ARMA-EGARCH मॉडल के आधार पर बिटकॉइन अस्थिरता का मॉडलिंग और विश्लेषण
लेखक:लिडिया, बनाया गयाः 2022-11-15 15:32:43, अद्यतन किया गयाः 2023-09-14 20:30:52ईडी, और प्रक्रिया को छोड़ दिया गया था।
सामान्य सामान्य वितरण का मिलान स्तर t वितरण जितना अच्छा नहीं है, जो यह भी दर्शाता है कि उपज वितरण में सामान्य वितरण की तुलना में मोटी पूंछ होती है। इसके बाद, मॉडलिंग प्रक्रिया में प्रवेश करें, लॉग_रिटर्न (रिटर्न की लघुगणकीय दर) के लिए एक एआरएमए-गार्च (1,1) मॉडल प्रतिगमन निष्पादित किया जाता है और निम्नानुसार अनुमान लगाया जाता हैः
[23] मेंः
am_GARCH = arch_model(training_garch, mean='AR', vol='GARCH',
p=1, q=1, lags=3, dist='ged')
res_GARCH = am_GARCH.fit(disp=False, options={'ftol': 1e-01})
res_GARCH.summary()
बाहर[23]: पुनरावृत्तिः 1, कार्य संख्याः 10, नकारात्मक LLF: -1917.4262154917305
एआर-गार्च मॉडल परिणाम
औसत मॉडल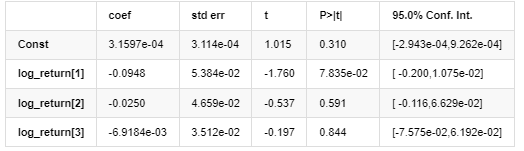
अस्थिरता मॉडल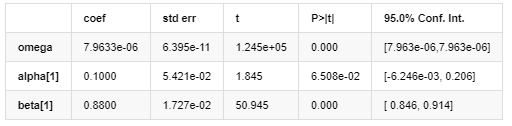
वितरण
सह-भिन्नता अनुमानकः मजबूत
ARCH डेटाबेस के अनुसार GARCH अस्थिरता समीकरण का वर्णनः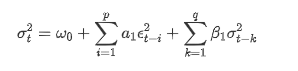
अस्थिरता के लिए सशर्त प्रतिगमन समीकरण को इस प्रकार प्राप्त किया जा सकता हैः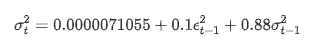
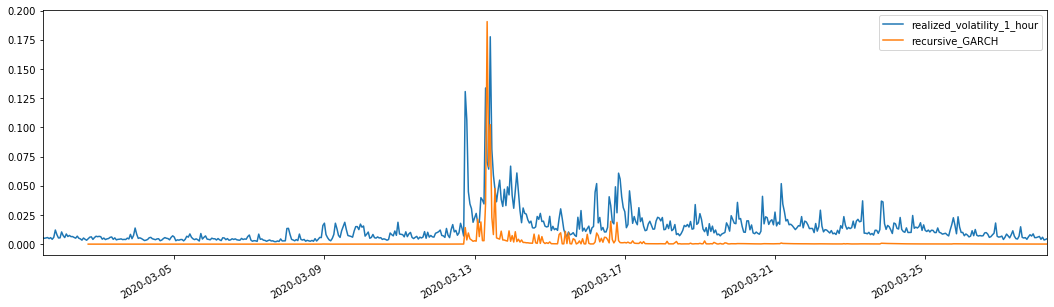
मिलान किए गए पूर्वानुमानित अस्थिरता के साथ संयुक्त, प्रभाव देखने के लिए नमूना की वास्तविक अस्थिरता के साथ इसकी तुलना करें।
[26] मेंः
def recursive_forecast(pd_dataframe):
window = predict_lag
model = 'GARCH'
index = kline_test[1:].index
end_loc = np.where(index >= kline_test.index[window])[0].min()
forecasts = {}
for i in range(len(kline_test[1:]) - window + 2):
mod = arch_model(pd_dataframe['log_return'][1:], mean='AR', vol=model, dist='ged',p=1, q=1)
res = mod.fit(last_obs=i+end_loc, disp='off', options={'ftol': 1e03})
temp = res.forecast().variance
fcast = temp.iloc[i + end_loc - 1]
forecasts[fcast.name] = fcast
forecasts = pd.DataFrame(forecasts).T
pd_dataframe['recursive_{}'.format(model)] = forecasts['h.1']
evaluate(pd_dataframe, 'realized_volatility_1_hour', 'recursive_{}'.format(model))
recursive_forecast(kline_test)
