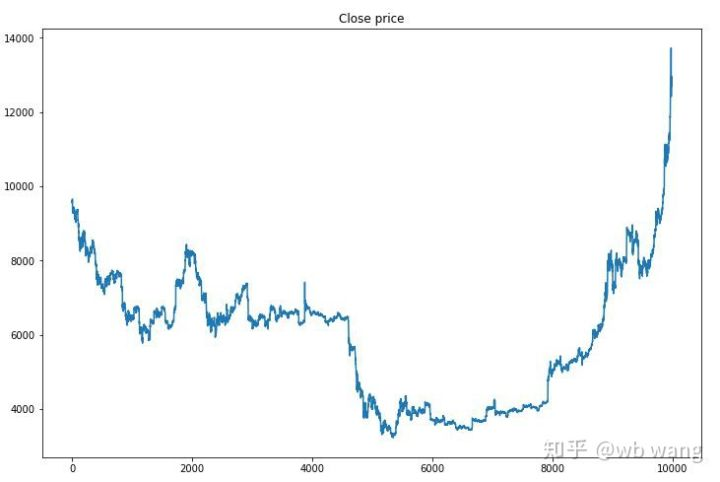
Il y a beaucoup d'opérations d'achat au début de la formation, et il n'y a pratiquement pas de tour rentable. Au milieu de la formation, l'opération d'achat a progressivement diminué, et la probabilité de profit augmente également, mais il y a encore une grande chance de perte.
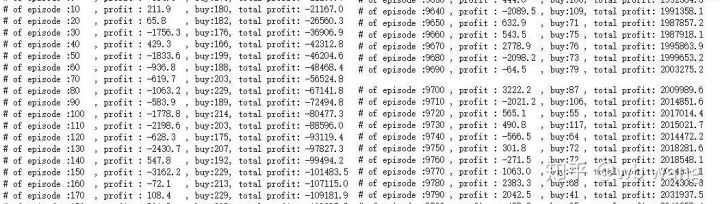
Il suffit d'aplanir les profits de chaque tour et le résultat est le suivant:
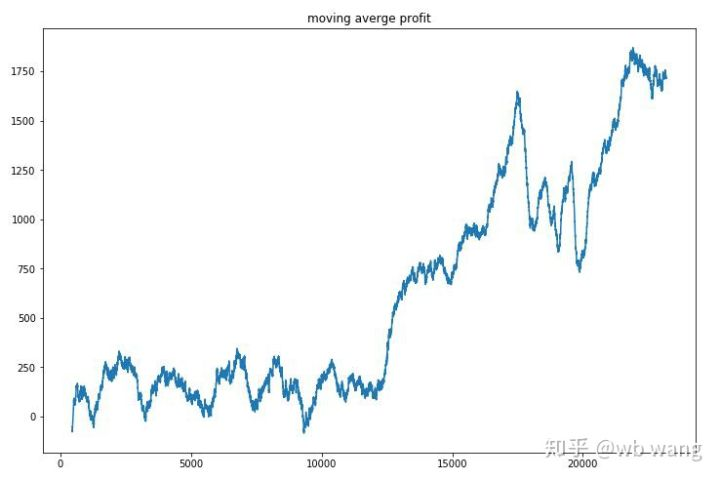
La stratégie s'est rapidement débarrassée de la situation où le retour précoce était négatif, mais la fluctuation était grande. Le retour n'a pas augmenté rapidement avant 10 000 tours. En général, la formation du modèle était très difficile.
