高周波取引戦略について考える (1)
作者: リン・ハーンリディア, 作成日:2023-08-04 13:47:39, 更新日:2023-09-12 15:50:10
高周波取引戦略について考える (1)
デジタル通貨の高周波取引に関する2つの記事を書きました.デジタル通貨高周波戦略 詳細な紹介
高周波 の 利益 の 源
先述した記事では,高周波戦略は,特に変動が非常に高い市場に適していると述べました. 短期間の取引手段の価格変動は,全体的なトレンドと振動から構成されています. 傾向の変化を正確に予測できれば,確かに利益が得られますが,これは最も困難な側面でもあります. 本記事では,私は主に高周波メーカーの戦略に焦点を当て,トレンド予測に深入しません. 振動する市場で,戦略的に入札と注文を出すことで,取引の頻度が十分に高く,利益利益率が大きい場合,トレンドによって引き起こされる潜在的な損失をカバーすることができます. このようにして,市場の動きを予測することなく,収益性が達成できます. 現在,取引所はメーカーの取引に割引を提供しています. これは利益の要素でもあります. 競争の要素が大きいほど,割引の割合は高くなります.
解決 さ れる 問題
-
買取・売却の注文を2つともする戦略の実施における最初の問題は,これらの注文をどこに配置するか決定することです.注文が市場深さに近づくほど,実行の可能性は高くなります.しかし,非常に不安定な市場条件では,注文が即座に実行される価格は市場深さから遠く離れ,十分な利益を得ることができません.一方,注文をあまりにも遠くに配置すると実行の可能性が低下します.これは解決する必要がある最適化問題です.
-
ポジションコントロールはリスクを管理する上で極めて重要です.戦略は,長期間にわたって過剰なポジションを蓄積することはできません.これは,配置された注文の距離と量を制御し,全体的なポジションに制限を設定することによって対処できます.
上記の目標を達成するために,実行確率,実行からの利益,市場推定などのさまざまな側面のためにモデリングと推定が必要である.このトピックには"高周波取引"や"オーダーブック"などのキーワードを使用して多数の記事や論文が利用可能である.多くの勧告もオンラインで見つけることができます.さらに詳細は,この記事の範囲を超えています.さらに,信頼性と高速なバックテストシステムを確立することがお勧めです.高周波戦略はライブ取引を通じて簡単に検証できるが,バックテストは追加の洞察を提供し,試行錯誤のコストを削減するのに役立ちます.
必要なデータ
バイナンスではダウンロード可能なデータ個々のトレードとベスト・ビッド/アスク・オーダーのために.深度データは,ホワイトリストで API を介してダウンロードしたり,手動で収集することもできます.バックテスト目的では,総取引データは十分です.この記事では,HOOKUSDT-aggTrades-2023-01-27データの例を使用します.
[1] において
from datetime import date,datetime
import time
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
個々の貿易データには以下のデータが含まれます.
- agg_trade_id: 総取引のID
- 価格:取引が実行された価格.
- 量: 取引の量.
- first_trade_id:複数の取引が集計される場合,これは最初の取引のIDを表します.
- last_trade_id: アグリゲーション内の最後の取引のID.
- transact_time: 取引実行のタイムスタンプ.
- is_buyer_maker: 取引の方向性を示します.
True はメーカーとして実行される購入注文を表し,セールオーダーはテイカーとして実行されます.
その日,66万の取引が行われたことがわかります.これは非常に活発な市場を示しています. CSVファイルはコメントセクションに添付されます.
[4] において
trades = pd.read_csv('COMPUSDT-aggTrades-2023-07-02.csv')
trades
アウト[4]: ほら ほら ほら ほら ほら ほら ほら
配列 × 7列
単一の取引額をモデル化する
まず,データ処理は,元の取引を2つのグループに分けます:メーカーとして実行された購入オーダーとテイカーとして実行された販売オーダー.さらに,元の総取引データは,同じ時間に,同じ価格で,同じ方向で実行された取引を単一のデータポイントに組み合わせます.例えば,100のボリュームを持つ単一の購入オーダーがある場合,価格が異なる場合,それぞれ60と40のボリュームを持つ2つの取引に分割されることがあります.これは購入オーダーのボリュームの推定に影響を与えます.したがって,トランザクション_タイムに基づいてデータを再び総結集する必要があります.この2番目の総結集後に,データボリュームは140,000のレコードで減少します.
