डिजिटल मुद्रा कारक मॉडल
लेखक:लिडिया, बनाया गयाः 2022-10-24 17:37:50, अद्यतन किया गयाः 2023-09-15 20:59:38
कारक मॉडल ढांचा
शेयर बाजार के बहु-कारक मॉडल पर शोध रिपोर्ट प्रचुर मात्रा में हैं, जिसमें समृद्ध सिद्धांत और अभ्यास हैं। डिजिटल मुद्रा बाजार में मुद्राओं की संख्या, कुल बाजार मूल्य, व्यापार की मात्रा, डेरिवेटिव बाजार आदि की परवाह किए बिना, कारक अनुसंधान करना पर्याप्त है। यह पेपर मुख्य रूप से मात्रात्मक रणनीतियों के शुरुआती लोगों के लिए है, और इसमें जटिल गणितीय सिद्धांत और सांख्यिकीय विश्लेषण शामिल नहीं होगा। यह कारक अनुसंधान के लिए एक सरल ढांचा बनाने के लिए डेटा स्रोत के रूप में बाइनेंस स्थायी भविष्य बाजार का उपयोग करेगा, जो कारक संकेतकों का मूल्यांकन करने के लिए सुविधाजनक है।
कारक को एक संकेतक के रूप में माना जा सकता है और एक अभिव्यक्ति लिखी जा सकती है। कारक लगातार बदलता है, भविष्य की आय की जानकारी को दर्शाता है। आम तौर पर, कारक एक निवेश तर्क का प्रतिनिधित्व करता है।
उदाहरण के लिए, समापन मूल्य कारक के पीछे की धारणा यह है कि स्टॉक की कीमत भविष्य की कमाई की भविष्यवाणी कर सकती है, और स्टॉक की कीमत जितनी अधिक होगी, भविष्य की कमाई उतनी ही अधिक होगी (या कम हो सकती है) । वास्तव में, इस कारक के आधार पर एक पोर्टफोलियो का निर्माण नियमित दौर में उच्च मूल्य वाले शेयरों को खरीदने के लिए एक निवेश मॉडल / रणनीति है। आम तौर पर, उन कारकों को जो लगातार अतिरिक्त लाभ उत्पन्न कर सकते हैं, उन्हें अल्फा भी कहा जाता है। उदाहरण के लिए, बाजार मूल्य कारक और गति कारक को अकादमिक और निवेश समुदाय द्वारा एक बार प्रभावी कारकों के रूप में सत्यापित किया गया है।
शेयर बाजार और डिजिटल मुद्रा बाजार दोनों जटिल प्रणाली हैं। कोई भी कारक नहीं है जो भविष्य के मुनाफे की पूरी तरह से भविष्यवाणी कर सके, लेकिन उनके पास अभी भी एक निश्चित पूर्वानुमान है। प्रभावी अल्फा (निवेश मोड) धीरे-धीरे अधिक पूंजी इनपुट के साथ अमान्य हो जाएगा। हालांकि, यह प्रक्रिया बाजार में अन्य मॉडल का उत्पादन करेगी, जिससे एक नया अल्फा पैदा होगा। बाजार मूल्य कारक ए-शेयर बाजार में एक बहुत ही प्रभावी रणनीति थी। बस सबसे कम बाजार मूल्य के साथ 10 शेयर खरीदें, और उन्हें एक दिन में एक बार समायोजित करें। 2007 के बाद से, 10 साल का बैकटेस्ट लाभ का 400 गुना से अधिक उत्पन्न करेगा, जो समग्र बाजार से बहुत अधिक है। हालांकि, 2017 में व्हाइट हॉर्स स्टॉक मार्केट ने छोटे बाजार मूल्य कारक की विफलता को दर्शाया, और मूल्य कारक लोकप्रिय हो गया। इसलिए, हमें लगातार संतुलन बनाने और अल्फा का उपयोग करने की आवश्यकता है।
खोजे गए कारक रणनीतियों की स्थापना का आधार हैं। कई असंबंधित प्रभावी कारकों को जोड़कर एक बेहतर रणनीति का निर्माण किया जा सकता है।
import requests
from datetime import date,datetime
import time
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import requests, zipfile, io
%matplotlib inline
डेटा संसाधन
अब तक, 2022 की शुरुआत से अब तक बिनेंस यूएसडीटी के प्रति घंटा-के लाइन डेटा 150 मुद्राओं से अधिक हो गए हैं। जैसा कि हमने पहले उल्लेख किया है, कारक मॉडल एक मुद्रा चयन मॉडल है, जो एक निश्चित मुद्रा के बजाय सभी मुद्राओं के लिए उन्मुख है। के-लाइन डेटा में उच्च और बंद कम कीमतें, व्यापारिक मात्रा, लेनदेन की संख्या, टेकर खरीद मात्रा और अन्य डेटा शामिल हैं। ये डेटा निश्चित रूप से सभी कारकों का स्रोत नहीं हैं, जैसे कि अमेरिकी स्टॉक सूचकांक, ब्याज दर में वृद्धि की उम्मीद, लाभप्रदता, श्रृंखला पर डेटा, सोशल मीडिया लोकप्रियता आदि। असामान्य डेटा स्रोत भी प्रभावी अल्फा पा सकते हैं, लेकिन मूल मूल्य मात्रा भी पर्याप्त है।
## Current trading pair
Info = requests.get('https://fapi.binance.com/fapi/v1/exchangeInfo')
symbols = [s['symbol'] for s in Info.json()['symbols']]
symbols = list(filter(lambda x: x[-4:] == 'USDT', [s.split('_')[0] for s in symbols]))
print(symbols)
बाहरः
['BTCUSDT', 'ETHUSDT', 'BCHUSDT', 'XRPUSDT', 'EOSUSDT', 'LTCUSDT', 'TRXUSDT', 'ETCUSDT', 'LINKUSDT',
'XLMUSDT', 'ADAUSDT', 'XMRUSDT', 'DASHUSDT', 'ZECUSDT', 'XTZUSDT', 'BNBUSDT', 'ATOMUSDT', 'ONTUSDT',
'IOTAUSDT', 'BATUSDT', 'VETUSDT', 'NEOUSDT', 'QTUMUSDT', 'IOSTUSDT', 'THETAUSDT', 'ALGOUSDT', 'ZILUSDT',
'KNCUSDT', 'ZRXUSDT', 'COMPUSDT', 'OMGUSDT', 'DOGEUSDT', 'SXPUSDT', 'KAVAUSDT', 'BANDUSDT', 'RLCUSDT',
