उच्च आवृत्ति व्यापार रणनीतियों पर विचार (5)
लेखक:लिडिया, बनाया गयाः 2023-08-10 15:57:27, अद्यतन किया गयाः 2023-09-12 15:51:54
उच्च आवृत्ति व्यापार रणनीतियों पर विचार (5)
पिछले लेख में, मध्य मूल्य की गणना के लिए विभिन्न तरीकों का परिचय दिया गया था, और एक संशोधित मध्य मूल्य का प्रस्ताव दिया गया था। इस लेख में, हम इस विषय में गहराई से गहराई से जाएंगे।
आवश्यक डेटा
हमें ऑर्डर बुक के शीर्ष दस स्तरों के लिए ऑर्डर फ्लो डेटा और गहराई डेटा की आवश्यकता है, जिसे 100ms की अपडेट आवृत्ति के साथ लाइव ट्रेडिंग से एकत्र किया गया है। सादगी के लिए, हम बोली और पूछ मूल्य के लिए वास्तविक समय के अपडेट शामिल नहीं करेंगे। डेटा आकार को कम करने के लिए, हमने केवल 100,000 पंक्तियों को गहराई डेटा रखा है और टिक-बाय-टिक बाजार डेटा को अलग-अलग स्तंभों में अलग कर दिया है।
में [1]:
from datetime import date,datetime
import time
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import ast
%matplotlib inline
[2] मेंः
tick_size = 0.0001
[3] मेंः
trades = pd.read_csv('YGGUSDT_aggTrade.csv',names=['type','event_time', 'agg_trade_id','symbol', 'price', 'quantity', 'first_trade_id', 'last_trade_id',
'transact_time', 'is_buyer_maker'])
[4] मेंः
trades = trades.groupby(['transact_time','is_buyer_maker']).agg({
'transact_time':'last',
'agg_trade_id': 'last',
'price': 'first',
'quantity': 'sum',
'first_trade_id': 'first',
'last_trade_id': 'last',
'is_buyer_maker': 'last',
})
[5] मेंः
trades.index = pd.to_datetime(trades['transact_time'], unit='ms')
trades.index.rename('time', inplace=True)
trades['interval'] = trades['transact_time'] - trades['transact_time'].shift()
[6] मेंः
depths = pd.read_csv('YGGUSDT_depth.csv',names=['type','event_time', 'transact_time','symbol', 'u1', 'u2', 'u3', 'bids','asks'])
[7] मेंः
depths = depths.iloc[:100000]
[8] मेंः
depths['bids'] = depths['bids'].apply(ast.literal_eval).copy()
depths['asks'] = depths['asks'].apply(ast.literal_eval).copy()
[9] मेंः
def expand_bid(bid_data):
expanded = {}
for j, (price, quantity) in enumerate(bid_data):
expanded[f'bid_{j}_price'] = float(price)
expanded[f'bid_{j}_quantity'] = float(quantity)
return pd.Series(expanded)
def expand_ask(ask_data):
expanded = {}
for j, (price, quantity) in enumerate(ask_data):
expanded[f'ask_{j}_price'] = float(price)
expanded[f'ask_{j}_quantity'] = float(quantity)