[6] において
trades['date'] = pd.to_datetime(trades['transact_time'], unit='ms')
trades.index = trades['date']
buy_trades = trades[trades['is_buyer_maker']==False].copy()
sell_trades = trades[trades['is_buyer_maker']==True].copy()
buy_trades = buy_trades.groupby('transact_time').agg({
'agg_trade_id': 'last',
'price': 'last',
'quantity': 'sum',
'first_trade_id': 'first',
'last_trade_id': 'last',
'is_buyer_maker': 'last',
'date': 'last',
'transact_time':'last'
})
sell_trades = sell_trades.groupby('transact_time').agg({
'agg_trade_id': 'last',
'price': 'last',
'quantity': 'sum',
'first_trade_id': 'first',
'last_trade_id': 'last',
'is_buyer_maker': 'last',
'date': 'last',
'transact_time':'last'
})
buy_trades['interval']=buy_trades['transact_time'] - buy_trades['transact_time'].shift()
sell_trades['interval']=sell_trades['transact_time'] - sell_trades['transact_time'].shift()
[10] で:
print(trades.shape[0] - (buy_trades.shape[0]+sell_trades.shape[0]))
外部 [10]: 14 6181
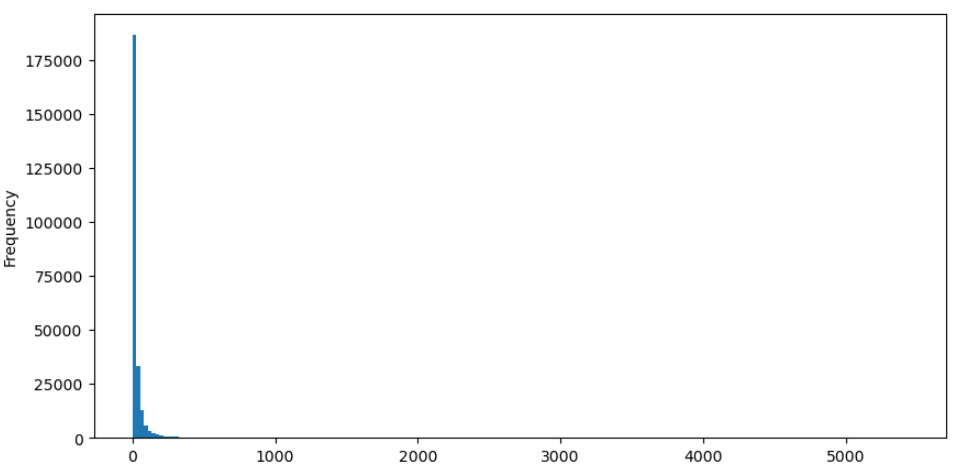
買取オーダーを例として,まずヒストグラムをプロットしてみましょう.ヒストグラムの左端に多数データが集中しているため,大きなロングテール効果があることが観察できます.しかし,尾端に分散したいくつかの大きな取引もあります.
[36]:
buy_trades['quantity'].plot.hist(bins=200,figsize=(10, 5));
外 [36]:
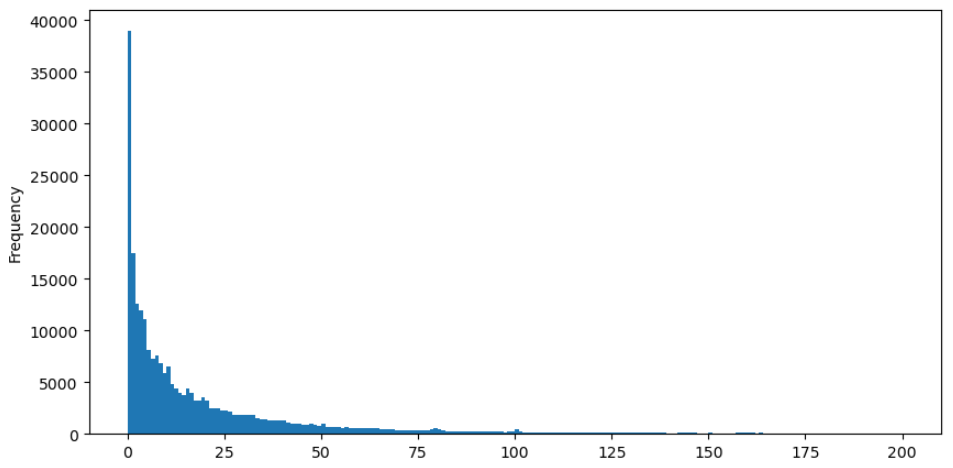
簡単に観察するために,尾を切り,データを分析しましょう. 取引量が増加するにつれて,発生頻度が減少し,減少率は速くなります.
[37]:
buy_trades['quantity'][buy_trades['quantity']<200].plot.hist(bins=200,figsize=(10, 5));
外 [37]:
取引量の分布に関する多くの研究が行われた.取引量は,統計物理学と社会科学における一般的な確率分布であるパレト分布として知られるパワー法則分布に従っていることが判明した.パワー法則分布では,イベントの大きさ (または頻度) の確率はそのイベントの大きさのマイナス指数に比例する.この分布の主な特徴は,他の多くの分布で予想されるよりも大きなイベントの頻度 (すなわち平均から遠いもの) が高いことである.これはまさに取引量分布の特徴である.パレト分布の形態は,P (x) = C (x) ^-α) によって与えられる.これを実証的に検証しよう.