'WAVESUSDT', 'MKRUSDT', 'SNXUSDT', 'DOTUSDT', 'DEFIUSDT', 'YFIUSDT', 'BALUSDT', 'CRVUSDT', 'TRBUSDT',
'RUNEUSDT', 'SUSHIUSDT', 'SRMUSDT', 'EGLDUSDT', 'SOLUSDT', 'ICXUSDT', 'STORJUSDT', 'BLZUSDT', 'UNIUSDT',
'AVAXUSDT', 'FTMUSDT', 'HNTUSDT', 'ENJUSDT', 'FLMUSDT', 'TOMOUSDT', 'RENUSDT', 'KSMUSDT', 'NEARUSDT',
'AAVEUSDT', 'FILUSDT', 'RSRUSDT', 'LRCUSDT', 'MATICUSDT', 'OCEANUSDT', 'CVCUSDT', 'BELUSDT', 'CTKUSDT',
'AXSUSDT', 'ALPHAUSDT', 'ZENUSDT', 'SKLUSDT', 'GRTUSDT', '1INCHUSDT', 'CHZUSDT', 'SANDUSDT', 'ANKRUSDT',
'BTSUSDT', 'LITUSDT', 'UNFIUSDT', 'REEFUSDT', 'RVNUSDT', 'SFPUSDT', 'XEMUSDT', 'BTCSTUSDT', 'COTIUSDT',
'CHRUSDT', 'MANAUSDT', 'ALICEUSDT', 'HBARUSDT', 'ONEUSDT', 'LINAUSDT', 'STMXUSDT', 'DENTUSDT', 'CELRUSDT',
'HOTUSDT', 'MTLUSDT', 'OGNUSDT', 'NKNUSDT', 'SCUSDT', 'DGBUSDT', '1000SHIBUSDT', 'ICPUSDT', 'BAKEUSDT',
'GTCUSDT', 'BTCDOMUSDT', 'TLMUSDT', 'IOTXUSDT', 'AUDIOUSDT', 'RAYUSDT', 'C98USDT', 'MASKUSDT', 'ATAUSDT',
'DYDXUSDT', '1000XECUSDT', 'GALAUSDT', 'CELOUSDT', 'ARUSDT', 'KLAYUSDT', 'ARPAUSDT', 'CTSIUSDT', 'LPTUSDT',
'ENSUSDT', 'PEOPLEUSDT', 'ANTUSDT', 'ROSEUSDT', 'DUSKUSDT', 'FLOWUSDT', 'IMXUSDT', 'API3USDT', 'GMTUSDT',
'APEUSDT', 'BNXUSDT', 'WOOUSDT', 'FTTUSDT', 'JASMYUSDT', 'DARUSDT', 'GALUSDT', 'OPUSDT', 'BTCUSDT',
'ETHUSDT', 'INJUSDT', 'STGUSDT', 'FOOTBALLUSDT', 'SPELLUSDT', '1000LUNCUSDT', 'LUNA2USDT', 'LDOUSDT',
'CVXUSDT']
print(len(symbols))
बाहरः
153
#Function to obtain any period of K-line
def GetKlines(symbol='BTCUSDT',start='2020-8-10',end='2021-8-10',period='1h',base='fapi',v = 'v1'):
Klines = []
start_time = int(time.mktime(datetime.strptime(start, "%Y-%m-%d").timetuple()))*1000 + 8*60*60*1000
end_time = min(int(time.mktime(datetime.strptime(end, "%Y-%m-%d").timetuple()))*1000 + 8*60*60*1000,time.time()*1000)
intervel_map = {'m':60*1000,'h':60*60*1000,'d':24*60*60*1000}
while start_time < end_time:
mid_time = start_time+1000*int(period[:-1])*intervel_map[period[-1]]
url = 'https://'+base+'.binance.com/'+base+'/'+v+'/klines?symbol=%s&interval=%s&startTime=%s&endTime=%s&limit=1000'%(symbol,period,start_time,mid_time)
res = requests.get(url)
res_list = res.json()
if type(res_list) == list and len(res_list) > 0:
start_time = res_list[-1][0]+int(period[:-1])*intervel_map[period[-1]]
Klines += res_list
if type(res_list) == list and len(res_list) == 0:
start_time = start_time+1000*int(period[:-1])*intervel_map[period[-1]]
if mid_time >= end_time:
break
df = pd.DataFrame(Klines,columns=['time','open','high','low','close','amount','end_time','volume','count','buy_amount','buy_volume','null']).astype('float')
df.index = pd.to_datetime(df.time,unit='ms')
return df
start_date = '2022-1-1'
end_date = '2022-09-14'
period = '1h'
df_dict = {}
for symbol in symbols:
df_s = GetKlines(symbol=symbol,start=start_date,end=end_date,period=period,base='fapi',v='v1')
if not df_s.empty:
df_dict[symbol] = df_s
symbols = list(df_dict.keys())
print(df_s.columns)
बाहरः
Index(['time', 'open', 'high', 'low', 'close', 'amount', 'end_time', 'volume',
'count', 'buy_amount', 'buy_volume', 'null'],
dtype='object')
जिन आंकड़ों में हम रुचि रखते हैं: समापन मूल्य, उद्घाटन मूल्य, व्यापारिक मात्रा, लेनदेन की संख्या और टेकर खरीद अनुपात सबसे पहले के-लाइन डेटा से निकाले जाते हैं। इन आंकड़ों के आधार पर, आवश्यक कारकों को संसाधित किया जाता है।
df_close = pd.DataFrame(index=pd.date_range(start=start_date, end=end_date, freq=period),columns=df_dict.keys())
df_open = pd.DataFrame(index=pd.date_range(start=start_date, end=end_date, freq=period),columns=df_dict.keys())
df_volume = pd.DataFrame(index=pd.date_range(start=start_date, end=end_date, freq=period),columns=df_dict.keys())
df_buy_ratio = pd.DataFrame(index=pd.date_range(start=start_date, end=end_date, freq=period),columns=df_dict.keys())
df_count = pd.DataFrame(index=pd.date_range(start=start_date, end=end_date, freq=period),columns=df_dict.keys())
for symbol in df_dict.keys():