बाहर[26]: औसत पूर्ण त्रुटि (एमएई): 0.0128 औसत पूर्ण प्रतिशत त्रुटि (एमएपीई): 95.6 मूल औसत वर्ग त्रुटि (आरएमएसई): 0.018
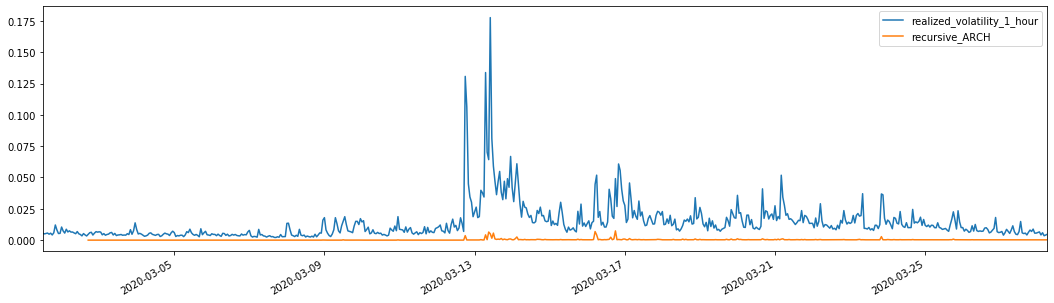
तुलना के लिए, निम्नानुसार एक आर्क बनाएंः
[27] मेंः
def recursive_forecast(pd_dataframe):
window = predict_lag
model = 'ARCH'
index = kline_test[1:].index
end_loc = np.where(index >= kline_test.index[window])[0].min()
forecasts = {}
for i in range(len(kline_test[1:]) - window + 2):
mod = arch_model(pd_dataframe['log_return'][1:], mean='AR', vol=model, dist='ged', p=1)
res = mod.fit(last_obs=i+end_loc, disp='off', options={'ftol': 1e03})
temp = res.forecast().variance
fcast = temp.iloc[i + end_loc - 1]
forecasts[fcast.name] = fcast
forecasts = pd.DataFrame(forecasts).T
pd_dataframe['recursive_{}'.format(model)] = forecasts['h.1']
evaluate(pd_dataframe, 'realized_volatility_1_hour', 'recursive_{}'.format(model))
recursive_forecast(kline_test)
बाहर[27]: औसत पूर्ण त्रुटि (MAE): 0.0136 औसत पूर्ण प्रतिशत त्रुटि (एमएपीई): 98.1 मूल औसत वर्ग त्रुटि (आरएमएसई): 0.02
7. EGARCH मॉडलिंग
अगला कदम EGARCH मॉडलिंग करना है
[24] मेंः
am_EGARCH = arch_model(training_egarch, mean='AR', vol='EGARCH',
p=1, lags=3, o=1,q=1, dist='ged')
res_EGARCH = am_EGARCH.fit(disp=False, options={'ftol': 1e-01})
res_EGARCH.summary()
बाहर[1]: पुनरावृत्तिः 1, कार्य संख्याः 11, नकारात्मक LLF: -1966.610328148909
एआर-ईजीएआरसीएच मॉडल परिणाम
औसत मॉडल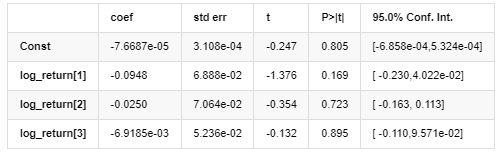
अस्थिरता मॉडल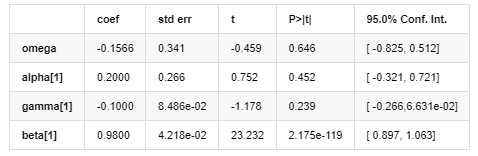
वितरण
सह-भिन्नता अनुमानकः मजबूत
एआरसीएच पुस्तकालय द्वारा प्रदान किए गए ईजीएआरसीएच अस्थिरता समीकरण का वर्णन इस प्रकार है: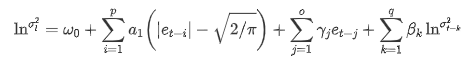
प्रतिस्थापन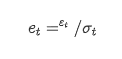
अस्थिरता का सशर्त प्रतिगमन समीकरण निम्नानुसार प्राप्त किया जा सकता है: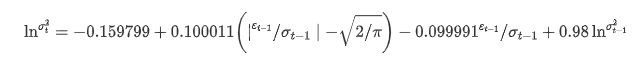
उनमें से, सममित पद γ का अनुमानित गुणांक विश्वास अंतराल से कम है, जो इंगित करता है कि बिटकॉइन रिटर्न दरों की अस्थिरता में एक महत्वपूर्ण
जोड़े गए पूर्वानुमानित अस्थिरता के साथ, परिणामों की तुलना नमूने की वास्तविक अस्थिरता के साथ की जाती हैः
[२८] मेंः
def recursive_forecast(pd_dataframe):
window = 280
