Pemodelan dan Analisis Volatilitas Bitcoin Berdasarkan Model ARMA-EGARCH
Penulis:Lydia, Dibuat: 2022-11-15 15:32:43, Diperbarui: 2023-09-14 20:30:52ED, dan prosesnya dihilangkan.
Tingkat pencocokan distribusi normal Normal tidak sebaik distribusi t, yang juga menunjukkan bahwa distribusi hasil memiliki ekor yang lebih tebal daripada distribusi normal. Selanjutnya, masukkan proses pemodelan, regresi model ARMA-GARCH(1,1) dijalankan untuk log_return (tingkat logaritma pengembalian) dan diperkirakan sebagai berikut:
Dalam [23]:
am_GARCH = arch_model(training_garch, mean='AR', vol='GARCH',
p=1, q=1, lags=3, dist='ged')
res_GARCH = am_GARCH.fit(disp=False, options={'ftol': 1e-01})
res_GARCH.summary()
Keluar[23]: Iterasi: 1, Func. Jumlah: 10, Negatif LLF: -1917.4262154917305
Hasil Model AR - GARCH
Model rata-rata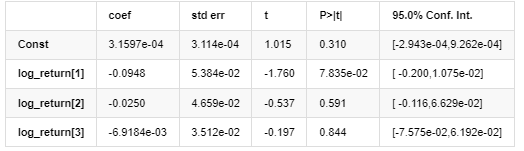
Model Volatilitas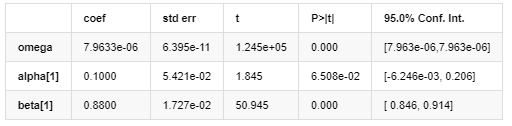
Distribusi
Perkiraan kovarians: kuat
Deskripsi persamaan volatilitas GARCH menurut basis data ARCH: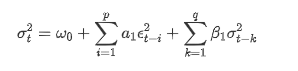
Persamaan regresi bersyarat untuk volatilitas dapat diperoleh sebagai: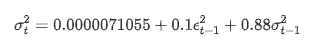
Dikombinasikan dengan volatilitas yang diprediksi, bandingkan dengan volatilitas sampel yang direalisasikan untuk melihat efeknya.
Di [26]:
def recursive_forecast(pd_dataframe):
window = predict_lag
model = 'GARCH'
index = kline_test[1:].index
end_loc = np.where(index >= kline_test.index[window])[0].min()
forecasts = {}
for i in range(len(kline_test[1:]) - window + 2):
mod = arch_model(pd_dataframe['log_return'][1:], mean='AR', vol=model, dist='ged',p=1, q=1)
res = mod.fit(last_obs=i+end_loc, disp='off', options={'ftol': 1e03})
temp = res.forecast().variance
fcast = temp.iloc[i + end_loc - 1]
forecasts[fcast.name] = fcast
forecasts = pd.DataFrame(forecasts).T
pd_dataframe['recursive_{}'.format(model)] = forecasts['h.1']
evaluate(pd_dataframe, 'realized_volatility_1_hour', 'recursive_{}'.format(model))
recursive_forecast(kline_test)
Keluar[26]: Kesalahan mutlak rata-rata (MAE): 0,0128 Kesalahan Persentase Absolute Rata-rata (MAPE): 95,6 Kasalahan akar rata-rata persegi (RMSE): 0,018
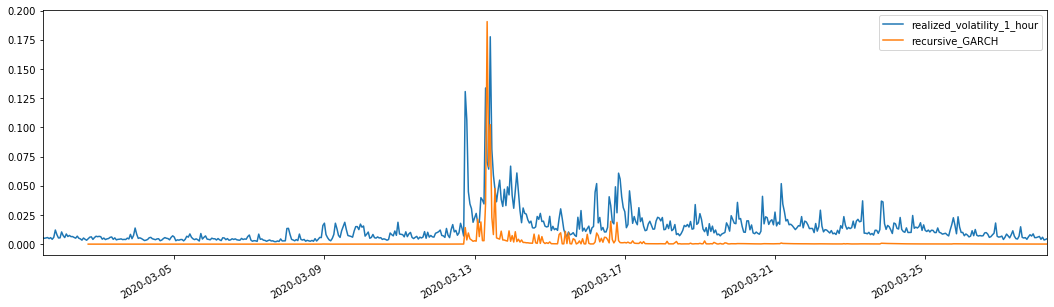
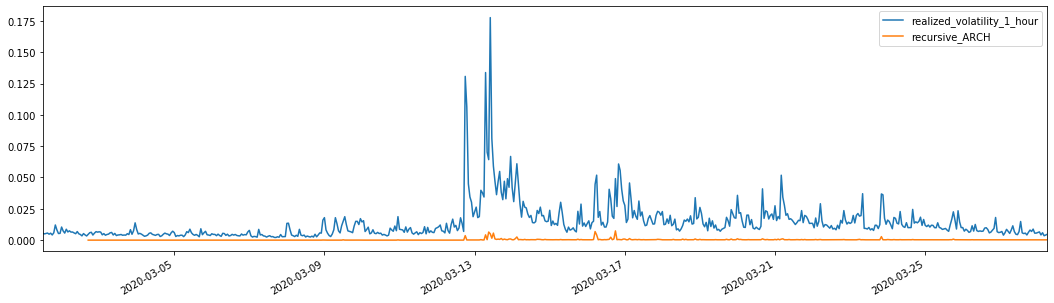