df_s = df_dict[symbol]
df_close[symbol] = df_s.close
df_open[symbol] = df_s.open
df_volume[symbol] = df_s.volume
df_count[symbol] = df_s['count']
df_buy_ratio[symbol] = df_s.buy_amount/df_s.amount
df_close = df_close.dropna(how='all')
df_open = df_open.dropna(how='all')
df_volume = df_volume.dropna(how='all')
df_count = df_count.dropna(how='all')
df_buy_ratio = df_buy_ratio.dropna(how='all')
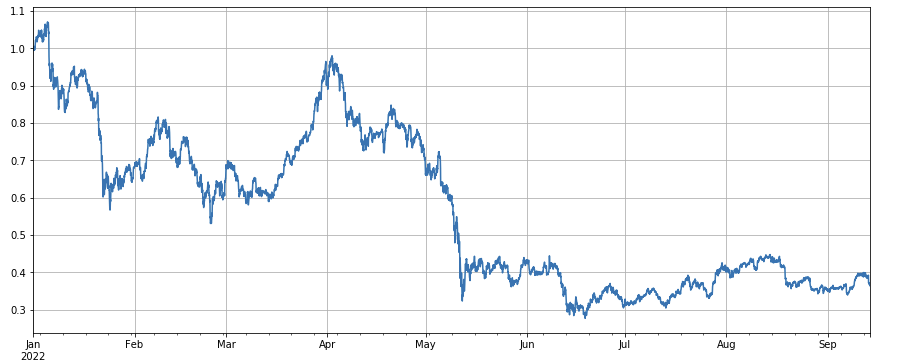
बाजार सूचकांक का समग्र प्रदर्शन निराशाजनक है, जो वर्ष की शुरुआत से हाल के दिनों में 60% गिर गया है।
df_norm = df_close/df_close.fillna(method='bfill').iloc[0] #normalization
df_norm.mean(axis=1).plot(figsize=(15,6),grid=True);
#Final index profit chart
कारक वैधता निर्णय
-
प्रतिगमन पद्धति निम्नलिखित अवधि का उपज आश्रित चर है, और परीक्षण करने के लिए कारक स्वतंत्र चर है। प्रतिगमन द्वारा प्राप्त गुणांक कारक का उपज भी है। प्रतिगमन समीकरण के निर्माण के बाद, घटकों की वैधता और अस्थिरता को आम तौर पर गुणांक t मूल्य के पूर्ण औसत मूल्य, गुणांक t मूल्य के पूर्ण मूल्य अनुक्रम का अनुपात 2 से अधिक, वार्षिक कारक रिटर्न, वार्षिक कारक लाभ अस्थिरता और कारक लाभ का शार्प अनुपात के संदर्भ में देखा जाता है। एक बार में कई कारकों को प्रतिगमन किया जा सकता है। विवरण के लिए कृपया बार दस्तावेज़ देखें।
-
आईसी, आईआर और अन्य संकेत तथाकथित आईसी कारक और अगली अवधि की वापसी दर के बीच सहसंबंध गुणांक है। अब, RANK_ IC का उपयोग आम तौर पर भी किया जाता है, यह कारक रैंकिंग और अगली स्टॉक वापसी दर के बीच सहसंबंध गुणांक है। आईआर आम तौर पर आईसी अनुक्रम का औसत मूल्य / आईसी अनुक्रम का मानक विचलन है।
-
स्तरीकृत प्रतिगमन पद्धति इस पेपर में, हम इस विधि का उपयोग करेंगे, जो कि परीक्षण किए जाने वाले कारकों के अनुसार मुद्राओं को सॉर्ट करना है, उन्हें समूह बैकटेस्टिंग के लिए एन समूहों में विभाजित करना है, और स्थिति समायोजन के लिए एक निश्चित अवधि का उपयोग करना है। यदि स्थिति आदर्श है, तो समूह एन मुद्राओं की रिटर्न दर एक अच्छी एकरसता दिखाएगी, एकरसता से बढ़ रही है या घट रही है, और प्रत्येक समूह का आय अंतर बड़ा है। ऐसे कारक अच्छे भेदभाव में परिलक्षित होते हैं। यदि पहले समूह में सबसे अधिक लाभ है और अंतिम समूह में सबसे कम लाभ है, तो अंतिम उपज प्राप्त करने के लिए पहले समूह में लंबा और अंतिम समूह में छोटा जाएं, जो शार्प अनुपात का संदर्भ संकेतक है।
वास्तविक बैकटेस्ट ऑपरेशन
चयनित सिक्कों को घटकों की रैंकिंग के आधार पर 3 समूहों में विभाजित किया जाता है, सबसे छोटे से सबसे बड़े तक। मुद्राओं के प्रत्येक समूह में कुल का लगभग 1/3 हिस्सा होता है। यदि एक कारक प्रभावी है, तो प्रत्येक समूह में अंक की संख्या जितनी कम होगी, रिटर्न दर उतनी ही अधिक होगी, लेकिन इसका मतलब यह भी है कि प्रत्येक मुद्रा में अपेक्षाकृत अधिक धन आवंटित किया जाएगा। यदि लंबी और छोटी स्थिति क्रमशः डबल लीवरेज हैं, और पहला समूह और अंतिम समूह क्रमशः 10 मुद्राएं हैं, तो एक मुद्रा कुल का 10% है। यदि एक मुद्रा को शॉर्ट किया जाता है, तो 20% वापस ले लिया जाता है; यदि समूहों की संख्या 50 है, तो 4% वापस ले लिया जाएगा। विविधतापूर्ण मुद्राएं ब्लैक स्वान के जोखिम को कम कर सकती हैं। पहले समूह (न्यूनतम मूल्य कारक) को लंबा करें, तीसरे समूह में जाएं। कारक जितना बड़ा होगा, और आय जितनी अधिक होगी, आप बस कारक को रिवर्स कर सकते हैं और लंबी स्थिति को कम या नकारात्मक या विपरीत आय में बदल सकते हैं।
आम तौर पर, कारक भविष्यवाणी क्षमता का आकलन अंतिम बैकटेस्ट की रिटर्न दर और शार्प अनुपात के अनुसार किया जा सकता है। इसके अलावा, यह भी संदर्भित करने की आवश्यकता है कि क्या कारक अभिव्यक्ति सरल है, समूह के आकार के लिए संवेदनशील है, स्थिति समायोजन अंतराल के लिए संवेदनशील है, और बैकटेस्ट के प्रारंभिक समय के लिए संवेदनशील है।
स्थिति समायोजन की आवृत्ति के संबंध में, शेयर बाजार में आमतौर पर 5 दिन, 10 दिन और एक महीने की अवधि होती है। हालांकि, डिजिटल मुद्रा बाजार के लिए, ऐसी अवधि निस्संदेह बहुत लंबी है, और वास्तविक बॉट में बाजार की वास्तविक समय में निगरानी की जाती है। पदों को फिर से समायोजित करने के लिए एक विशिष्ट अवधि से चिपके रहने की आवश्यकता नहीं है। इसलिए, वास्तविक बॉट में, हम वास्तविक समय में या कम समय में पदों को समायोजित करते हैं।