model = 'EGARCH'
index = kline_test[1:].index
end_loc = np.where(index >= kline_test.index[window])[0].min()
forecasts = {}
for i in range(len(kline_test[1:]) - window + 2):
mod = arch_model(pd_dataframe['log_return'][1:], mean='AR', vol=model,
lags=3, p=2, o=0, q=1, dist='ged')
res = mod.fit(last_obs=i+end_loc, disp='off', options={'ftol': 1e03})
temp = res.forecast().variance
fcast = temp.iloc[i + end_loc - 1]
forecasts[fcast.name] = fcast
forecasts = pd.DataFrame(forecasts).T
pd_dataframe['recursive_{}'.format(model)] = forecasts['h.1']
evaluate(pd_dataframe, 'realized_volatility_1_hour', 'recursive_{}'.format(model))
pd_dataframe['recursive_{}'.format(model)]
recursive_forecast(kline_test)
बाहर[1]: औसत पूर्ण त्रुटि (एमएई): 0.0201 औसत पूर्ण प्रतिशत त्रुटि (एमएपीई): 122 मूल औसत वर्ग त्रुटि (आरएमएसई): 0.0279
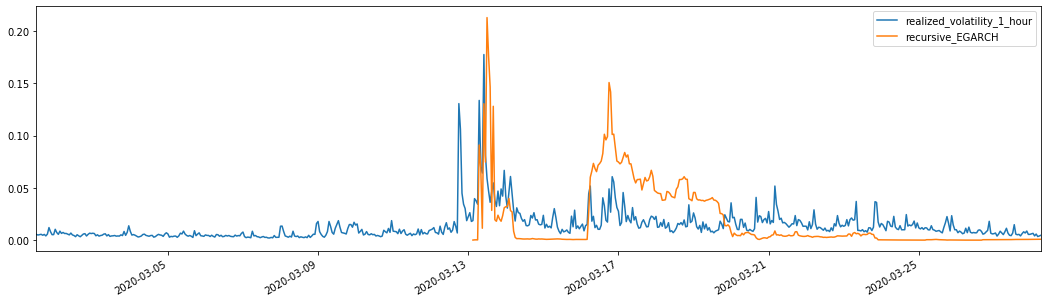
यह देखा जा सकता है कि ईजीएआरसीएच अस्थिरता के प्रति अधिक संवेदनशील है और एआरसीएच और गार्च की तुलना में अस्थिरता को बेहतर ढंग से मेल खाता है।
8. अस्थिरता पूर्वानुमान का मूल्यांकन
प्रति घंटा डेटा नमूना के आधार पर चुना जाता है, और अगला कदम एक घंटे आगे की भविष्यवाणी करना है। हम आरवी के साथ तीन मॉडल के पहले 10 घंटों के पूर्वानुमानित अस्थिरता का चयन करते हैं, बेंचमार्क अस्थिरता के रूप में। तुलनात्मक त्रुटि मान निम्नानुसार हैः
[29] मेंः
compare_ARCH_X = pd.DataFrame()
compare_ARCH_X['original']=kline_test['realized_volatility_1_hour']
compare_ARCH_X['arch']=kline_test['recursive_ARCH']
compare_ARCH_X['arch_diff']=compare_ARCH_X['original']-np.abs(compare_ARCH_X['arch'])
compare_ARCH_X['garch']=kline_test['recursive_GARCH']
compare_ARCH_X['garch_diff']=compare_ARCH_X['original']-np.abs(compare_ARCH_X['garch'])
compare_ARCH_X['egarch']=kline_test['recursive_EGARCH']
compare_ARCH_X['egarch_diff']=compare_ARCH_X['original']-np.abs(compare_ARCH_X['egarch'])
compare_ARCH_X = compare_ARCH_X[280:]
compare_ARCH_X.head(10)
बाहर[1]: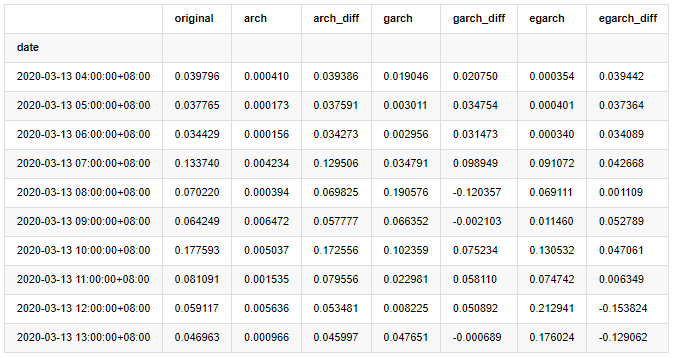
[३०] मेंः
compare_ARCH_X_diff = pd.DataFrame(index=['ARCH','GARCH','EGARCH'], columns=['head 1 step', 'head 10 steps', 'head 100 steps'])
