तंत्रिका नेटवर्क और डिजिटल मुद्रा मात्रात्मक व्यापार श्रृंखला (2) - गहन शिक्षा और प्रशिक्षण बिटकॉइन ट्रेडिंग रणनीति
लेखक:लिडिया, बनाया गयाः 2023-01-12 16:49:09, अद्यतन किया गयाः 2023-09-20 10:07:39
तंत्रिका नेटवर्क और डिजिटल मुद्रा मात्रात्मक व्यापार श्रृंखला (2) - गहन शिक्षा और प्रशिक्षण बिटकॉइन ट्रेडिंग रणनीति
1. परिचय
पिछले लेख में, हमने बिटकॉइन की कीमत की भविष्यवाणी करने के लिए LSTM नेटवर्क का उपयोग पेश किया:https://www.fmz.com/bbs-topic/9879, जैसा कि लेख में उल्लेख किया गया है, यह आरएनएन और पाइटॉर्च से परिचित होने के लिए केवल एक छोटी प्रशिक्षण परियोजना है। यह लेख ट्रेडिंग रणनीतियों को सीधे प्रशिक्षित करने के लिए गहन सीखने के उपयोग का परिचय देगा। गहन सीखने का मॉडल ओपनएआई ओपन सोर्स पीपीओ है, और वातावरण जिम की शैली को संदर्भित करता है। समझने और परीक्षण की सुविधा के लिए, एलएसटीएम का पीपीओ मॉडल और बैकटेस्टिंग के लिए जिम वातावरण तैयार पैकेज का उपयोग किए बिना सीधे लिखे जाते हैं। पीपीओ, या निकटतम नीति अनुकूलन, नीति ग्रेडिएंट का एक अनुकूलन सुधार है। जिम को ओपनएआई द्वारा भी जारी किया गया था। यह रणनीति नेटवर्क के साथ बातचीत कर सकता है और वर्तमान वातावरण की स्थिति और पुरस्कारों को फीडबैक कर सकता है। यह गहन सीखने के अभ्यास की तरह है। यह एलएसटीएम के पीपीओ मॉडल का उपयोग बिटकॉइन की बाजार की जानकारी के अनुसार सीधे खरीद, बिक्री या कोई संचालन नहीं करने जैसे निर्देश बनाने के लिए करता है। फीडबैक बैकटेस्ट वातावरण द्वारा दिया जाता है। प्रशिक्षण के माध्यम से, मॉडल को रणनीतिक लाभ के लक्ष्य को प्राप्त करने के लिए लगातार अनुकूलित किया जाता है। इस लेख को पढ़ने के लिए पायथन, पायटॉर्च और डीआरएल में गहन सीखने की एक निश्चित नींव की आवश्यकता होती है। लेकिन इससे कोई फर्क नहीं पड़ता कि आप नहीं कर सकते हैं। इस लेख में दिए गए कोड के साथ सीखना और शुरू करना आसान है। यह ट्यूटोरियल एफएमजेड क्वांट ट्रेडिंग प्लेटफॉर्म द्वारा उत्पादित है (www.fmz.com) संपर्क के लिए क्यूक्यू समूह में शामिल होने के लिए आपका स्वागत है: 863946592।
2. डेटा और सीखने के संदर्भ
एफएमजेड क्वांट ट्रेडिंग प्लेटफॉर्म से प्राप्त बिटकॉइन मूल्य डेटाःhttps://www.quantinfo.com/Tools/View/4.html. ट्रेडिंग रणनीतियों को प्रशिक्षित करने के लिए DRL+gym का उपयोग करने वाला एक लेखःhttps://towardsdatascience.com/visualizing-stock-trading-agents-using-matplotlib-and-gym-584c992bc6d4. पायटॉर्च के साथ आरंभ करने के कुछ उदाहरणःhttps://github.com/yunjey/pytorch-tutorial.. इस लेख में एलएसटीएम-पीपीओ मॉडल द्वारा सीधे लागू किया जाएगाःhttps://github.com/seungeunrho/minimalRL/blob/master/ppo-lstm.py.. पीपीओ के बारे में लेख:https://zhuanlan.zhihu.com/p/38185553. डीआरएल के बारे में अधिक लेखःhttps://www.zhihu.com/people/flood-sung/posts.. जिम के बारे में, इस लेख में स्थापना की आवश्यकता नहीं है, लेकिन यह गहन शिक्षा में बहुत आम हैःhttps://gym.openai.com/.