ट्रेडिंग रणनीति के अनुसार, ट्रेडिंग की स्थिति को बंद करने के लिए, ट्रेडिंग की स्थिति को बंद करने के लिए, ट्रेडिंग की स्थिति को बंद करने के लिए, ट्रेडिंग की स्थिति को बंद करने के लिए, ट्रेडिंग की स्थिति को बंद करने के लिए, ट्रेडिंग की स्थिति को बंद करने के लिए, ट्रेडिंग की स्थिति को बंद करने के लिए, ट्रेडिंग की स्थिति को बंद करने के लिए, ट्रेडिंग की स्थिति को बंद करने के लिए, ट्रेडिंग की स्थिति को बंद करने के लिए, ट्रेडिंग की स्थिति को बंद करने के लिए, ट्रेडिंग की स्थिति को बंद करने के लिए, ट्रेडिंग की स्थिति को बंद करने के लिए, ट्रेडिंग की स्थिति को बंद करने के लिए, ट्रेडिंग की स्थिति को बंद करने के लिए, ट्रेडिंग की स्थिति को बंद करने के लिए, ट्रेडिंग की स्थिति को बंद करने के लिए, ट्रेडिंग की स्थिति को बंद करने के लिए, ट्रेडिंग की स्थिति को बंद करने के लिए, ट्रेडिंग की स्थिति को बंद करने के लिए, ट्रेडिंग की स्थिति को बंद करने के लिए, ट्रेडिंग की स्थिति को बंद करने के लिए, ट्रेडिंग की स्थिति को बंद करने के लिए, ट्रेडिंग की स्थिति को बंद करने के लिए, ट्रेडिंग की स्थिति को बंद करने के लिए
#Backtest engine
class Exchange:
def __init__(self, trade_symbols, fee=0.0004, initial_balance=10000):
self.initial_balance = initial_balance #Initial assets
self.fee = fee
self.trade_symbols = trade_symbols
self.account = {'USDT':{'realised_profit':0, 'unrealised_profit':0, 'total':initial_balance, 'fee':0, 'leverage':0, 'hold':0}}
for symbol in trade_symbols:
self.account[symbol] = {'amount':0, 'hold_price':0, 'value':0, 'price':0, 'realised_profit':0,'unrealised_profit':0,'fee':0}
def Trade(self, symbol, direction, price, amount):
cover_amount = 0 if direction*self.account[symbol]['amount'] >=0 else min(abs(self.account[symbol]['amount']), amount)
open_amount = amount - cover_amount
self.account['USDT']['realised_profit'] -= price*amount*self.fee #Net of fees
self.account['USDT']['fee'] += price*amount*self.fee
self.account[symbol]['fee'] += price*amount*self.fee
if cover_amount > 0: #Close position first
self.account['USDT']['realised_profit'] += -direction*(price - self.account[symbol]['hold_price'])*cover_amount #Profits
self.account[symbol]['realised_profit'] += -direction*(price - self.account[symbol]['hold_price'])*cover_amount
self.account[symbol]['amount'] -= -direction*cover_amount
self.account[symbol]['hold_price'] = 0 if self.account[symbol]['amount'] == 0 else self.account[symbol]['hold_price']
if open_amount > 0:
total_cost = self.account[symbol]['hold_price']*direction*self.account[symbol]['amount'] + price*open_amount
total_amount = direction*self.account[symbol]['amount']+open_amount
self.account[symbol]['hold_price'] = total_cost/total_amount
self.account[symbol]['amount'] += direction*open_amount
def Buy(self, symbol, price, amount):
self.Trade(symbol, 1, price, amount)
def Sell(self, symbol, price, amount):
self.Trade(symbol, -1, price, amount)
def Update(self, close_price): #Update assets
self.account['USDT']['unrealised_profit'] = 0
self.account['USDT']['hold'] = 0
for symbol in self.trade_symbols:
if not np.isnan(close_price[symbol]):
self.account[symbol]['unrealised_profit'] = (close_price[symbol] - self.account[symbol]['hold_price'])*self.account[symbol]['amount']
self.account[symbol]['price'] = close_price[symbol]
self.account[symbol]['value'] = abs(self.account[symbol]['amount'])*close_price[symbol]
self.account['USDT']['hold'] += self.account[symbol]['value']
self.account['USDT']['unrealised_profit'] += self.account[symbol]['unrealised_profit']
self.account['USDT']['total'] = round(self.account['USDT']['realised_profit'] + self.initial_balance + self.account['USDT']['unrealised_profit'],6)
self.account['USDT']['leverage'] = round(self.account['USDT']['hold']/self.account['USDT']['total'],3)
#Function of test factor
def Test(factor, symbols, period=1, N=40, value=300):
e = Exchange(symbols, fee=0.0002, initial_balance=10000)
res_list = []
index_list = []
factor = factor.dropna(how='all')
for idx, row in factor.iterrows():