compare_ARCH_X_diff['head 1 step']['ARCH'] = compare_ARCH_X['arch_diff']['2020-03-13 04:00:00+08:00']
compare_ARCH_X_diff['head 10 steps']['ARCH'] = np.mean(compare_ARCH_X['arch_diff'][:10])
compare_ARCH_X_diff['head 100 steps']['ARCH'] = np.mean(compare_ARCH_X['arch_diff'][:100])
compare_ARCH_X_diff['head 1 step']['GARCH'] = compare_ARCH_X['garch_diff']['2020-03-13 04:00:00+08:00']
compare_ARCH_X_diff['head 10 steps']['GARCH'] = np.mean(compare_ARCH_X['garch_diff'][:10])
compare_ARCH_X_diff['head 100 steps']['GARCH'] = np.mean(compare_ARCH_X['garch_diff'][:100])
compare_ARCH_X_diff['head 1 step']['EGARCH'] = compare_ARCH_X['egarch_diff']['2020-03-13 04:00:00+08:00']
compare_ARCH_X_diff['head 10 steps']['EGARCH'] = np.mean(compare_ARCH_X['egarch_diff'][:10])
compare_ARCH_X_diff['head 100 steps']['EGARCH'] = np.abs(np.mean(compare_ARCH_X['egarch_diff'][:100]))
compare_ARCH_X_diff
बाहर[30]: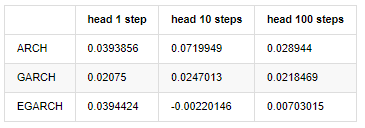
कई परीक्षण किए गए हैं, पहले घंटे के पूर्वानुमान परिणामों में, ईजीएआरसीएच की सबसे छोटी त्रुटि की संभावना अपेक्षाकृत बड़ी है, लेकिन समग्र अंतर विशेष रूप से स्पष्ट नहीं है; अल्पकालिक पूर्वानुमान प्रभावों में कुछ स्पष्ट अंतर हैं; ईजीएआरसीएच में दीर्घकालिक पूर्वानुमान में सबसे उत्कृष्ट भविष्यवाणी क्षमता है
[31] मेंः
compare_ARCH_X = pd.DataFrame()
compare_ARCH_X['Model'] = ['ARCH','GARCH','EGARCH']
compare_ARCH_X['RMSE'] = [get_rmse(kline_test['realized_volatility_1_hour'][280:320],kline_test['recursive_ARCH'][280:320]),
get_rmse(kline_test['realized_volatility_1_hour'][280:320],kline_test['recursive_GARCH'][280:320]),
get_rmse(kline_test['realized_volatility_1_hour'][280:320],kline_test['recursive_EGARCH'][280:320])]
compare_ARCH_X['MAPE'] = [get_mape(kline_test['realized_volatility_1_hour'][280:320],kline_test['recursive_ARCH'][280:320]),
get_mape(kline_test['realized_volatility_1_hour'][280:320],kline_test['recursive_GARCH'][280:320]),
get_mape(kline_test['realized_volatility_1_hour'][280:320],kline_test['recursive_EGARCH'][280:320])]
compare_ARCH_X['MASE'] = [get_mape(kline_test['realized_volatility_1_hour'][280:320],kline_test['recursive_ARCH'][280:320]),