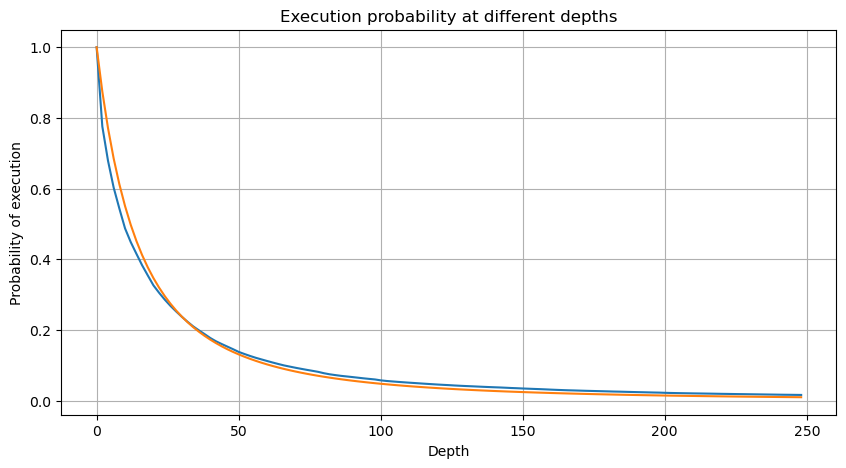
次のグラフは,ある値を上回る取引金額の確率を表しています.青い線は実際の確率を表し,オレンジ色の線はシミュレーションされた確率を表します.この時点で具体的なパラメータには触れないことに注意してください.分布は確かにパレト分布に従うことが観察できます.取引金額が0を超える確率は1であり,正規化を満たすために,分布方程式は以下のとおりであるべきです.
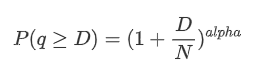
ここで,Nは正規化のためのパラメータです.我々は平均取引額,Mを選択し,alphaを-2.06に設定します.Alphaの特定の推定は,D=NのときにP値を計算することによって得ることができます.特に,alpha = log (((P(d>M)) /log ((2).異なるポイントの選択は,alphaの値にわずかな違いをもたらす可能性があります.
[55 ]:
depths = range(0, 250, 2)
probabilities = np.array([np.mean(buy_trades['quantity'] > depth) for depth in depths])
alpha = np.log(np.mean(buy_trades['quantity'] > mean_quantity))/np.log(2)
mean_quantity = buy_trades['quantity'].mean()
probabilities_s = np.array([(1+depth/mean_quantity)**alpha for depth in depths])
plt.figure(figsize=(10, 5))
plt.plot(depths, probabilities)
plt.plot(depths, probabilities_s)
plt.xlabel('Depth')
plt.ylabel('Probability of execution')
plt.title('Execution probability at different depths')
plt.grid(True)
アウト[55]:
[56 ]:
plt.figure(figsize=(10, 5))
plt.grid(True)
plt.title('Diff')
plt.plot(depths, probabilities_s-probabilities);
アウト[56]:
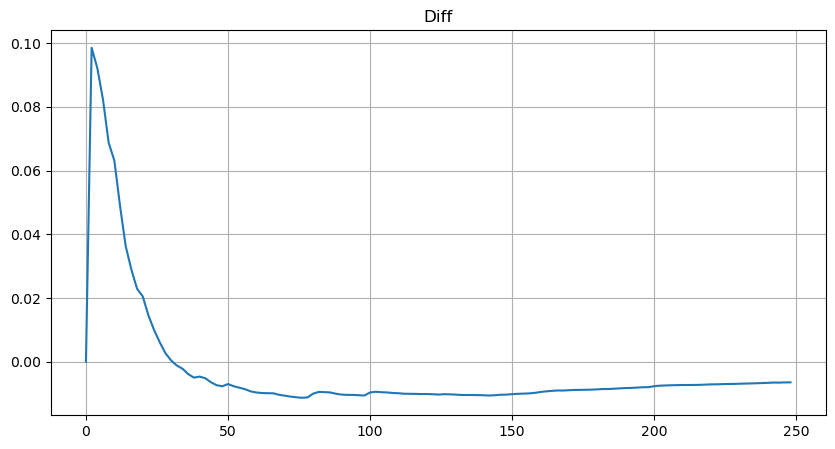
しかし,この推定値は,シミュレーション値と実際の値の違いをグラフに示すように,推定値のみである.取引額が小さいとき,偏差は大きく,10%近くまで近づく.パラメータ推定中に異なる点を選択しても,特定のポイントの確率の精度を向上させることができるが,全体の偏差問題は解決しない.この差異は,パワー法則分布と実際の分布の違いから生じる.より正確な結果を得るために,パワー法則分布の方程式は修正する必要がある.具体的なプロセスはここで詳細に述べられていないが,要約すると,一瞬の洞察の後,実際の方程式は以下のとおりであることが判明した.