if idx.hour % period == 0:
buy_symbols = row.sort_values().dropna()[0:N].index
sell_symbols = row.sort_values().dropna()[-N:].index
prices = df_close.loc[idx,]
index_list.append(idx)
for symbol in symbols:
if symbol in buy_symbols and e.account[symbol]['amount'] <= 0:
e.Buy(symbol,prices[symbol],value/prices[symbol]-e.account[symbol]['amount'])
if symbol in sell_symbols and e.account[symbol]['amount'] >= 0:
e.Sell(symbol,prices[symbol], value/prices[symbol]+e.account[symbol]['amount'])
e.Update(prices)
res_list.append([e.account['USDT']['total'],e.account['USDT']['hold']])
return pd.DataFrame(data=res_list, columns=['total','hold'],index = index_list)
सरल कारक परीक्षण
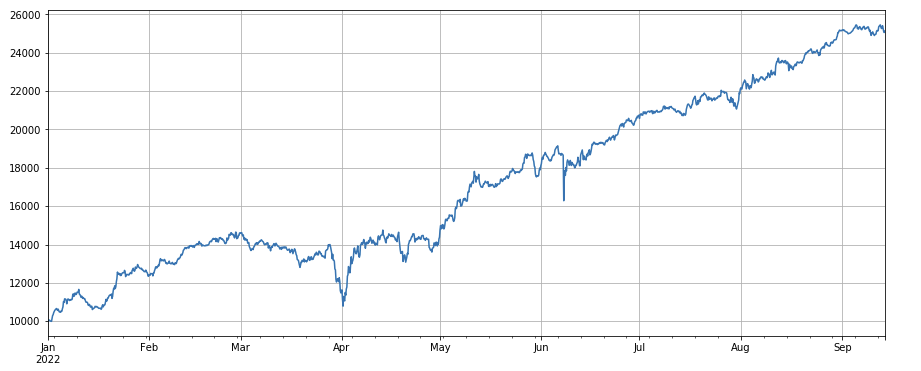
ट्रेडिंग वॉल्यूम फैक्टरः कम ट्रेडिंग वॉल्यूम वाली सरल लंबी मुद्राएं और उच्च ट्रेडिंग वॉल्यूम वाली छोटी मुद्राएं, जो बहुत अच्छा प्रदर्शन करती हैं, यह दर्शाता है कि लोकप्रिय मुद्राओं में गिरावट की प्रवृत्ति है।
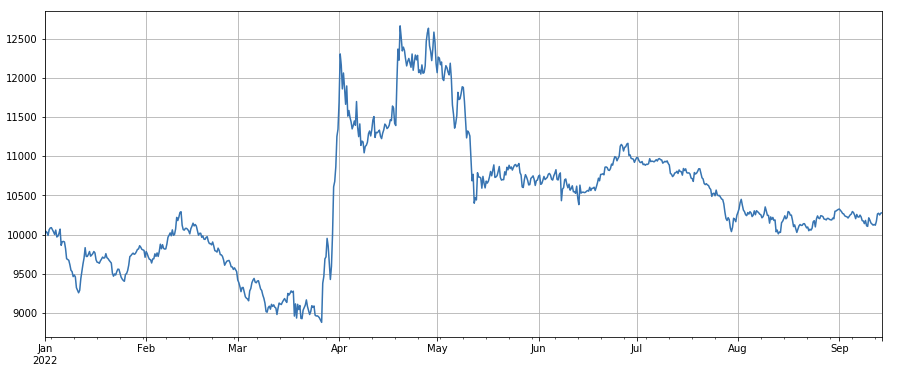
ट्रेडिंग प्राइस फैक्टरः कम कीमतों वाली लंबी मुद्राओं और उच्च कीमतों वाली छोटी मुद्राओं का प्रभाव दोनों सामान्य हैं।
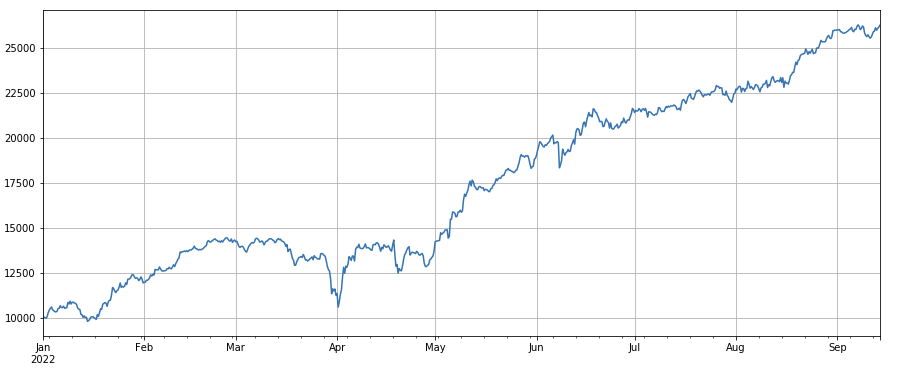
लेन-देन संख्या कारकः प्रदर्शन लेन-देन मात्रा के समान है। यह स्पष्ट है कि लेन-देन मात्रा कारक और लेन-देन संख्या कारक के बीच सहसंबंध बहुत अधिक है। वास्तव में, विभिन्न मुद्राओं में उनके बीच औसत सहसंबंध 0.97 तक पहुंच गया है, यह दर्शाता है कि दोनों कारक बहुत समान हैं। कई कारकों को संश्लेषित करते समय इस कारक को ध्यान में रखने की आवश्यकता है।
3h गति कारक: (df_close - df_close. shift (3)) /df_ close. shift(3). यानी, कारक का 3-घंटे का उदय। बैकटेस्ट परिणाम बताते हैं कि 3-घंटे के उदय में स्पष्ट प्रतिगमन विशेषताएं हैं, अर्थात, बाद में गिरना आसान है। समग्र प्रदर्शन ठीक है, लेकिन पीछे हटने और दोलन की एक लंबी अवधि भी है।
24 घंटों की गति कारकः 24 घंटों की स्थिति समायोजन अवधि का परिणाम अच्छा है, उपज 3 घंटों की गति के समान है, और वापस लेने की कम है।
लेन-देन की मात्रा का परिवर्तन कारकः df_ volume.rolling(24).mean() /df_ volume.rolling (96). mean(), यानी पिछले तीन दिनों में लेन-देन की मात्रा से पिछले दिन की लेन-देन की मात्रा का अनुपात। स्थिति को हर 8 घंटे में समायोजित किया जाता है। बैकटेस्टिंग के परिणाम अच्छे थे, और निकासी भी अपेक्षाकृत कम थी, जो इंगित करती है कि सक्रिय लेनदेन की मात्रा वाले अधिक घटने के इच्छुक थे।
लेन-देन संख्या का परिवर्तन कारकः df_ count.rolling(24.mean() /df_ count.rolling(96). mean (), अर्थात, पिछले दिन में लेनदेन संख्या का पिछले तीन दिनों में लेनदेन संख्या के अनुपात। स्थिति को हर 8 घंटे में समायोजित किया जाता है। बैकटेस्टिंग के परिणाम अच्छे थे, और निकासी भी अपेक्षाकृत कम है, जो इंगित करता है कि सक्रिय लेनदेन मात्रा वाले अधिक घटने के इच्छुक थे।
एकल लेनदेन मूल्य का परिवर्तन कारक: - ((df_volume.rolling(24).mean()/df_count.rolling(24.mean())/(df_volume.rolling(24.mean()/df_count.rolling(96.mean()) , अर्थात अंतिम दिन के लेन-देन मूल्य का पिछले तीन दिनों के लेन-देन मूल्य का अनुपात है, और स्थिति को हर 8 घंटे में समायोजित किया जाएगा। यह कारक लेन-देन मात्रा कारक के साथ भी अत्यधिक सहसंबद्ध है।
लेन-देन अनुपात द्वारा लेने वाले का परिवर्तन कारकः df_buy_ratio.rolling(24).mean() /df_buy_ratio.rolling(96).mean(), यानी, अंतिम दिन में कुल लेनदेन मात्रा के लिए लेन-देन मूल्य के लिए लेन-देन के अनुपात में लेने वाले का अनुपात, और स्थिति को हर 8 घंटे में समायोजित किया जाएगा। यह कारक काफी अच्छा प्रदर्शन करता है और इसका लेन-देन मात्रा कारक के साथ बहुत कम सहसंबंध है।
अस्थिरता कारकः (df_close/df_open).rolling(24).std(), कम अस्थिरता के साथ लंबी मुद्राओं पर जाएं, इसका एक निश्चित प्रभाव पड़ता है।
लेनदेन की मात्रा और समापन मूल्य के बीच सहसंबंध कारक: df_close.rolling(96).corr(df_volume), पिछले चार दिनों में समापन मूल्य में लेनदेन की मात्रा का सहसंबंध कारक है, जिसने समग्र रूप से अच्छा प्रदर्शन किया है।
यहाँ सूचीबद्ध कारक मूल्य मात्रा पर आधारित हैं। वास्तव में कारक सूत्रों का संयोजन स्पष्ट तर्क के बिना बहुत जटिल हो सकता है। आप प्रसिद्ध ALPHA101 कारक निर्माण विधि का संदर्भ ले सकते हैंःhttps://github.com/STHSF/alpha101.