get_mape(kline_test['realized_volatility_1_hour'][280:320],kline_test['recursive_GARCH'][280:320]),
get_mape(kline_test['realized_volatility_1_hour'][280:320],kline_test['recursive_EGARCH'][280:320])]
compare_ARCH_X
बाहर[1]: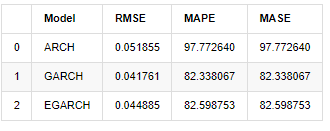
संकेतक के संदर्भ में, ARCH की तुलना में GARCH और EGARCH में कुछ सुधार है, लेकिन अंतर विशेष रूप से स्पष्ट नहीं है। बहु-नमूना अंतराल चयन और सत्यापन के बाद, EGARCH में बेहतर प्रदर्शन होगा, जो मुख्य रूप से इसलिए है क्योंकि EGARCH नमूनों की heteroscedasticity को अच्छी तरह से बताता है।
9. निष्कर्ष
उपरोक्त सरल विश्लेषण से, यह पाया जा सकता है कि बिटकॉइन की लघुगणकीय प्रतिफल दर सामान्य वितरण के अनुरूप नहीं है, जो मोटी वसा पूंछों की विशेषता है, और अस्थिरता में एकत्रीकरण और लाभप्रदता प्रभाव है, जबकि स्पष्ट सशर्त विषमता दिखाती है।
लघुगणकीय प्रतिफल दर की भविष्यवाणी और मूल्यांकन में, एआरएमए मॉडल की इंट्रा सैंपल स्थैतिक भविष्यवाणी क्षमता गतिशील से काफी बेहतर है, जो दिखाता है कि रोलिंग विधि पुनरावर्ती विधि से स्पष्ट रूप से बेहतर है, और ओवरमैचिंग और त्रुटि प्रवर्धन की समस्याओं से बच सकती है। नमूना के बाहर प्रतिफल दर की भविष्यवाणी करना मुश्किल है, जो बाजार की कमजोर दक्षता धारणा को संतुष्ट करता है।
इसके अलावा, बिटकॉइन की मोटी पूंछ घटना, यानी रिटर्न के मोटी पूंछ वितरण से निपटने पर, यह पाया जाता है कि जीईडी (सामान्य त्रुटि) वितरण टी वितरण और सामान्य वितरण से बेहतर है, जो पूंछ जोखिम की माप सटीकता में काफी सुधार कर सकता है। उसी समय, ईजीएआरसीएच में दीर्घकालिक अस्थिरता की भविष्यवाणी करने में अधिक फायदे हैं, जो नमूने की हेटरोसेडेस्टिसिटी की अच्छी तरह से व्याख्या करता है। मॉडल मिलान में सममित अनुमान गुणांक आत्मविश्वास अंतराल से कम है, जो इंगित करता है कि बिटकॉइन के रिटर्न दरों में उतार-चढ़ाव में एक महत्वपूर्ण
पूरी मॉडलिंग प्रक्रिया विभिन्न बोल्ड मान्यताओं से भरी हुई है, और वैधता के आधार पर कोई स्थिरता पहचान नहीं है, इसलिए हम केवल कुछ घटनाओं को सावधानीपूर्वक सत्यापित कर सकते हैं। इतिहास केवल सांख्यिकी में भविष्य की भविष्यवाणी की संभावना का समर्थन कर सकता है, लेकिन सटीकता और लागत प्रदर्शन अनुपात अभी भी एक लंबी कठिन यात्रा है।
