5.4 なぜ抽出外試験が必要なのか
作者: リン・ハーン優しさ作成日: 2019-05-10 09:13:53 更新日:概要
前回のセクションでは,いくつかの重要なパフォーマンス指標に焦点を当てて戦略バックテストパフォーマンスレポートを読む方法を示しました. 実際,バックテストパフォーマンスレポートで利益を生み出す戦略を書くのは難しいものではありません. この戦略が将来もリアルマーケットで有効かどうか評価することは困難です. だから今日は,サンプル外テストとその重要性を説明します.
バックテストは実市場と等しくない
多くの初心者は,自分の取引戦略に容易に納得し,良い見方をするパフォーマンスレポートや資金曲線で自分の考えを実践する準備ができています. 確かに,このバックテスト結果は,彼らが観察した市場の特定の状態に完全に合致しますが,取引戦略が長期間の戦いに置かれたら,その戦略が実際には効果的ではないことを発見します.
私は多くの取引戦略を見てきました. バックテストでは成功率は50%にも達できます. このような高い勝利率の前提下では,まだより高い利益と損失比が1:1です. しかし,これらの戦略が実行されると,それらはすべてお金を失うことになります. その理由はたくさんあります. これらの理由のうち,データサンプルが小さすぎるのが主な原因で,データの偏差につながります.
しかし,取引は非常に複雑で,その後は非常に明らかですが,元のものに戻ると,私たちはまだ圧倒されていると感じます.これは量化の原因 - 歴史データの限界を伴うものです. したがって,取引戦略をテストするために限られた歴史的データしか使用しない場合,
抽出外検査とは?
データが限られているとき,限られたデータを完全に活用して,取引戦略を科学的にテストするにはどうすればよいか?答えは,オフサンプルのテスト方法です.バックテスト中に,歴史的なデータは時間順に2つのセグメントに分かれます.以前のセグメントは戦略最適化のために使用され,トレーニングセットと呼ばれ,後者のセグメントはテストセットと呼ばれるオフサンプルのテストに使用されます.
戦略が常に有効である場合は,トレーニングセットデータ内のいくつかのセットの最適なパラメータを最適化し,これらのセットのパラメータをテストセットデータにバックテストに再び適用します.理想的には,バックテスト結果はトレーニングセットとほぼ同じで,または違いは合理的な範囲内です.この戦略は比較的有効であると言えるでしょう.
テストセットがうまくいかないか,または変化が多く,他のパラメータが同じである場合, 戦略はデータ移行バイアスを有する可能性があります.
例えば,商品先物リバーをバックテストしたいと仮定します.リバーには約10年間のデータ (2009~2019) があります. 2009年から2015年のデータをトレーニングセットとして,2015年から2019年のデータをテストセットとして使用できます.トレーニングセットの最良のパラメータセットが (15,90), (5,50), (10,100)...である場合は,これらのパラメータセットをテストセットに入れます.これらの2つのバックテストパフォーマンスレポートとファンド曲線を比較することで,その違いが合理的な範囲内にあるかどうかを判断します.
抽象外テストを使用しない場合は,戦略をテストするために2009年から2019年のデータを直接使用するだけです.結果は,歴史的なデータに過剰に適合しているため,良いバックテストパフォーマンスレポートである可能性がありますが,そのようなバックテスト結果は実際の市場にとってほとんど意味を持ち,特により多くのパラメータを持つ戦略には指針効果がありません.
試験外試験
上記のように,歴史的なデータがないという前提で,サンプル内のデータとサンプル外のデータを形成するためにデータを2つに分割することが良い考えです. しかし,再帰テストとクロスチェックテストを行うことができれば,さらに良いかもしれません.
復習式テストの基本原理は モデルを訓練するために前の長い歴史的データを利用し モデルをテストするために比較的短いデータを使用し データを取得するために 継続的に時間窓を移動し 訓練とテストの手順を繰り返します
-
訓練データ: 2000年から2001年,試験データ: 2002年
-
訓練データ:2001年から2002年 試験データ:2003年
-
訓練データ:2002年から2003年 試験データ:2004年
-
訓練データ:2003年から2004年 試験データ:2005年
-
訓練データ:2004年から2005年 試験データ:2006年
...そういったこと...
最後に,テスト結果 (2002年,2003年,2004年,2005年,2006年...) を統計的に分析し,戦略の業績を包括的に評価しました.
次の図では,再帰試験の原理を直感的に説明できます.
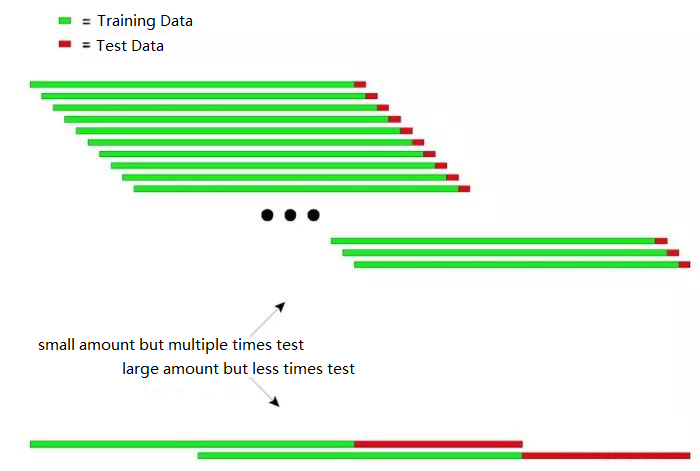
上記の図は,再帰テストの2つの方法を示しています.
