Bisakah Anda berlari lebih cepat dari gorila dengan bertaruh (berdagang) menggunakan mesin vektor SVM?
 3
3843
3
3843
Bisakah Anda berlari lebih cepat dari gorila dengan bertaruh (berdagang) menggunakan mesin vektor SVM?
Hari ini, kita akan melakukan yang terbaik untuk mengalahkan orangutan, yang dianggap sebagai salah satu pesaing paling menakutkan di dunia keuangan. Kami akan mencoba memprediksi hasil trading Forex hari berikutnya. Saya jamin, bahkan untuk mengalahkan orangutan yang bertaruh secara acak dan mendapatkan peluang 50% untuk menang adalah hal yang sangat sulit. Kami akan menggunakan algoritma pembelajaran mesin yang sudah ada, yang mendukung klasifikasi vektor. Mesin vektor SVM adalah metode yang sangat kuat untuk menyelesaikan tugas regresi dan klasifikasi.
- SVM mendukung mesin vektor
Mesin vektor SVM didasarkan pada gagasan bahwa kita dapat menggunakan superplanet untuk memilah ruang karakteristik p. Algoritma mesin vektor SVM menggunakan superplanet dan Margin Identifikasi untuk menciptakan batas keputusan klasifikasi, seperti gambar di bawah ini.
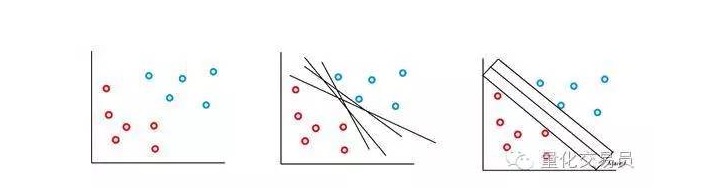
Dalam kasus yang paling sederhana, klasifikasi linier adalah mungkin. Algoritma memilih batas keputusan, yang dapat memaksimalkan jarak antara kelas.
Dalam sebagian besar waktu yang Anda hadapi dalam keuangan, Anda tidak mungkin menemukan set yang mudah dan linear yang dapat dipisahkan, tetapi tidak dapat dipisahkan sering terjadi. Mesin vektor SVM memecahkan masalah ini dengan menerapkan metode yang dikenal sebagai metode margin lunak.
Dalam kasus ini, beberapa kesalahan klasifikasi diizinkan, tetapi mereka sendiri melakukan fungsi untuk meminimalkan faktor dan jarak kesalahan ke batas yang proporsional dengan C (kesalahan biaya atau anggaran dapat diizinkan).
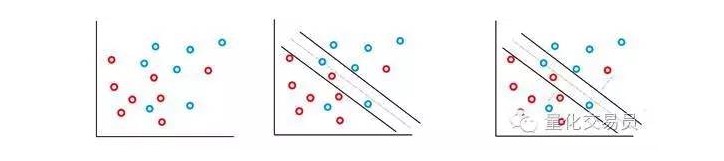
Pada dasarnya, mesin akan memaksimalkan jarak antara klasifikasi, sementara mengurangi hukuman yang ditimbang oleh C.
Classifier SVM memiliki fitur yang bagus yaitu lokasi dan ukuran dari batas keputusan klasifikasi ditentukan hanya oleh sebagian data, yaitu bagian data yang paling dekat dari batas keputusan. Sifat dari algoritma ini memungkinkan untuk melawan gangguan dari nilai-nilai yang tidak normal dari jarak jauh.
Apakah itu terlalu rumit? yah, saya pikir kesenangan baru saja dimulai.
Pertimbangkan hal-hal berikut ((membedakan titik merah dari titik warna lainnya):
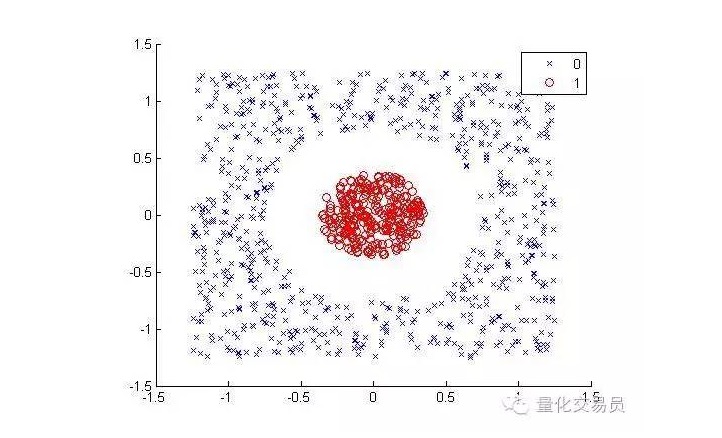
Bagi manusia, pengelompokan itu sangat sederhana. Tapi tidak untuk mesin. Jelas, itu tidak bisa dibuat menjadi garis lurus.