3. एलएसटीएम-पीपीओ
पीपीओ के गहन विवरण के लिए, आप पिछले संदर्भ सामग्री से सीख सकते हैं। यहाँ अवधारणाओं के लिए सिर्फ एक सरल परिचय है। एलएसटीएम नेटवर्क के अंतिम अंक में केवल कीमत की भविष्यवाणी की गई थी। भविष्यवाणी की गई कीमत के आधार पर खरीदने और बेचने का तरीका अलग से महसूस करना होगा। यह सोचना स्वाभाविक है कि ट्रेडिंग एक्शन का प्रत्यक्ष आउटपुट अधिक प्रत्यक्ष होगा। यह नीति ढाल का मामला है, जो इनपुट पर्यावरण जानकारी एस के अनुसार विभिन्न कार्यों की संभावना दे सकता है। एलएसटीएम का नुकसान भविष्यवाणी की गई कीमत और वास्तविक मूल्य के बीच का अंतर है, जबकि पीजी का नुकसान - लॉग § * क्यू है, जहां पी एक आउटपुट कार्रवाई की संभावना है, और क्यू कार्रवाई का मूल्य है (जैसे अंतर्ज्ञानी पुरस्कार स्कोर) । स्पष्टीकरण यह है कि यदि किसी कार्रवाई का मूल्य अधिक है, तो नेटवर्क को हानि को कम करने के लिए एक कुंजी होनी चाहिए। हालांकि पीपीओ अधिक जटिल है, इसका सिद्धांत यह है कि प्रत्येक कार्रवाई के आउटपुट मूल्य का मूल्यांकन और अद्यतन करना कितना बेहतर है।
एलएसटीएम-पीपीओ का स्रोत कोड नीचे दिया गया है, जिसे पिछले डेटा के साथ संयोजन में समझा जा सकता हैः
import time
import requests
import json
import numpy as np
import pandas as pd
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torch.distributions import Categorical
from itertools import count
# Hyperparameters of the model
learning_rate = 0.0005
gamma = 0.98
lmbda = 0.95
eps_clip = 0.1
K_epoch = 3
device = torch.device('cpu') # It can also be changed to GPU version.
class PPO(nn.Module):
def __init__(self, state_size, action_size):
super(PPO, self).__init__()
self.data = []
self.fc1 = nn.Linear(state_size,10)
self.lstm = nn.LSTM(10,10)
self.fc_pi = nn.Linear(10,action_size)
self.fc_v = nn.Linear(10,1)
self.optimizer = optim.Adam(self.parameters(), lr=learning_rate)
def pi(self, x, hidden):
# Output the probability of each action. Since LSTM network also contains the information of hidden layer, please refer to the previous article.
x = F.relu(self.fc1(x))
x = x.view(-1, 1, 10)
x, lstm_hidden = self.lstm(x, hidden)
x = self.fc_pi(x)
prob = F.softmax(x, dim=2)
return prob, lstm_hidden
def v(self, x, hidden):
# Value function is used to evaluate the current situation, so there is only one output.
x = F.relu(self.fc1(x))
x = x.view(-1, 1, 10)
x, lstm_hidden = self.lstm(x, hidden)
v = self.fc_v(x)
return v
def put_data(self, transition):
self.data.append(transition)
def make_batch(self):