Untuk perbandingan, buatlah ARCH sebagai berikut:
Dalam [27]:
def recursive_forecast(pd_dataframe):
window = predict_lag
model = 'ARCH'
index = kline_test[1:].index
end_loc = np.where(index >= kline_test.index[window])[0].min()
forecasts = {}
for i in range(len(kline_test[1:]) - window + 2):
mod = arch_model(pd_dataframe['log_return'][1:], mean='AR', vol=model, dist='ged', p=1)
res = mod.fit(last_obs=i+end_loc, disp='off', options={'ftol': 1e03})
temp = res.forecast().variance
fcast = temp.iloc[i + end_loc - 1]
forecasts[fcast.name] = fcast
forecasts = pd.DataFrame(forecasts).T
pd_dataframe['recursive_{}'.format(model)] = forecasts['h.1']
evaluate(pd_dataframe, 'realized_volatility_1_hour', 'recursive_{}'.format(model))
recursive_forecast(kline_test)
Keluar[27]: Kesalahan mutlak rata-rata (MAE): 0,0136 Kesalahan Persentase Absolute Rata-rata (MAPE): 98,1 Kasalahan akar rata-rata persegi (RMSE): 0,02
7. model EGARCH
Langkah selanjutnya adalah untuk melakukan EGARCH pemodelan
Dalam [24]:
am_EGARCH = arch_model(training_egarch, mean='AR', vol='EGARCH',
p=1, lags=3, o=1,q=1, dist='ged')
res_EGARCH = am_EGARCH.fit(disp=False, options={'ftol': 1e-01})
res_EGARCH.summary()
Keluar[24]: Iterasi: 1, Func. Jumlah: 11, Negatif LLF: -1966.610328148909
Hasil Model AR - EGARCH
Model rata-rata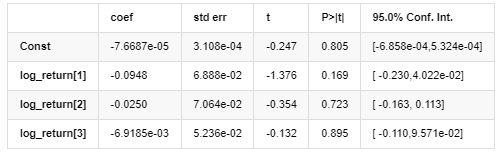
Model Volatilitas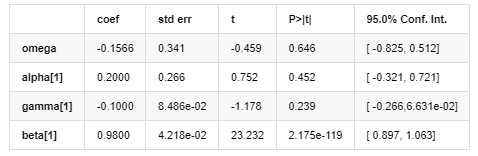
Distribusi
Perkiraan kovarians: kuat
Persamaan volatilitas EGARCH yang disediakan oleh perpustakaan ARCH dijelaskan sebagai berikut: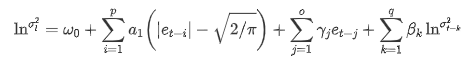
pengganti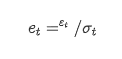
Persamaan regresi kondisional volatilitas dapat diperoleh sebagai berikut: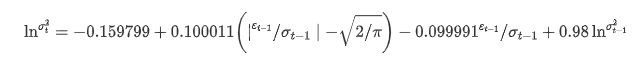
Di antara mereka, koefisien perkiraan dari istilah simetris γ lebih kecil dari interval kepercayaan, menunjukkan bahwa ada
Digabungkan dengan volatilitas yang diprediksi yang dicocokkan, hasilnya dibandingkan dengan volatilitas sampel yang direalisasikan sebagai berikut:
Dalam [28]:
def recursive_forecast(pd_dataframe):
window = 280
model = 'EGARCH'
index = kline_test[1:].index
end_loc = np.where(index >= kline_test.index[window])[0].min()
forecasts = {}
for i in range(len(kline_test[1:]) - window + 2):