Après la formation finale, laissez le modèle exécuter toutes les données à nouveau pour voir comment il fonctionne. Pendant la période, enregistrez la valeur marchande totale du compte, le nombre de Bitcoins détenus, la proportion de la valeur de Bitcoin et les rendements totaux. La première est la valeur marchande totale, et les rendements totaux sont similaires à elle, ils ne seront pas affichés:
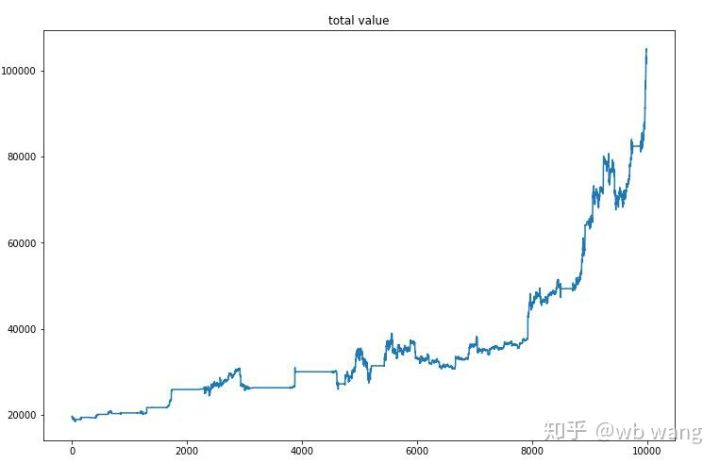
La valeur marchande totale a augmenté lentement au début du marché baissier, et a suivi l'augmentation du marché haussier ultérieur, mais il y avait encore des pertes périodiques.
Enfin, jetez un coup d'œil à la proportion de positions. L'axe gauche du graphique est la proportion de positions, et l'axe droit est le marché. On peut juger préliminairement que le modèle est sur-adapté. La fréquence des positions est faible au début du marché baissier et élevée au bas du marché. On peut également voir que le modèle n'a pas appris à tenir des positions à long terme et vend toujours rapidement.
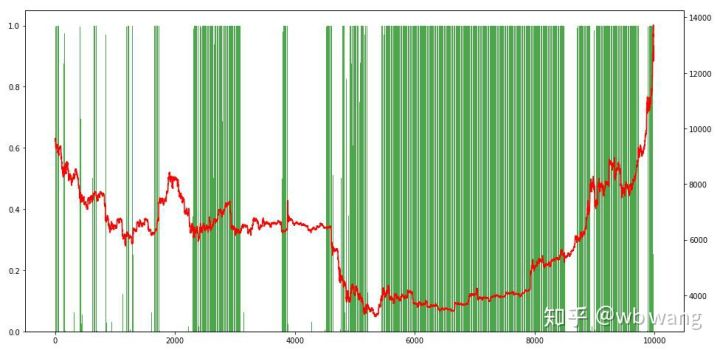
8. Analyse des données d'essai
Le marché d'une heure de Bitcoin du 27 juin 2019 à maintenant a été obtenu à partir des données de test.
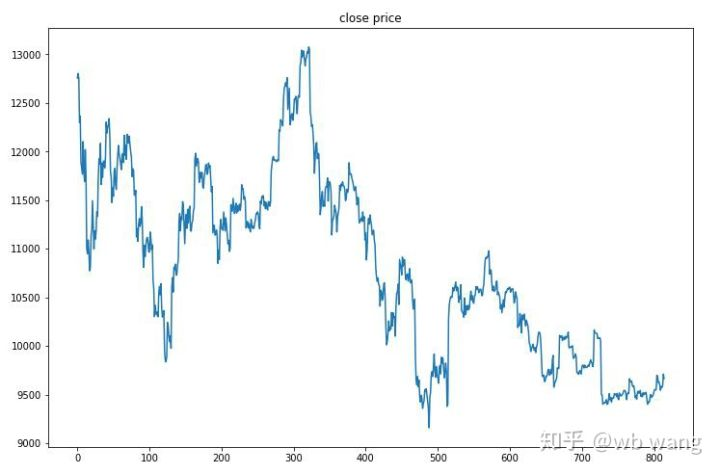
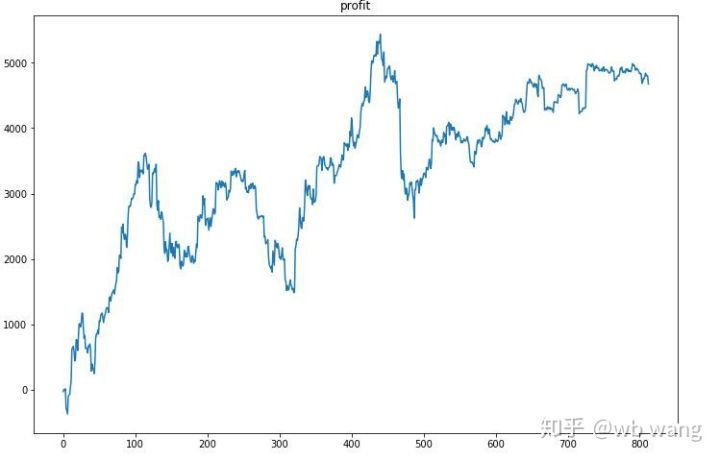
Tout d'abord, le rendement relatif final s'est déroulé comme ça, mais il n'y a pas eu de perte.