第"タイプ:少量で複数回試験
2つ目のタイプ: 大量で試し回数が少ない
実用的な応用では,不固定データに対するモデルの安定性を決定するために,試験データの長さを変更することによって複数の試験を行うことができる.
交差チェックテストの基本原理:すべてのデータを N 部分に分割し, N-1 部分を使って訓練し,残りの部分を使ってテストする.
2000年から2003年まで,年間分別に応じて4つの部分に分かれています.クロスチェックテストの操作は以下の通りです.
-
訓練データ:2001年~2003年 試験データ2000年
-
訓練データ: 2000年~2002年,試験データ: 2003年
-
訓練データ: 2000, 2001, 2003,試験データ: 2002
-
訓練データ: 2000, 2002, 2003,試験データ: 2001年
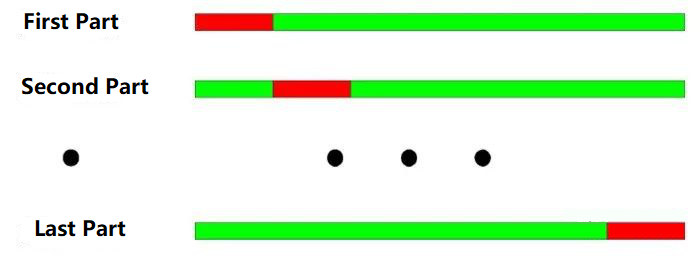
上図のように,クロスチェックテストの最大の利点は,限られたデータを最大限に活用することであり,各トレーニングデータはテストデータでもあります.しかし,バックテストにクロスチェックが適用される場合も明らかな欠点があります.
-
価格データは安定していない場合,モデルのテスト結果はしばしば信頼性がない.例えば,2008年のトレーニングデータと2005年のテストデータを使用する.2008年の市場環境が2005年と比較して大きく変化した可能性が高いため,モデルテストの結果は信頼性がない.
-
最初のテストと同様に クロスチェックのテストでは 最新のデータでモデルを訓練し 古いデータでモデルをテストすると それ自体も論理的ではありません
さらに,定量戦略モデルをテストする際に,再帰テストとクロスチェックテストの両方がデータ重複の問題に直面しています.
取引戦略モデルを開発する際に,ほとんどの技術指標は,特定の期間の歴史的データに基づいています.例えば,過去50日の歴史的データを計算するためにトレンド指標を使用しますが,次の取引日,また取引日の最初の50日のデータから計算されます. 2つの指標を計算するためのデータは49日間同じです.これは,隣接する2日ごとに指標の非常に微小な変化をもたらすでしょう.
データの重複は以下の効果をもたらすことがあります.
-
モデルが予測する結果の ゆっくりとした変化が ポジションの ゆっくりとした変化につながります これは私たちがよく言う指標の 歇症です
-
モデルの結果のテストのためのいくつかの統計値は利用できません. 繰り返しデータによる配列相関性により,いくつかの統計テストの結果は信頼性がない.
良い取引戦略は,将来的に利益をもたらすはずです. 抽出外テストは,取引戦略を客観的に検出することに加えて,定量的なトレーダーにとって時間を節約する上でより効率的です. ほとんどの場合,すべてのサンプルを直接最適なパラメータを使用することは非常に危険です.
パラメータ最適化の時間前のすべての過去データを区別し,データをサンプル内のデータとサンプル外のデータに分割すると,サンプル内のデータを用いてパラメータを最適化し,サンプル外のサンプルをサンプル外テストに使用します.エラーが検出され,同時に最適化された戦略が将来の市場に適しているかどうかをテストすることができます.
結論から言うと
タイムトラベルの能力があれば,取引をする必要はありません. 結局のところ,私たちは皆凡人であり,歴史上のデータで戦略を検証する必要があります.
しかし,膨大な歴史データがあっても,無限の予測不可能な未来の前では,歴史は極めて希少である.したがって,歴史に基づいた取引システムは,最終的には時間とともに沈むだろう.歴史は未来を枯渇させることはできないからである.したがって,完全なポジティブな期待取引システムは,その固有の原則と論理によって支持されなければならない.
信頼して確認しろ - レガン大統領
放課後 運動
-
生存者の偏見とは どんな現実的な現象でしょうか?
-
FMZ Quant プラットフォームを使用して,入試と出試のバックテストを比較する.
- マッハエ取引所がいつ追加されるか
- 端末模擬器でLinuxホストをインストールする際に,最後にBad System Callが表示される原因は?
- 返信する深さの量を調整できますか?
- ローカル,win,Macにロボットを配置する方法
- トークン・フューチャー・エクスチェンジを追加する際に誤りがあった.
- 管理者が Deribit のwss 接続コードを提供できますか?
- BitMax は 総和を使用します
- 視覚化プログラムで最高価格を記録する方法を教えてください
- 複数のデジタル通貨ペアを同時に取ることができる方法はないか?
- 5.5 取引戦略の最適化
- 5.3 戦略バックテストの業績報告の読み方
- よくある質問
- デジタル通貨のリトークでは,アニメーションの底辺の周期が1分であれば,毎分何点のデータをシミュレートすることができますか?
- FMZ 量化プラットフォーム 学ぶ価値のあるビットコインとデジタル通貨の量化戦略
- 5.2 定量的な取引のバックテストをどのように行うか
- デジタル通貨戦略のレビューでは,現在のバーの閉店か次のバーの開店か?
- デジタル通貨戦略のレビューでは,平成の取引量は少ないので,なぜ取引がしばしば失敗するのか,ポジションは凍結Amount > 0
- 5.1 バックテストの意味と罠
- 4.6 C++言語で戦略を実装する方法
- エマに関する質問です