mod = arch_model(pd_dataframe['log_return'][1:], mean='AR', vol=model,
lags=3, p=2, o=0, q=1, dist='ged')
res = mod.fit(last_obs=i+end_loc, disp='off', options={'ftol': 1e03})
temp = res.forecast().variance
fcast = temp.iloc[i + end_loc - 1]
forecasts[fcast.name] = fcast
forecasts = pd.DataFrame(forecasts).T
pd_dataframe['recursive_{}'.format(model)] = forecasts['h.1']
evaluate(pd_dataframe, 'realized_volatility_1_hour', 'recursive_{}'.format(model))
pd_dataframe['recursive_{}'.format(model)]
recursive_forecast(kline_test)
Keluar[28]: Kesalahan mutlak rata-rata (MAE): 0,0201 Kesalahan persentase absolut rata-rata (MAPE): 122 Kasalahan akar rata-rata persegi (RMSE): 0,0279
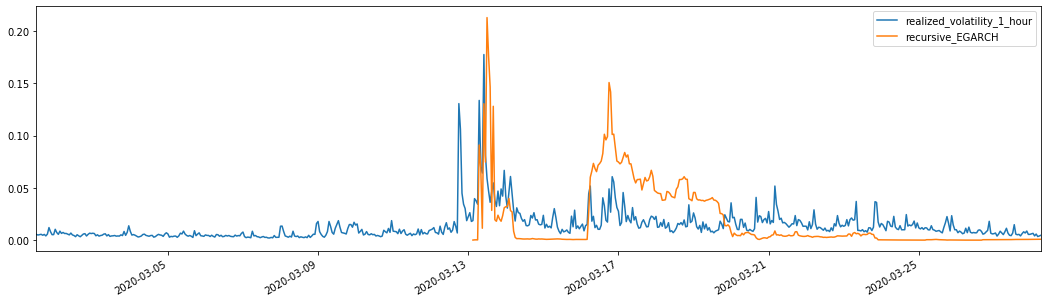
Hal ini dapat dilihat bahwa EGARCH lebih sensitif terhadap volatilitas dan lebih cocok volatilitas daripada ARCH dan GARCH.
8. Evaluasi prediksi volatilitas
Data per jam dipilih berdasarkan sampel, dan langkah selanjutnya adalah memprediksi satu jam ke depan. Kami memilih volatilitas yang diprediksi dari 10 jam pertama dari tiga model, dengan RV sebagai volatilitas patokan. Nilai kesalahan komparatif adalah sebagai berikut:
Dalam [29]:
compare_ARCH_X = pd.DataFrame()
compare_ARCH_X['original']=kline_test['realized_volatility_1_hour']
compare_ARCH_X['arch']=kline_test['recursive_ARCH']
compare_ARCH_X['arch_diff']=compare_ARCH_X['original']-np.abs(compare_ARCH_X['arch'])
compare_ARCH_X['garch']=kline_test['recursive_GARCH']
compare_ARCH_X['garch_diff']=compare_ARCH_X['original']-np.abs(compare_ARCH_X['garch'])
compare_ARCH_X['egarch']=kline_test['recursive_EGARCH']
compare_ARCH_X['egarch_diff']=compare_ARCH_X['original']-np.abs(compare_ARCH_X['egarch'])
compare_ARCH_X = compare_ARCH_X[280:]
compare_ARCH_X.head(10)
Keluar[29]: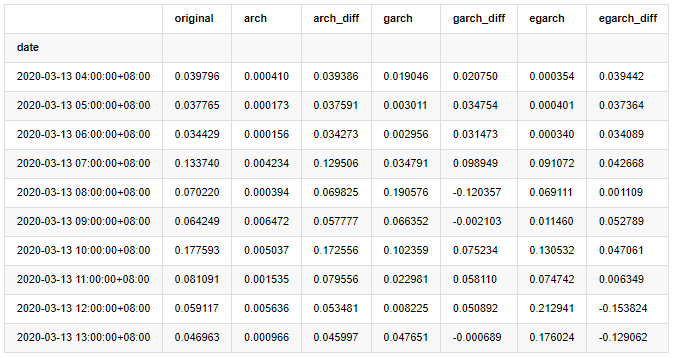
Di [30]:
compare_ARCH_X_diff = pd.DataFrame(index=['ARCH','GARCH','EGARCH'], columns=['head 1 step', 'head 10 steps', 'head 100 steps'])
compare_ARCH_X_diff['head 1 step']['ARCH'] = compare_ARCH_X['arch_diff']['2020-03-13 04:00:00+08:00']
compare_ARCH_X_diff['head 10 steps']['ARCH'] = np.mean(compare_ARCH_X['arch_diff'][:10])
compare_ARCH_X_diff['head 100 steps']['ARCH'] = np.mean(compare_ARCH_X['arch_diff'][:100])