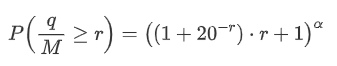
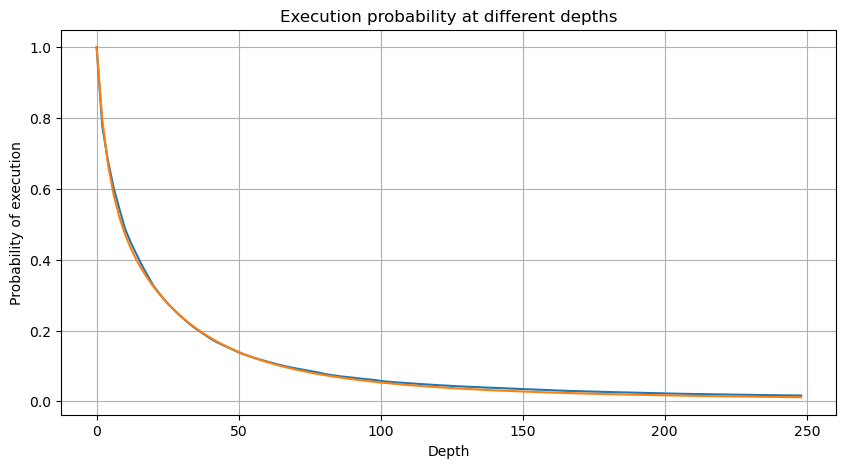
単純化するために,r = q/M を使って標準化された取引額を表します.前と同じ方法を使用してパラメータを推定できます.次のグラフは,修正後に最大偏差が2%を超えないことを示しています.理論的には,さらなる調整ができますが,この精度レベルはすでに十分です.
[52] で:
depths = range(0, 250, 2)
probabilities = np.array([np.mean(buy_trades['quantity'] > depth) for depth in depths])
mean = buy_trades['quantity'].mean()
alpha = np.log(np.mean(buy_trades['quantity'] > mean))/np.log(2.05)
probabilities_s = np.array([(((1+20**(-depth/mean))*depth+mean)/mean)**alpha for depth in depths])
plt.figure(figsize=(10, 5))
plt.plot(depths, probabilities)
plt.plot(depths, probabilities_s)
plt.xlabel('Depth')
plt.ylabel('Probability of execution')
plt.title('Execution probability at different depths')
plt.grid(True)
アウト[52]:
[53 ]:
plt.figure(figsize=(10, 5))
plt.grid(True)
plt.title('Diff')
plt.plot(depths, probabilities_s-probabilities);
アウト[53]:
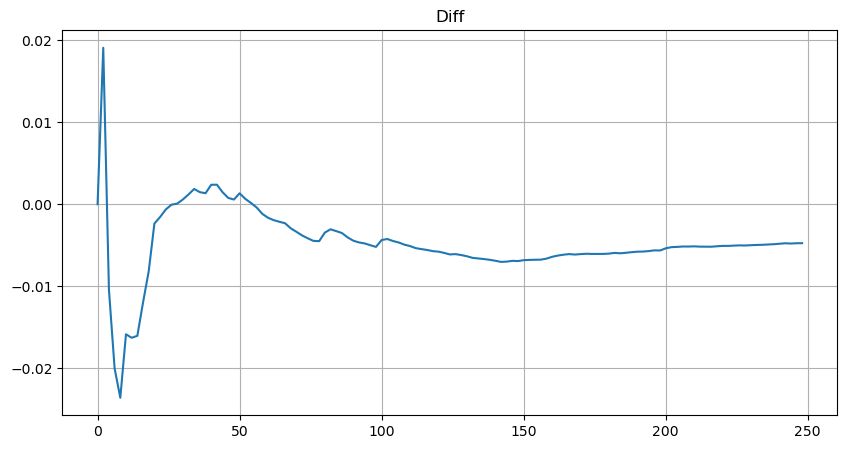
取引量分布の推定方程式では,方程式内の確率が実際の確率ではなく,条件確率であることを注意することが重要です.この時点で,次のオーダーの値が特定の値よりも大きい可能性はどれかという質問に答えることができます.また,異なる深さでのオーダーの実行確率 (理想シナリオでは,同じ深さでのオーダー追加,キャンセル,並列を考慮せずに) を決定することができます.
この 点 で は,その 文章 の 長さ は すでに かなり 長く あり,まだ 答え が 求め られる 質問 が 多く あり ます.次 の 記事 の シリーズ は その 答え を 提供 する こと に 努め ます.