return pd.Series(expanded)
# Apply to each line to get a new df
expanded_df_bid = depths['bids'].apply(expand_bid)
expanded_df_ask = depths['asks'].apply(expand_ask)
# Expansion on the original df
depths = pd.concat([depths, expanded_df_bid, expanded_df_ask], axis=1)
[10] मेंः
depths.index = pd.to_datetime(depths['transact_time'], unit='ms')
depths.index.rename('time', inplace=True);
[11] मेंः
trades = trades[trades['transact_time'] < depths['transact_time'].iloc[-1]]
इन 20 स्तरों में बाजार के वितरण पर एक नज़र डालें। यह अपेक्षाओं के अनुरूप है, बाजार मूल्य से अधिक आदेश दिए गए हैं। इसके अलावा, खरीद आदेश और बिक्री आदेश मोटे तौर पर सममित हैं।
[14] मेंः
bid_mean_list = []
ask_mean_list = []
for i in range(20):
bid_mean_list.append(round(depths[f'bid_{i}_quantity'].mean(),0))
ask_mean_list.append(round(depths[f'ask_{i}_quantity'].mean(),0))
plt.figure(figsize=(10, 5))
plt.plot(bid_mean_list);
plt.plot(ask_mean_list);
plt.grid(True)
बाहर[1]:
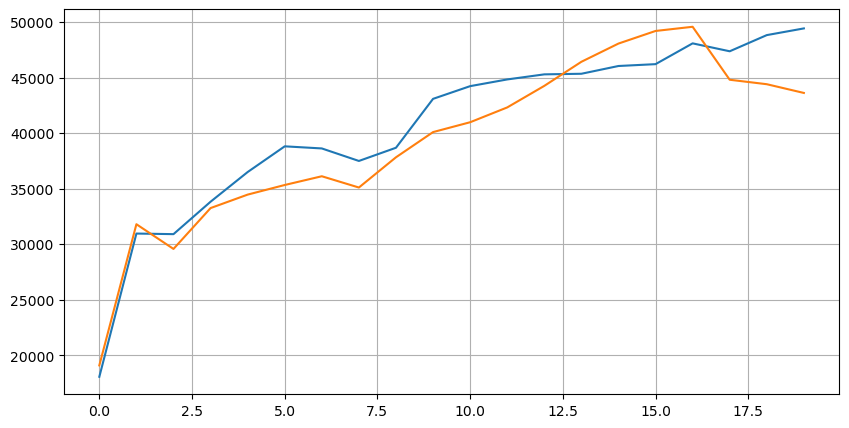
पूर्वानुमान की सटीकता का मूल्यांकन करने के लिए लेनदेन डेटा के साथ गहराई डेटा को मिलाएं। सुनिश्चित करें कि लेनदेन डेटा गहराई डेटा से बाद में है। विलंबता पर विचार किए बिना, सीधे पूर्वानुमानित मूल्य और वास्तविक लेनदेन मूल्य के बीच औसत वर्ग त्रुटि की गणना करें। इसका उपयोग भविष्यवाणी की सटीकता को मापने के लिए किया जाता है।
परिणामों से, बोली और पूछ मूल्य (मध्य_मूल्य) के औसत मूल्य के लिए त्रुटि सबसे अधिक है। हालांकि, जब भारित मध्य_मूल्य में बदल दिया जाता है, तो त्रुटि तुरंत काफी कम हो जाती है। समायोजित भारित मध्य_मूल्य का उपयोग करके आगे सुधार देखा जाता है। केवल I ^ 3 / 2 का उपयोग करने पर प्रतिक्रिया प्राप्त करने के बाद, यह जाँच की गई और पाया गया कि परिणाम बेहतर थे। प्रतिबिंब पर, यह घटनाओं की विभिन्न आवृत्तियों के कारण होने की संभावना है। जब मैं -1 और 1 के करीब होता है, तो यह कम संभावना वाली घटनाओं का प्रतिनिधित्व करता है। इन कम संभावना वाली घटनाओं के लिए सुधार करने के लिए, उच्च आवृत्ति वाली घटनाओं की भविष्यवाणी करने की सटीकता से समझौता किया जाता है। इसलिए, उच्च आवृत्ति वाली घटनाओं को प्राथमिकता देने के लिए, कुछ समायोजन किए गए (ये पैरामीटर विशुद्ध रूप से परीक्षण-त्रुटि-त्रुटि थे और लाइव ट्रेडिंग में सीमित व्यावहारिक महत्व रखते हैं) ।
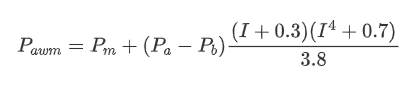