# Prepare the training data.
s_lst, a_lst, r_lst, s_prime_lst, prob_a_lst, hidden_lst, done_lst = [], [], [], [], [], [], []
for transition in self.data:
s, a, r, s_prime, prob_a, hidden, done = transition
s_lst.append(s)
a_lst.append([a])
r_lst.append([r])
s_prime_lst.append(s_prime)
prob_a_lst.append([prob_a])
hidden_lst.append(hidden)
done_mask = 0 if done else 1
done_lst.append([done_mask])
s,a,r,s_prime,done_mask,prob_a = torch.tensor(s_lst, dtype=torch.float), torch.tensor(a_lst), \
torch.tensor(r_lst), torch.tensor(s_prime_lst, dtype=torch.float), \
torch.tensor(done_lst, dtype=torch.float), torch.tensor(prob_a_lst)
self.data = []
return s,a,r,s_prime, done_mask, prob_a, hidden_lst[0]
def train_net(self):
s,a,r,s_prime,done_mask, prob_a, (h1,h2) = self.make_batch()
first_hidden = (h1.detach(), h2.detach())
for i in range(K_epoch):
v_prime = self.v(s_prime, first_hidden).squeeze(1)
td_target = r + gamma * v_prime * done_mask
v_s = self.v(s, first_hidden).squeeze(1)
delta = td_target - v_s
delta = delta.detach().numpy()
advantage_lst = []
advantage = 0.0
for item in delta[::-1]:
advantage = gamma * lmbda * advantage + item[0]
advantage_lst.append([advantage])
advantage_lst.reverse()
advantage = torch.tensor(advantage_lst, dtype=torch.float)
pi, _ = self.pi(s, first_hidden)
pi_a = pi.squeeze(1).gather(1,a)
ratio = torch.exp(torch.log(pi_a) - torch.log(prob_a)) # a/b == log(exp(a)-exp(b))
surr1 = ratio * advantage
surr2 = torch.clamp(ratio, 1-eps_clip, 1+eps_clip) * advantage
loss = -torch.min(surr1, surr2) + F.smooth_l1_loss(v_s, td_target.detach()) # Trained both value and decision networks at the same time.
self.optimizer.zero_grad()
loss.mean().backward(retain_graph=True)
self.optimizer.step()
4. बिटकॉइन बैकटेस्टिंग वातावरण
जिम के प्रारूप के बाद, एक रीसेट आरंभिकरण विधि है। चरण इनपुट क्रिया, और लौटाया परिणाम है (अगली स्थिति, कार्रवाई आय, समाप्त करने के लिए या नहीं, अतिरिक्त जानकारी) । पूरे बैकटेस्ट वातावरण भी 60 पंक्तियाँ है। आप अपने आप से अधिक जटिल संस्करणों को संशोधित कर सकते हैं। विशिष्ट कोड हैः
class BitcoinTradingEnv:
def __init__(self, df, commission=0.00075, initial_balance=10000, initial_stocks=1, all_data = False, sample_length= 500):
self.initial_stocks = initial_stocks # Initial number of Bitcoins
self.initial_balance = initial_balance # Initial assets
self.current_time = 0 # Time position of the backtest
self.commission = commission # Trading fees
self.done = False # Is the backtest over?
self.df = df
self.norm_df = 100*(self.df/self.df.shift(1)-1).fillna(0) # Standardized approach, simple yield normalization.
self.mode = all_data # Whether it is a sample backtest mode.
self.sample_length = 500 # Sample length
def reset(self):
self.balance = self.initial_balance
self.stocks = self.initial_stocks
self.last_profit = 0
if self.mode:
self.start = 0
self.end = self.df.shape[0]-1
else:
self.start = np.random.randint(0,self.df.shape[0]-self.sample_length)
self.end = self.start + self.sample_length
self.initial_value = self.initial_balance + self.initial_stocks*self.df.iloc[self.start,4]
self.stocks_value = self.initial_stocks*self.df.iloc[self.start,4]
self.stocks_pct = self.stocks_value/self.initial_value
self.value = self.initial_value
self.current_time = self.start
return np.concatenate([self.norm_df[['o','h','l','c','v']].iloc[self.start].values , [self.balance/10000, self.stocks/1]])
def step(self, action):
# action is the action taken by the strategy, here the account will be updated and the reward will be calculated.
done = False
if action == 0: # Hold
pass
elif action == 1: # Buy
buy_value = self.balance*0.5
if buy_value > 1: # Insufficient balance, no account operation.
self.balance -= buy_value
self.stocks += (1-self.commission)*buy_value/self.df.iloc[self.current_time,4]
elif action == 2: # Sell
sell_amount = self.stocks*0.5
if sell_amount > 0.0001:
self.stocks -= sell_amount
self.balance += (1-self.commission)*sell_amount*self.df.iloc[self.current_time,4]
self.current_time += 1
if self.current_time == self.end:
done = True
self.value = self.balance + self.stocks*self.df.iloc[self.current_time,4]
self.stocks_value = self.stocks*self.df.iloc[self.current_time,4]
self.stocks_pct = self.stocks_value/self.value
if self.value < 0.1*self.initial_value:
done = True
profit = self.value - (self.initial_balance+self.initial_stocks*self.df.iloc[self.current_time,4])
reward = profit - self.last_profit # The reward for each turn is the added revenue.