Teknik inti adalah teknik matematika yang sangat cerdas yang memungkinkan kita untuk memecahkan masalah klasifikasi linier dalam ruang dimensi tinggi. Sekarang mari kita lihat bagaimana cara melakukannya.
Kita akan mengubah ruang fitur dua dimensi menjadi tiga dimensi dengan cara mengevaluasi dan mengelompokkannya kembali ke dua dimensi.
Berikut ini adalah pemetaan dimensi dan hasil pengelompokan:
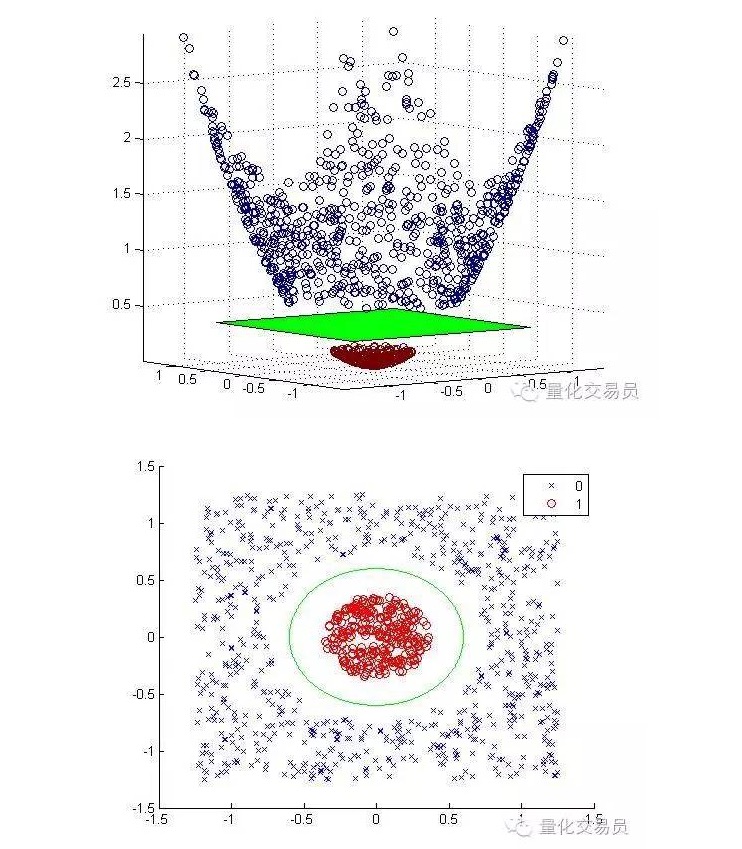
Secara umum, jika Anda memiliki d input, Anda dapat memetakan dari ruang input dimensi-d ke ruang fitur dimensi-p menggunakan sebuah pemetaan. Jalankan solusi yang akan dihasilkan oleh algoritma minimalisasi di atas, lalu memetakan kembali ke superplanet dimensi-p dari ruang input awal Anda.
Prasyarat penting dari solusi matematis di atas, tergantung pada bagaimana menghasilkan set sampel titik yang baik dalam ruang karakteristik.
Anda hanya perlu set sampel titik-titik ini untuk melakukan optimasi batas, pemetaan tidak perlu jelas, dan titik-titik di ruang fitur berdimensi tinggi dapat dihitung dengan aman melalui fungsi inti ((dan sedikit bantuan dari Teorema Mercer)).
Misalnya, Anda ingin menyelesaikan masalah klasifikasi Anda dalam ruang karakteristik yang sangat besar, misalkan 100000 dimensi. Dapatkah Anda membayangkan kemampuan komputasi yang Anda butuhkan? Saya sangat meragukan apakah Anda dapat menyelesaikannya.
- Tantangan dan Gorila
Sekarang kita bersiap menghadapi tantangan untuk mengalahkan Jeff dalam hal kemampuan memprediksi.
Jeff adalah seorang ahli di pasar uang, dan dengan bertaruh secara acak, dia bisa mendapatkan akurasi prediksi 50%, yang merupakan sinyal untuk memprediksi tingkat keuntungan pada hari perdagangan berikutnya.
Kami akan menggunakan berbagai urutan waktu dasar, termasuk urutan waktu harga langsung, dengan keuntungan hingga 10 lag per urutan waktu, dengan total 55 fitur.
Vektor SVM yang akan kami bangun adalah menggunakan kernel 3 derajat. Anda dapat membayangkan bahwa memilih kernel yang sesuai adalah tugas yang sangat sulit lainnya, untuk mengkalibrasi parameter C dan Γ, triple cross-validate berjalan pada grid dari kombinasi parameter yang mungkin, dan set terbaik akan dipilih.
