Senjata AlphaGo: Algoritma Monte Carlo, Anda akan memahaminya setelah membaca ini! (dengan contoh kode)--Cetak ulang
 0
23882
0
23882
Algorithm Monte Carlo: Algorithm of Alpha Dogs, hanya dengan membaca saja sudah bisa!
Pada tanggal 9-15 Maret tahun ini, sebuah peristiwa besar terjadi di dunia Go, yaitu lima putaran pertempuran antara manusia dan mesin di Seoul, Korea Selatan. Hasil pertandingan ini adalah sebuah kekalahan bagi manusia, dimana juara dunia Go, Lee Hsien Loong, kalah 1-4 dari AlphaGo, sebuah program kecerdasan buatan dari Google. Jadi apa itu AlphaGo dan di mana kunci untuk menang?
- ### Algoritma AlphaGo dan Monte Carlo
Menurut Xinhua, program AlphaGo adalah sebuah program Go-Go yang dikembangkan oleh tim DeepMind milik Google, yang disebut-sebut oleh para penggemar Go-Alpha sebagai Go-Alpha Dog.
Dalam artikel sebelumnya, kami telah membahas tentang algoritma jaringan saraf yang sedang dikembangkan oleh Google untuk membuat mesin belajar secara otonom, dan AlphaGo adalah produk serupa.
Wakil Ketua Asosiasi Otomatisasi China, Sekretaris Jenderal Wang Liyuan mengatakan bahwa para desainer tidak perlu mahir dalam permainan Go, mereka hanya perlu memahami aturan dasar permainan Go. Di belakang AlphaGo adalah sekelompok ilmuwan komputer terkemuka, tepatnya, para ahli di bidang pembelajaran mesin.
Jadi, apa kunci untuk membuat AlphaGo bisa belajar sendiri dan menjadi jenius?
Apa itu Algoritma Monte Carlo? Algorithm Monte Carlo adalah sebuah algoritma yang digunakan untuk mengevaluasi dan mengevaluasi hasil dari sebuah penelitian. Jika ada 1.000 buah apel di dalam keranjang, dan Anda memilih yang terbesar setiap kali Anda menutup mata Anda, Anda dapat memilih tanpa batas. Jadi, Anda dapat mengambil satu secara acak dengan mata tertutup, kemudian mengambil satu lagi secara acak dibandingkan dengan yang pertama, dan meninggalkan yang besar, dan mengambil satu lagi secara acak dibandingkan dengan yang sebelumnya, dan meninggalkan yang besar.
Dengan kata lain, algoritma Monte Carlo adalah bahwa semakin banyak sampel, semakin banyak solusi terbaik yang dapat ditemukan, tetapi tidak menjamin bahwa itu adalah yang terbaik, karena jika ada 10.000 apel, mungkin akan ditemukan yang lebih besar.
Perbandingan yang dapat dibuat antara dia dan algoritma Las Vegas adalah: Konon katanya, jika ada sebuah kunci, ada 1000 kunci untuk dipilih, tetapi hanya 1 yang benar. Jadi setiap kali mengambil 1 kunci secara acak untuk mencoba, dan tidak bisa dibuka, ganti 1 lagi. Semakin banyak percobaan, semakin besar peluang untuk membuka solusi terbaik, tetapi sebelum dibuka, kunci yang salah itu tidak berguna.
Jadi algoritma Las Vegas adalah solusi terbaik, tetapi tidak selalu dapat ditemukan. Dengan asumsi bahwa tidak ada kunci yang dapat dibuka dari 1.000 kunci, kunci sebenarnya adalah kunci 1001, tetapi tidak ada algoritma 1001 dalam sampel, algoritma Las Vegas tidak dapat menemukan kunci yang dapat dibuka.
Algoritma Monte Carlo dari AlphaGo Kesulitan Go sangat besar bagi kecerdasan buatan, karena Go memiliki terlalu banyak cara untuk dimainkan sehingga sulit bagi komputer untuk membedakannya. Wang Jiyun berkata: Yang pertama, Go memiliki banyak kemungkinan. Setiap langkah Go memiliki banyak kemungkinan, dan pemain Go memiliki 19 × 19 = 361 pilihan jatuh. Dalam satu putaran Go 150 putaran, ada 10.170 situasi yang mungkin terjadi. Yang kedua, adalah aturan yang terlalu halus, dalam beberapa hal, pilihan jatuh bergantung pada intuisi yang terbentuk dari akumulasi pengalaman. Selain itu, dalam permainan Go, komputer sulit untuk membedakan kekuatan dan kelemahan permainan saat ini. Oleh karena itu, tantangan Go disebut sebagai rencana Apollo AI.
AlphaGo bukan hanya sebuah algoritma Monte Carlo, melainkan sebuah versi upgrade dari algoritma Monte Carlo.
AlphaGo bekerja sama dengan algoritma pencarian pohon Monte Carlo dan dua jaringan saraf dalam untuk menyelesaikan permainan catur. Sebelum berhadapan dengan Lee Hsien Loong, Google pertama-tama melatih jaringan saraf anjing Alpha dengan hampir 30 juta langkah dari pasangan manusia, sehingga ia dapat memprediksi bagaimana pemain catur profesional manusia jatuh.
“Tugas mereka adalah untuk bekerja sama dan memilih langkah-langkah catur yang lebih menjanjikan, meninggalkan catur yang jelas-jelas kurang baik, sehingga penghitungan dapat dikendalikan dalam batas yang dapat dilakukan komputer”.