परिणामों में थोड़ा सुधार हुआ है। जैसा कि पिछले लेख में उल्लेख किया गया है, रणनीतियों को भविष्यवाणी के लिए अधिक डेटा पर भरोसा करना चाहिए। अधिक गहराई और ऑर्डर लेनदेन डेटा की उपलब्धता के साथ, ऑर्डर बुक पर ध्यान केंद्रित करने से प्राप्त सुधार पहले से ही कमजोर है।
[15] मेंः
df = pd.merge_asof(trades, depths, on='transact_time', direction='backward')
[17] मेंः
df['spread'] = round(df['ask_0_price'] - df['bid_0_price'],4)
df['mid_price'] = (df['bid_0_price']+ df['ask_0_price']) / 2
df['I'] = (df['bid_0_quantity'] - df['ask_0_quantity']) / (df['bid_0_quantity'] + df['ask_0_quantity'])
df['weight_mid_price'] = df['mid_price'] + df['spread']*df['I']/2
df['adjust_mid_price'] = df['mid_price'] + df['spread']*(df['I'])*(df['I']**8+1)/4
df['adjust_mid_price_2'] = df['mid_price'] + df['spread']*df['I']*(df['I']**2+1)/4
df['adjust_mid_price_3'] = df['mid_price'] + df['spread']*df['I']**3/2
df['adjust_mid_price_4'] = df['mid_price'] + df['spread']*(df['I']+0.3)*(df['I']**4+0.7)/3.8
[18] मेंः
print('Mean value Error in mid_price:', ((df['price']-df['mid_price'])**2).sum())
print('Error of pending order volume weighted mid_price:', ((df['price']-df['weight_mid_price'])**2).sum())
print('The error of the adjusted mid_price:', ((df['price']-df['adjust_mid_price'])**2).sum())
print('The error of the adjusted mid_price_2:', ((df['price']-df['adjust_mid_price_2'])**2).sum())
print('The error of the adjusted mid_price_3:', ((df['price']-df['adjust_mid_price_3'])**2).sum())
print('The error of the adjusted mid_price_4:', ((df['price']-df['adjust_mid_price_4'])**2).sum())
बाहर[18]:
मध्य मूल्य में त्रुटिः 0.0048751924999999845 लंबित ऑर्डर वॉल्यूम भारित मध्य_मूल्य की त्रुटिः 0.0048373440193987035 समायोजित मध्य_मूल्य की त्रुटिः 0.004803654771638586 समायोजित मध्य_मूल्य_2 की त्रुटिः 0.004808216498329721 समायोजित मध्य_मूल्य_3 की त्रुटिः 0.004794984755260528 समायोजित मध्य_मूल्य_4 की त्रुटिः 0.0047909595497071375
गहराई के दूसरे स्तर पर विचार करें
हम पिछले लेख के दृष्टिकोण का अनुसरण कर सकते हैं एक पैरामीटर की विभिन्न सीमाओं की जांच करने और लेनदेन मूल्य में परिवर्तन के आधार पर मध्य_मूल्य में इसके योगदान को मापने के लिए। गहराई के पहले स्तर के समान, जैसे-जैसे I बढ़ता है, लेनदेन मूल्य में वृद्धि होने की अधिक संभावना है, जो I से सकारात्मक योगदान का संकेत देता है।