self.last_profit = profit
next_state = np.concatenate([self.norm_df[['o','h','l','c','v']].iloc[self.current_time].values , [self.balance/10000, self.stocks/1]])
return (next_state, reward, done, profit)
५. कुछ उल्लेखनीय विवरण
- प्रारंभिक खाते में मुद्रा क्यों है?
बैकटेस्ट वातावरण के रिटर्न की गणना करने का सूत्र हैः वर्तमान रिटर्न = चालू खाता मूल्य - प्रारंभिक खाते का वर्तमान मूल्य। इसका मतलब है कि यदि बिटकॉइन की कीमत घट जाती है और रणनीति सिक्का-बिक्री ऑपरेशन करती है, भले ही कुल खाता मूल्य घट जाए, रणनीति को वास्तव में पुरस्कृत किया जाना चाहिए। यदि बैकटेस्ट में लंबा समय लगता है, तो प्रारंभिक खाते का थोड़ा प्रभाव पड़ सकता है, लेकिन शुरुआत में इसका बहुत प्रभाव पड़ेगा। सापेक्ष रिटर्न की गणना सुनिश्चित करती है कि प्रत्येक सही ऑपरेशन से सकारात्मक पुरस्कार प्राप्त होगा।
- प्रशिक्षण के दौरान बाजार का नमूना क्यों लिया गया?
डेटा की कुल मात्रा 10,000 से अधिक के-लाइन है। यदि आप हर बार एक लूप को पूरी तरह से चलाते हैं, तो इसमें लंबा समय लगेगा, और रणनीति हर बार एक ही स्थिति का सामना करती है, तो ओवरफिट करना आसान हो सकता है। बैकटेस्ट के रूप में एक बार में 500 बार लेना। हालांकि अभी भी ओवरफिट करना संभव है, रणनीति 10,000 से अधिक विभिन्न संभावित शुरुआत का सामना करती है।
- क्या होगा यदि कोई मुद्रा या पैसा नहीं है?
इस स्थिति को बैकटेस्ट वातावरण में विचार नहीं किया जाता है। यदि मुद्रा बिक गई है या न्यूनतम ट्रेडिंग मात्रा तक नहीं पहुंच सकती है, तो बिक्री ऑपरेशन वास्तव में गैर-ऑपरेशन के बराबर है। यदि कीमत घट जाती है, तो सापेक्ष रिटर्न की गणना विधि के अनुसार, यह अभी भी रणनीतिक सकारात्मक रिटर्न पर आधारित है। इस स्थिति का प्रभाव यह है कि जब रणनीति का फैसला होता है कि बाजार कम हो रहा है और खाते की शेष मुद्रा को बेचा नहीं जा सकता है, तो बिक्री कार्रवाई को गैर-ऑपरेटिंग कार्रवाई से अलग करना असंभव है, लेकिन इसका बाजार पर रणनीति के निर्णय पर कोई प्रभाव नहीं पड़ता है।
- मुझे खाते की जानकारी को स्थिति के रूप में क्यों लौटना चाहिए?
पीपीओ मॉडल में वर्तमान स्थिति के मूल्य का मूल्यांकन करने के लिए एक मूल्य नेटवर्क है। स्पष्ट रूप से, यदि रणनीति यह मानती है कि कीमत बढ़ेगी, तो संपूर्ण स्थिति का सकारात्मक मूल्य तभी होगा जब चालू खाता बिटकॉइन रखता है, और इसके विपरीत। इसलिए, खाता जानकारी मूल्य नेटवर्क निर्णय के लिए एक महत्वपूर्ण आधार है। यह ध्यान दिया जाता है कि पिछले कार्रवाई की जानकारी को स्थिति के रूप में वापस नहीं किया जाता है। मुझे लगता है कि मूल्य का न्याय करना बेकार है।
- यह कब गैर-संचालन में वापस आ जाएगा?