#transaction volume
factor_volume = df_volume
factor_volume_res = Test(factor_volume, symbols, period=4)
factor_volume_res.total.plot(figsize=(15,6),grid=True);
#transaction price
factor_close = df_close
factor_close_res = Test(factor_close, symbols, period=8)
factor_close_res.total.plot(figsize=(15,6),grid=True);
#transaction count
factor_count = df_count
factor_count_res = Test(factor_count, symbols, period=8)
factor_count_res.total.plot(figsize=(15,6),grid=True);
print(df_count.corrwith(df_volume).mean())
0.9671246744996017
#3h momentum factor
factor_1 = (df_close - df_close.shift(3))/df_close.shift(3)
factor_1_res = Test(factor_1,symbols,period=1)
factor_1_res.total.plot(figsize=(15,6),grid=True);
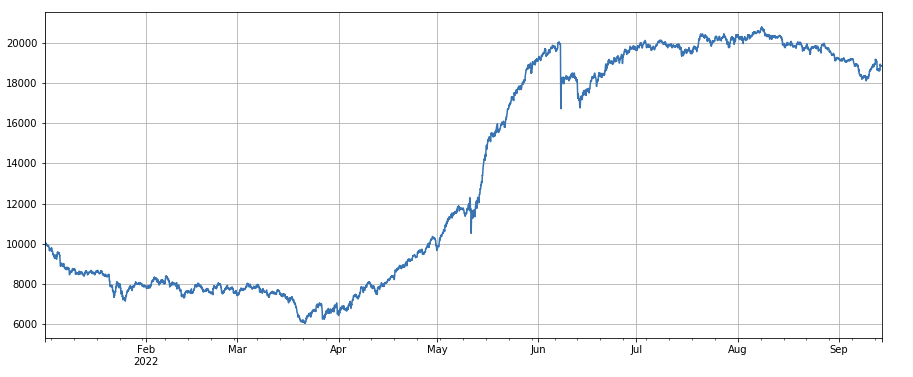
#24h momentum factor
factor_2 = (df_close - df_close.shift(24))/df_close.shift(24)
factor_2_res = Test(factor_2,symbols,period=24)
tamenxuanfactor_2_res.total.plot(figsize=(15,6),grid=True);
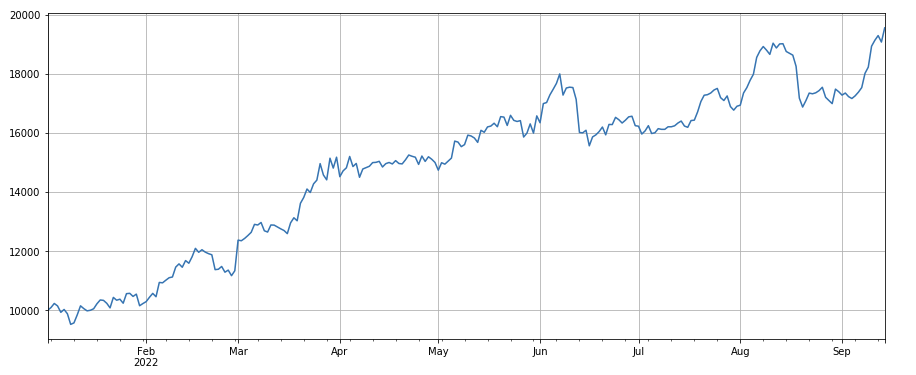
#factor of transaction volume
factor_3 = df_volume.rolling(24).mean()/df_volume.rolling(96).mean()
factor_3_res = Test(factor_3, symbols, period=8)
factor_3_res.total.plot(figsize=(15,6),grid=True);
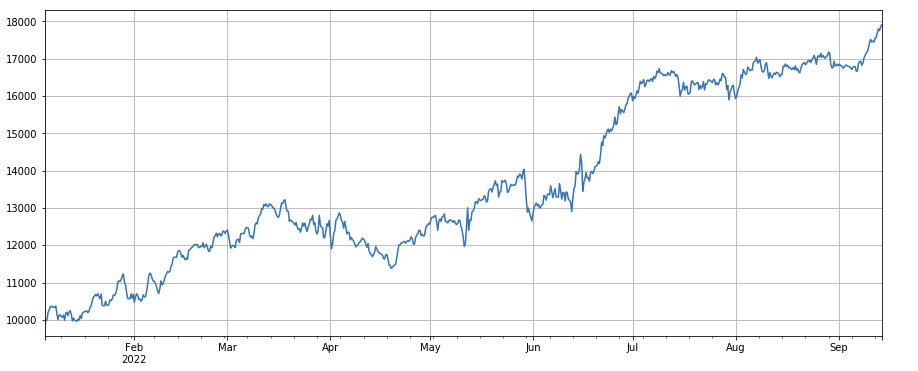
#factor of transaction number
factor_4 = df_count.rolling(24).mean()/df_count.rolling(96).mean()
factor_4_res = Test(factor_4, symbols, period=8)
factor_4_res.total.plot(figsize=(15,6),grid=True);
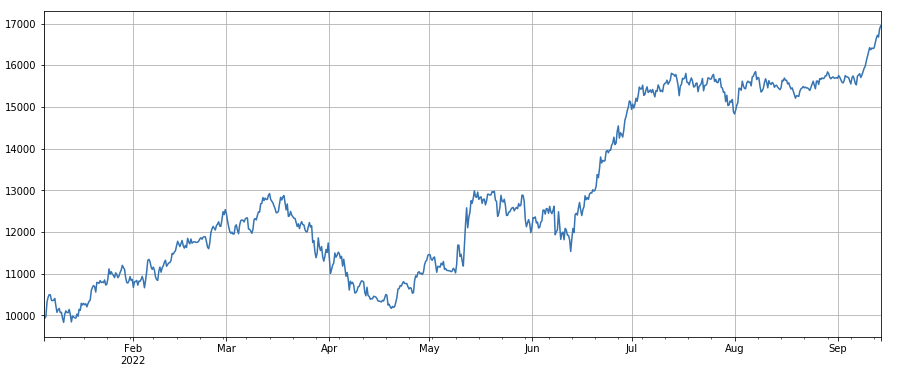
#factor correlation
print(factor_4.corrwith(factor_3).mean())
0.9707239580854841
#single transaction value factor
factor_5 = -(df_volume.rolling(24).mean()/df_count.rolling(24).mean())/(df_volume.rolling(24).mean()/df_count.rolling(96).mean())
factor_5_res = Test(factor_5, symbols, period=8)
factor_5_res.total.plot(figsize=(15,6),grid=True);
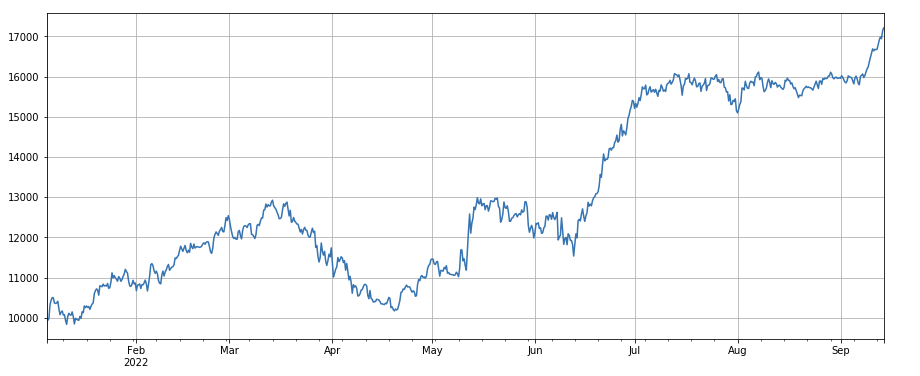
print(factor_4.corrwith(factor_5).mean())
0.861206620552479
#proportion factor of taker by transaction
factor_6 = df_buy_ratio.rolling(24).mean()/df_buy_ratio.rolling(96).mean()
factor_6_res = Test(factor_6, symbols, period=4)
factor_6_res.total.plot(figsize=(15,6),grid=True);
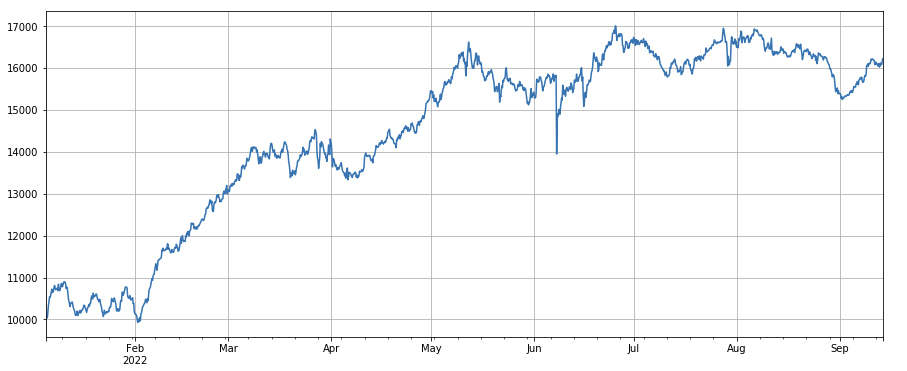
print(factor_3.corrwith(factor_6).mean())
0.1534572192503726
#volatility factor
factor_7 = (df_close/df_open).rolling(24).std()