दूसरी गहराई के स्तर पर भी इसी दृष्टिकोण को लागू करते हुए, हम पाते हैं कि यद्यपि प्रभाव पहले स्तर की तुलना में थोड़ा छोटा है, फिर भी यह महत्वपूर्ण है और इसे नजरअंदाज नहीं किया जाना चाहिए। तीसरा गहराई स्तर भी एक कमजोर योगदान दिखाता है, लेकिन कम एकरसता के साथ। गहरी गहराई में कम संदर्भ मूल्य होता है।
विभिन्न योगदानों के आधार पर, हम असंतुलन मापदंडों के इन तीन स्तरों को अलग-अलग भार देते हैं। विभिन्न गणना विधियों की जांच करके, हम भविष्यवाणी त्रुटियों में और कमी देखते हैं।
[19] मेंः
bins = np.linspace(-1, 1, 50)
df['change'] = (df['price'].pct_change().shift(-1))/tick_size
df['I_bins'] = pd.cut(df['I'], bins, labels=bins[1:])
df['I_2'] = (df['bid_1_quantity'] - df['ask_1_quantity']) / (df['bid_1_quantity'] + df['ask_1_quantity'])
df['I_2_bins'] = pd.cut(df['I_2'], bins, labels=bins[1:])
df['I_3'] = (df['bid_2_quantity'] - df['ask_2_quantity']) / (df['bid_2_quantity'] + df['ask_2_quantity'])
df['I_3_bins'] = pd.cut(df['I_3'], bins, labels=bins[1:])
df['I_4'] = (df['bid_3_quantity'] - df['ask_3_quantity']) / (df['bid_3_quantity'] + df['ask_3_quantity'])
df['I_4_bins'] = pd.cut(df['I_4'], bins, labels=bins[1:])
fig, axes = plt.subplots(nrows=2, ncols=2, figsize=(8, 5))
axes[0][0].plot(df.groupby('I_bins')['change'].mean())
axes[0][0].set_title('I')
axes[0][0].grid(True)
axes[0][1].plot(df.groupby('I_2_bins')['change'].mean())
axes[0][1].set_title('I 2')
axes[0][1].grid(True)
axes[1][0].plot(df.groupby('I_3_bins')['change'].mean())
axes[1][0].set_title('I 3')
axes[1][0].grid(True)
axes[1][1].plot(df.groupby('I_4_bins')['change'].mean())
axes[1][1].set_title('I 4')
axes[1][1].grid(True)
plt.tight_layout();
बाहर[19]:
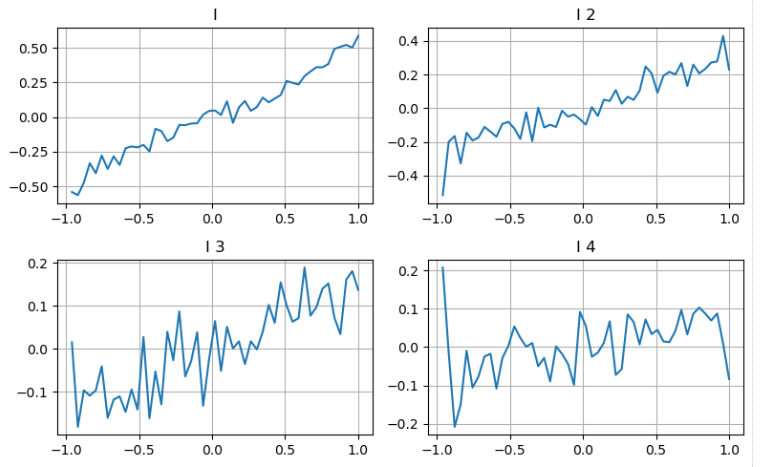
[20] मेंः
df['adjust_mid_price_4'] = df['mid_price'] + df['spread']*(df['I']+0.3)*(df['I']**4+0.7)/3.8
df['adjust_mid_price_5'] = df['mid_price'] + df['spread']*(0.7*df['I']+0.3*df['I_2'])/2
df['adjust_mid_price_6'] = df['mid_price'] + df['spread']*(0.7*df['I']+0.3*df['I_2'])**3/2
df['adjust_mid_price_7'] = df['mid_price'] + df['spread']*(0.7*df['I']+0.3*df['I_2']+0.3)*((0.7*df['I']+0.3*df['I_2'])**4+0.7)/3.8
df['adjust_mid_price_8'] = df['mid_price'] + df['spread']*(0.7*df['I']+0.2*df['I_2']+0.1*df['I_3']+0.3)*((0.7*df['I']+0.3*df['I_2']+0.1*df['I_3'])**4+0.7)/3.8
[21] मेंः
print('The error of the adjusted mid_price_4:', ((df['price']-df['adjust_mid_price_4'])**2).sum())