जब रणनीति यह तय करती है कि लेनदेन द्वारा लाए गए रिटर्न हैंडलिंग शुल्क को कवर नहीं कर सकते हैं, तो इसे गैर-संचालन पर लौटना चाहिए। हालांकि पिछले विवरण में मूल्य प्रवृत्ति का न्याय करने के लिए रणनीतियों का बार-बार उपयोग किया गया है, यह केवल समझ की सुविधा के लिए है। वास्तव में, यह पीपीओ मॉडल बाजार की भविष्यवाणी नहीं करता है, लेकिन केवल तीन कार्यों की संभावना को आउटपुट करता है।
6. डेटा अधिग्रहण और प्रशिक्षण
पिछले लेख की तरह, डेटा अधिग्रहण विधि और प्रारूप इस प्रकार हैः Bitfinex Exchange BTC_USD ट्रेडिंग जोड़ी की एक घंटे की अवधि K-लाइन 7 मई 2018 से 27 जून 2019 तकः
resp = requests.get('https://www.quantinfo.com/API/m/chart/history?symbol=BTC_USD_BITFINEX&resolution=60&from=1525622626&to=1561607596')
data = resp.json()
df = pd.DataFrame(data,columns = ['t','o','h','l','c','v'])
df.index = df['t']
df = df.dropna()
df = df.astype(np.float32)
एलएसटीएम नेटवर्क के उपयोग के कारण, प्रशिक्षण का समय बहुत लंबा है. मैंने जीपीयू संस्करण पर स्विच किया, जो लगभग तीन गुना तेज है.
env = BitcoinTradingEnv(df)
model = PPO()
total_profit = 0 # Record total profit
profit_list = [] # Record the profits of each training session
for n_epi in range(10000):
hidden = (torch.zeros([1, 1, 32], dtype=torch.float).to(device), torch.zeros([1, 1, 32], dtype=torch.float).to(device))
s = env.reset()
done = False
buy_action = 0
sell_action = 0
while not done:
h_input = hidden
prob, hidden = model.pi(torch.from_numpy(s).float().to(device), h_input)
prob = prob.view(-1)
m = Categorical(prob)
a = m.sample().item()
if a==1:
buy_action += 1
if a==2:
sell_action += 1
s_prime, r, done, profit = env.step(a)
model.put_data((s, a, r/10.0, s_prime, prob[a].item(), h_input, done))
s = s_prime
model.train_net()
profit_list.append(profit)
total_profit += profit
if n_epi%10==0:
print("# of episode :{:<5}, profit : {:<8.1f}, buy :{:<3}, sell :{:<3}, total profit: {:<20.1f}".format(n_epi, profit, buy_action, sell_action, total_profit))
7. प्रशिक्षण के परिणाम और विश्लेषण
लंबे इंतजार के बाद:

सबसे पहले, प्रशिक्षण डेटा के बाजार को देखें। सामान्य तौर पर, पहली छमाही में लंबे समय तक गिरावट है, और दूसरी छमाही में एक मजबूत उछाल है।
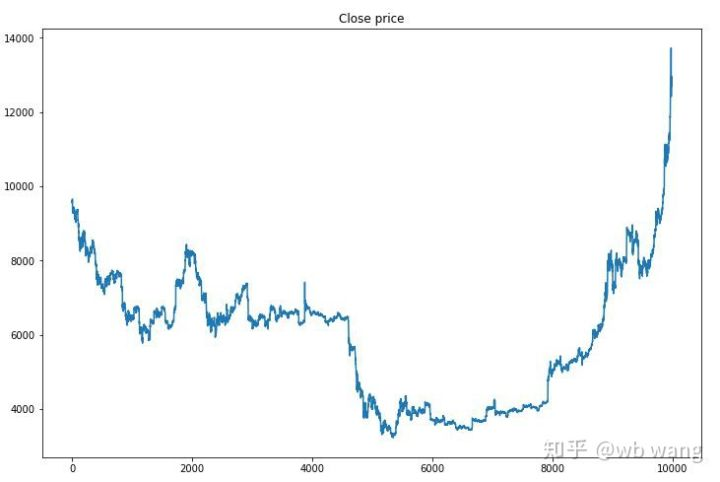
प्रशिक्षण के प्रारंभिक चरण में कई खरीद संचालन होते हैं, और मूल रूप से कोई लाभदायक दौर नहीं होता है। प्रशिक्षण के मध्य तक, खरीद ऑपरेशन धीरे-धीरे कम हो गया है, और लाभ की संभावना भी बढ़ रही है, लेकिन अभी भी नुकसान का एक बड़ा मौका है।
प्रत्येक राउंड के लाभ को समतल करें, और परिणाम निम्नानुसार है:
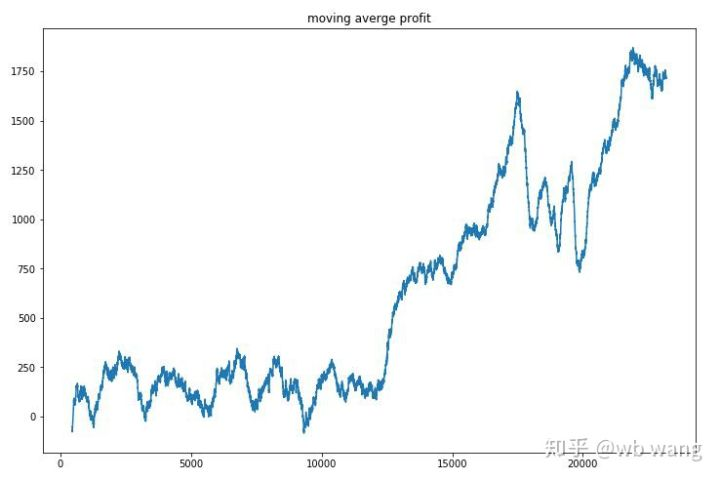
रणनीति ने जल्दी से इस स्थिति से छुटकारा पा लिया कि प्रारंभिक रिटर्न नकारात्मक था, लेकिन उतार-चढ़ाव बड़ा था। 10,000 राउंड के बाद तक रिटर्न तेजी से नहीं बढ़ा। सामान्य तौर पर, मॉडल प्रशिक्षण बहुत मुश्किल था।
अंतिम प्रशिक्षण के बाद, मॉडल को यह देखने के लिए सभी डेटा फिर से चलाने दें कि यह कैसे प्रदर्शन करता है। इस अवधि के दौरान, खाते का कुल बाजार मूल्य, रखे गए बिटकॉइन की संख्या, बिटकॉइन मूल्य का अनुपात और कुल रिटर्न रिकॉर्ड करें। पहला है कुल बाजार मूल्य, और कुल रिटर्न इसके समान हैं, वे पोस्ट नहीं किया जाएगाः
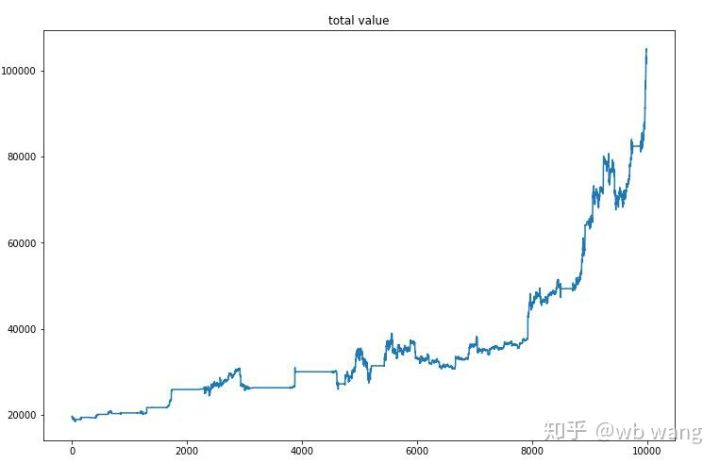