factor_7_res = Test(factor_7, symbols, period=2)
factor_7_res.total.plot(figsize=(15,6),grid=True);
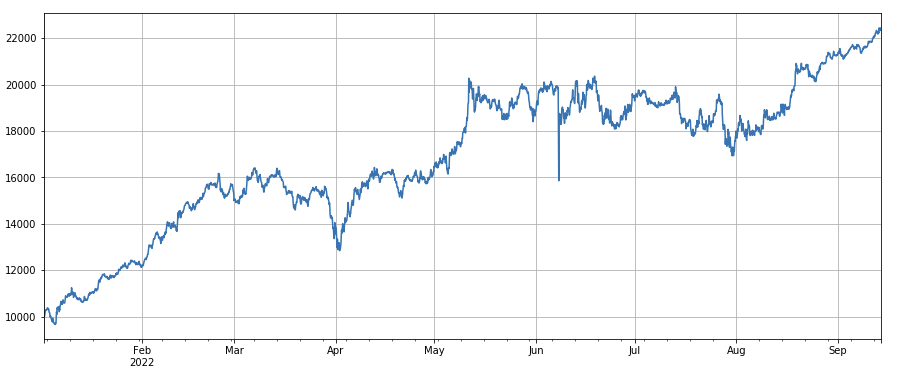
#correlation factor between transaction volume and closing price
factor_8 = df_close.rolling(96).corr(df_volume)
factor_8_res = Test(factor_8, symbols, period=4)
factor_8_res.total.plot(figsize=(15,6),grid=True);
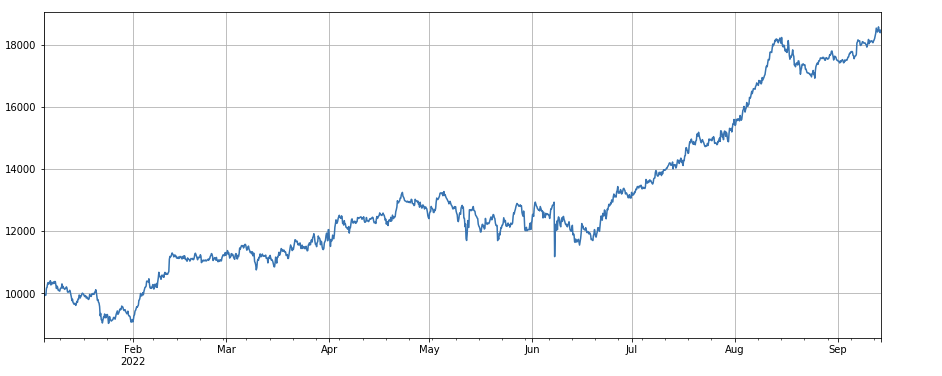
बहु कारक संश्लेषण
यह निश्चित रूप से रणनीति निर्माण प्रक्रिया का सबसे महत्वपूर्ण हिस्सा है कि लगातार नए प्रभावी कारकों की खोज की जाए, लेकिन एक अच्छी कारक संश्लेषण विधि के बिना, एक उत्कृष्ट एकल अल्फा कारक अपनी अधिकतम भूमिका नहीं निभा सकता है। आम बहु कारक संश्लेषण विधियों में शामिल हैंः
समान भार विधिः संश्लेषण के बाद नए कारकों को प्राप्त करने के लिए सभी कारकों को समान भारों के साथ जोड़ा जाता है।
ऐतिहासिक कारक प्रतिफल दर के भार पद्धतिः संश्लेषण के बाद एक नया कारक प्राप्त करने के लिए वजन के रूप में नवीनतम अवधि में ऐतिहासिक कारक प्रतिफल दर के अंकगणितीय औसत के अनुसार सभी कारकों को जोड़ा जाता है। इस पद्धति में अच्छी तरह से प्रदर्शन करने वाले कारकों का वजन अधिक होता है।
अधिकतम आईसी_आईआर भार पद्धति: इतिहास की एक अवधि में समग्र कारक के औसत आईसी मूल्य का उपयोग अगली अवधि में समग्र कारक के आईसी मूल्य के अनुमान के रूप में किया जाता है, और ऐतिहासिक आईसी मूल्य के सह-विभेदक मैट्रिक्स का उपयोग अगली अवधि में समग्र कारक की अस्थिरता के अनुमान के रूप में किया जाता है। आईसी_आईआर के अनुसार आईसी का अपेक्षित मूल्य आईसी के मानक विचलन से विभाजित है ताकि अधिकतम समग्र कारक आईसी_आईआर का इष्टतम वजन समाधान प्राप्त किया जा सके।
मुख्य घटक विश्लेषण (पीसीए): पीसीए डेटा आयाम में कमी के लिए एक आम विधि है, और कारकों के बीच सहसंबंध उच्च हो सकता है। आयाम में कमी के बाद मुख्य घटकों का उपयोग सिंथेटिक कारकों के रूप में किया जाता है।
इस पेपर में कारक वैधता असाइनमेंट को मैन्युअल रूप से संदर्भित किया जाएगा। ऊपर वर्णित विधियों का उल्लेख किया जा सकता हैःae933a8c-5a94-4d92-8f33-d92b70c36119.pdf
एकल कारकों का परीक्षण करते समय, क्रमबद्ध करना तय है, लेकिन बहु कारक संश्लेषण को पूरी तरह से अलग-अलग डेटा को जोड़ने की आवश्यकता है, इसलिए सभी कारकों को मानकीकृत करने की आवश्यकता है, और चरम मूल्य और लापता मूल्य को सामान्य रूप से हटाने की आवश्यकता है। यहाँ हम संश्लेषण के लिए df_ volume\factor_ 1\factor_ 7\factor_ 6\factor_ 8 का उपयोग करते हैं।
#standardize functions, remove missing values and extreme values, and standardize
def norm_factor(factor):