print('The error of the adjusted mid_price_5:', ((df['price']-df['adjust_mid_price_5'])**2).sum())
print('The error of the adjusted mid_price_6:', ((df['price']-df['adjust_mid_price_6'])**2).sum())
print('The error of the adjusted mid_price_7:', ((df['price']-df['adjust_mid_price_7'])**2).sum())
print('The error of the adjusted mid_price_8:', ((df['price']-df['adjust_mid_price_8'])**2).sum())
बाहर[21]:
समायोजित मध्य_मूल्य_4 की त्रुटिः 0.0047909595497071375 समायोजित मध्य_मूल्य_5 की त्रुटिः 0.0047884350488318714 समायोजित मध्य_मूल्य_6 की त्रुटिः 0.0047778319053133735 समायोजित मध्य_मूल्य_7 की त्रुटिः 0.004773578540592192 समायोजित मध्य_मूल्य_8 की त्रुटिः 0.004771415189297518
लेन-देन डेटा पर विचार करना
लेन-देन डेटा सीधे लंबी और छोटी स्थिति की सीमा को दर्शाता है। आखिरकार, लेनदेन में वास्तविक धन शामिल है, जबकि ऑर्डर देने की लागत बहुत कम है और इसमें जानबूझकर धोखा भी शामिल हो सकता है। इसलिए, मध्य_मूल्य की भविष्यवाणी करते समय, रणनीतियों को लेनदेन डेटा पर ध्यान केंद्रित करना चाहिए।
रूप के संदर्भ में, हम औसत आदेश आगमन मात्रा के असंतुलन को VI के रूप में परिभाषित कर सकते हैं, जिसमें Vb और Vs क्रमशः एक इकाई समय अंतराल के भीतर खरीद और बिक्री आदेशों की औसत मात्रा का प्रतिनिधित्व करते हैं।
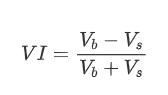
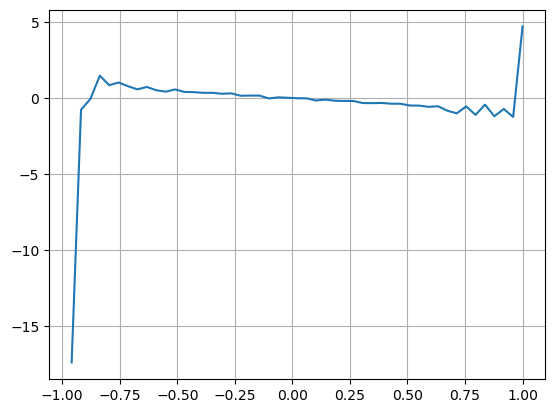
परिणामों से पता चलता है कि एक छोटी अवधि में आगमन की मात्रा का मूल्य परिवर्तन की भविष्यवाणी पर सबसे महत्वपूर्ण प्रभाव पड़ता है। जब VI 0.1 और 0.9 के बीच होता है, तो यह मूल्य के साथ नकारात्मक रूप से सहसंबंधित होता है, जबकि इस सीमा के बाहर, यह मूल्य के साथ सकारात्मक रूप से सहसंबंधित होता है। इससे पता चलता है कि जब बाजार चरम नहीं होता है और मुख्य रूप से दोलन करता है, तो कीमत औसत पर लौटने की प्रवृत्ति होती है। हालांकि, चरम बाजार की स्थिति में, जैसे कि जब बड़ी संख्या में खरीद ऑर्डर होते हैं, तो विक्रय ऑर्डर भारी होते हैं, एक प्रवृत्ति उभरती है। इन कम संभावना परिदृश्यों पर विचार किए बिना भी, प्रवृत्ति और VI के बीच एक नकारात्मक रैखिक संबंध मानकर मध्य_मूल्य की भविष्यवाणी त्रुटि को काफी कम कर देता है। गुणांक
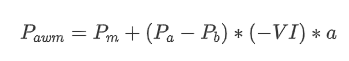
[22] मेंः
alpha=0.1
[23] मेंः
df['avg_buy_interval'] = None
df['avg_sell_interval'] = None
df.loc[df['is_buyer_maker'] == True, 'avg_buy_interval'] = df[df['is_buyer_maker'] == True]['transact_time'].diff().ewm(alpha=alpha).mean()