प्रारंभिक भालू बाजार में कुल बाजार मूल्य धीरे-धीरे बढ़ता गया और बाद के बैल बाजार में वृद्धि के साथ रहा, लेकिन फिर भी आवधिक नुकसान हुए।
अंत में, पदों के अनुपात पर एक नज़र डालें। चार्ट की बाईं धुरी पदों का अनुपात है, और दाईं धुरी बाजार है। यह प्रारंभिक रूप से न्याय किया जा सकता है कि मॉडल ओवरफिट है। शुरुआती भालू बाजार में पदों की आवृत्ति कम है, और बाजार के नीचे उच्च है। यह भी देखा जा सकता है कि मॉडल ने दीर्घकालिक पदों को पकड़ना नहीं सीखा है और हमेशा जल्दी से बेचता है।
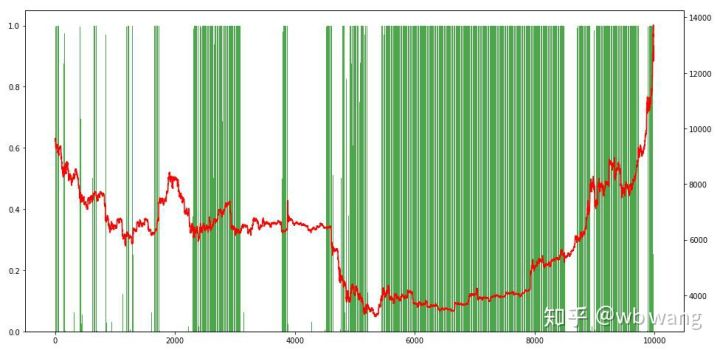
8. परीक्षण डेटा विश्लेषण
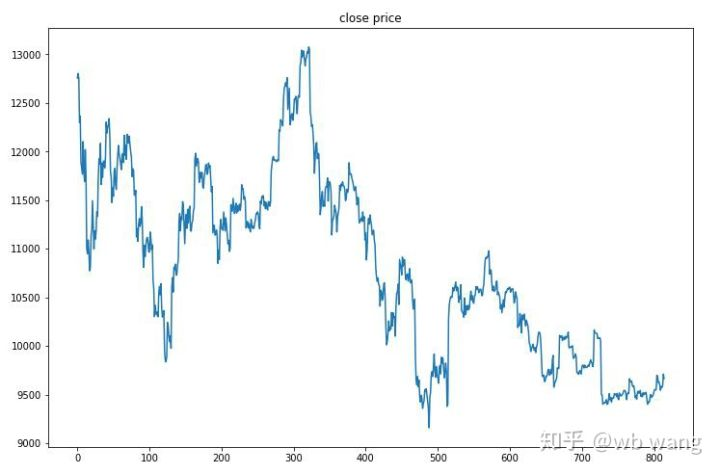
27 जून 2019 से अब तक बिटकॉइन का एक घंटे का बाजार परीक्षण डेटा से प्राप्त किया गया था। यह चार्ट से देखा जा सकता है कि कीमत $13,000 से गिरकर $9,000 से अधिक हो गई है, जो मॉडल के लिए एक महान परीक्षण है।
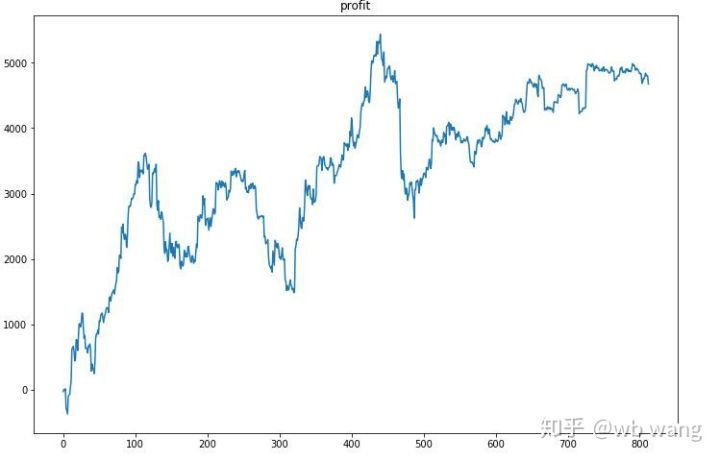
सबसे पहले, अंतिम सापेक्ष वापसी ने ऐसा-ऐसा किया, लेकिन कोई नुकसान नहीं हुआ।
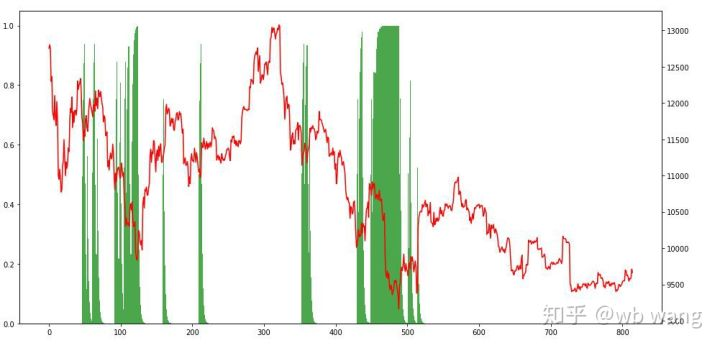
स्थिति की स्थिति को देखते हुए, हम अनुमान लगा सकते हैं कि मॉडल एक तेज गिरावट के बाद खरीदने और एक रिबाउंड के बाद बेचने की प्रवृत्ति रखता है। बिटकॉइन का बाजार हाल की अवधि में थोड़ा उतार-चढ़ाव किया है, और मॉडल एक छोटी स्थिति में रहा है।
9. सारांश
इस पेपर में, एक बिटकॉइन स्वचालित ट्रेडिंग रोबोट को पीपीओ की मदद से प्रशिक्षित किया जाता है, एक गहरी गहन सीखने की विधि, और कुछ निष्कर्ष प्राप्त किए जाते हैं। सीमित समय के कारण, मॉडल में अभी भी कुछ पहलुओं में सुधार किया जाना है। चर्चा का स्वागत है। सबसे बड़ा सबक यह है कि डेटा मानकीकरण विधि के लिए, स्केलिंग और अन्य