पारंपरिक बाजारों की तुलना में, बिटकॉइन के उच्च आवृत्ति डेटा की उपलब्धता आसान है। उच्च आवृत्ति डेटा के आधार पर विभिन्न संकेतकों का
हालाँकि, उपरोक्त सिद्धांत तक ही सीमित है। उच्च आवृत्ति डेटा वास्तव में व्यापारियों के व्यवहार का अधिक सटीक विश्लेषण प्रदान कर सकता है। यह न केवल वित्तीय सैद्धांतिक मॉडल के लिए अधिक विश्वसनीय परीक्षण प्रदान कर सकता है, बल्कि व्यापारियों के लिए अधिक प्रचुर निर्णय लेने की जानकारी भी प्रदान कर सकता है, यहां तक कि सूचना प्रवाह और पूंजी प्रवाह की भविष्यवाणी का समर्थन करता है, और अधिक सटीक मात्रात्मक व्यापार रणनीतियों को डिजाइन करने में सहायता करता है। हालांकि, बिटकॉइन बाजार इतना अस्थिर है कि बहुत लंबे ऐतिहासिक डेटा प्रभावी निर्णय लेने की जानकारी से मेल नहीं खा सकते हैं, इसलिए उच्च आवृत्ति डेटा निश्चित रूप से डिजिटल मुद्रा के निवेशकों के लिए अधिक बाजार लाभ लाएगा।
अंत में, यदि आपको उपरोक्त सामग्री उपयोगी लगती है, तो आप मुझे एक कप कोला खरीदने के लिए थोड़ा BTC भी दे सकते हैं। लेकिन मुझे कॉफी की आवश्यकता नहीं है, इसे पीने के बाद मैं सो जाऊंगा।
- क्रिप्टोक्यूरेंसी बाजार में मौलिक विश्लेषण की मात्राः डेटा को खुद के लिए बोलने दें!
- मौद्रिक सर्कल के मूलभूत मात्रात्मक अनुसंधान - अब हर तरह के जादूगरों पर भरोसा न करें, डेटा निष्पक्ष रूप से बोलते हैं!
- क्वांटिफाइड ट्रेडिंग के लिए आवश्यक उपकरण - आविष्कारक क्वांटिफाइड डेटा एक्सप्लोरर मॉड्यूल
- सब कुछ में महारत हासिल करना - एफएमजेड ट्रेडिंग टर्मिनल का नया संस्करण (टीआरबी आर्बिट्रेज स्रोत कोड के साथ)
- सब कुछ जानने के लिए FMZ के नए संस्करण के लिए ट्रेडिंग टर्मिनल का परिचय (अनुदानित TRB सूट स्रोत कोड)
- एफएमजेड क्वांटः क्रिप्टोकरेंसी बाजार में सामान्य आवश्यकताओं के डिजाइन उदाहरणों का विश्लेषण (II)
- 80 पंक्तियों के कोड में उच्च आवृत्ति रणनीति के साथ मस्तिष्क रहित बिक्री बॉट्स का शोषण कैसे करें
- एफएमजेड क्वांटिकेशनः क्रिप्टोक्यूरेंसी बाजार में आम जरूरतों के डिजाइन उदाहरण का विश्लेषण
- 80 लाइनों के कोड के साथ उच्च आवृत्ति रणनीतियों का उपयोग करके बेचने के लिए मस्तिष्क रहित रोबोट का शोषण कैसे करें
- एफएमजेड क्वांटः क्रिप्टोकरेंसी बाजार में सामान्य आवश्यकताओं के डिजाइन उदाहरणों का विश्लेषण (I)
- एफएमजेड क्वांटिकेशनः क्रिप्टोक्यूरेंसी बाजार में आम जरूरतों के डिजाइन उदाहरण का विश्लेषण (1)