Iain Yang, peneliti dari Institut Automasi Akademi Ilmu Pengetahuan Tiongkok, mengatakan bahwa perangkat lunak permainan catur tradisional, umumnya menggunakan pencarian kekerasan, termasuk komputer biru tua, yang membangun pohon pencarian untuk semua hasil yang mungkin (setiap hasil adalah salah satu buah di pohon), melakukan pencarian melintasi sesuai kebutuhan. Metode ini juga memiliki beberapa kelayakan dalam bidang catur, catur, dan lain-lain, tetapi tidak dapat diterapkan untuk Go, karena Go melintasi 19 baris, kemungkinan jatuhnya sangat besar sehingga komputer tidak dapat membangun pohon ini (terlalu banyak buah) untuk melakukan pencarian melintasi.
Yanggach menjelaskan lebih lanjut bahwa satu unit dasar jaringan saraf dalam mirip dengan neuron di otak manusia, dengan banyak lapisan yang terhubung seolah-olah jaringan saraf di otak manusia. Dua jaringan saraf AlphaGo adalah jaringan strategi dan jaringan penilaian.
Jaringan strategi berlian terutama digunakan untuk menghasilkan strategi gugur. Dalam proses bermain catur, bukan memikirkan apa yang harus dilakukan sendiri, tetapi memikirkan apa yang akan dilakukan oleh tangan manusia. Artinya, berdasarkan status saat ini dari papan catur input, ia akan memprediksi di mana langkah selanjutnya manusia akan bermain catur, dan mengajukan beberapa keputusan yang paling sesuai dengan pemikiran manusia.
Namun, jaringan strategi tidak tahu apakah langkah yang akan mereka keluarkan akan berhasil atau tidak, mereka hanya tahu apakah langkah itu sama dengan langkah manusia, dan di sinilah jaringan penilaian akan bekerja.
Mengutip Van Gast: Jaringan penilaian pivot akan mengevaluasi seluruh posisi untuk setiap pilihan yang mungkin, dan kemudian memberikan pivot kemenangan. Nilai-nilai ini akan ditampilkan ke dalam algoritme pencarian pohon Monte Carlo, yang akan memunculkan langkah dengan pivot kemenangan tertinggi melalui proses berulang seperti di atas.
AlphaGo menggunakan kedua alat ini untuk menganalisis situasi dan menilai keunggulan dan kelemahan dari setiap strategi di bawahnya, seperti pemain catur manusia yang akan menilai situasi saat ini dan menduga situasi di masa depan. Dengan menggunakan algoritma pencarian pohon Monte Carlo untuk menganalisis 20 langkah di masa depan, Anda dapat menentukan di mana probabilitas kemenangan di bawahnya akan tinggi.
Namun tidak diragukan lagi, algoritma Monte Carlo adalah salah satu inti dari AlphaGo.
Dua percobaan kecil Akhirnya, mari kita lihat dua eksperimen kecil dengan algoritma Monte Carlo.
- ### 1. Hitung perputaran pi.
Prinsipnya: pertama-tama gambarkan sebuah persegi, gambarkan lingkaran di dalamnya, lalu gambarkan titik acak di dalam persegi, dan atur titik yang jatuh di dalam lingkaran menjadi P, maka P = luas lingkaran / luas persegi. P=(Pi*R*R)/(2R*2R) = Pi/4, yaitu Pi = 4P
Langkah selanjutnya: 1. Letakkan pusat lingkaran pada titik asal dan buat lingkaran dengan R sebagai radius, maka 1⁄4 lingkaran luas kuadrat pertama adalah Pi*R*R/4 2. Buatlah persegi luar dari 1⁄4 lingkaran, dengan koordinat: ((0,0) ((0,R) ((R,0) ((R,R), maka luas persegi tersebut adalah R*R 3. Pilih titik ((X,Y)), sehingga 0 <= X <= R dan 0 <= Y <= R, yaitu titik di dalam persegi 4. Melalui rumus X*X+Y*Y*R menilai apakah titik berada dalam 1⁄4 lingkaran. 5. Jika N adalah jumlah semua titik ((yaitu jumlah percobaan) dan M adalah jumlah titik dalam lingkaran 1 / 4 ((yang memenuhi titik langkah 4), maka
P = M/N, jadi Pi = 4.*N/M
 Gambar 1
Gambar 1
Hasil M_C(10000) adalah 3.1424
- ### 2. Simulasi Monte Carlo untuk mencari nilai ekstrem dari fungsi, untuk menghindari terjerumus ke dalam nilai ekstrem lokal
# Di antara[-2,2] secara acak menghasilkan sebuah bilangan, mencari y yang sesuai, dan mencari di dalamnya yang terbesar yang dianggap sebagai fungsi di[-2,2] dengan nilai maksimum
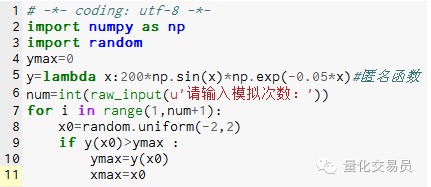 Gambar 2.
Gambar 2.
Setelah 1000 kali simulasi ditemukan nilai maksimum 185.12292832389875 (sangat akurat)
Lihat ini, kalian sudah paham. Anda bisa menulis kode dengan tangan, itu sangat menarik! Dikutip dari WeChat Public