तरीकों का उपयोग न करें, अन्यथा मॉडल जल्दी से मूल्य और बाजार के बीच संबंध को याद रखेगा, और ओवरफिट में गिर जाएगा। मानकीकृत परिवर्तन दर सापेक्ष डेटा है, जो मॉडल के लिए बाजार के साथ संबंध को याद रखना मुश्किल बनाता है, और परिवर्तन दर और वृद्धि और कमी के बीच संबंध खोजने के लिए मजबूर है।
पिछले लेखों का परिचय: एक उच्च आवृत्ति रणनीति मैंने खुलासा किया कि एक बार बहुत लाभदायक थाःhttps://www.fmz.com/bbs-topic/9886.
- क्रिप्टोक्यूरेंसी बाजार में मौलिक विश्लेषण की मात्राः डेटा को खुद के लिए बोलने दें!
- मौद्रिक सर्कल के मूलभूत मात्रात्मक अनुसंधान - अब हर तरह के जादूगरों पर भरोसा न करें, डेटा निष्पक्ष रूप से बोलते हैं!
- क्वांटिफाइड ट्रेडिंग के लिए आवश्यक उपकरण - आविष्कारक क्वांटिफाइड डेटा एक्सप्लोरर मॉड्यूल
- सब कुछ में महारत हासिल करना - एफएमजेड ट्रेडिंग टर्मिनल का नया संस्करण (टीआरबी आर्बिट्रेज स्रोत कोड के साथ)
- सब कुछ जानने के लिए FMZ के नए संस्करण के लिए ट्रेडिंग टर्मिनल का परिचय (अनुदानित TRB सूट स्रोत कोड)
- एफएमजेड क्वांटः क्रिप्टोकरेंसी बाजार में सामान्य आवश्यकताओं के डिजाइन उदाहरणों का विश्लेषण (II)
- 80 पंक्तियों के कोड में उच्च आवृत्ति रणनीति के साथ मस्तिष्क रहित बिक्री बॉट्स का शोषण कैसे करें
- एफएमजेड क्वांटिकेशनः क्रिप्टोक्यूरेंसी बाजार में आम जरूरतों के डिजाइन उदाहरण का विश्लेषण
- 80 लाइनों के कोड के साथ उच्च आवृत्ति रणनीतियों का उपयोग करके बेचने के लिए मस्तिष्क रहित रोबोट का शोषण कैसे करें
- एफएमजेड क्वांटः क्रिप्टोकरेंसी बाजार में सामान्य आवश्यकताओं के डिजाइन उदाहरणों का विश्लेषण (I)
- एफएमजेड क्वांटिकेशनः क्रिप्टोक्यूरेंसी बाजार में आम जरूरतों के डिजाइन उदाहरण का विश्लेषण (1)