factor = factor.dropna(how='all')
factor_clip = factor.apply(lambda x:x.clip(x.quantile(0.2), x.quantile(0.8)),axis=1)
factor_norm = factor_clip.add(-factor_clip.mean(axis=1),axis ='index').div(factor_clip.std(axis=1),axis ='index')
return factor_norm
df_volume_norm = norm_factor(df_volume)
factor_1_norm = norm_factor(factor_1)
factor_6_norm = norm_factor(factor_6)
factor_7_norm = norm_factor(factor_7)
factor_8_norm = norm_factor(factor_8)
factor_total = 0.6*df_volume_norm + 0.4*factor_1_norm + 0.2*factor_6_norm + 0.3*factor_7_norm + 0.4*factor_8_norm
factor_total_res = Test(factor_total, symbols, period=8)
factor_total_res.total.plot(figsize=(15,6),grid=True);
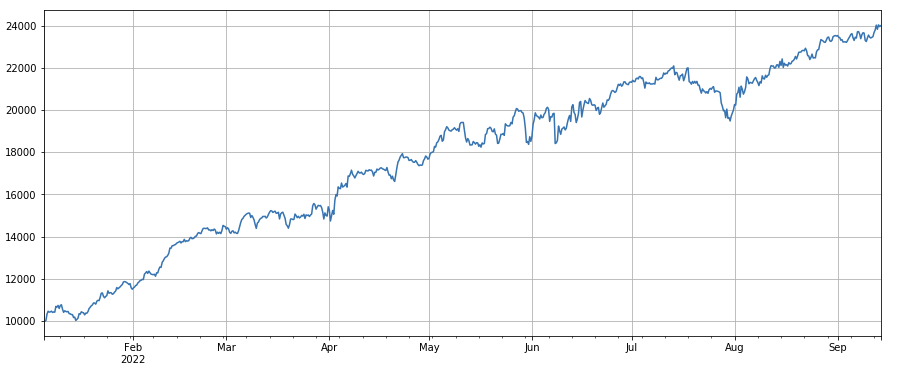
सारांश
यह पेपर एकल कारक के परीक्षण विधि का परिचय देता है और सामान्य एकल कारकों का परीक्षण करता है, और शुरू में बहु कारक संश्लेषण की विधि का परिचय देता है। हालांकि, बहु कारक के कई शोध सामग्री हैं। पेपर में उल्लिखित प्रत्येक बिंदु को आगे विकसित किया जा सकता है। यह विभिन्न रणनीतियों पर शोध को अल्फा कारक की खोज में बदलने का एक व्यवहार्य तरीका है। कारक पद्धति का उपयोग व्यापारिक विचारों के सत्यापन को बहुत तेज कर सकता है, और संदर्भ के लिए कई सामग्री हैं।
असली बॉट सेःhttps://www.fmz.com/robot/486605
- क्रिप्टोक्यूरेंसी बाजार में मौलिक विश्लेषण की मात्राः डेटा को खुद के लिए बोलने दें!
- मौद्रिक सर्कल के मूलभूत मात्रात्मक अनुसंधान - अब हर तरह के जादूगरों पर भरोसा न करें, डेटा निष्पक्ष रूप से बोलते हैं!
- क्वांटिफाइड ट्रेडिंग के लिए आवश्यक उपकरण - आविष्कारक क्वांटिफाइड डेटा एक्सप्लोरर मॉड्यूल
- सब कुछ में महारत हासिल करना - एफएमजेड ट्रेडिंग टर्मिनल का नया संस्करण (टीआरबी आर्बिट्रेज स्रोत कोड के साथ)
- सब कुछ जानने के लिए FMZ के नए संस्करण के लिए ट्रेडिंग टर्मिनल का परिचय (अनुदानित TRB सूट स्रोत कोड)
- एफएमजेड क्वांटः क्रिप्टोकरेंसी बाजार में सामान्य आवश्यकताओं के डिजाइन उदाहरणों का विश्लेषण (II)
- 80 पंक्तियों के कोड में उच्च आवृत्ति रणनीति के साथ मस्तिष्क रहित बिक्री बॉट्स का शोषण कैसे करें
- एफएमजेड क्वांटिकेशनः क्रिप्टोक्यूरेंसी बाजार में आम जरूरतों के डिजाइन उदाहरण का विश्लेषण
- 80 लाइनों के कोड के साथ उच्च आवृत्ति रणनीतियों का उपयोग करके बेचने के लिए मस्तिष्क रहित रोबोट का शोषण कैसे करें
- एफएमजेड क्वांटः क्रिप्टोकरेंसी बाजार में सामान्य आवश्यकताओं के डिजाइन उदाहरणों का विश्लेषण (I)
- एफएमजेड क्वांटिकेशनः क्रिप्टोक्यूरेंसी बाजार में आम जरूरतों के डिजाइन उदाहरण का विश्लेषण (1)