Hasilnya tidak terlalu menggembirakan:
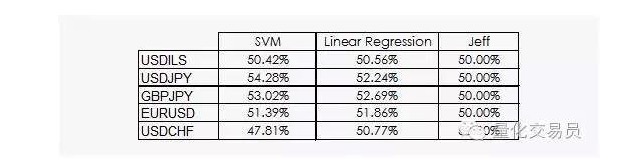
Kita bisa melihat bahwa baik Regressi Linear maupun Mesin Vektor SVM bisa mengalahkan Jeff. Meskipun hasilnya tidak terlalu optimis, kita juga bisa mengambil beberapa informasi dari data, dan itu sudah menjadi berita baik, karena dalam disiplin data, keuntungan dari urutan waktu keuangan sehari-hari bukanlah yang paling berguna.
Setelah verifikasi silang, dataset akan dilatih dan diuji, kami mencatat kemampuan prediksi SVM yang dilatih, dan untuk memiliki kinerja yang stabil, kami mengulangi pembagian acak setiap mata uang 1000 kali.
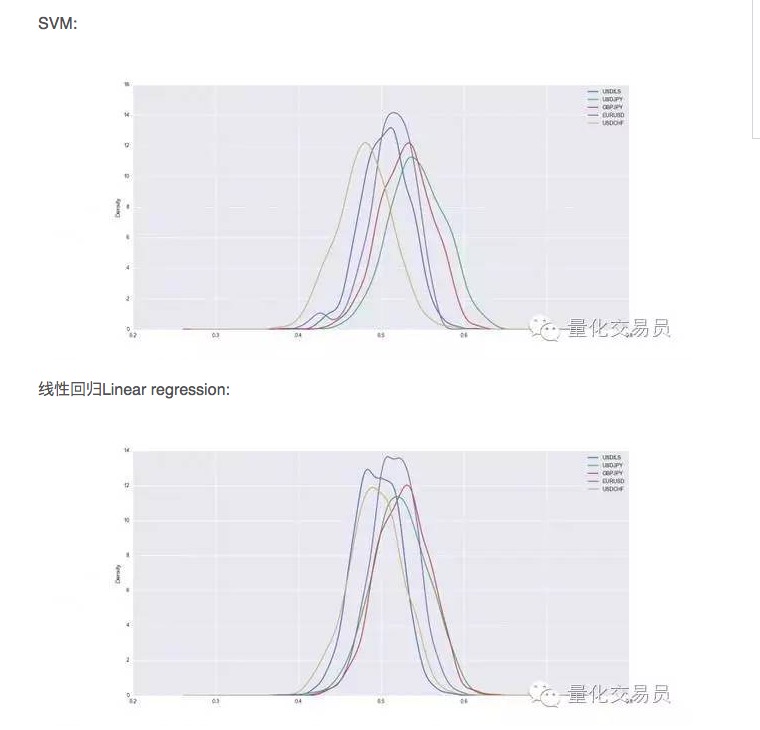
Dengan demikian, dalam beberapa kasus, SVM lebih baik dari regressi linear sederhana, tetapi performa yang berbeda juga sedikit lebih tinggi. Dalam kasus USD/JPY, misalnya, rata-rata sinyal yang dapat kita prediksi adalah 54% dari total jumlah. Ini adalah hasil yang cukup bagus, tapi mari kita lihat lebih dekat!
Ted adalah sepupu Jeff, yang tentu saja juga seekor gorila, tetapi lebih cerdas dari Jeff. Ted memperhatikan set sampel pelatihan, bukan taruhan acak.
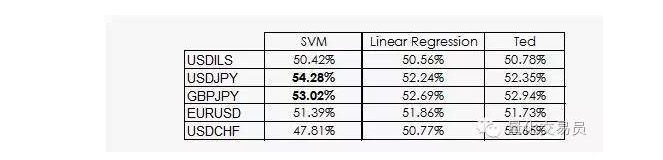
Seperti yang kita lihat, sebagian besar kinerja SVM hanya berasal dari satu fakta: mesin belajar bahwa klasifikasi tidak mungkin sama dengan priori. Sebenarnya, regresi linier tidak dapat memperoleh informasi apa pun dari ruang karakteristik, tetapi intercept () masuk akal dalam regresi, dan intercept dan intercept terkait dengan fakta bahwa suatu klasifikasi berkinerja lebih baik daripada yang lain.
Berita yang sedikit lebih baik, SVM dapat mengambil informasi non-linear tambahan dari data, yang memungkinkan kita untuk memperkirakan keakuratan 2%.
Sayangnya, kita tidak tahu apa itu, seperti halnya mesin vektor SVM memiliki kelemahan utama sendiri, yang tidak bisa kita jelaskan.
Penulis: P. López, diterbitkan di quantdare
Dikutip dari WeChat Public