compare_ARCH_X_diff['head 1 step']['GARCH'] = compare_ARCH_X['garch_diff']['2020-03-13 04:00:00+08:00']
compare_ARCH_X_diff['head 10 steps']['GARCH'] = np.mean(compare_ARCH_X['garch_diff'][:10])
compare_ARCH_X_diff['head 100 steps']['GARCH'] = np.mean(compare_ARCH_X['garch_diff'][:100])
compare_ARCH_X_diff['head 1 step']['EGARCH'] = compare_ARCH_X['egarch_diff']['2020-03-13 04:00:00+08:00']
compare_ARCH_X_diff['head 10 steps']['EGARCH'] = np.mean(compare_ARCH_X['egarch_diff'][:10])
compare_ARCH_X_diff['head 100 steps']['EGARCH'] = np.abs(np.mean(compare_ARCH_X['egarch_diff'][:100]))
compare_ARCH_X_diff
Keluar[30]: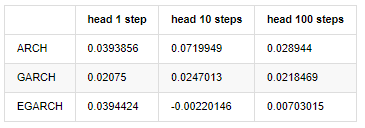
Beberapa tes telah dilakukan, dalam hasil prediksi jam pertama, kemungkinan kesalahan terkecil EGARCH relatif besar, tetapi perbedaan keseluruhan tidak terlalu jelas; Ada beberapa perbedaan yang jelas dalam efek prediksi jangka pendek; EGARCH memiliki kemampuan prediksi yang paling luar biasa dalam prediksi jangka panjang
Di [31]:
compare_ARCH_X = pd.DataFrame()
compare_ARCH_X['Model'] = ['ARCH','GARCH','EGARCH']
compare_ARCH_X['RMSE'] = [get_rmse(kline_test['realized_volatility_1_hour'][280:320],kline_test['recursive_ARCH'][280:320]),
get_rmse(kline_test['realized_volatility_1_hour'][280:320],kline_test['recursive_GARCH'][280:320]),
get_rmse(kline_test['realized_volatility_1_hour'][280:320],kline_test['recursive_EGARCH'][280:320])]
compare_ARCH_X['MAPE'] = [get_mape(kline_test['realized_volatility_1_hour'][280:320],kline_test['recursive_ARCH'][280:320]),
get_mape(kline_test['realized_volatility_1_hour'][280:320],kline_test['recursive_GARCH'][280:320]),
get_mape(kline_test['realized_volatility_1_hour'][280:320],kline_test['recursive_EGARCH'][280:320])]
compare_ARCH_X['MASE'] = [get_mape(kline_test['realized_volatility_1_hour'][280:320],kline_test['recursive_ARCH'][280:320]),
get_mape(kline_test['realized_volatility_1_hour'][280:320],kline_test['recursive_GARCH'][280:320]),
get_mape(kline_test['realized_volatility_1_hour'][280:320],kline_test['recursive_EGARCH'][280:320])]
compare_ARCH_X
Keluar[31]: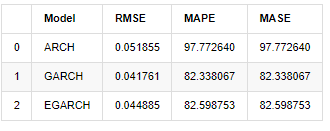
Dalam hal indikator, GARCH dan EGARCH memiliki beberapa perbaikan dibandingkan dengan ARCH, tetapi perbedaannya tidak terlalu jelas.