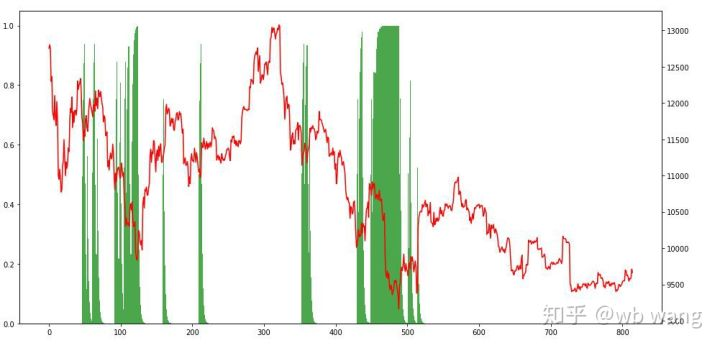
En regardant la situation de la position, nous pouvons supposer que le modèle a tendance à acheter après une forte baisse et à vendre après un rebond.
9. Résumé
Dans cet article, un robot de trading automatique Bitcoin est formé à l'aide de PPO, une méthode d'apprentissage intensif profond, et certaines conclusions sont obtenues. En raison du temps limité, il y a encore quelques aspects à améliorer dans le modèle. Bienvenue à la discussion. La plus grande leçon est que pour la méthode de normalisation des données, n'utilisez pas l'échelle et d'autres méthodes, sinon le modèle se souviendra rapidement de la relation entre le prix et le marché, et tombera en suradaptation. Le taux de changement normalisé est les données relatives, ce qui rend difficile pour le modèle de se souvenir de la relation avec le marché, et est obligé de trouver la relation entre le taux de changement et l'augmentation et la diminution.
Introduction aux articles précédents: Une stratégie à haute fréquence que j' ai révélée qui était autrefois très rentable:https://www.fmz.com/bbs-topic/9886.
- Quantifier l'analyse fondamentale sur le marché des crypto-monnaies: laissez les données parler d'elles-mêmes!
- Les fondements de la recherche quantifiée dans le cercle monétaire - ne croyez plus à tous les professeurs de mathématiques, les données sont objectives!
- Un outil indispensable dans le domaine de la quantification des transactions - l'inventeur du module de recherche de données quantifiées
- Maîtriser tout - Introduction à FMZ Nouvelle version du terminal de négociation (avec le code source TRB Arbitrage)
- Tout savoir sur la nouvelle version du terminal de trading FMZ (source code TRB)
- FMZ Quant: Une analyse des exemples de conception des exigences communes sur le marché des crypto-monnaies (II)
- Comment exploiter les robots de vente sans cerveau avec une stratégie de haute fréquence en 80 lignes de code
- Quantification FMZ: analyse de l'exemple de conception des besoins courants sur le marché des crypto-monnaies (II)
- Comment exploiter les robots sans cerveau pour les vendre avec une stratégie de haute fréquence de 80 lignes de code
- FMZ Quant: Une analyse des exemples de conception des exigences communes sur le marché des crypto-monnaies (I)
- Quantification FMZ: analyse de l'exemple de conception des besoins courants sur le marché des crypto-monnaies (1)