df.loc[df['is_buyer_maker'] == False, 'avg_sell_interval'] = df[df['is_buyer_maker'] == False]['transact_time'].diff().ewm(alpha=alpha).mean()
[24] मेंः
df['avg_buy_quantity'] = None
df['avg_sell_quantity'] = None
df.loc[df['is_buyer_maker'] == True, 'avg_buy_quantity'] = df[df['is_buyer_maker'] == True]['quantity'].ewm(alpha=alpha).mean()
df.loc[df['is_buyer_maker'] == False, 'avg_sell_quantity'] = df[df['is_buyer_maker'] == False]['quantity'].ewm(alpha=alpha).mean()
[25] मेंः
df['avg_buy_quantity'] = df['avg_buy_quantity'].fillna(method='ffill')
df['avg_sell_quantity'] = df['avg_sell_quantity'].fillna(method='ffill')
df['avg_buy_interval'] = df['avg_buy_interval'].fillna(method='ffill')
df['avg_sell_interval'] = df['avg_sell_interval'].fillna(method='ffill')
df['avg_buy_rate'] = 1000 / df['avg_buy_interval']
df['avg_sell_rate'] =1000 / df['avg_sell_interval']
df['avg_buy_volume'] = df['avg_buy_rate']*df['avg_buy_quantity']
df['avg_sell_volume'] = df['avg_sell_rate']*df['avg_sell_quantity']
[26] मेंः
df['I'] = (df['bid_0_quantity']- df['ask_0_quantity']) / (df['bid_0_quantity'] + df['ask_0_quantity'])
df['OI'] = (df['avg_buy_rate']-df['avg_sell_rate']) / (df['avg_buy_rate'] + df['avg_sell_rate'])
df['QI'] = (df['avg_buy_quantity']-df['avg_sell_quantity']) / (df['avg_buy_quantity'] + df['avg_sell_quantity'])
df['VI'] = (df['avg_buy_volume']-df['avg_sell_volume']) / (df['avg_buy_volume'] + df['avg_sell_volume'])
[27] मेंः
bins = np.linspace(-1, 1, 50)
df['VI_bins'] = pd.cut(df['VI'], bins, labels=bins[1:])
plt.plot(df.groupby('VI_bins')['change'].mean());
plt.grid(True)
बाहर[27]:
[२८] मेंः
df['adjust_mid_price'] = df['mid_price'] + df['spread']*df['I']/2
df['adjust_mid_price_9'] = df['mid_price'] + df['spread']*(-df['OI'])*2
df['adjust_mid_price_10'] = df['mid_price'] + df['spread']*(-df['VI'])*1.4
[29] मेंः
print('The error of the adjusted mid_price:', ((df['price']-df['adjust_mid_price'])**2).sum())
print('The error of the adjusted mid_price_9:', ((df['price']-df['adjust_mid_price_9'])**2).sum())
print('The error of the adjusted mid_price_10:', ((df['price']-df['adjust_mid_price_10'])**2).sum())
बाहर[1]:
समायोजित मध्य_मूल्य की त्रुटिः 0.0048373440193987035 समायोजित मध्य_मूल्य_9 की त्रुटिः 0.004629586542840461 समायोजित मध्य_मूल्य_10 की त्रुटिः 0.004401790287167206