9. Kesimpulan
Dari analisis sederhana di atas, dapat ditemukan bahwa tingkat pengembalian logaritma Bitcoin tidak sesuai dengan distribusi normal, yang ditandai dengan ekor lemak tebal, dan volatilitas memiliki efek agregasi dan leverage, sementara menunjukkan heterogenitas bersyarat yang jelas.
Dalam prediksi dan evaluasi tingkat pengembalian logaritma, kemampuan prediksi statis dalam sampel ARMA lebih baik daripada yang dinamis secara signifikan, yang menunjukkan bahwa metode rolling jelas lebih baik daripada metode iteratif, dan dapat menghindari masalah overmatching dan amplifikasi kesalahan.
Selain itu, ketika berurusan dengan fenomena ekor tebal Bitcoin, yaitu distribusi ekor tebal pengembalian, ditemukan bahwa distribusi GED (kesalahan umum) lebih baik daripada distribusi t dan distribusi normal secara signifikan, yang dapat meningkatkan akurasi pengukuran risiko ekor. Pada saat yang sama, EGARCH memiliki lebih banyak keuntungan dalam memprediksi volatilitas jangka panjang, yang menjelaskan baik heteroskedastikitas sampel. Koefisien estimasi simetris dalam pencocokan model kurang dari interval kepercayaan, yang menunjukkan bahwa ada
Seluruh proses pemodelan penuh dengan berbagai asumsi berani, dan tidak ada identifikasi konsistensi tergantung pada validitas, sehingga kita hanya dapat memverifikasi beberapa fenomena dengan hati-hati. Sejarah hanya dapat mendukung probabilitas memprediksi masa depan dalam statistik, tetapi akurasi dan rasio kinerja biaya masih memiliki perjalanan panjang yang sulit untuk dilakukan.
Dibandingkan dengan pasar tradisional, ketersediaan data frekuensi tinggi Bitcoin lebih mudah. Pengukuran
Namun, yang disebutkan di atas terbatas pada teori. Data frekuensi yang lebih tinggi memang dapat memberikan analisis yang lebih akurat tentang perilaku pedagang. Hal ini tidak hanya dapat memberikan tes yang lebih dapat diandalkan untuk model teoritis keuangan, tetapi juga memberikan informasi pengambilan keputusan yang lebih melimpah bagi pedagang, bahkan mendukung prediksi aliran informasi dan arus modal, dan membantu merancang strategi perdagangan kuantitatif yang lebih tepat. Namun, pasar Bitcoin sangat fluktuatif sehingga data historis yang terlalu lama tidak dapat mencocokkan informasi pengambilan keputusan yang efektif, sehingga data frekuensi tinggi pasti akan membawa keuntungan pasar yang lebih besar bagi investor mata uang digital.
Akhirnya, jika Anda merasa konten di atas bermanfaat, Anda juga bisa menawarkan sedikit BTC untuk membelikan saya secangkir Cola.
- Mengkuantifikasi Analisis Fundamental di Pasar Cryptocurrency: Biarkan Data Berbicara Sendiri!
- Di sini, saya akan membahas beberapa hal yang sangat penting tentang penelitian kuantitatif dasar dalam lingkaran mata uang - jangan percaya lagi pada guru-guru sihir yang bodoh, data berbicara secara obyektif!
- Alat penting dalam bidang transaksi kuantitatif - inventor modul eksplorasi data kuantitatif
- Menguasai Semuanya - Pendahuluan ke FMZ Versi Baru Terminal Trading (dengan TRB Arbitrage Source Code)
- Untuk mengetahui semua tentang FMZ, silahkan kunjungi situs resmi FMZ.
- FMZ Quant: Analisis Contoh Desain Persyaratan Umum di Pasar Cryptocurrency (II)
- Cara Mengeksploitasi Robot Penjual Tanpa Otak dengan Strategi Frekuensi Tinggi dalam 80 Baris Kode
- FMZ Kuantitas: Perencanaan Contoh Desain Permintaan Umum di Pasar Cryptocurrency (II)
- Cara Mengeksploitasi Robot Tanpa Otak untuk Dijual dengan Strategi Frekuensi Tinggi 80 Baris Kode
- FMZ Quant: Analisis Contoh Desain Persyaratan Umum di Pasar Cryptocurrency (I)
- Kuantitas FMZ: Perbedaan antara permintaan umum pasar cryptocurrency dan contoh desain (1)