व्यापक मध्य मूल्य
ऑर्डर बुक असंतुलन और लेनदेन डेटा दोनों मध्य_मूल्य की भविष्यवाणी करने के लिए उपयोगी हैं, हम इन दो मापदंडों को एक साथ जोड़ सकते हैं। इस मामले में भारों का असाइनमेंट मनमाना है और सीमा स्थितियों को ध्यान में नहीं रखता है। चरम मामलों में, पूर्वानुमानित मध्य_मूल्य बोली और पूछ मूल्य के बीच नहीं पड़ सकता है। हालांकि, जब तक भविष्यवाणी त्रुटि को कम किया जा सकता है, ये विवरण बहुत चिंता का विषय नहीं हैं।
अंत में, पूर्वानुमान त्रुटि 0.00487 से 0.0043 तक कम हो जाती है। इस बिंदु पर, हम विषय में आगे नहीं जाएंगे। जब मध्य_मूल्य की भविष्यवाणी करने की बात आती है, तो अभी भी कई पहलुओं का पता लगाने की आवश्यकता होती है, क्योंकि यह अनिवार्य रूप से मूल्य की भविष्यवाणी कर रहा है। सभी को अपने स्वयं के दृष्टिकोण और तकनीकों का प्रयास करने के लिए प्रोत्साहित किया जाता है।
[३०] मेंः
#Note that the VI needs to be delayed by one to use
df['CI'] = -1.5*df['VI'].shift()+0.7*(0.7*df['I']+0.2*df['I_2']+0.1*df['I_3'])**3
[31] मेंः
df['adjust_mid_price_11'] = df['mid_price'] + df['spread']*(df['CI'])
print('The error of the adjusted mid_price_11:', ((df['price']-df['adjust_mid_price_11'])**2).sum())
बाहर[1]:
समायोजित मध्य_मूल्य_11 की त्रुटिः 0.0043001941412563575
सारांश
यह लेख मध्य मूल्य की गणना विधि को और बेहतर बनाने के लिए गहराई के डेटा और लेनदेन डेटा को जोड़ती है। यह सटीकता को मापने और मूल्य परिवर्तन भविष्यवाणी की सटीकता में सुधार करने के लिए एक विधि प्रदान करती है। कुल मिलाकर, पैरामीटर कठोर नहीं हैं और केवल संदर्भ के लिए हैं। अधिक सटीक मध्य मूल्य के साथ, अगला कदम व्यावहारिक अनुप्रयोगों में मध्य मूल्य का उपयोग करके बैकटेस्टिंग करना है। सामग्री का यह हिस्सा व्यापक है, इसलिए अपडेट को कुछ समय के लिए रोक दिया जाएगा।
- बिटकॉइन विकल्पों के लिए डेल्टा हेजिंग स्माइल कर्व के साथ
- उच्च आवृत्ति व्यापार रणनीतियों पर विचार (4)
- उच्च आवृत्ति ट्रेडिंग रणनीतियों के बारे में सोचें (5)
- उच्च आवृत्ति ट्रेडिंग रणनीतियों के बारे में सोचना (4)
- उच्च आवृत्ति व्यापार रणनीतियों पर विचार (3)
- उच्च आवृत्ति ट्रेडिंग रणनीतियों के बारे में सोचना (3)
- उच्च आवृत्ति व्यापार रणनीतियों पर विचार (2)
- उच्च आवृत्ति ट्रेडिंग रणनीतियों के बारे में सोचना (2)
- उच्च आवृत्ति व्यापार रणनीतियों पर विचार (1)
- उच्च आवृत्ति ट्रेडिंग रणनीतियों के बारे में सोचना)))
- Futu Securities Configuration विवरण दस्तावेज